《Neural Collaborative Filtering》NCF模型的理解以及python代码
1 原文








2 NCF模型
2.1 背景
在信息爆炸的时代,推荐系统在缓解信息过载方面发挥着关键作用,已被许多在线服务广泛采用,包括电子商务,在线新闻和社交媒体网站。个性化推荐系统的关键在于根据用户过去的交互(例如评级和点击)对项目的偏好建模,称为协同过滤。在各种协同过滤技术中,矩阵分解(MF)是最受欢迎的一种,其中使用潜在特征向量来表示用户或项目,将用户和项目投射到共享潜在空间。此后,用户对项目的交互被建模为其潜在向量的内积。
通过Netflix奖推广,MF已经成为基于潜在因素模型的推荐方法主流。许多研究工作致力于增强MF,例如将其与基于邻居的模型集成,将其与项目内容的主题模型相结合,并将其扩展到因子分解机FM以进行特征的通用建模。尽管MF对于协同过滤有效,但众所周知,通过简单的 inner product进行特征交互可以阻碍其性能。例如,对于对显式反馈进行评级预测的任务,众所周知,通过将用户和项目偏差项结合到交互功能中,可以提高MF模型的性能。虽然它似乎只是 inner product操作的一个微不足道的调整,但它指出了设计更好的专用交互功能来建模用户和项目之间的潜在特征交互的积极效果。 inner product简单地线性地组合潜在特征,可能不足以捕获用户交互数据的复杂结构。
关于显示反馈与隐式反馈:
- 显性反馈行为包括用户明确表示对物品喜好的行为
- 隐性反馈行为指的是那些不能明确反应用户喜好
很多情况下,用户不会给出明确的显示反馈(评分),而是只留下了一些操作日志(点击、播放)。因此,需要根据隐式反馈来猜测用户的喜好。
2.2 MF模型的缺点
MF将每个用户和项目通过潜在特征的实值向量相关联。公式如下:


问题:
Let us first focus on the first three rows (users) in Figure 1a. It is easy to have s 23 ( 0.66 ) > s 12 ( 0.5 ) > s 13 ( 0.4 ) s23(0.66) > s12(0.5) > s13(0.4) s23(0.66)>s12(0.5)>s13(0.4). As such, the geometric relations of p1, p2, and p3 in the latent space can be plotted as in Figure 1b. Now, let us consider a new user u4, whose input is given as the dashed line in Figure 1a. We can have s 41 ( 0.6 ) > s 43 ( 0.4 ) > s 42 ( 0.2 ) s41(0.6) > s43(0.4) > s42(0.2) s41(0.6)>s43(0.4)>s42(0.2), meaning that u4 is most similar to u1, followed by u3, and lastly u2. However, if a MF model places p4 closest to p1 (the two options are shown in Figure 1b with dashed lines), it will result in p4 closer to p2 than p3, which unfortunately will incur a large ranking loss.
其中,Jaccard系数 s i j = ∣ R i ∣ ∩ ∣ R j ∣ ∣ R i ∣ ∪ ∣ R j ∣ sij = \frac{|Ri|∩|Rj|}{|Ri|∪|Rj|} sij=∣Ri∣∪∣Rj∣∣Ri∣∩∣Rj∣。解决该问题的方法之一是使用大量的潜在因子 K (就是隐式空间向量的维度)。然而这可能对模型的泛化能力产生不利的影响(例如:过拟合),特别是在稀疏的集合上。而该论文通过使用DNN从数据中学习交互函数,突破了这个限制。接下来将对论文的通用框架如下:
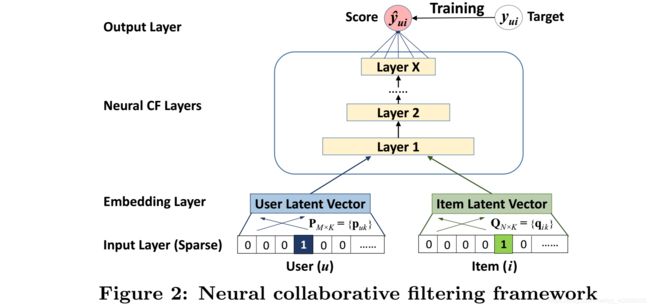
2.3 三个模型
本文主要包含三个模型分别为:GMF(广义矩阵分解)、MLP(多层感知机)、NeuMF(GMF&MLP)。

2.3 GMF
2.2节图的左部分,模型的输出为:
![]()
其中, p u ⊙ p i p_u\odot p_i pu⊙pi是两个向量的元素级乘法。
![]()
其中, h T h^T hT表示输出层边缘权重; a o u t a_{out} aout表示输出层的激活函数。user隐向量 p u = P T v u U p_u = P^T v^U_u pu=PTvuU,item隐向量 q u = Q T v i I q_u = Q^T v^I_i qu=QTviI, P ∈ R M × K , Q ∈ R N × K P ∈ R^{M×K} , Q ∈ R^{N×K} P∈RM×K,Q∈RN×K
2.4 MLP
2.2节图的右部分,模型:

2.5 NeuMF
结合GMF和MLP,得到的就是第三种实现方式(NeuMF),2.2节图则是NeuMF完整实现,输出层的计算公式为:

为了给融合模型提供更大的灵活性,我们允许GMF和MLP学习单独的嵌入,并通过连接它们的最后隐藏层来组合这两个模型。
3 python
import numpy as np
import pandas as pd
import tensorflow as tf
import os
DATA_DIR = 'data/ratings.dat'
DATA_PATH = 'data/'
COLUMN_NAMES = ['user','item']
def re_index(s):
i = 0
s_map = {}
for key in s:
s_map[key] = i
i += 1
return s_map
def load_data():
full_data = pd.read_csv(DATA_DIR,sep='::',header=None,names=COLUMN_NAMES,
usecols=[0,1],dtype={0:np.int32,1:np.int32},engine='python')
full_data.user = full_data['user'] - 1
user_set = set(full_data['user'].unique())
item_set = set(full_data['item'].unique())
user_size = len(user_set)
item_size = len(item_set)
item_map = re_index(item_set)
item_list = []
full_data['item'] = full_data['item'].map(lambda x:item_map[x])
item_set = set(full_data.item.unique())
user_bought = {}
for i in range(len(full_data)):
u = full_data['user'][i]
t = full_data['item'][i]
if u not in user_bought:
user_bought[u] = []
user_bought[u].append(t)
user_negative = {}
for key in user_bought:
user_negative[key] = list(item_set - set(user_bought[key]))
user_length = full_data.groupby('user').size().tolist()
split_train_test = []
for i in range(len(user_set)):
for _ in range(user_length[i] - 1):
split_train_test.append('train')
split_train_test.append('test')
full_data['split'] = split_train_test
train_data = full_data[full_data['split'] == 'train'].reset_index(drop=True)
test_data = full_data[full_data['split'] == 'test'].reset_index(drop=True)
del train_data['split']
del test_data['split']
labels = np.ones(len(train_data),dtype=np.int32)
train_features = train_data
train_labels = labels.tolist()
test_features = test_data
test_labels = test_data['item'].tolist()
return ((train_features, train_labels),
(test_features, test_labels),
(user_size, item_size),
(user_bought, user_negative))
def add_negative(features,user_negative,labels,numbers,is_training):
feature_user,feature_item,labels_add,feature_dict = [],[],[],{}
for i in range(len(features)):
user = features['user'][i]
item = features['item'][i]
label = labels[i]
feature_user.append(user)
feature_item.append(item)
labels_add.append(label)
neg_samples = np.random.choice(user_negative[user],size=numbers,replace=False).tolist()
if is_training:
for k in neg_samples:
feature_user.append(user)
feature_item.append(k)
labels_add.append(0)
else:
for k in neg_samples:
feature_user.append(user)
feature_item.append(k)
labels_add.append(k)
feature_dict['user'] = feature_user
feature_dict['item'] = feature_item
return feature_dict,labels_add
def dump_data(features,labels,user_negative,num_neg,is_training):
if not os.path.exists(DATA_PATH):
os.makedirs(DATA_PATH)
features,labels = add_negative(features,user_negative,labels,num_neg,is_training)
data_dict = dict([('user', features['user']),
('item', features['item']), ('label', labels)])
print(data_dict)
if is_training:
np.save(os.path.join(DATA_PATH, 'train_data.npy'), data_dict)
else:
np.save(os.path.join(DATA_PATH, 'test_data.npy'), data_dict)
def train_input_fn(features,labels,batch_size,user_negative,num_neg):
data_path = os.path.join(DATA_PATH, 'train_data.npy')
if not os.path.exists(data_path):
dump_data(features, labels, user_negative, num_neg, True)
data = np.load(data_path).item()
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.shuffle(100000).batch(batch_size)
return dataset
def eval_input_fn(features, labels, user_negative, test_neg):
""" Construct testing dataset. """
data_path = os.path.join(DATA_PATH, 'test_data.npy')
if not os.path.exists(data_path):
dump_data(features, labels, user_negative, test_neg, False)
data = np.load(data_path).item()
print("Loading testing data finished!")
dataset = tf.data.Dataset.from_tensor_slices(data)
dataset = dataset.batch(test_neg + 1)
return dataset
import numpy as np
def mrr(gt_item, pred_items):
if gt_item in pred_items:
index = np.where(pred_items == gt_item)[0][0]
return np.reciprocal(float(index + 1))
else:
return 0
def hit(gt_item, pred_items):
if gt_item in pred_items:
return 1
return 0
def ndcg(gt_item, pred_items):
if gt_item in pred_items:
index = np.where(pred_items == gt_item)[0][0]
return np.reciprocal(np.log2(index + 2))
return 0
import numpy as np
import pandas as pd
import tensorflow as tf
import sys
class NCF(object):
def __init__(self, embed_size, user_size, item_size, lr,
optim, initializer, loss_func, activation_func,
regularizer_rate, iterator, topk, dropout, is_training):
"""
Important Arguments.
embed_size: The final embedding size for users and items.
optim: The optimization method chosen in this model.
initializer: The initialization method.
loss_func: Loss function, we choose the cross entropy.
regularizer_rate: L2 is chosen, this represents the L2 rate.
iterator: Input dataset.
topk: For evaluation, computing the topk items.
"""
self.embed_size = embed_size
self.user_size = user_size
self.item_size = item_size
self.lr = lr
self.initializer = initializer
self.loss_func = loss_func
self.activation_func = activation_func
self.regularizer_rate = regularizer_rate
self.optim = optim
self.topk = topk
self.dropout = dropout
self.is_training = is_training
self.iterator = iterator
def get_data(self):
sample = self.iterator.get_next()
self.user = sample['user']
self.item = sample['item']
self.label = tf.cast(sample['label'],tf.float32)
def inference(self):
""" Initialize important settings """
self.regularizer = tf.contrib.layers.l2_regularizer(self.regularizer_rate)
if self.initializer == 'Normal':
self.initializer = tf.truncated_normal_initializer(stddev=0.01)
elif self.initializer == 'Xavier_Normal':
self.initializer = tf.contrib.layers.xavier_initializer()
else:
self.initializer = tf.glorot_uniform_initializer()
if self.activation_func == 'ReLU':
self.activation_func = tf.nn.relu
elif self.activation_func == 'Leaky_ReLU':
self.activation_func = tf.nn.leaky_relu
elif self.activation_func == 'ELU':
self.activation_func = tf.nn.elu
if self.loss_func == 'cross_entropy':
# self.loss_func = lambda labels, logits: -tf.reduce_sum(
# (labels * tf.log(logits) + (
# tf.ones_like(labels, dtype=tf.float32) - labels) *
# tf.log(tf.ones_like(logits, dtype=tf.float32) - logits)), 1)
self.loss_func = tf.nn.sigmoid_cross_entropy_with_logits
if self.optim == 'SGD':
self.optim = tf.train.GradientDescentOptimizer(self.lr,
name='SGD')
elif self.optim == 'RMSProp':
self.optim = tf.train.RMSPropOptimizer(self.lr, decay=0.9,
momentum=0.0, name='RMSProp')
elif self.optim == 'Adam':
self.optim = tf.train.AdamOptimizer(self.lr, name='Adam')
def create_model(self):
with tf.name_scope('input'):
self.user_onehot = tf.one_hot(self.user,self.user_size,name='user_onehot')
self.item_onehot = tf.one_hot(self.item,self.item_size,name='item_onehot')
with tf.name_scope('embed'):
self.user_embed_GMF = tf.layers.dense(inputs = self.user_onehot,
units = self.embed_size,
activation = self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='user_embed_GMF')
self.item_embed_GMF = tf.layers.dense(inputs=self.item_onehot,
units=self.embed_size,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='item_embed_GMF')
self.user_embed_MLP = tf.layers.dense(inputs=self.user_onehot,
units=self.embed_size,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='user_embed_MLP')
self.item_embed_MLP = tf.layers.dense(inputs=self.item_onehot,
units=self.embed_size,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='item_embed_MLP')
with tf.name_scope("GMF"):
self.GMF = tf.multiply(self.user_embed_GMF,self.item_embed_GMF,name='GMF')
with tf.name_scope("MLP"):
self.interaction = tf.concat([self.user_embed_MLP, self.item_embed_MLP],
axis=-1, name='interaction')
self.layer1_MLP = tf.layers.dense(inputs=self.interaction,
units=self.embed_size * 2,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='layer1_MLP')
self.layer1_MLP = tf.layers.dropout(self.layer1_MLP, rate=self.dropout)
self.layer2_MLP = tf.layers.dense(inputs=self.layer1_MLP,
units=self.embed_size,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='layer2_MLP')
self.layer2_MLP = tf.layers.dropout(self.layer2_MLP, rate=self.dropout)
self.layer3_MLP = tf.layers.dense(inputs=self.layer2_MLP,
units=self.embed_size // 2,
activation=self.activation_func,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='layer3_MLP')
self.layer3_MLP = tf.layers.dropout(self.layer3_MLP, rate=self.dropout)
with tf.name_scope('concatenation'):
self.concatenation = tf.concat([self.GMF,self.layer3_MLP],axis=-1,name='concatenation')
self.logits = tf.layers.dense(inputs= self.concatenation,
units = 1,
activation=None,
kernel_initializer=self.initializer,
kernel_regularizer=self.regularizer,
name='predict')
self.logits_dense = tf.reshape(self.logits,[-1])
with tf.name_scope("loss"):
self.loss = tf.reduce_mean(self.loss_func(
labels=self.label, logits=self.logits_dense, name='loss'))
# self.loss = tf.reduce_mean(self.loss_func(self.label, self.logits),
# name='loss')
with tf.name_scope("optimzation"):
self.optimzer = self.optim.minimize(self.loss)
def eval(self):
with tf.name_scope("evaluation"):
self.item_replica = self.item
_, self.indice = tf.nn.top_k(tf.sigmoid(self.logits_dense), self.topk)
def summary(self):
""" Create summaries to write on tensorboard. """
self.writer = tf.summary.FileWriter('./graphs/NCF', tf.get_default_graph())
with tf.name_scope("summaries"):
tf.summary.scalar('loss', self.loss)
tf.summary.histogram('histogram loss', self.loss)
self.summary_op = tf.summary.merge_all()
def build(self):
self.get_data()
self.inference()
self.create_model()
self.eval()
self.summary()
self.saver = tf.train.Saver(tf.global_variables())
def step(self, session, step):
""" Train the model step by step. """
if self.is_training:
loss, optim, summaries = session.run(
[self.loss, self.optimzer, self.summary_op])
self.writer.add_summary(summaries, global_step=step)
else:
indice, item = session.run([self.indice, self.item_replica])
prediction = np.take(item, indice)
return prediction, item
import os,sys,time
import numpy as np
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_integer('batch_size', 128, 'size of mini-batch.')
tf.app.flags.DEFINE_integer('negative_num', 4, 'number of negative samples.')
tf.app.flags.DEFINE_integer('test_neg', 99, 'number of negative samples for test.')
tf.app.flags.DEFINE_integer('embedding_size', 16, 'the size for embedding user and item.')
tf.app.flags.DEFINE_integer('epochs', 20, 'the number of epochs.')
tf.app.flags.DEFINE_integer('topK', 10, 'topk for evaluation.')
tf.app.flags.DEFINE_string('optim', 'Adam', 'the optimization method.')
tf.app.flags.DEFINE_string('initializer', 'Xavier', 'the initializer method.')
tf.app.flags.DEFINE_string('loss_func', 'cross_entropy', 'the loss function.')
tf.app.flags.DEFINE_string('activation', 'ReLU', 'the activation function.')
tf.app.flags.DEFINE_string('model_dir', 'model/', 'the dir for saving model.')
tf.app.flags.DEFINE_float('regularizer', 0.0, 'the regularizer rate.')
tf.app.flags.DEFINE_float('lr', 0.001, 'learning rate.')
tf.app.flags.DEFINE_float('dropout', 0.0, 'dropout rate.')
def train(train_data,test_data,user_size,item_size):
with tf.Session() as sess:
iterator = tf.data.Iterator.from_structure(train_data.output_types,
train_data.output_shapes)
model = NCF.NCF(FLAGS.embedding_size, user_size, item_size, FLAGS.lr,
FLAGS.optim, FLAGS.initializer, FLAGS.loss_func, FLAGS.activation,
FLAGS.regularizer, iterator, FLAGS.topK, FLAGS.dropout, is_training=True)
model.build()
ckpt = tf.train.get_checkpoint_state(FLAGS.model_dir)
if ckpt:
print("Reading model parameters from %s" % ckpt.model_checkpoint_path)
model.saver.restore(sess, ckpt.model_checkpoint_path)
else:
print("Creating model with fresh parameters.")
sess.run(tf.global_variables_initializer())
count = 0
for epoch in range(FLAGS.epochs):
sess.run(model.iterator.make_initializer(train_data))
model.is_training = True
model.get_data()
start_time = time.time()
try:
while True:
model.step(sess, count)
count += 1
except tf.errors.OutOfRangeError:
print("Epoch %d training " % epoch + "Took: " + time.strftime("%H: %M: %S",
time.gmtime(time.time() - start_time)))
sess.run(model.iterator.make_initializer(test_data))
model.is_training = False
model.get_data()
start_time = time.time()
HR,MRR,NDCG = [],[],[]
prediction, label = model.step(sess, None)
try:
while True:
prediction, label = model.step(sess, None)
label = int(label[0])
HR.append(metrics.hit(label, prediction))
MRR.append(metrics.mrr(label, prediction))
NDCG.append(metrics.ndcg(label, prediction))
except tf.errors.OutOfRangeError:
hr = np.array(HR).mean()
mrr = np.array(MRR).mean()
ndcg = np.array(NDCG).mean()
print("Epoch %d testing " % epoch + "Took: " + time.strftime("%H: %M: %S",
time.gmtime(time.time() - start_time)))
print("HR is %.3f, MRR is %.3f, NDCG is %.3f" % (hr, mrr, ndcg))
################################## SAVE MODEL ################################
checkpoint_path = os.path.join(FLAGS.model_dir, "NCF.ckpt")
model.saver.save(sess, checkpoint_path)
def main():
((train_features, train_labels),
(test_features, test_labels),
(user_size, item_size),
(user_bought, user_negative)) = NCF_input.load_data()
print(train_features[:10])
train_data = NCF_input.train_input_fn(train_features,train_labels,FLAGS.batch_size,user_negative,FLAGS.negative_num)
# print(train_data)
test_data = NCF_input.eval_input_fn(test_features, test_labels,
user_negative, FLAGS.test_neg)
train(train_data,test_data,user_size,item_size)
if __name__ == '__main__':
main()
巨人的肩膀
https://www.comp.nus.edu.sg/~xiangnan/papers/ncf.pdf