《python深度学习》学习笔记与代码实现(第五章)
python深度学习第五章-深度学习用于计算机视觉
5.1 卷积神经网络简介
首先,让我们来实际看看一个非常简单的convnet示例。我们将使用我们的convnet对mnist数字进行分类,这是您在第2章中已经完成的一项任务,使用了一个紧密连接的网络(当时我们的测试精度为97.8%)。即使我们的convnet非常基础,它的准确性会超过第二章密集型连接网络
下面的6行代码向您展示了一个基本的convnet是什么样子的。它是一堆conv2d和maxpooling2d层。我们马上就会看到他们具体做了什么。重要的是,convnet采用形状的输入张量(图像高度、图像宽度、图像通道)(不包括批处理尺寸)。在我们的例子中,我们将配置convnet来处理大小(28,28,1)的输入,这是mnist图像的格式。我们通过将参数输入_shape=(28,28,1)传递给第一层来实现这一点。
# 卷积神经网络对mnist手写数字进行分类
from keras import layers
from keras import models
from keras.datasets import mnist
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 3, 3, 64) 36928
=================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
_________________________________________________________________
# 添加全连接层
# 在进入Dense层之前,(3,3,64)的3维矩阵被展平为形状(576,)的向量
model.add(layers.Flatten())
model.add(layers.Dense(64,activation = 'relu'))
model.add(layers.Dense(10,activation = 'softmax'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
flatten_1 (Flatten) (None, 576) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 36928
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
_________________________________________________________________
如您所见,我们的(3,3,64)输出在经过两个密集层之前被展平为形状向量(576,图1)。
现在,让我们用mnist数字训练我们的convnet。我们将重用许多已经在第2章的mnist示例中介绍过的代码。
# 对标签进行分类编码
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
train_images = train_images.reshape((60000,28,28,1))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000,28,28,1))
test_images = test_images.astype('float32')/255
model.compile(optimizer = 'rmsprop',loss = 'categorical_crossentropy',metrics = ['accuracy'])
model.fit(train_images,train_labels,epochs = 5,batch_size = 64)
Epoch 1/5
60000/60000 [==============================] - 42s 694us/step - loss: 0.1679 - acc: 0.9469
Epoch 2/5
60000/60000 [==============================] - 15s 258us/step - loss: 0.0478 - acc: 0.9849
Epoch 3/5
60000/60000 [==============================] - 16s 261us/step - loss: 0.0332 - acc: 0.9900
Epoch 4/5
60000/60000 [==============================] - 15s 258us/step - loss: 0.0247 - acc: 0.9921
Epoch 5/5
60000/60000 [==============================] - 15s 257us/step - loss: 0.0198 - acc: 0.9940
test_loss,test_acc = model.evaluate(test_images,test_labels)
print('测试集的精确度为:',test_acc)
10000/10000 [==============================] - 2s 152us/step
测试集的精确度为: 0.9918
虽然第2章中的密集连接网络的测试精度为97.8%,但我们的基本convnet的测试精度为99.3%:我们将错误率降低了68%(相对)。
5.2 在小型数据集上从头开始训练一个神经网络
在小数据集上从头开始训练convnet
只有很少的数据来训练一个图像分类模型是一种常见的情况,如果你在专业环境中使用计算机视觉,在实践中你很可能会遇到这种情况。
拥有“很少”的样本可能意味着从几百到数万张图片的任何地方。作为一个实际的例子,我们将把图像分类为“狗”或“猫”,数据集中包含4000张猫和狗的图片(2000只猫,2000只狗)。我们将使用2000张图片进行培训,1000张用于验证,最后1000张用于测试。
在本节中,我们将回顾一个解决这个问题的基本策略:从头开始培训一个新模型,了解我们拥有的数据量很少。我们将从幼稚地在2000个训练样本上训练一个小的convnet开始,而不进行任何正规化,为可以实现的目标设定一个基线。这将使我们的分类精度达到71%。在那一点上,我们的主要问题将是过度拟合。然后我们将介绍数据增强,这是一种减轻计算机视觉中过拟合的强大技术。通过利用数据扩充,我们将改进我们的网络,使其精度达到82%。
在下一节中,我们将回顾将深度学习应用于小数据集的两个更重要的技术:使用预先培训的网络进行特征提取(这将使我们的精度达到90%到93%),以及对预先培训的网络进行微调(这将使我们的最终精度达到95%)。总之,这三个策略——从头开始训练一个小模型,使用预先训练的模型进行特征提取,以及微调预先训练的模型——将构成未来解决使用小数据集进行计算机视觉的问题的工具箱。
深度学习对小数据问题的相关性
有时您会听到,只有在有大量数据可用时,深度学习才有效。这在一定程度上是一个有效的观点:深度学习的一个基本特征是,它能够自己在培训数据中发现有趣的特性,而不需要任何手动特性工程,并且只有在有大量培训示例的情况下才能实现。这对于输入样本是高维的问题尤其适用,比如图像。
然而,对于初学者来说,构成“大量”样本的因素是相对的——相对于您试图训练的网络的大小和深度。用几十个样本训练一个convnet来解决一个复杂的问题是不可能的,但是如果模型很小并且很好地规范化,并且任务很简单,那么几百个样本就可能足够了。由于convnet学习了局部的、翻译不变的特征,因此它们在感知问题上具有很高的数据效率。从零开始在一个非常小的图像数据集上训练convnet仍然会产生合理的结果,尽管相对缺乏数据,但不需要任何定制的特性工程。您将在本节中看到这一点。
但更重要的是,深度学习模型本质上是高度可重用的:例如,您可以采用在大型数据集上训练的图像分类或语音到文本模型,然后在显著不同的问题上重用它,只需进行微小的更改。具体来说,在计算机视觉的情况下,许多预先培训的模型(通常在ImageNet数据集上培训)现在可以公开下载,并且可以用于从非常少的数据中引导强大的视觉模型。这就是我们将在下一节中要做的。
现在,让我们从掌握数据开始。
我们使用的是Kaggle上的猫狗分类数据集,下载连接:https://www.kaggle.com/c/dogs-vs-cats/data
下面是代码实现,首先我们要从总体的样本中挑出一少部分样本
# 使用小的猫狗 数据集进行卷积的示例
import os,shutil
original_dataset_dir = r'D:\study\Python\Deeplearning\ch5\dogs-vs-cats\train\train'
base_dir = r'D:\study\Python\Deeplearning\ch5\sampledata'
os.mkdir(base_dir)
train_dir = os.path.join(base_dir,"train")
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir,'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir,'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir,'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir,'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir,'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir,'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir,'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir,'dogs')
os.mkdir(test_dogs_dir)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_cats_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1000,1500)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_dogs_dir,fname)
shutil.copyfile(src,dst)
fnames = ['dog.{}.jpg'.format(i) for i in range(1500,2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_dogs_dir,fname)
shutil.copyfile(src,dst)
print('total training cat images:',len(os.listdir(train_cats_dir)))
print('total training dog images:',len(os.listdir(train_dogs_dir)))
print('total validation cat images:',len(os.listdir(validation_cats_dir)))
print('total validation dog images:',len(os.listdir(validation_dogs_dir)))
print('total test cat images:',len(os.listdir(test_cats_dir)))
print('total test dog images:',len(os.listdir(test_dogs_dir)))
total training cat images: 1000
total training dog images: 1000
total validation cat images: 500
total validation dog images: 500
total test cat images: 500
total test dog images: 500
建立我们的网络
在前面的示例中,我们已经为mnist构建了一个小型convnet,因此您应该熟悉它们。我们将重用相同的通用结构:我们的convnet将是一个交替的conv2d(带有relu激活)和maxpooling2d层的堆叠。
然而,由于我们处理的是更大的图像和更复杂的问题,我们将相应地扩大我们的网络:它将有一个更大的conv2d+maxpooling2d阶段。这既有助于增强网络的容量,也有助于进一步减小功能图的大小,这样当我们到达Flatten层时,它们就不会太大。这里,由于我们从150x150大小的输入(有点随意的选择)开始,我们最终得到了在展平层之前的7x7大小的特征图。
请注意,特征图的深度在网络中逐渐增加(从32到128),而特征图的尺寸在减小(从148x148到7x7)。这是您将在几乎所有convnet中看到的模式。
由于这是一个二元分类问题,所以我们用一个单元(一个大小为1的致密层)和一个Sigmoid激活函数来结束网络。这个单元将对网络查看一个类或另一个类的概率进行编码。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
from keras import optimizers
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),metrics = ['acc'])
数据预处理
正如您现在已经知道的,在将数据送入我们的网络之前,应该将其格式化为适当的预处理浮点张量。目前,我们的数据以jpeg文件的形式存放在驱动器上,因此将其放入网络的步骤大致如下:
1.阅读图片文件。
2.将jpeg内容解码为像素的RBG网格。
3.把它们转换成浮点张量。
4.将像素值(介于0和255之间)重新调整为[0,1]间隔(如您所知,神经网络更喜欢处理较小的输入值)。
这看起来有点让人望而生畏,但谢天谢地,Keras拥有自动处理这些步骤的实用程序。keras有一个带有图像处理助手工具的模块,位于keras.preprocessing.image。特别是,它包含了ImageDataGenerator类,它允许快速设置python生成器,该生成器可以自动将磁盘上的图像文件转换为批预处理张量。这就是我们在这里要用到的。
# 数据预处理,将jpg格式的图片要转换成rgb三通道的形式
from keras.preprocessing.image import ImageDataGenerator
# from keras.preprocessing.image import img_to_array
# 将多有图像乘以1/255进行缩放
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 将所有图像的大小调整为150*150
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
for data_batch, labels_batch in validation_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch.shape)
break
data batch shape: (20, 150, 150, 3)
labels batch shape: (20,)
开始训练模型
history = model.fit_generator(train_generator,steps_per_epoch = 100,epochs = 30,validation_data = validation_generator,validation_steps = 50)
Epoch 1/30
100/100 [==============================] - 9s - loss: 0.6898 - acc: 0.5285 - val_loss: 0.6724 - val_acc: 0.5950
Epoch 2/30
100/100 [==============================] - 8s - loss: 0.6543 - acc: 0.6340 - val_loss: 0.6565 - val_acc: 0.5950
Epoch 3/30
100/100 [==============================] - 8s - loss: 0.6143 - acc: 0.6690 - val_loss: 0.6116 - val_acc: 0.6650
Epoch 4/30
100/100 [==============================] - 8s - loss: 0.5626 - acc: 0.7125 - val_loss: 0.5774 - val_acc: 0.6970
Epoch 5/30
100/100 [==============================] - 8s - loss: 0.5266 - acc: 0.7335 - val_loss: 0.5726 - val_acc: 0.6960
Epoch 6/30
100/100 [==============================] - 8s - loss: 0.5007 - acc: 0.7550 - val_loss: 0.6075 - val_acc: 0.6580
Epoch 7/30
100/100 [==============================] - 8s - loss: 0.4723 - acc: 0.7840 - val_loss: 0.5516 - val_acc: 0.7060
Epoch 8/30
100/100 [==============================] - 8s - loss: 0.4521 - acc: 0.7875 - val_loss: 0.5724 - val_acc: 0.6980
Epoch 9/30
100/100 [==============================] - 8s - loss: 0.4163 - acc: 0.8095 - val_loss: 0.5653 - val_acc: 0.7140
Epoch 10/30
100/100 [==============================] - 8s - loss: 0.3988 - acc: 0.8185 - val_loss: 0.5508 - val_acc: 0.7180
Epoch 11/30
100/100 [==============================] - 8s - loss: 0.3694 - acc: 0.8385 - val_loss: 0.5712 - val_acc: 0.7300
Epoch 12/30
100/100 [==============================] - 8s - loss: 0.3385 - acc: 0.8465 - val_loss: 0.6097 - val_acc: 0.7110
Epoch 13/30
100/100 [==============================] - 8s - loss: 0.3229 - acc: 0.8565 - val_loss: 0.5827 - val_acc: 0.7150
Epoch 14/30
100/100 [==============================] - 8s - loss: 0.2962 - acc: 0.8720 - val_loss: 0.5928 - val_acc: 0.7190
Epoch 15/30
100/100 [==============================] - 8s - loss: 0.2684 - acc: 0.9005 - val_loss: 0.5921 - val_acc: 0.7190
Epoch 16/30
100/100 [==============================] - 8s - loss: 0.2509 - acc: 0.8980 - val_loss: 0.6148 - val_acc: 0.7250
Epoch 17/30
100/100 [==============================] - 8s - loss: 0.2221 - acc: 0.9110 - val_loss: 0.6487 - val_acc: 0.7010
Epoch 18/30
100/100 [==============================] - 8s - loss: 0.2021 - acc: 0.9250 - val_loss: 0.6185 - val_acc: 0.7300
Epoch 19/30
100/100 [==============================] - 8s - loss: 0.1824 - acc: 0.9310 - val_loss: 0.7713 - val_acc: 0.7020
Epoch 20/30
100/100 [==============================] - 8s - loss: 0.1579 - acc: 0.9425 - val_loss: 0.6657 - val_acc: 0.7260
Epoch 21/30
100/100 [==============================] - 8s - loss: 0.1355 - acc: 0.9550 - val_loss: 0.8077 - val_acc: 0.7040
Epoch 22/30
100/100 [==============================] - 8s - loss: 0.1247 - acc: 0.9545 - val_loss: 0.7726 - val_acc: 0.7080
Epoch 23/30
100/100 [==============================] - 8s - loss: 0.1111 - acc: 0.9585 - val_loss: 0.7387 - val_acc: 0.7220
Epoch 24/30
100/100 [==============================] - 8s - loss: 0.0932 - acc: 0.9710 - val_loss: 0.8196 - val_acc: 0.7050
Epoch 25/30
100/100 [==============================] - 8s - loss: 0.0707 - acc: 0.9790 - val_loss: 0.9012 - val_acc: 0.7190
Epoch 26/30
100/100 [==============================] - 8s - loss: 0.0625 - acc: 0.9855 - val_loss: 1.0437 - val_acc: 0.6970
Epoch 27/30
100/100 [==============================] - 8s - loss: 0.0611 - acc: 0.9820 - val_loss: 0.9831 - val_acc: 0.7060
Epoch 28/30
100/100 [==============================] - 8s - loss: 0.0488 - acc: 0.9865 - val_loss: 0.9721 - val_acc: 0.7310
Epoch 29/30
100/100 [==============================] - 8s - loss: 0.0375 - acc: 0.9915 - val_loss: 0.9987 - val_acc: 0.7100
Epoch 30/30
100/100 [==============================] - 8s - loss: 0.0387 - acc: 0.9895 - val_loss: 1.0139 - val_acc: 0.7240
保存这个模型
model.save('cats_and_dogs_small_1.h5')
画出训练集和测试集的精度和损失
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()


使用数据增强
过拟合是由于样本太少而导致的,这使得我们无法训练一个能够归纳为新数据的模型。假设有无限的数据,我们的模型将暴露在手头数据分布的每一个可能方面:我们永远不会过度拟合。数据增强采用从现有训练样本生成更多训练数据的方法,通过一些随机转换“增强”样本,生成可信的图像。我们的目标是,在训练时,我们的模型不会看到完全相同的图片两次。这有助于模型观察更多的数据,并有更好的泛化能力。
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
# 使用图像增强来得到更多的样本
from keras.preprocessing import image
fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)]
# 选择一张图片进行增强
img_path = fname[3]
# 读取图像并调整大小
img = image.load_img(img_path,target_size = (150,150))
# 将其转换为(150,150,3)的numpy数组
x = image.img_to_array(img)
# 将其形状变为(1,150,150,3)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x,batch_size = 1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i%4 == 0:
break
plt.show()
如果我们使用这个数据扩充配置训练一个新的网络,我们的网络将永远看不到相同的输入。然而,它所看到的输入仍然是相互关联的,因为它们来自少数原始图像——我们不能产生新的信息,我们只能重新混合现有的信息。因此,这可能不足以完全消除过拟合。为了进一步防止过度拟合,我们还将在模型中添加一个Dropout层,就在密接分类器之前:
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation = 'relu',input_shape = (150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation = 'relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(loss = 'binary_crossentropy',optimizer = optimizers.RMSprop(lr = 1e-4),metrics = ['acc'])
train_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,)
# 不能增强测试数据
test_datagen = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(train_generator,steps_per_epoch = 100,epochs = 30,validation_data = validation_generator,validation_steps = 50)
Found 1000 images belonging to 2 classes.
Epoch 1/30
100/100 [==============================] - 35s 351ms/step - loss: 0.6842 - acc: 0.5434 - val_loss: 0.6537 - val_acc: 0.6140
Epoch 2/30
100/100 [==============================] - 32s 317ms/step - loss: 0.6588 - acc: 0.6062 - val_loss: 0.6808 - val_acc: 0.5780
Epoch 3/30
100/100 [==============================] - 33s 327ms/step - loss: 0.6499 - acc: 0.6175 - val_loss: 0.6364 - val_acc: 0.6350
Epoch 4/30
100/100 [==============================] - 33s 326ms/step - loss: 0.6359 - acc: 0.6328 - val_loss: 0.6862 - val_acc: 0.5920
Epoch 5/30
100/100 [==============================] - 34s 338ms/step - loss: 0.6247 - acc: 0.6306 - val_loss: 0.5617 - val_acc: 0.7090
Epoch 6/30
100/100 [==============================] - 33s 331ms/step - loss: 0.6045 - acc: 0.6575 - val_loss: 0.6276 - val_acc: 0.6440
Epoch 7/30
100/100 [==============================] - 34s 335ms/step - loss: 0.5972 - acc: 0.6681 - val_loss: 0.5271 - val_acc: 0.7300
Epoch 8/30
100/100 [==============================] - 35s 346ms/step - loss: 0.5790 - acc: 0.6869 - val_loss: 0.5360 - val_acc: 0.7190
Epoch 9/30
100/100 [==============================] - 33s 326ms/step - loss: 0.5672 - acc: 0.6912 - val_loss: 0.5047 - val_acc: 0.7570
Epoch 10/30
100/100 [==============================] - 32s 325ms/step - loss: 0.5699 - acc: 0.6884 - val_loss: 0.5287 - val_acc: 0.7190
Epoch 11/30
100/100 [==============================] - 32s 322ms/step - loss: 0.5535 - acc: 0.7031 - val_loss: 0.6483 - val_acc: 0.6440
Epoch 12/30
100/100 [==============================] - 34s 340ms/step - loss: 0.5483 - acc: 0.7109 - val_loss: 0.4674 - val_acc: 0.7900
Epoch 13/30
100/100 [==============================] - 33s 333ms/step - loss: 0.5537 - acc: 0.7032 - val_loss: 0.4692 - val_acc: 0.7860
Epoch 14/30
100/100 [==============================] - 34s 336ms/step - loss: 0.5424 - acc: 0.7094 - val_loss: 0.4828 - val_acc: 0.7550
Epoch 15/30
100/100 [==============================] - 33s 335ms/step - loss: 0.5230 - acc: 0.7394 - val_loss: 0.4468 - val_acc: 0.7890
Epoch 16/30
100/100 [==============================] - 34s 338ms/step - loss: 0.5283 - acc: 0.7219 - val_loss: 0.4575 - val_acc: 0.7840
Epoch 17/30
100/100 [==============================] - 32s 323ms/step - loss: 0.5184 - acc: 0.7306 - val_loss: 0.4436 - val_acc: 0.7950
Epoch 18/30
100/100 [==============================] - 33s 328ms/step - loss: 0.5147 - acc: 0.7422 - val_loss: 0.4373 - val_acc: 0.7970
Epoch 19/30
100/100 [==============================] - 33s 330ms/step - loss: 0.5038 - acc: 0.7503 - val_loss: 0.4435 - val_acc: 0.8000
Epoch 20/30
100/100 [==============================] - 33s 332ms/step - loss: 0.5025 - acc: 0.7475 - val_loss: 0.4292 - val_acc: 0.7950
Epoch 21/30
100/100 [==============================] - 33s 330ms/step - loss: 0.4913 - acc: 0.7531 - val_loss: 0.4118 - val_acc: 0.8180
Epoch 22/30
100/100 [==============================] - 33s 330ms/step - loss: 0.4936 - acc: 0.7541 - val_loss: 0.4381 - val_acc: 0.7920
Epoch 23/30
100/100 [==============================] - 35s 348ms/step - loss: 0.4857 - acc: 0.7612 - val_loss: 0.4436 - val_acc: 0.7820
Epoch 24/30
100/100 [==============================] - 35s 351ms/step - loss: 0.4925 - acc: 0.7538 - val_loss: 0.4929 - val_acc: 0.7410
Epoch 25/30
100/100 [==============================] - 32s 322ms/step - loss: 0.4746 - acc: 0.7594 - val_loss: 0.4174 - val_acc: 0.7980
Epoch 26/30
100/100 [==============================] - 32s 324ms/step - loss: 0.4779 - acc: 0.7672 - val_loss: 0.4333 - val_acc: 0.8130
Epoch 27/30
100/100 [==============================] - 33s 327ms/step - loss: 0.4611 - acc: 0.7825 - val_loss: 0.3700 - val_acc: 0.8380
Epoch 28/30
100/100 [==============================] - 36s 360ms/step - loss: 0.4662 - acc: 0.7775 - val_loss: 0.4069 - val_acc: 0.8120
Epoch 29/30
100/100 [==============================] - 37s 372ms/step - loss: 0.4589 - acc: 0.7822 - val_loss: 0.3784 - val_acc: 0.8250
Epoch 30/30
100/100 [==============================] - 35s 346ms/step - loss: 0.4598 - acc: 0.7797 - val_loss: 0.3617 - val_acc: 0.8350
保存模型
model.save('cats_and_dogs_small_2.h5')
画出这个模型的训练集和交叉验证集的精度和损失
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc) + 1)
plt.plot(epochs,acc,'r',label = 'Traning acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('training and validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'r',label = 'Traning loss')
plt.plot(epochs,val_loss,'b',label = 'Validation loss')
plt.title('training and validation loss')
plt.legend()
plt.show()
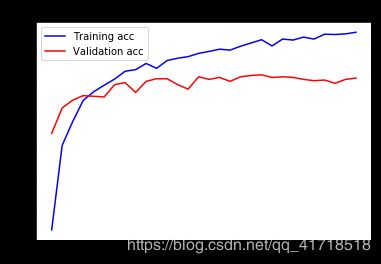
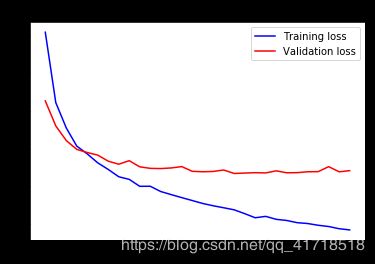
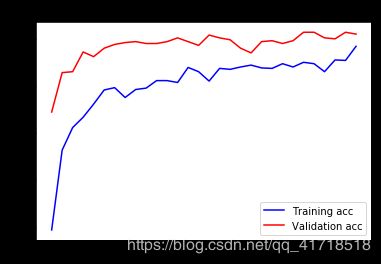
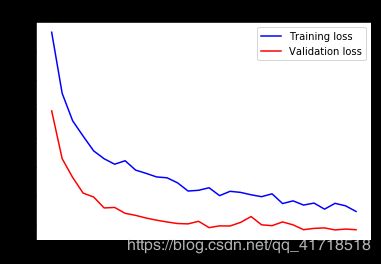
通过进一步利用正则化技术和调整网络参数(如每个卷积层的滤波器数量或网络中的层数),我们可能能够获得更高的精度,可能高达86-87%。然而,仅仅通过从头开始训练我们自己的convnet就很难再提高了,这仅仅是因为我们的数据太少了。
作为提高这个问题准确性的下一步,我们将不得不利用一个经过预先培训的模型,这将是接下来两个部分的重点。
5.3 使用预训练的卷积神经网络
使用预训练好的模型,有两个种方法可以让我们使用现有模型
1.在数据集上运行卷积基,将其输出记录到磁盘上的一个numpy数组中,然后将这些数据作为独立的、紧密连接的分类器的输入,
类似于本书第一章中所看到的那样。这个解决方案运行起来非常快速和便宜,因为它只需要对每个输入图像运行一次卷积基,
而卷积基是迄今为止管道中最昂贵的部分。然而,出于完全相同的原因,这种技术根本不允许我们利用数据扩充
2.扩展我们的模型(conv_-base),在顶部添加密集层,并在输入数据上端到端地运行整个模型。
这允许我们使用数据增强,因为每次模型看到每个输入图像都要经过卷积基。
然而,出于同样的原因,这种技术要比第一种技术昂贵得多。
让我们来浏览设置第一个模型所需的代码:根据我们的数据记录conv_的输出,并将这些输出用作新模型的输入。
我们将首先简单地运行先前引入的ImageDataGenerator的实例,以提取作为numpy数组及其标签的图像。
我们将通过调用conv_基模型的预测方法从这些图像中提取特征。
import os
os.environ['CUDA_VISIBLE_DEVICES'] = "0"
# os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# 使用与训练的卷积神经网络,迁移学习,keras包含了很多已经训练好的经典的网络,可以直接导入
from keras.applications import VGG16
# include_top指导入的模型中是否包含全连接层(分类层)
conv_base = VGG16(weights = 'imagenet',include_top = False,input_shape = (150,150,3))
# 下一步,有两种方法可供选择
# 1,在数据集上运行卷积基,将其输出记录到磁盘上的一个numpy数组中,
# 然后将这些数据作为一个独立的、紧密连接的分类器的输入,类似于本书第一章中看到的那样。
# 这个解决方案运行起来非常快速和便宜,因为它只需要对每个输入图像运行一次卷积基,
# 而卷积基是迄今为止管道中最昂贵的部分。然而,出于完全相同的原因,这种技术根本不允许我们利用数据增强。
# 2扩展我们的模型(conv_-base),在顶部添加密集层,并在输入数据上端到端地运行整个模型。这允许我们使用数据增强,
# 因为每次模型看到每个输入图像都要经过卷积基。然而,出于同样的原因,这种技术要比第一种技术昂贵得多。
# 第一种方法
import os
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
base_dir = r'D:\study\Python\Deeplearning\ch5\sampledata'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
datagen = ImageDataGenerator(rescale=1./255)
batch_size = 20
def extract_features(directory, sample_count):
features = np.zeros(shape=(sample_count, 4, 4, 512))
labels = np.zeros(shape=(sample_count))
generator = datagen.flow_from_directory(
directory,
target_size=(150, 150),
batch_size=batch_size,
class_mode='binary')
i = 0
for inputs_batch, labels_batch in generator:
features_batch = conv_base.predict(inputs_batch)
features[i * batch_size : (i + 1) * batch_size] = features_batch
labels[i * batch_size : (i + 1) * batch_size] = labels_batch
i += 1
if i * batch_size >= sample_count:
# Note that since generators yield data indefinitely in a loop,
# we must `break` after every image has been seen once.
break
return features, labels
train_features, train_labels = extract_features(train_dir, 2000)
validation_features, validation_labels = extract_features(validation_dir, 1000)
test_features, test_labels = extract_features(test_dir, 1000)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
# 提取的特征目前是形状的(sample,4,4,512)。我们将把它们送入一个紧密相连的分类器,因此首先我们必须将它们展平到(sample,8192):
train_features = np.reshape(train_features,(2000,4*4*512))
validation_features = np.reshape(validation_features,(1000,4*4*512))
test_features = np.reshape(test_features,(1000,4*4*512))
# 定义并训练密集型分类器
from keras import models
from keras import layers
from keras import optimizers
model = models.Sequential()
model.add(layers.Dense(256,activation = 'relu',input_dim = 4*4*512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.compile(optimizer = optimizers.RMSprop(lr = 2e-5),loss = 'binary_crossentropy',metrics = ['acc'])
history = model.fit(train_features,train_labels,
epochs = 30,
batch_size = 20,
validation_data = (validation_features,validation_labels))
Train on 2000 samples, validate on 1000 samples
Epoch 1/30
2000/2000 [==============================] - 4s 2ms/step - loss: 0.6080 - acc: 0.6715 - val_loss: 0.4262 - val_acc: 0.8200
Epoch 2/30
2000/2000 [==============================] - 2s 944us/step - loss: 0.4216 - acc: 0.8015 - val_loss: 0.3599 - val_acc: 0.8590
Epoch 3/30
2000/2000 [==============================] - 2s 954us/step - loss: 0.3546 - acc: 0.8380 - val_loss: 0.3212 - val_acc: 0.8710
Epoch 4/30
2000/2000 [==============================] - 2s 943us/step - loss: 0.3065 - acc: 0.8705 - val_loss: 0.2978 - val_acc: 0.8780
Epoch 5/30
2000/2000 [==============================] - 2s 949us/step - loss: 0.2858 - acc: 0.8840 - val_loss: 0.2895 - val_acc: 0.8770
Epoch 6/30
2000/2000 [==============================] - 2s 919us/step - loss: 0.2621 - acc: 0.8940 - val_loss: 0.2826 - val_acc: 0.8760
Epoch 7/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.2447 - acc: 0.9035 - val_loss: 0.2666 - val_acc: 0.8950
Epoch 8/30
2000/2000 [==============================] - 2s 956us/step - loss: 0.2254 - acc: 0.9155 - val_loss: 0.2586 - val_acc: 0.8980
Epoch 9/30
2000/2000 [==============================] - 2s 940us/step - loss: 0.2184 - acc: 0.9180 - val_loss: 0.2679 - val_acc: 0.8830
Epoch 10/30
2000/2000 [==============================] - 2s 990us/step - loss: 0.2000 - acc: 0.9275 - val_loss: 0.2516 - val_acc: 0.9000
Epoch 11/30
2000/2000 [==============================] - 2s 990us/step - loss: 0.2002 - acc: 0.9200 - val_loss: 0.2476 - val_acc: 0.9040
Epoch 12/30
2000/2000 [==============================] - 2s 940us/step - loss: 0.1862 - acc: 0.9320 - val_loss: 0.2470 - val_acc: 0.9040
Epoch 13/30
2000/2000 [==============================] - 2s 926us/step - loss: 0.1780 - acc: 0.9355 - val_loss: 0.2487 - val_acc: 0.8950
Epoch 14/30
2000/2000 [==============================] - 2s 970us/step - loss: 0.1701 - acc: 0.9380 - val_loss: 0.2523 - val_acc: 0.8880
Epoch 15/30
2000/2000 [==============================] - 2s 942us/step - loss: 0.1624 - acc: 0.9430 - val_loss: 0.2398 - val_acc: 0.9070
Epoch 16/30
2000/2000 [==============================] - 2s 960us/step - loss: 0.1546 - acc: 0.9460 - val_loss: 0.2386 - val_acc: 0.9030
Epoch 17/30
2000/2000 [==============================] - 2s 961us/step - loss: 0.1485 - acc: 0.9495 - val_loss: 0.2394 - val_acc: 0.9060
Epoch 18/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1433 - acc: 0.9480 - val_loss: 0.2432 - val_acc: 0.9000
Epoch 19/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1378 - acc: 0.9540 - val_loss: 0.2340 - val_acc: 0.9070
Epoch 20/30
2000/2000 [==============================] - 2s 1ms/step - loss: 0.1277 - acc: 0.9590 - val_loss: 0.2351 - val_acc: 0.9090
Epoch 21/30
2000/2000 [==============================] - 2s 991us/step - loss: 0.1168 - acc: 0.9640 - val_loss: 0.2362 - val_acc: 0.9100
Epoch 22/30
2000/2000 [==============================] - 2s 966us/step - loss: 0.1205 - acc: 0.9545 - val_loss: 0.2355 - val_acc: 0.9060
Epoch 23/30
2000/2000 [==============================] - 2s 971us/step - loss: 0.1126 - acc: 0.9650 - val_loss: 0.2410 - val_acc: 0.9070
Epoch 24/30
2000/2000 [==============================] - 2s 932us/step - loss: 0.1096 - acc: 0.9635 - val_loss: 0.2359 - val_acc: 0.9060
Epoch 25/30
2000/2000 [==============================] - 2s 924us/step - loss: 0.1037 - acc: 0.9680 - val_loss: 0.2362 - val_acc: 0.9030
Epoch 26/30
2000/2000 [==============================] - 2s 966us/step - loss: 0.1015 - acc: 0.9650 - val_loss: 0.2386 - val_acc: 0.9010
Epoch 27/30
2000/2000 [==============================] - 2s 951us/step - loss: 0.0969 - acc: 0.9725 - val_loss: 0.2389 - val_acc: 0.9020
Epoch 28/30
2000/2000 [==============================] - 2s 951us/step - loss: 0.0936 - acc: 0.9720 - val_loss: 0.2521 - val_acc: 0.8970
Epoch 29/30
2000/2000 [==============================] - 2s 937us/step - loss: 0.0878 - acc: 0.9730 - val_loss: 0.2385 - val_acc: 0.9030
Epoch 30/30
2000/2000 [==============================] - 2s 969us/step - loss: 0.0846 - acc: 0.9755 - val_loss: 0.2415 - val_acc: 0.9050
# 画出其精度和损失函数
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(acc)+1)
plt.plot(epochs,acc,'b',label = 'Training acc')
plt.plot(epochs,val_acc,'r',label = 'Validation acc')
plt.title('Training and Validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'b',label = 'Training loss')
plt.plot(epochs,val_loss,'r',label = 'Validation loss')
plt.title('Training and Validation loss')
plt.legend()
plt.show()
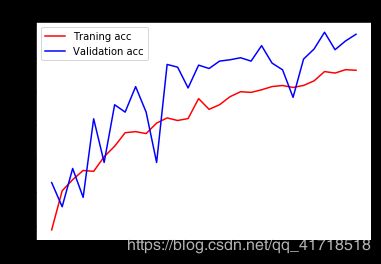
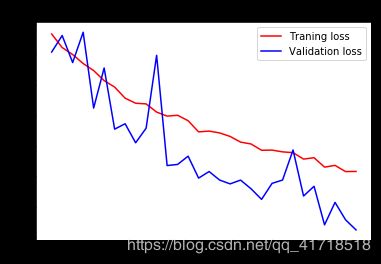
我们的验证精度达到了90%左右,比我们在前一节中从零开始训练的小模型所能达到的效果要好得多。然而,我们的曲线图也表明,我们几乎从一开始就过度拟合了——尽管使用辍学率相当高。这是因为该技术不利用数据扩充,这对于防止对小图像数据集的过度拟合至关重要。
第二种方法
现在,让我们回顾一下我们提到的第二种进行特征提取的技术,它速度慢得多,成本也高,但是它允许我们在培训期间利用数据扩充:扩展conv_基础模型,并在输入端到端地运行它。请注意,这项技术实际上非常昂贵,所以只有在您有权访问GPU的情况下才应该尝试它:它在CPU上是绝对难以处理的。如果你不能在GPU上运行你的代码,那么前面的技术就是方法。
因为模型的行为与层类似,所以可以向顺序模型添加模型(如conv_库),就像添加层一样。因此,您可以执行以下操作:
# 第二种方法,在已有模型后加入自己定义的层,但是需要注意冻结参数
from keras import models
from keras import layers
model = models.Sequential()
# conv_base为刚才导入的VGG16网络
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256,activation = 'relu'))
model.add(layers.Dense(1,activation = 'sigmoid'))
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Model) (None, 4, 4, 512) 14714688
_________________________________________________________________
flatten_1 (Flatten) (None, 8192) 0
_________________________________________________________________
dense_3 (Dense) (None, 256) 2097408
_________________________________________________________________
dense_4 (Dense) (None, 1) 257
=================================================================
Total params: 16,812,353
Trainable params: 16,812,353
Non-trainable params: 0
_________________________________________________________________
冻结VGG16的参数,只训练我们添加的那两层
print('This is the number of trainable weights','before freezing the conv_base:',len(model.trainable_weights))
conv_base.trainable = False
print('This is the number of trainable weights','after freezing the conv_base:',len(model.trainable_weights))
This is the number of trainable weights before freezing the conv_base: 30
This is the number of trainable weights after freezing the conv_base: 4
# 数据预处理
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
train_datagen = ImageDataGenerator(rescale = 1./255,
rotation_range = 40,
width_shift_range = 0.2,
height_shift_range = 0.2,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
fill_mode = 'nearest'
)
test_generator = ImageDataGenerator(rescale = 1./255)
train_generator = train_datagen.flow_from_directory(train_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary'
)
validation_generator = test_generator.flow_from_directory(
validation_dir,
target_size = (150,150),
batch_size = 20,
class_mode = 'binary'
)
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
model.compile(loss = 'binary_crossentropy',
optimizer = optimizers.RMSprop(lr = 2e-5),
metrics = ['acc'])
history = model.fit_generator(train_generator,
steps_per_epoch = 100,
epochs = 30,
validation_data = validation_generator,
validation_steps = 50)
Epoch 1/30
100/100 [==============================] - 60s 605ms/step - loss: 0.5822 - acc: 0.6965 - val_loss: 0.4469 - val_acc: 0.8220
Epoch 2/30
100/100 [==============================] - 60s 595ms/step - loss: 0.4771 - acc: 0.7815 - val_loss: 0.3647 - val_acc: 0.8640
Epoch 3/30
100/100 [==============================] - 60s 596ms/step - loss: 0.4298 - acc: 0.8055 - val_loss: 0.3323 - val_acc: 0.8650
Epoch 4/30
100/100 [==============================] - 60s 597ms/step - loss: 0.4034 - acc: 0.8165 - val_loss: 0.3054 - val_acc: 0.8860
Epoch 5/30
100/100 [==============================] - 60s 596ms/step - loss: 0.3781 - acc: 0.8305 - val_loss: 0.2987 - val_acc: 0.8810
Epoch 6/30
100/100 [==============================] - 59s 595ms/step - loss: 0.3645 - acc: 0.8455 - val_loss: 0.2799 - val_acc: 0.8900
Epoch 7/30
100/100 [==============================] - 60s 598ms/step - loss: 0.3552 - acc: 0.8480 - val_loss: 0.2808 - val_acc: 0.8940
Epoch 8/30
100/100 [==============================] - 60s 596ms/step - loss: 0.3611 - acc: 0.8375 - val_loss: 0.2707 - val_acc: 0.8960
Epoch 9/30
100/100 [==============================] - 59s 593ms/step - loss: 0.3450 - acc: 0.8460 - val_loss: 0.2671 - val_acc: 0.8970
Epoch 10/30
100/100 [==============================] - 60s 596ms/step - loss: 0.3394 - acc: 0.8475 - val_loss: 0.2625 - val_acc: 0.8950
Epoch 11/30
100/100 [==============================] - 59s 592ms/step - loss: 0.3332 - acc: 0.8555 - val_loss: 0.2588 - val_acc: 0.8950
Epoch 12/30
100/100 [==============================] - 60s 598ms/step - loss: 0.3318 - acc: 0.8555 - val_loss: 0.2557 - val_acc: 0.8970
Epoch 13/30
100/100 [==============================] - 59s 593ms/step - loss: 0.3230 - acc: 0.8535 - val_loss: 0.2531 - val_acc: 0.9010
Epoch 14/30
100/100 [==============================] - 59s 594ms/step - loss: 0.3090 - acc: 0.8695 - val_loss: 0.2525 - val_acc: 0.8970
Epoch 15/30
100/100 [==============================] - 60s 601ms/step - loss: 0.3103 - acc: 0.8650 - val_loss: 0.2569 - val_acc: 0.8930
Epoch 16/30
100/100 [==============================] - 60s 596ms/step - loss: 0.3146 - acc: 0.8550 - val_loss: 0.2460 - val_acc: 0.9040
Epoch 17/30
100/100 [==============================] - 59s 593ms/step - loss: 0.3010 - acc: 0.8685 - val_loss: 0.2491 - val_acc: 0.9010
Epoch 18/30
100/100 [==============================] - 59s 594ms/step - loss: 0.3085 - acc: 0.8675 - val_loss: 0.2489 - val_acc: 0.8990
Epoch 19/30
100/100 [==============================] - 59s 595ms/step - loss: 0.3067 - acc: 0.8700 - val_loss: 0.2550 - val_acc: 0.8900
Epoch 20/30
100/100 [==============================] - 60s 599ms/step - loss: 0.3025 - acc: 0.8720 - val_loss: 0.2651 - val_acc: 0.8850
Epoch 21/30
100/100 [==============================] - 59s 593ms/step - loss: 0.2993 - acc: 0.8690 - val_loss: 0.2509 - val_acc: 0.8970
Epoch 22/30
100/100 [==============================] - 59s 590ms/step - loss: 0.3042 - acc: 0.8685 - val_loss: 0.2494 - val_acc: 0.8980
Epoch 23/30
100/100 [==============================] - 59s 594ms/step - loss: 0.2875 - acc: 0.8735 - val_loss: 0.2558 - val_acc: 0.8950
Epoch 24/30
100/100 [==============================] - 59s 594ms/step - loss: 0.2921 - acc: 0.8700 - val_loss: 0.2508 - val_acc: 0.8980
Epoch 25/30
100/100 [==============================] - 59s 593ms/step - loss: 0.2849 - acc: 0.8750 - val_loss: 0.2425 - val_acc: 0.9070
Epoch 26/30
100/100 [==============================] - 59s 594ms/step - loss: 0.2882 - acc: 0.8735 - val_loss: 0.2447 - val_acc: 0.9070
Epoch 27/30
100/100 [==============================] - 60s 595ms/step - loss: 0.2778 - acc: 0.8650 - val_loss: 0.2455 - val_acc: 0.9010
Epoch 28/30
100/100 [==============================] - 60s 601ms/step - loss: 0.2878 - acc: 0.8775 - val_loss: 0.2421 - val_acc: 0.9000
Epoch 29/30
100/100 [==============================] - 60s 597ms/step - loss: 0.2836 - acc: 0.8770 - val_loss: 0.2435 - val_acc: 0.9070
Epoch 30/30
100/100 [==============================] - 62s 624ms/step - loss: 0.2739 - acc: 0.8920 - val_loss: 0.2424 - val_acc: 0.9050
model.save('cats_and_dogs_small_3.h5')
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,'b',label = 'Training acc')
plt.plot(epochs,val_acc,'r',label = 'Validation acc')
plt.title('Train and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'b',label = "Training loss")
plt.plot(epochs,val_loss,'r',label = 'Validation loss')
plt.title('Train and Validation loss')
plt.legend()
plt.show()
微调
另一种广泛使用的模型重用技术(与特征提取互补)是微调。微调包括解冻用于特征提取的冻结模型库的一些顶层,并联合训练模型的新添加部分(在我们的例子中,是完全连接的分类器)和这些顶层。这被称为“微调”,因为它稍微调整了被重用模型的更抽象的表示,以便使它们与手头的问题更相关。 我们之前已经说过,为了能够在顶部训练一个随机初始化的分类器,有必要冻结VGG16的卷积基。出于同样的原因,只有在对顶部分类器进行了训练之后,才能对卷积基的顶层进行微调。如果分类没有经过训练,那么在训练过程中通过网络传播的错误信号将太大,并且先前由被微调的层学习的表示将被破坏。因此,对网络进行微调的步骤如下: 1)将您的自定义网络添加到已培训的基础网络之上。 2)冻结基础网络。 3)培训您添加的部件。 4)解冻基础网络中的某些层。 5)共同训练这些层和添加的零件。 在进行特征提取时,我们已经完成了前3个步骤。让我们继续第四步:我们将解冻conv_基地,然后冻结里面的各个层。 作为提醒,这就是我们的卷积基的样子:
conv_base.summary()
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 150, 150, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
________________________________________________________________
我们将对最后3个卷积层进行微调,这意味着在Block4_池冻结之前的所有层,并且可以训练Block5_Conv1、Block5_Conv2和Block5_Conv3层。 为什么不微调更多层?为什么不微调整个卷积基呢?我们可以。但是,我们需要考虑:
卷积基中的早期层编码更通用、可重用的特性,而更高层编码更专业的特性。对更专业的特性进行微调更有用,因为这些特性是需要针对新问题重新调整用途的特性。在微调较低层时,会有快速降低的回报。
我们训练的参数越多,就越有过度拟合的风险。卷积基有1500万个参数,因此尝试在我们的小数据集上训练它是有风险的。 因此,在我们的情况下,只对卷积基中的前2到3层进行微调是一个很好的策略。 让我们设置它,从上一个示例中我们停止的地方开始:
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
print(layer)
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
现在我们可以开始微调我们的网络了。我们将使用rmsprop优化器,使用非常低的学习率来实现这一点。使用低学习率的原因是,我们希望将所做的修改的大小限制为我们正在微调的3个层的表示。太大的更新可能会损害这些表示。 现在,让我们继续进行微调:
# 给VGG16后边加上一两层,并且冻结VGG16前几层的参数,只训练最顶层的几层和添加的两层
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/100
100/100 [==============================] - 71s 708ms/step - loss: 0.2964 - acc: 0.8740 - val_loss: 0.2679 - val_acc: 0.8940
Epoch 2/100
100/100 [==============================] - 69s 695ms/step - loss: 0.2588 - acc: 0.8950 - val_loss: 0.2117 - val_acc: 0.9130
Epoch 3/100
100/100 [==============================] - 70s 696ms/step - loss: 0.2290 - acc: 0.9045 - val_loss: 0.2136 - val_acc: 0.9130
Epoch 4/100
100/100 [==============================] - 69s 690ms/step - loss: 0.2251 - acc: 0.9090 - val_loss: 0.2173 - val_acc: 0.9130
Epoch 5/100
100/100 [==============================] - 69s 689ms/step - loss: 0.2254 - acc: 0.9075 - val_loss: 0.2012 - val_acc: 0.9180
Epoch 6/100
100/100 [==============================] - 69s 694ms/step - loss: 0.1914 - acc: 0.9230 - val_loss: 0.1999 - val_acc: 0.9270
Epoch 7/100
100/100 [==============================] - 69s 694ms/step - loss: 0.1788 - acc: 0.9320 - val_loss: 0.2214 - val_acc: 0.9180
Epoch 8/100
100/100 [==============================] - 69s 689ms/step - loss: 0.1718 - acc: 0.9275 - val_loss: 0.2047 - val_acc: 0.9210
Epoch 9/100
100/100 [==============================] - 69s 688ms/step - loss: 0.1522 - acc: 0.9340 - val_loss: 0.2339 - val_acc: 0.9120
Epoch 10/100
100/100 [==============================] - 69s 692ms/step - loss: 0.1413 - acc: 0.9440 - val_loss: 0.1962 - val_acc: 0.9260
Epoch 11/100
100/100 [==============================] - 69s 688ms/step - loss: 0.1683 - acc: 0.9330 - val_loss: 0.2370 - val_acc: 0.9080
Epoch 12/100
100/100 [==============================] - 69s 694ms/step - loss: 0.1428 - acc: 0.9415 - val_loss: 0.1867 - val_acc: 0.9290
Epoch 13/100
100/100 [==============================] - 69s 687ms/step - loss: 0.1289 - acc: 0.9540 - val_loss: 0.1870 - val_acc: 0.9310
Epoch 14/100
100/100 [==============================] - 69s 689ms/step - loss: 0.1386 - acc: 0.9440 - val_loss: 0.1763 - val_acc: 0.9290
Epoch 15/100
100/100 [==============================] - 69s 695ms/step - loss: 0.1281 - acc: 0.9475 - val_loss: 0.1794 - val_acc: 0.9300
Epoch 16/100
100/100 [==============================] - 69s 694ms/step - loss: 0.1126 - acc: 0.9545 - val_loss: 0.1843 - val_acc: 0.9340
Epoch 17/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0951 - acc: 0.9595 - val_loss: 0.1679 - val_acc: 0.9310
Epoch 18/100
100/100 [==============================] - 69s 688ms/step - loss: 0.1109 - acc: 0.9565 - val_loss: 0.1779 - val_acc: 0.9340
Epoch 19/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0944 - acc: 0.9670 - val_loss: 0.1766 - val_acc: 0.9320
Epoch 20/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0942 - acc: 0.9670 - val_loss: 0.2022 - val_acc: 0.9250
Epoch 21/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0921 - acc: 0.9635 - val_loss: 0.2021 - val_acc: 0.9260
Epoch 22/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0825 - acc: 0.9670 - val_loss: 0.1876 - val_acc: 0.9320
Epoch 23/100
100/100 [==============================] - 69s 689ms/step - loss: 0.1010 - acc: 0.9630 - val_loss: 0.1837 - val_acc: 0.9360
Epoch 24/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0847 - acc: 0.9670 - val_loss: 0.1988 - val_acc: 0.9350
Epoch 25/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0731 - acc: 0.9705 - val_loss: 0.2018 - val_acc: 0.9350
Epoch 26/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0827 - acc: 0.9695 - val_loss: 0.1748 - val_acc: 0.9400
Epoch 27/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0722 - acc: 0.9755 - val_loss: 0.2203 - val_acc: 0.9330
Epoch 28/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0680 - acc: 0.9735 - val_loss: 0.2063 - val_acc: 0.9280
Epoch 29/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0654 - acc: 0.9710 - val_loss: 0.1923 - val_acc: 0.9360
Epoch 30/100
100/100 [==============================] - 69s 694ms/step - loss: 0.0733 - acc: 0.9710 - val_loss: 0.1965 - val_acc: 0.9320
Epoch 31/100
100/100 [==============================] - 69s 692ms/step - loss: 0.0708 - acc: 0.9760 - val_loss: 0.2125 - val_acc: 0.9290
Epoch 32/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0669 - acc: 0.9745 - val_loss: 0.2035 - val_acc: 0.9350
Epoch 33/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0679 - acc: 0.9735 - val_loss: 0.2199 - val_acc: 0.9270
Epoch 34/100
100/100 [==============================] - 69s 692ms/step - loss: 0.0628 - acc: 0.9785 - val_loss: 0.1928 - val_acc: 0.9310
Epoch 35/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0664 - acc: 0.9770 - val_loss: 0.2173 - val_acc: 0.9290
Epoch 36/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0515 - acc: 0.9820 - val_loss: 0.2261 - val_acc: 0.9340
Epoch 37/100
100/100 [==============================] - 69s 692ms/step - loss: 0.0555 - acc: 0.9785 - val_loss: 0.3316 - val_acc: 0.9160
Epoch 38/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0558 - acc: 0.9790 - val_loss: 0.2359 - val_acc: 0.9340
Epoch 39/100
100/100 [==============================] - 69s 692ms/step - loss: 0.0400 - acc: 0.9875 - val_loss: 0.2345 - val_acc: 0.9350
Epoch 40/100
100/100 [==============================] - 69s 695ms/step - loss: 0.0504 - acc: 0.9830 - val_loss: 0.2222 - val_acc: 0.9370
Epoch 41/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0437 - acc: 0.9835 - val_loss: 0.2325 - val_acc: 0.9390
Epoch 42/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0455 - acc: 0.9830 - val_loss: 0.2271 - val_acc: 0.9410
Epoch 43/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0557 - acc: 0.9805 - val_loss: 0.2746 - val_acc: 0.9300
Epoch 44/100
100/100 [==============================] - 69s 694ms/step - loss: 0.0450 - acc: 0.9840 - val_loss: 0.3066 - val_acc: 0.9230
Epoch 45/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0536 - acc: 0.9810 - val_loss: 0.2126 - val_acc: 0.9330
Epoch 46/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0477 - acc: 0.9810 - val_loss: 0.1954 - val_acc: 0.9400
Epoch 47/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0360 - acc: 0.9885 - val_loss: 0.2033 - val_acc: 0.9410
Epoch 48/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0405 - acc: 0.9820 - val_loss: 0.2188 - val_acc: 0.9330
Epoch 49/100
100/100 [==============================] - 68s 685ms/step - loss: 0.0318 - acc: 0.9880 - val_loss: 0.2992 - val_acc: 0.9240
Epoch 50/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0308 - acc: 0.9900 - val_loss: 0.2760 - val_acc: 0.9280
Epoch 51/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0429 - acc: 0.9855 - val_loss: 0.2365 - val_acc: 0.9360
Epoch 52/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0435 - acc: 0.9845 - val_loss: 0.2321 - val_acc: 0.9400
Epoch 53/100
100/100 [==============================] - 69s 686ms/step - loss: 0.0306 - acc: 0.9895 - val_loss: 0.2982 - val_acc: 0.9260
Epoch 54/100
100/100 [==============================] - 69s 686ms/step - loss: 0.0406 - acc: 0.9850 - val_loss: 0.3509 - val_acc: 0.9260
Epoch 55/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0374 - acc: 0.9890 - val_loss: 0.2440 - val_acc: 0.9350
Epoch 56/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0313 - acc: 0.9880 - val_loss: 0.2671 - val_acc: 0.9300
Epoch 57/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0264 - acc: 0.9865 - val_loss: 0.2277 - val_acc: 0.9340
Epoch 58/100
100/100 [==============================] - 69s 685ms/step - loss: 0.0286 - acc: 0.9890 - val_loss: 0.3027 - val_acc: 0.9310
Epoch 59/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0332 - acc: 0.9865 - val_loss: 0.2370 - val_acc: 0.9330
Epoch 60/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0251 - acc: 0.9900 - val_loss: 0.2270 - val_acc: 0.9400
Epoch 61/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0345 - acc: 0.9880 - val_loss: 0.3246 - val_acc: 0.9190
Epoch 62/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0360 - acc: 0.9905 - val_loss: 0.3061 - val_acc: 0.9290
Epoch 63/100
100/100 [==============================] - 69s 685ms/step - loss: 0.0405 - acc: 0.9855 - val_loss: 0.2458 - val_acc: 0.9390
Epoch 64/100
100/100 [==============================] - 69s 686ms/step - loss: 0.0241 - acc: 0.9905 - val_loss: 0.2371 - val_acc: 0.9350
Epoch 65/100
100/100 [==============================] - 68s 685ms/step - loss: 0.0223 - acc: 0.9920 - val_loss: 0.2663 - val_acc: 0.9420
Epoch 66/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0325 - acc: 0.9900 - val_loss: 0.2829 - val_acc: 0.9340
Epoch 67/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0319 - acc: 0.9855 - val_loss: 0.2462 - val_acc: 0.9410
Epoch 68/100
100/100 [==============================] - 68s 684ms/step - loss: 0.0314 - acc: 0.9900 - val_loss: 0.2452 - val_acc: 0.9400
Epoch 69/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0217 - acc: 0.9920 - val_loss: 0.2276 - val_acc: 0.9400
Epoch 70/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0316 - acc: 0.9895 - val_loss: 0.3000 - val_acc: 0.9320
Epoch 71/100
100/100 [==============================] - 69s 685ms/step - loss: 0.0235 - acc: 0.9900 - val_loss: 0.2419 - val_acc: 0.9380
Epoch 72/100
100/100 [==============================] - 68s 684ms/step - loss: 0.0254 - acc: 0.9890 - val_loss: 0.2744 - val_acc: 0.9270
Epoch 73/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0213 - acc: 0.9935 - val_loss: 0.2577 - val_acc: 0.9360
Epoch 74/100
100/100 [==============================] - 69s 687ms/step - loss: 0.0234 - acc: 0.9900 - val_loss: 0.5941 - val_acc: 0.8910
Epoch 75/100
100/100 [==============================] - 69s 686ms/step - loss: 0.0229 - acc: 0.9910 - val_loss: 0.2376 - val_acc: 0.9410
Epoch 76/100
100/100 [==============================] - 68s 684ms/step - loss: 0.0269 - acc: 0.9895 - val_loss: 0.2192 - val_acc: 0.9400
Epoch 77/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0306 - acc: 0.9895 - val_loss: 0.4235 - val_acc: 0.9180
Epoch 78/100
100/100 [==============================] - 69s 688ms/step - loss: 0.0297 - acc: 0.9870 - val_loss: 0.4058 - val_acc: 0.9150
Epoch 79/100
100/100 [==============================] - 68s 685ms/step - loss: 0.0185 - acc: 0.9920 - val_loss: 0.2406 - val_acc: 0.9350
Epoch 80/100
100/100 [==============================] - 68s 682ms/step - loss: 0.0231 - acc: 0.9925 - val_loss: 0.2911 - val_acc: 0.9350
Epoch 81/100
100/100 [==============================] - 68s 685ms/step - loss: 0.0210 - acc: 0.9925 - val_loss: 0.2490 - val_acc: 0.9390
Epoch 82/100
100/100 [==============================] - 68s 683ms/step - loss: 0.0285 - acc: 0.9900 - val_loss: 0.2651 - val_acc: 0.9400
Epoch 83/100
100/100 [==============================] - 69s 686ms/step - loss: 0.0238 - acc: 0.9915 - val_loss: 0.2630 - val_acc: 0.9420
Epoch 84/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0139 - acc: 0.9945 - val_loss: 0.4327 - val_acc: 0.9170
Epoch 85/100
100/100 [==============================] - 70s 696ms/step - loss: 0.0318 - acc: 0.9885 - val_loss: 0.3970 - val_acc: 0.9170
Epoch 86/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0212 - acc: 0.9920 - val_loss: 0.2888 - val_acc: 0.9360
Epoch 87/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0271 - acc: 0.9900 - val_loss: 0.3411 - val_acc: 0.9280
Epoch 88/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0168 - acc: 0.9955 - val_loss: 0.2189 - val_acc: 0.9480
Epoch 89/100
100/100 [==============================] - 70s 697ms/step - loss: 0.0233 - acc: 0.9920 - val_loss: 0.2459 - val_acc: 0.9410
Epoch 90/100
100/100 [==============================] - 69s 690ms/step - loss: 0.0224 - acc: 0.9915 - val_loss: 0.2352 - val_acc: 0.9400
Epoch 91/100
100/100 [==============================] - 70s 699ms/step - loss: 0.0189 - acc: 0.9925 - val_loss: 0.2632 - val_acc: 0.9380
Epoch 92/100
100/100 [==============================] - 69s 694ms/step - loss: 0.0163 - acc: 0.9940 - val_loss: 0.3046 - val_acc: 0.9360
Epoch 93/100
100/100 [==============================] - 69s 695ms/step - loss: 0.0099 - acc: 0.9980 - val_loss: 0.3264 - val_acc: 0.9350
Epoch 94/100
100/100 [==============================] - 69s 694ms/step - loss: 0.0174 - acc: 0.9950 - val_loss: 0.2712 - val_acc: 0.9370
Epoch 95/100
100/100 [==============================] - 69s 691ms/step - loss: 0.0132 - acc: 0.9965 - val_loss: 0.3202 - val_acc: 0.9330
Epoch 96/100
100/100 [==============================] - 69s 695ms/step - loss: 0.0126 - acc: 0.9945 - val_loss: 0.2944 - val_acc: 0.9330
Epoch 97/100
100/100 [==============================] - 70s 695ms/step - loss: 0.0236 - acc: 0.9940 - val_loss: 0.3391 - val_acc: 0.9340
Epoch 98/100
100/100 [==============================] - 69s 689ms/step - loss: 0.0241 - acc: 0.9910 - val_loss: 0.2671 - val_acc: 0.9360
Epoch 99/100
100/100 [==============================] - 69s 695ms/step - loss: 0.0231 - acc: 0.9915 - val_loss: 0.2538 - val_acc: 0.9400
Epoch 100/100
100/100 [==============================] - 69s 693ms/step - loss: 0.0219 - acc: 0.9935 - val_loss: 0.2560 - val_acc: 0.9370
# 画出精度和损失函数的曲线
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,'b',label = 'Training acc')
plt.plot(epochs,val_all,'r',label = 'Validation acc')
plt.title('Train and Validation acc')
plt.legend()
plt.figure()
plt.plot(epochs,loss,'b',label = "Training loss")
plt.plot(epochs,val_loss,'r',label = 'Validation loss')
plt.title('Train and Validation loss')
plt.legend()
plt.show()
这些曲线看起来很紧凑。为了使它们更易读,我们可以用这些量的指数移动平均值替换每一个损失和精度。下面是一个简单的实用程序函数:
# 使曲线更平滑的函数
def smooth_curve(points, factor=0.8):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
plt.plot(epochs,
smooth_curve(acc), 'bo', label='Smoothed training acc')
plt.plot(epochs,
smooth_curve(val_acc), 'b', label='Smoothed validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,
smooth_curve(loss), 'bo', label='Smoothed training loss')
plt.plot(epochs,
smooth_curve(val_loss), 'b', label='Smoothed validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
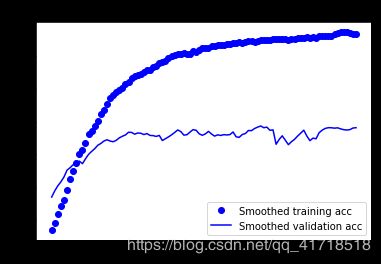
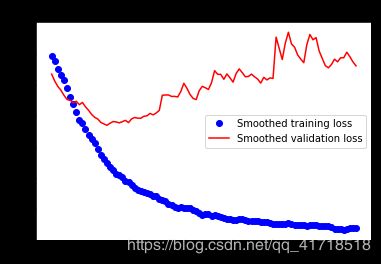
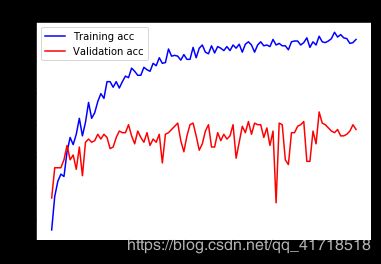
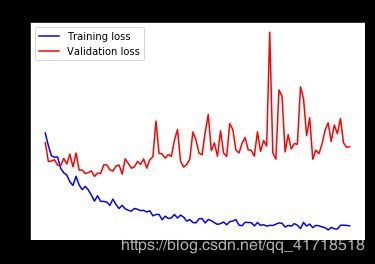
这些曲线看起来更清晰、更稳定。我们看到一个不错的1%的绝对改善。 请注意,损失曲线没有显示出任何真正的改善(事实上,它正在恶化)。你可能想知道,如果损失不减少,精确度如何提高?答案很简单:我们显示的是逐点损失值的平均值,但实际影响准确性的是损失值的分布,而不是它们的平均值,因为准确性是模型预测的类概率的二元阈值化的结果。即使这没有反映在平均损失中,模型可能仍然在改进。 我们现在可以根据测试数据最终评估此模型:
# 使用训练好的模型进行预测
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test acc:', test_acc)
Found 1000 images belonging to 2 classes.
test acc: 0.9420000052452088
总结:
如果你有少量样本的话,可以使用现成的模型,即别人训练好的模型。
有3种方法:
1.直接使用别人训练好的模型来处理自己的训练数据,运行一次导入的模型,把自己的训练数据处理的结果保存,然后训练一个小的全连接网络。相当于用已有模型来提取特征,自己只需要训练一个小的全连接网络。
2.把全连接网络加在以后有模型之后,但是需要冻结已有模型的参数
3.可以加入全连接网络,冻结底层的参数,对高层的参数可以进行微调。
5.4 卷积神经网络的可视化
人们常说,深度学习模型是“黑匣子”,学习表示很难以人类可读的形式提取和呈现。虽然对于某些类型的深度学习模型,这是部分正确的,但对于convnets,这绝对不是正确的。自2013年以来,已经开发了一系列用于可视化和解释这些表示的技术。我们不会调查所有这些问题,但我们将涵盖三个最容易接近和最有用的问题:
1.可视化卷积神经网络中间输出(“中间激活”)。这有助于理解连续的convnet层如何转换其输入,并了解各个convnet过滤器的含义。
2.可视化卷积神经网络的过滤器。这有助于准确理解convnet中每个过滤器所能接受的视觉模式或概念。
3.在图像中可视化类激活的热图。这有助于理解标识为属于给定类的图像的哪个部分,从而允许在图像中定位对象。
对于第一种方法我们将使用5.2节用来解决猫和狗的分类问题的从零开始训练的小型卷积神经网络。对于接下来的两种方法,我们将使用上一节中介绍的VGG16模型。
# 1.可视化卷积神经网络的中间输出
from keras.models import load_model
model = load_model('cats_and_dogs_small_2.h5')
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_5 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_7 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_8 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 6272) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 6272) 0
_________________________________________________________________
dense_3 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_4 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
img_path = r'D:\study\Python\Deeplearning\ch5\dogs-vs-cats\train\train\cat.1700.jpg'
from keras.preprocessing import image
import numpy as np
img = image.load_img(img_path,target_size = (150,150))
img_tensor = image.img_to_array(img)
img_tensor = np.expand_dims(img_tensor,axis = 0)
img_tensor /= 255.
print(img_tensor.shape)
(1, 150, 150, 3)
import matplotlib.pyplot as plt
plt.imshow(img_tensor[0])
plt.show()

为了提取我们想要查看的特征图,我们将创建一个以成批图像为输入的keras模型,并输出所有卷积和pooling层的激活。 为此,我们将使用keras类模型。使用两个参数来实例化模型:输入张量(或输入张量列表)和输出张量(或输出张量列表)。 生成的类是一个keras模型,就像您熟悉的顺序模型一样,将指定的输入映射到指定的输出。 使模型类与众不同的是,它允许具有多个输出的模型,而不是顺序的。有关模型类的更多信息,请参阅第7章第1节。
from keras import models
layer_outputs = [layer.output for layer in model.layers[:8]]
# 输入为图片,输出为前8层的激活值,这个模型有一个输入,8个输出
activation_model = models.Model(inputs = model.input,outputs = layer_outputs)
activations = activation_model.predict(img_tensor)
# 返回8个numpy数组组成的列表,每层的激活对应一个数组
first_layer_activation = activations[0]
print(first_layer_activation.shape)
import matplotlib.pyplot as plt
# 查看第一层中第四个特征图是什么样子的
plt.matshow(first_layer_activation[0,:,:,4],cmap = 'viridis')
# 查看第一层中第七个特征图是什么样子的
plt.matshow(first_layer_activation[0,:,:,7],cmap = 'viridis')


# 提取所有通道的特征图,并显示
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
for layer_name,layer_activation in zip(layer_names,activations):
n_features = layer_activation.shape[-1] #表示每一层特征图中的特征个数
size = layer_activation.shape[1] #特征图的形状为(1,size,四ize,n_features)
n_cols = n_features // images_per_row # 在这个通道中将激活通道平铺
display_grid = np.zeros((size*n_cols,images_per_row*size))
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,:,:,col*images_per_row + row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image,0,255).astype('uint8')
display_grid[col * size :(col +1) * size,row * size :(row+1) * size] = channel_image # 显示网格
scale = 1./size
plt.figure(figsize = (scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid,aspect = 'auto',cmap = 'viridis')
plt.show()


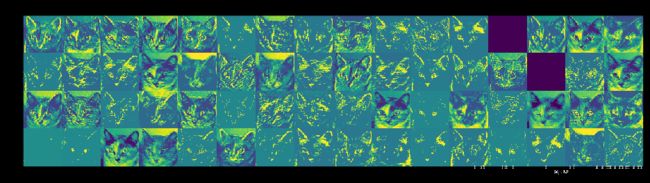
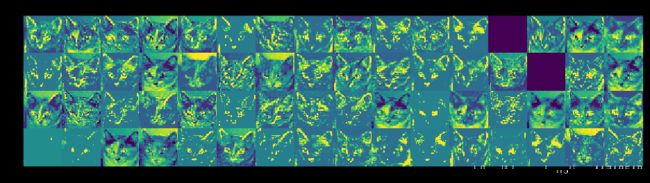
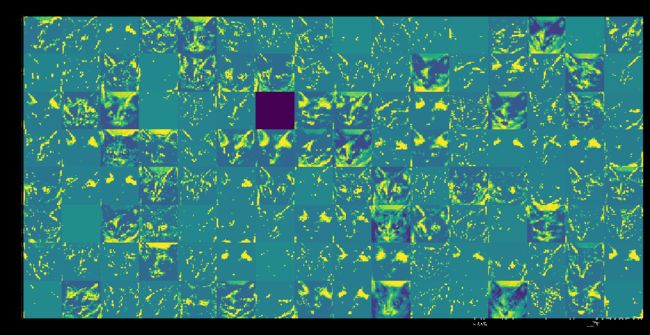

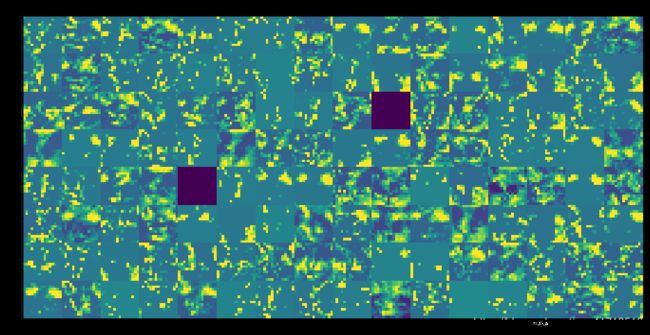
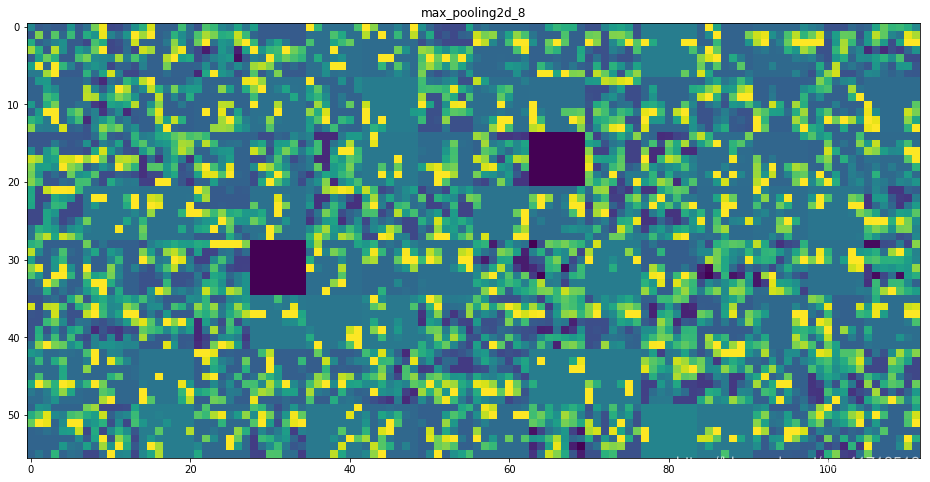
这里需要注意的几个重要事项:
第一层是各种边缘探测器的集合。在那个阶段,激活仍然保留了最初图片中的几乎所有信息。
随着我们向上走,激活变得越来越抽象,视觉解释能力也越来越差。他们开始编码更高级的概念,如“猫耳”或“猫眼”。更高级别的演示文稿包含的关于图像视觉内容的信息越来越少,与图像类别相关的信息也越来越多。
激活的稀疏性随着层的深度而增加:在第一层中,所有过滤器都由输入图像激活,但在下面的层中,越来越多的过滤器是空白的。这意味着在输入图像中找不到由过滤器编码的模式。
我们刚刚证明了深层神经网络所学表示的一个非常重要的普遍特征:
一个层所提取的特征随着层的深度越来越抽象。更高层次的激活会带来越来越少的关于所看到的特定输入的信息,以及越来越多的关于目标的信息(在我们的例子中,是图像的类别:猫或狗)。深度神经网络有效地充当一个信息蒸馏管道,将原始数据输入(在我们的例子中,是RBG图片),并反复转换,以便过滤出不相关的信息(例如图像的特定视觉外观),同时放大和细化有用的信息(例如图像的类别)。
这类似于人类和动物感知世界的方式:观察一个场景几秒钟后,人类可以记住其中存在的抽象对象(如自行车、树),但无法记住这些对象的具体外观。事实上,如果你现在试图从脑海中画出一辆普通的自行车,很有可能你根本就不能得到它,即使你一生中见过成千上万辆自行车。现在就试试:这种效果是绝对真实的。你的大脑已经学会了完全抽象它的视觉输入,把它转换成高层次的视觉概念,同时完全过滤掉不相关的视觉细节,这使得我们很难记住周围的事物实际上是什么样子的。
2.可视化卷积神经网络的过滤器
检查convnets学习的过滤器的另一个简单方法是显示每个过滤器要响应的可视模式。 这可以通过输入空间中的梯度上升来实现:将梯度下降应用于convnet输入图像的值, 以便从空白输入图像开始最大化特定过滤器的响应。所产生的输入图像将是所选过滤器最大响应的图像。
这个过程很简单:我们将建立一个损失函数, 使给定卷积层中给定滤波器的值最大化,然后使用随机梯度下降来调整输入图像的值, 从而使这个激活值最大化。例如,在ImageNet上训练的VGG16网络的“block3_conv1”层的第0个过滤器激活的损失如下所示:
from keras.applications import VGG16
from keras import backend as K
model = VGG16(weights = 'imagenet',include_top = False)
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:,:,:,filter_index])
为了实现梯度下降,我们需要这个损失相对于模型输入的梯度。为此,我们将使用与keras后端模块打包的Gradients函数:
# 对“gradients”的调用返回张量列表(在本例中为1大小),因此我们只保留第一个元素——张量。
grads = K.gradients(loss,model.input)[0]
# 为了让梯度下降过程顺利进行,一个技巧是使用梯度张量除以其L2范数进行归一化
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input],[loss,grads])
import numpy as np
loss_value,grads_value = iterate([np.zeros((1,150,150,3))])
# 创造一张带有噪声的灰度图开始
input_img_data = np.random.random((1,150,150,3))*20 + 128.
step = 1.
for i in range(40):
# 计算对于输入图像的损失值和梯度值
loss_value,grads_value = iterate([input_img_data])
# 沿着让损失最大化的方向调节图像
input_img_data += grads_value * step
# 运行40次后得到的结果可能是【0,255】之间的浮点数,不能显示为图像,要将其转换为整数,进行显示
def deprocess_image(x):
# 使x均值为0,标准差为0.1
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
# 将x裁剪到【0,1】区间
x += 0.5
x = np.clip(x,0,1)
# 将x转换为RGB数组
x *= 255
x = np.clip(x,0,255).astype('uint8')
return x
# 构建一个损失函数,可以实现将第n层的第i个过滤器的激活只最大化
def generator_pattern(layer_name,filter_index,size = 150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:,:,:,filter_index])
grads = K.gradients(loss,model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
# 返回输入图像的损失和梯度
iterate = K.function([model.input],[loss,grads])
# 随即创造一张带有噪声的图像
input_img_data = np.random.random((1,size,size,3)) * 20 +128.
step = 1.
for i in range(40):
loss_value,grads_value = iterate([input_img_data])
input_img_data += grads_value*step
img = input_img_data[0]
return deprocess_image(img)
plt.imshow(generator_pattern('block3_conv1',0))

# 生成某一层中所有过滤器相应模式组成的网络
for layer_name in ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1']:
size = 64
margin = 5
results = np.zeros((8*size + 7 * margin,8*size +7*margin,3)) # 空图像,用于保存结果
for i in range(8):#遍历results的行
for j in range(8): #遍历results的列
filter_img = generator_pattern(layer_name,i+(j*8),size = size)
horizontal_start = i* size + i *margin
horizontal_end = horizontal_start + size
vertical_start = j * size + j * margin
vertical_end = vertical_start + size
results[horizontal_start:horizontal_end,
vertical_start:vertical_end,:] = filter_img
plt.figure(figsize = (20,20))
plt.imshow(results)
plt.show()

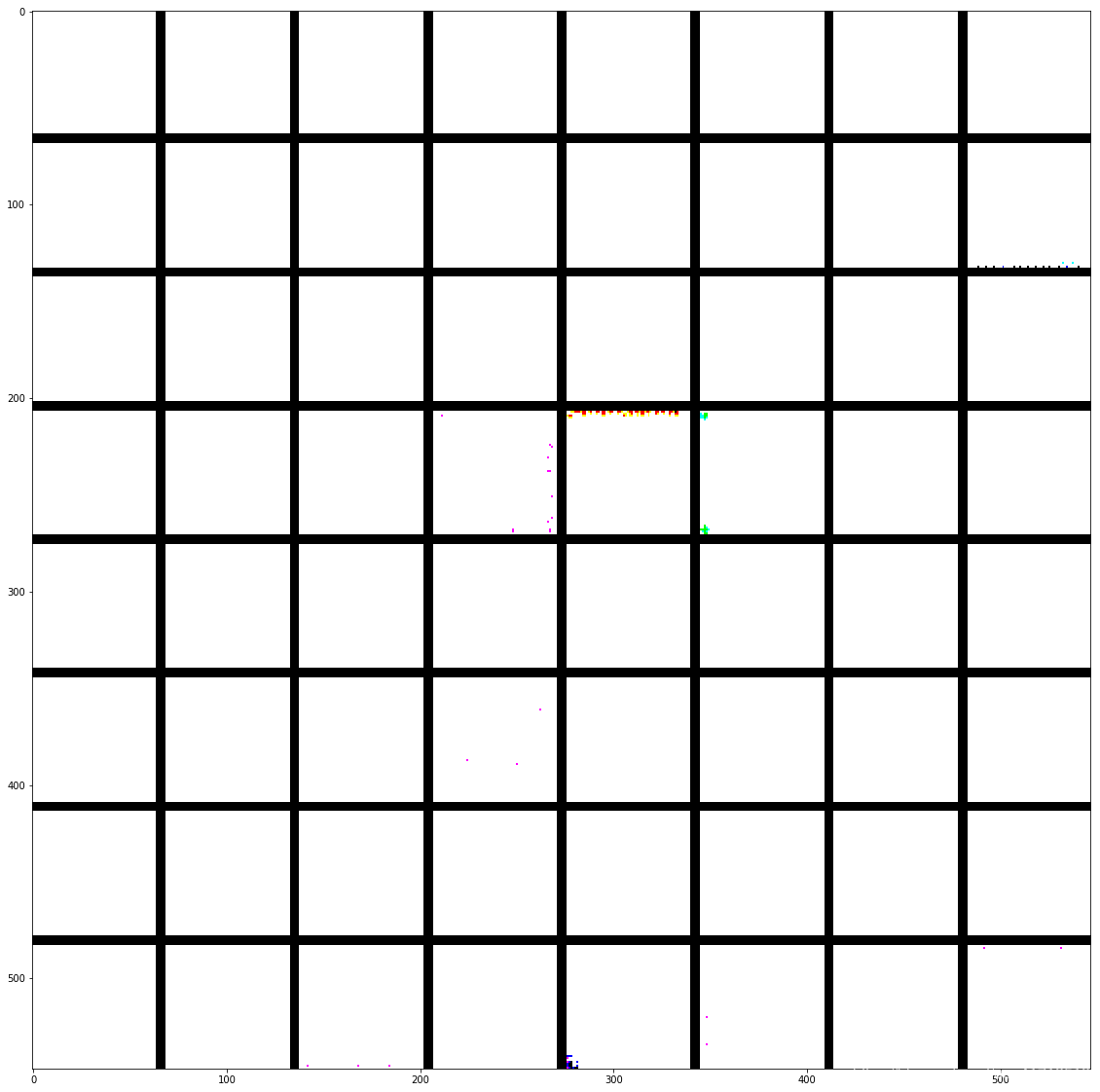


这些过滤器可视化告诉我们很多关于convnet层如何看待世界的信息:convnet中的每一层都只是学习一组过滤器, 这样它们的输入就可以表示为过滤器的组合。这类似于傅立叶变换如何将信号分解成一组余弦函数。 随着我们在模型中的提升,这些convnet过滤器组中的过滤器变得越来越复杂和精细:
可视化类激活的热力图
我们将介绍另一种可视化技术,它有助于理解给定图像的哪些部分引导convnet做出最终的分类决策。这有助于“调试”convnet的决策过程, 特别是在分类错误的情况下。它还允许您在图像中定位特定对象。
这类技术被称为“类激活图”(CAM)可视化,它包括在输入图像上生成“类激活”的热图。 “类激活”heatmap是一个与特定输出类相关的二维分数网格,针对任何输入图像中的每个位置进行计算, 表明每个位置对所考虑的类有多重要。例如,假设有一个图像输入到我们的“猫对狗”convnet中, 类激活映射可视化允许我们为类“cat”生成一个heatmap,指示图像中猫的不同部分是怎样的, 同样,对于类“dog”,指示图像中狗的不同部分是怎样的。
Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization 这是实现此步骤的论文。它非常简单:它包括获取给定输入图像的卷积层的输出特征映射,并通过类相对于通道的梯度来加权该特征映射中的每个通道。直观地说,理解这一技巧的一种方法是,我们通过“每个通道对类的重要性”来加权“输入图像激活不同通道的强度”的空间图,从而得出“输入图像激活类的强度”的空间图。
我们将使用预先培训过的vgg16网络再次演示此技术:
备注:自己的电脑运行一下程序报错,所以官房给的程序的结果作为正确结果,但是程序时自己敲的,有中文注释
from keras.applications.vgg16 import VGG16
# 此次引入的VGG16模型,包含了密集型连接层
model = VGG16(weights = 'imagenet')
Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels.h5
548380672/553467096 [============================>.] - ETA: 0s
Let's consider the following image of two African elephants, possible a mother and its cub, strolling in the savanna (under a Creative Commons license):
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input , decode_predictions
import numpy as np
img_path = r'D:\study\Python\Deeplearning\ch5\dogs-vs-cats\train\train\cat.3.jpg'
img = image.load_img(img_path,target_size = (224,224))
# 将图像转换成(224,224,3)的numpy矩阵
x = image.img_to_array(img)
# 添加一个维度,使之成为(1,224,224,3)的矩阵
x = np.expand_dims(x,axis = 0)
x = preprocess_input(x)
preds = model.predict(x)
print('Prediction:',decode_predictions(preds,top = 3)[0])
Predicted: [('n02504458', 'African_elephant', 0.90942144), ('n01871265', 'tusker', 0.08618243), ('n02504013', 'Indian_elephant', 0.0043545929)]
# 展示图像中哪部分激活了网络,使用Grad_CAM算法
african_cat_output = model.output[:,386]
last_conv_layer = model.get_layer('block5_conv3')
# 图片对应于block5_conv3输出的特征图对应的梯度
grads = K.gradients(african_cat_output,last_conv_layer.output)[0]
pooled_grads = K.mean(grads,axis = (0,1,2))
iterate = K.function([model.input],[pooled_grads,last_convv_layer.output[0]])
pooled_grads_value,conv_layer_output_value = iterate([x])
for i in range(512):
conv_layer_output_value[:,:,i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output_value,axis = -1)
heatmap = np.maximum(heatmap,0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
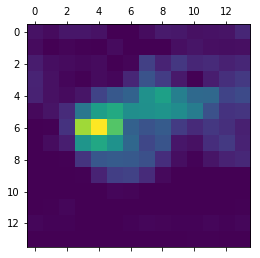
# 最后,用opencv来生成一张图象,叠加在原始图像上
import cv2
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap,(img.shape[1],img.shape[0]))
heatmap = np.uint8(255*heatmap)
heatmap = cv2.applyColorMap(heatmap,cv2.COLORMAP_JET)
superimposed_img = heat*0.4 + img
# cv2.imwrite()