《python深度学习》学习笔记与代码实现(第六章,6.4用卷积神经网络处理序列)
6.4 用卷积神经网络处理序列
1.实现一维卷积神经网络,用imdb情感分类任务举例
from keras.datasets import imdb
from keras.preprocessing import sequence
max_features = 10000
max_len = 500
print('loading dataset ......')
(x_train,y_train),(x_test,y_test) = imdb.load_data(num_words = max_features)
print('train sequences',len(x_train))
print('test sequences',len(x_test))
print('pad sequences (samples x time)')
x_train = sequence.pad_sequences(x_train,maxlen = max_len)
x_test = sequence.pad_sequences(x_test,maxlen = max_len)
print('x_train shape',x_train.shape)
print('x_test shape',x_test.shape)
loading dataset ......
train sequences 25000
test sequences 25000
pad sequences (samples x time)
x_train shape (25000, 500)
x_test shape (25000, 500)
# 在IMDB上训练并评估一个简单的一维卷积神经网络
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Embedding(max_features,128,input_length = max_len))
model.add(layers.Conv1D(32,7,activation = 'relu'))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32,7,activation = 'relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer = RMSprop(lr = 1e-4),loss = 'binary_crossentropy',metrics = ['acc'])
history = model.fit(x_train,y_train,epochs = 10,batch_size = 128,validation_split = 0.2)
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 500, 128) 1280000
_________________________________________________________________
conv1d_1 (Conv1D) (None, 494, 32) 28704
_________________________________________________________________
max_pooling1d_1 (MaxPooling1 (None, 98, 32) 0
_________________________________________________________________
conv1d_2 (Conv1D) (None, 92, 32) 7200
_________________________________________________________________
global_max_pooling1d_1 (Glob (None, 32) 0
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 1,315,937
Trainable params: 1,315,937
Non-trainable params: 0
_________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
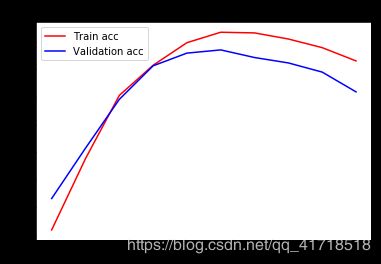
20000/20000 [==============================] - 36s 2ms/step - loss: 0.8337 - acc: 0.5091 - val_loss: 0.6874 - val_acc: 0.5660
Epoch 2/10
20000/20000 [==============================] - 9s 442us/step - loss: 0.6700 - acc: 0.6382 - val_loss: 0.6641 - val_acc: 0.6572
Epoch 3/10
20000/20000 [==============================] - 9s 432us/step - loss: 0.6236 - acc: 0.7528 - val_loss: 0.6081 - val_acc: 0.7456
Epoch 4/10
20000/20000 [==============================] - 9s 440us/step - loss: 0.5259 - acc: 0.8074 - val_loss: 0.4844 - val_acc: 0.8064
Epoch 5/10
20000/20000 [==============================] - 9s 434us/step - loss: 0.4095 - acc: 0.8483 - val_loss: 0.4339 - val_acc: 0.8294
Epoch 6/10
20000/20000 [==============================] - 9s 433us/step - loss: 0.3483 - acc: 0.8672 - val_loss: 0.4151 - val_acc: 0.8352
Epoch 7/10
20000/20000 [==============================] - 9s 433us/step - loss: 0.3089 - acc: 0.8660 - val_loss: 0.4383 - val_acc: 0.8214
Epoch 8/10
20000/20000 [==============================] - 9s 431us/step - loss: 0.2778 - acc: 0.8550 - val_loss: 0.4284 - val_acc: 0.8116
Epoch 9/10
20000/20000 [==============================] - 9s 435us/step - loss: 0.2532 - acc: 0.8393 - val_loss: 0.4370 - val_acc: 0.7950
Epoch 10/10
20000/20000 [==============================] - 9s 434us/step - loss: 0.2302 - acc: 0.8153 - val_loss: 0.4977 - val_acc: 0.7592
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc)+1)
plt.plot(epochs,acc,'r',label = 'Train acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('Train and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'r',label = 'Train loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('Train and Validation loss')
plt.legend()
plt.show()
结合CNN和RNN处理长序列
一维卷积神经网络对时间步的顺序不敏感,在耶拿数据集上运用一维卷积神经网络预测温度
import os
import numpy as np
data_dir = r'D:\study\Python\Deeplearning\Untitled Folder\jena_climate_2009_2016.csv'
fname = os.path.join(data_dir,'jena_climate_2009_2016.csv')
f = open(fname)
data = f.read()
f.close()
lines = data.split('\n')
header = lines[0].split(',')
lines = lines[1:]
float_data = np.zeros((len(lines), len(header) - 1))
for i, line in enumerate(lines):
values = [float(x) for x in line.split(',')[1:]]
float_data[i, :] = values
mean = float_data[:200000].mean(axis=0)
float_data -= mean
std = float_data[:200000].std(axis=0)
float_data /= std
def generator(data, lookback, delay, min_index, max_index,
shuffle=False, batch_size=128, step=6):
if max_index is None:
max_index = len(data) - delay - 1
i = min_index + lookback
while 1:
if shuffle:
rows = np.random.randint(
min_index + lookback, max_index, size=batch_size)
else:
if i + batch_size >= max_index:
i = min_index + lookback
rows = np.arange(i, min(i + batch_size, max_index))
i += len(rows)
samples = np.zeros((len(rows),
lookback // step,
data.shape[-1]))
targets = np.zeros((len(rows),))
for j, row in enumerate(rows):
indices = range(rows[j] - lookback, rows[j], step)
samples[j] = data[indices]
targets[j] = data[rows[j] + delay][1]
yield samples, targets
lookback = 1440
step = 6
delay = 144
batch_size = 128
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
# This is how many steps to draw from `val_gen`
# in order to see the whole validation set:
val_steps = (300000 - 200001 - lookback) // batch_size
# This is how many steps to draw from `test_gen`
# in order to see the whole test set:
test_steps = (len(float_data) - 300001 - lookback) // batch_size
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Conv1D(32,5,activation = 'relu',input_shape = (None,float_data.shape[-1])))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32,5,activation = 'relu'))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32,5,activation = 'relu'))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer=RMSprop(), loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=val_steps)
Layer (type) Output Shape Param #
=================================================================
conv1d_19 (Conv1D) (None, None, 32) 2272
_________________________________________________________________
max_pooling1d_14 (MaxPooling (None, None, 32) 0
_________________________________________________________________
conv1d_20 (Conv1D) (None, None, 32) 5152
_________________________________________________________________
max_pooling1d_15 (MaxPooling (None, None, 32) 0
_________________________________________________________________
conv1d_21 (Conv1D) (None, None, 32) 5152
_________________________________________________________________
global_max_pooling1d_6 (Glob (None, 32) 0
_________________________________________________________________
dense_4 (Dense) (None, 1) 33
=================================================================
Total params: 12,609
Trainable params: 12,609
Non-trainable params: 0
_________________________________________________________________
Epoch 1/20
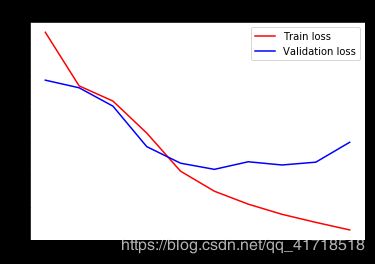
500/500 [==============================] - 19s 39ms/step - loss: 0.4117 - val_loss: 0.4399
Epoch 2/20
500/500 [==============================] - 16s 31ms/step - loss: 0.3551 - val_loss: 0.4312
Epoch 3/20
500/500 [==============================] - 16s 33ms/step - loss: 0.3327 - val_loss: 0.4414
Epoch 4/20
500/500 [==============================] - 17s 33ms/step - loss: 0.3187 - val_loss: 0.4359
Epoch 5/20
500/500 [==============================] - 16s 33ms/step - loss: 0.3034 - val_loss: 0.4311
Epoch 6/20
500/500 [==============================] - 17s 33ms/step - loss: 0.2970 - val_loss: 0.4358
Epoch 7/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2867 - val_loss: 0.4333
Epoch 8/20
500/500 [==============================] - 17s 33ms/step - loss: 0.2820 - val_loss: 0.4393
Epoch 9/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2730 - val_loss: 0.4521
Epoch 10/20
500/500 [==============================] - 17s 34ms/step - loss: 0.2692 - val_loss: 0.4542
Epoch 11/20
500/500 [==============================] - 17s 33ms/step - loss: 0.2659 - val_loss: 0.4432
Epoch 12/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2605 - val_loss: 0.4363
Epoch 13/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2564 - val_loss: 0.4590
Epoch 14/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2533 - val_loss: 0.4403
Epoch 15/20
500/500 [==============================] - 17s 33ms/step - loss: 0.2495 - val_loss: 0.4447
Epoch 16/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2479 - val_loss: 0.4476
Epoch 17/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2434 - val_loss: 0.4502
Epoch 18/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2411 - val_loss: 0.4416
Epoch 19/20
500/500 [==============================] - 16s 33ms/step - loss: 0.2391 - val_loss: 0.4576
Epoch 20/20
500/500 [==============================] - 17s 33ms/step - loss: 0.2375 - val_loss: 0.4768
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs,loss,'r',label = 'Train loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('Train and Validation loss')
plt.legend()
plt.show()
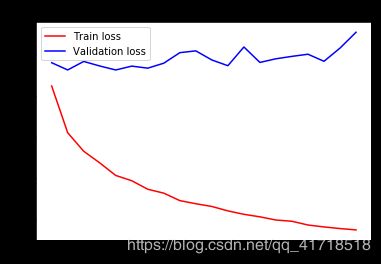 验证集精度不高,因为温度预测对时间的要求很严苛,卷积神经网络在任一序列段学习到的特征都一样
验证集精度不高,因为温度预测对时间的要求很严苛,卷积神经网络在任一序列段学习到的特征都一样
但是温度对较近的数据比较敏感,对较远的数据不敏感
想要结合卷积神经网络的速度和轻量与RNN网络的顺序敏感性,用卷积神经网络做预处理,将其输出作为RNN的输入,这种方式很有效
让我们在温度预测数据集上尝试一下。因为这个策略允许我们操作更长的序列,我们可以查看更早的数据(通过增加数据生成器的lookback参数),或者查看高分辨率时间序列(通过减少生成器的step参数)。在这里,我们将选择使用一个小两倍的step,从而使时间序列延长两倍,其中天气数据的采样率为每30分钟一个点。
step = 3 # 之前为6,表示每小时采样一次。现在为3,表示30分钟采样一次。序列增加一倍
lookback = 720 # Unchanged
delay = 144 # Unchanged
train_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step)
val_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step)
test_gen = generator(float_data,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step)
val_steps = (300000 - 200001 - lookback) // 128
test_steps = (len(float_data) - 300001 - lookback) // 128
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Conv1D(32,5,activation = 'relu',input_shape = (None,float_data.shape[-1])))
model.add(layers.MaxPooling1D(3))
model.add(layers.Conv1D(32,5,activation = 'relu'))
model.add(layers.GRU(32,dropout = 0.1,recurrent_dropout = 0.5))
model.add(layers.Dense(1))
model.summary()
model.compile(optimizer = RMSprop(),loss = 'mae')
history = model.fit_generator(train_gen,steps_per_epoch = 500,epochs = 20,validation_data = val_gen,validation_steps = val_steps)
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1d_24 (Conv1D) (None, None, 32) 2272
_________________________________________________________________
max_pooling1d_17 (MaxPooling (None, None, 32) 0
_________________________________________________________________
conv1d_25 (Conv1D) (None, None, 32) 5152
_________________________________________________________________
gru_2 (GRU) (None, 32) 6240
_________________________________________________________________
dense_6 (Dense) (None, 1) 33
=================================================================
Total params: 13,697
Trainable params: 13,697
Non-trainable params: 0
_________________________________________________________________
Epoch 1/20
500/500 [==============================] - 89s 178ms/step - loss: 0.3393 - val_loss: 0.2874
Epoch 2/20
500/500 [==============================] - 89s 177ms/step - loss: 0.3075 - val_loss: 0.2775
Epoch 3/20
500/500 [==============================] - 87s 175ms/step - loss: 0.2946 - val_loss: 0.2812
Epoch 4/20
500/500 [==============================] - 87s 174ms/step - loss: 0.2873 - val_loss: 0.2960
Epoch 5/20
500/500 [==============================] - 87s 174ms/step - loss: 0.2807 - val_loss: 0.2735
Epoch 6/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2763 - val_loss: 0.2715
Epoch 7/20
500/500 [==============================] - 86s 172ms/step - loss: 0.2707 - val_loss: 0.2878
Epoch 8/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2651 - val_loss: 0.2800
Epoch 9/20
500/500 [==============================] - 86s 172ms/step - loss: 0.2596 - val_loss: 0.2835
Epoch 10/20
500/500 [==============================] - 87s 174ms/step - loss: 0.2577 - val_loss: 0.2775
Epoch 11/20
500/500 [==============================] - 87s 173ms/step - loss: 0.2523 - val_loss: 0.2788
Epoch 12/20
500/500 [==============================] - 87s 174ms/step - loss: 0.2488 - val_loss: 0.2948
Epoch 13/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2438 - val_loss: 0.2872
Epoch 14/20
500/500 [==============================] - 87s 173ms/step - loss: 0.2431 - val_loss: 0.2919
Epoch 15/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2386 - val_loss: 0.2956
Epoch 16/20
500/500 [==============================] - 87s 173ms/step - loss: 0.2372 - val_loss: 0.2952
Epoch 17/20
500/500 [==============================] - 87s 173ms/step - loss: 0.2343 - val_loss: 0.2873
Epoch 18/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2322 - val_loss: 0.2922
Epoch 19/20
500/500 [==============================] - 87s 174ms/step - loss: 0.2290 - val_loss: 0.2987
Epoch 20/20
500/500 [==============================] - 86s 173ms/step - loss: 0.2265 - val_loss: 0.2901
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.plot(epochs,loss,'r',label = 'Train loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('Train and Validation loss')
plt.legend()
plt.show()
小结
1.二维卷积神经网络在二维空间中处理视觉模式时表现很好,与此同时,一维卷积神经网络在处理时间模式时表现也很好。对于某些问题,特别是自然语言处理任务,它可以替代RNN,并且速度更快
2.通常情况下,一维卷积神经网络的架构与计算机视觉领域的二维卷积神经网络很相似,它将Conv1D层和MaxPooling1D层堆叠在一起,最后是一个全局池化运算或展平操作
3.因为RNN在处理非常长的序列时计算代价很大,但一维卷积神经网络的计算代价很小,所以在RNN之前,使用一维卷积神经网络作为预处理是一个不错的选择,这样可以使序列变短,并提取出有用的表示交给RNN来处理
本章总结
一:知识点 1.如何对文本分词
2.什么是词嵌入,如何使用词嵌入
3.什么是循环网络,如何使用循环网络
4.如何堆叠RNN层以及如何使用双向RNN,以构建更强大的序列处理模型
5.如何使用一维卷积神经网络来处理序列
6.如何结合一维卷积神经网络和RNN来处理序列
二:可以用RNN进行时间序列回归(预测未来),时间序列分类,时间序列异常检测和序列标记
三:可以将一维卷积神经网络用于机器翻译(时间到序列的卷积模型,比如SlicNet),文档分类和拼写纠正
四:序列数据的整体顺序很重要的话,那么最好使用循环网络来处理,时间序列通常都是这样,最近的数据可能比久远的数据包含更多的信息量
五:如果整体顺序没有意义,那么一维卷积神经网络可以实现同样好的效果,而且计算代价更小。文本数据通常都是这样,在句首发现关键词和在句尾发现关键词一样都很有意义