听说流行写爬取妹子图爬虫,我也来一个
先上代码
import requests
from bs4 import BeautifulSoup
import os
def html_url(n):
url = 'http://www.win4000.com/meinv{}.html'.format(n)
html_url = requests.get(url)
html = html_url.text
return html
def jiexi(html):
soup = BeautifulSoup(html,'html.parser')
title_tag = soup.find('h1')
title = title_tag.string
image_tag = soup.find('div',{'id','pic-meinv'})
img = image_tag.find('img')
picture = img.attrs['data-original']
time_tag = soup.find('em')
time = time_tag.contents[0]
return title,picture,time
def save(title,picture,time):
if not os.path.exists(title):
os.makedirs(title)
print('正在下载第{}张图片'.format(time))
ext = picture.split('.')[-1] # 拿到扩展名
filename = title + '/' + title + time + '.' + ext
content = requests.get(picture).content
with open(filename,'wb') as f:
f.write(content)
if __name__ == '__main__':
for i in range(197307,0,-1):
html = html_url(str(i))
title,picture,time = jiexi(html)
print('正在下载 {}'.format(title))
save(title,picture,'1')
for j in range(int(time)-1):
html = html_url(str(i)+'_'+str(j+2))
title,picture,_=jiexi(html)
save(title,picture,str(j+2))
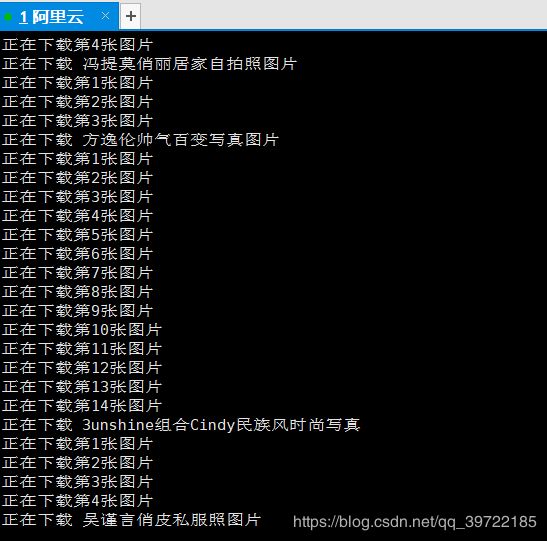
再上效果图
在云服务器上运行的效果图

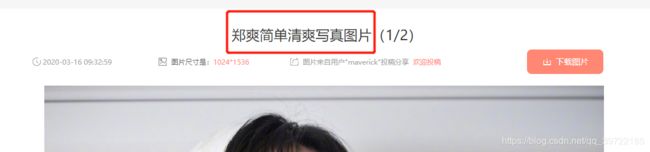
1.查看要爬取的网站
我是从197307 郑爽这块往回遍历的
url = http://www.win4000.com/meinv197307.html
得到网站的html
html = requests.get(url).text
2.分析网页
2-1 分析图片url
第一张图片的url为:http://www.win4000.com/meinv197307.html
第二张图片的url为: http://www.win4000.com/meinv197307_2.html
我们发现后边的多了个’_'下划线,加数字2,所以我们这块后期要做处理
2-2.右键‘检查’查看该图片标题
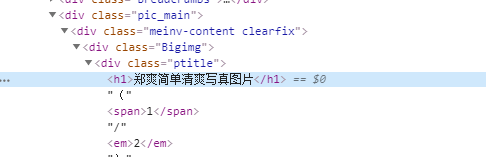
包含在一个h1标签内,所以我们查找的时候直接查找到该标签也就是:
title_tag = soup.find(‘h1’)
title = title_tag.string
2-3 右键‘检查’查看这个标题的图片一共有几张
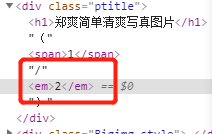
可以看到在一个em标签内,所以我们直接获取
time_tag = soup.find(‘em’)
time = time.tag.contents[0]
2-4 右键‘检查’图片的标签和具体地址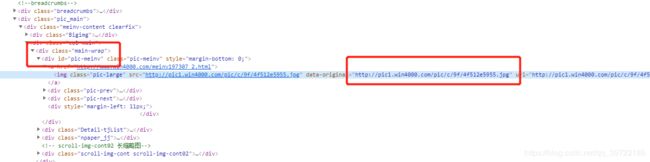 可以看到 在一个 div标签内id为‘pic-meinv’里所以
可以看到 在一个 div标签内id为‘pic-meinv’里所以
div_tag = soup.find(‘div’,{‘id’:‘pic-meinv’})
再寻找div标签内的img标签
img = image_tag.find(‘img’)
我们自己查看下img标签内哪个是自己想要的图 发现在‘data-origina’后的是所以
picture = img.attrs[‘data-original’]
所以我们现在得到了图片的URL,图片的标题,一套图片的张数
3.保存图片
3-1 首先我们用os模块检查当前脚本目录下有没有刚才图片标题的文件夹,没有我们就创建一个
if not os.path.exists(title):
os.makedirs(title)
3-2 再打个log查看我们下载第几张图
print(‘正在下载第{}张图片’.format(time))
3-3 拿到图片的扩展名
ext = picture.split(’.’)[-1] # 拿到扩展名
3-4 得到图片保存的目录,文件的名字
filename = title + ‘/’ + title + time + ‘.’ + ext
3-5 得到图片二进制文件
content = requests.get(picture).content
3-6 以二进制方法打开,写入图片,保存
with open(filename,‘wb’) as f:
f.write(content)
我们把各个函数模块链接起来,前文说的第二张图片下划线加数字,我们后边进行了处理
OK大工告成
最开始我requests的时候,模拟了浏览器的user-agent,
也就是
headers = {
‘User-Agent’:‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36’
}
request.get(url,headers=headers).text
但是模拟了headers后经常会爬不到网页,显示Nonetype,有没有大神能告知为何如此
目前爬了2000多张图没有问题
可以更改初始爬取的网页代码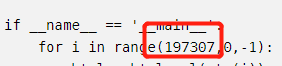
改了这个可以从这个网站你想要的开始爬取
完整代码请看开头。第一次写的不太好,希望大家指正!