人工智能(AI)是如何处理数据的?
AI处理数据主要是通过数据挖掘和数据分析。
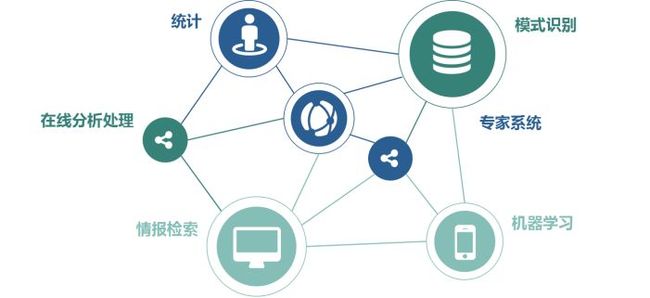
一、数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(Knowledge-Discovery in Databases,简称KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
利用数据挖掘进行数据处理常用的方法主要有分类、回归分析、聚类、关联规则、特征、变化和偏差分析、Web页挖掘等, 它们分别从不同的角度对数据进行挖掘。
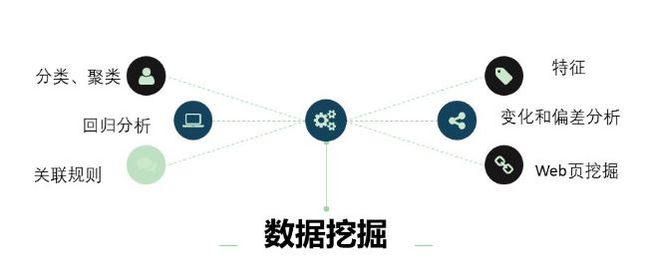
①分类。分类是找出数据库中一组数据对象的共同特点并按照分类模式将其划分为不同的类,其目的是通过分类模型,将数据库中的数据项映射到某个给定的类别。如一个汽车零售商将客户按照对汽车的喜好划分成不同的类,这样营销人员就可以将新型汽车的广告手册直接邮寄到特定的客户手中,从而大大增加了商业机会。
②回归分析。回归分析方法反映的是数据库中属性值在时间上的特征,产生一个将数据项映射到一个实值预测变量的函数,发现变量或属性间的依赖关系。
③聚类。聚类分析是把一组数据按照相似性和差异性分为几个类别,其目的是使得属于同一类别的数据间的相似性尽可能大,不同类别中的数据间的相似性尽可能小。
④关联规则。关联规则是描述数据库中数据项之间所存在的关系的规则。即根据一个事务中某些项的出现可导出另一些项在同一事务中也出现,即隐藏在数据间的关联或相互关系。
⑤特征。特征分析是从数据库中的一组数据中提取出关于这些数据的特征式,这些特征式表达了该数据集的总体特征。如营销人员通过对客户流失因素的特征提取,可以得到导致客户流失的一系列原因和主要特征,利用这些特征可以有效地预防客户的流失。
⑥变化和偏差分析。偏差包括很大一类潜在有趣的知识,如分类中的反常实例,模式的例外,观察结果对期望的偏差等,其目的是寻找观察结果与参照量之间有意义的差别。在企业危机管理及其预警中,管理者更感兴趣的是那些意外规则。意外规则的挖掘可以应用到各种异常信息的发现、分析、识别、评价和预警等方面。
⑦Web页挖掘。随着Internet的迅速发展及Web 的全球普及, 使得Web上的信息量无比丰富,通过对Web的挖掘,可以利用Web 的海量数据进行分析,收集政治、经济、政策、科技、金融、各种市场、竞争对手、供求信息、客户等有关的信息,集中精力分析和处理那些对企业有重大或潜在重大影响的外部环境信息和内部经营信息,并根据分析结果找出企业管理过程中出现的各种问题和可能引起危机的先兆,对这些信息进行分析和处理,以便识别、分析、评价和管理危机。
二、数据分析是数学与计算机科学相结合的产物,是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。在实际生活应用中,数据分析可帮助人们作出判断,以便采取适当行动。
在统计学领域,有些人将数据分析划分为描述性统计分析、探索性数据分析以及验证性数据分析;其中,探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧重于已有假设的证实或证伪。

①探索性数据分析:是指为了形成值得假设的检验而对数据进行分析的一种方法,是对传统统计学假设检验手段的补充。
②定性数据分析:又称为“定性资料分析”、“定性研究”或者“质性研究资料分析”,是指对诸如词语、照片、观察结果之类的非数值型数据的分析。
大量的数据分析需求都与特定的应用相关,需要相关领域知识的支持。通用的数据挖掘工具在处理特定应用问题时有其局限性,常常需要开发针对特定应用的数据分析系统。因此数据分析系统设计的第一步是对特定应用的业务进行深入地分析与研究,总结归纳分析思路并细分出所需的分析功能。
数据分析主要包含下面几个功能:

数据分析是组织有目的地收集数据、分析数据,使之成为信息的过程。这一过程是质量管理体系的支持过程。在产品的整个寿命周期,包括从市场调研到售后服务和最终处置的各个过程都需要适当运用数据分析过程,以提升有效性。

在实用中,数据可为AI提供基础要素,可帮助AI作出判断,以便AI进行学习。例如,来自马萨诸塞州总医院和哈佛医学院放射科的研究人员使用卷积神经网络来识别 CT图像,基于训练数据大小来评估神经网络的准确性。随着训练规模的增大,精度将被提高。
今天的大多数深度学习是监督的或半监督的,意味着用于训练模型的所有或一些数据必须由人标记。 无监督的机器学习是 AI 中当前的 “圣杯”,因为可以利用原始未标记的数据来训练模型。 广泛采用深度学习可能与大数据集的增长以及无人监督的机器学习的发展有关。然而,我们认为大型差异化数据集(电子健康记录,组学数据,地质数据,天气数据等)可能是未来十年企业利润创造的核心驱动力。
参考 IDC 报告,全世界创造的信息量预计到 2020 年将以 36%的复合年增长率增长,达到 44 泽字节( 440 亿 GB)。连接的设备(消费者和工业领域),机器到机器通信和远程传感器的增加和组合可以创建大型数据集, 然后可以挖掘洞察和训练自适应算法。
AI之所以拥有人的思维,人的智慧,其核心在于AI可以通过海量的数据进行机器学习和深度学习。拥有的数据越多,神经网络就变得越有效率,意味着随着数据量的增长,机器语言可以解决的问题的数量也在增长。移动手机、物联网、低耗数据存储的成熟和处理技术(通常在云端)已经在数量、大小、可靠数据结构方面创造了大量的成长。例如:
5G 的首次展示将最适当地加速数据可被获取和转移的机率。根据 IDC 的数字领域报告,到 2020 年,每年数据量将达到 44ZB(万亿 G),5 年内年复合增长率达到 141%,暗示我们刚开始看到这些科技可以达到的应用场景。
数据(Data)是指对事实、概念或指令的一种表达形式,可由人工或自动化装置进行处理。数据处理(data processing)是对数据的采集、存储、检索、加工、变换和传输,贯穿于社会生产和社会生活的各个领域。数据经过解释并赋予一定的意义之后,便成为信息。
人工智能出现之前,传统数据的处理主要包括了8个方面:

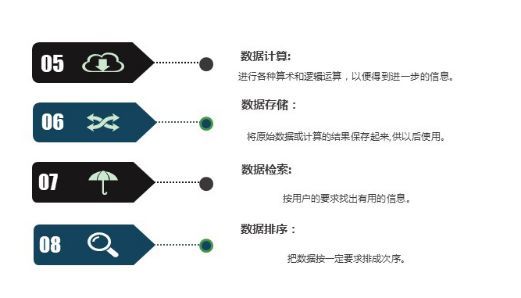
通过这个8方面,从大量的、可能是杂乱无章的、难以理解的数据中抽取并推导出对于某些特定的人们来说是有价值、有意义的数据。传统意义上的数据处理离不开软件的支持,每次处理数据大概都需要使用至少三次软件,这对人力物力都是一种极大的浪费。
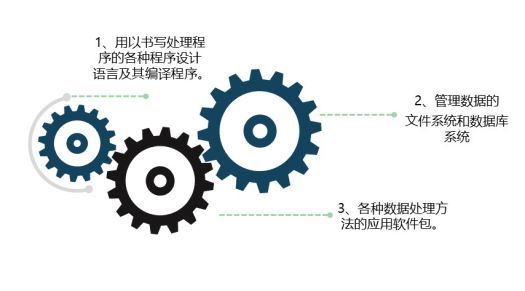
而在AI时代,数据的处理就变得简单多了,就拿最近比较热门的车联网来说。
车联网一个系统通过在车辆仪表台安装车载终端设备,就对车辆所有工作情况和静、动态信息的采集、存储并发送。车联网系统分为三大部分:车载终端、云计算处理平台、数据分析平台,根据不同行业对车辆的不同的功能需求实现对车辆有效监控管理。车辆的运行往往涉及多项开关量、传感器模拟量、CAN信号数据等等,驾驶员在操作车辆运行过程中,产生的车辆数据不断回发到后台数据库,形成海量数据,由云计算平台实现对海量数据的“过滤清洗”,数据分析平台对数据进行报表式处理,供管理人员查看。
作者:造数科技
链接:https://www.zhihu.com/question/264417928/answer/282811201
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。