Spark项目实战:大数据实时流处理日志(非常详细)
实战概览
- 一、实战内容
- 二、大数据实时流处理分析系统简介
- 1.需求
- 2.背景及架构
- 三、实战所用到的架构和涉及的知识
- 1.后端架构
- 2.前端框架
- 四、项目实战
- 1.后端开发实战
- 1.构建项目
- 2.引入依赖
- 3.创建工程包结构
- 4.编写代码
- 5.编写python脚本产生数据
- 6.创建日志存放目录并编写Flume的配置文件
- 7.创建Kafka主题
- 8.在HBase中创建项目需要的表
- 9.测试后端代码
- 2.前端开发实战
- 1.构建工程
- 2.引入依赖
- 3.创建MySQL表
- 4.配置SSM框架
- 5.创建工程包结构
- 6.编写代码
- 五、项目结果展示
- 六、总结
一、实战内容
- 编写python脚本,源源不断产生学习网站的用户行为日志。
- 启动 Flume 收集产生的日志。
- 启动 Kfka 接收 Flume 接收的日志。
- 使用 Spark Streaming 消费 Kafka 的用户日志。
- Spark Streaming将数据清洗过滤非法数据,然后分析日志中用户的访问课程,统计课程数,得到最受欢迎课程TOP5,第二个业务是统计各个搜索引擎的搜索量。(通过分析日志还可以实现很多其他的业务,基于篇幅,本项目只实现其中两个)。
- 将 Spark Streaming 处理的结果写入 HBase 中。
- 前端使用 Spring MVC、 Spring、 MyBatis 整合作为数据展示平台。
- 使用Ajax异步传输数据到jsp页面,并使用 Echarts 框架展示数据。
- 本实战使用IDEA2018作为开发工具,JDK版本为1.8,Scala版本为2.11。
二、大数据实时流处理分析系统简介
-
1.需求
如今大数据技术已经遍布生产的各个角落,其中又主要分为离线处理和实时流处理。本实战项目则是使用了实时流处理,而大数据的实时流式处理的特点:
1.数据会不断的产生,且数量巨大。
2.需要对产生额数据实时进行处理。
3.处理完的结果需要实时读写进数据库或用作其他分析。
针对以上的特点,传统的数据处理结构已经无力胜任,因而产生的大数据实时流处理的架构思想。 -
2.背景及架构
数据的处理一般涉及数据的聚合,数据的处理和展现能够在秒级或者毫秒级得到响应。针对这些问题目前形成了Flume + kafka + Storm / Spark /Flink + Hbase / Redis 的技架构。本实战采用Flume + kafka + Spark + Hbase的架构。
三、实战所用到的架构和涉及的知识
-
1.后端架构
1.Hadoop-2.6.0-cdh5.7.0
2.Spark-2.2.0-bin-2.6.0-cdh5.7.0
3.Apache-flume-1.9.0-bin
4.Kafka_2.11-1.0.0
5.Hbase-1.2.0-cdh5.7.0 -
2.前端框架
1.Spring MVC-4.3.3.RELEASE
2.Spring-4.3.3.RELEASE
3.MyBatis-3.2.1
4.Echarts
四、项目实战
-
1.后端开发实战
1.构建项目
构建Scala工程项目,并添加Maven支持。
2.引入依赖
<properties> <scala.version>2.11.8</scala.version> <hadoop.version>2.6.0-cdh5.7.0</hadoop.version> <spark.version>2.2.0</spark.version> <hbase.version>1.2.0-cdh5.7.0</hbase.version> </properties> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> </repository> </repositories> <dependencies> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId> spark-streaming-kafka-0-8_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.module</groupId> <artifactId>jackson-module-scala_2.11</artifactId> <version>2.6.5</version> </dependency> <dependency> <groupId>net.jpountz.lz4</groupId> <artifactId>lz4</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.5</version> </dependency> <dependency> <groupId>com.ggstar</groupId> <artifactId>ipdatabase</artifactId> <version>1.0-SNAPSHOT</version> </dependency> </dependencies>3.创建工程包结构
在scala目录下创建如下包结构:
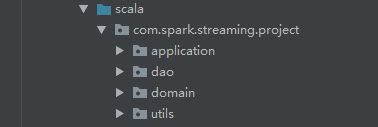
4.编写代码
(1). 在util包下创健Java类HBaseUtils,用于连接HBase,存储处理的结果:

类HBaseUtils完整代码如下:/** * Hbase工具类,用于: * 连接HBase,获得表实例 */ public class HBaseUtils { private Configuration configuration = null; private Connection connection = null; private static HBaseUtils instance = null; /** * 在私有构造方法中初始化属性 */ private HBaseUtils(){ try { configuration = new Configuration(); //指定要访问的zk服务器 configuration.set("hbase.zookeeper.quorum", "hadoop01:2181"); //得到Hbase连接 connection = ConnectionFactory.createConnection(configuration); }catch(Exception e){ e.printStackTrace(); } } /** * 获得HBase连接实例 */ public static synchronized HBaseUtils getInstance(){ if(instance == null){ instance = new HBaseUtils(); } return instance; } /** *由表名得到一个表的实例 * @param tableName * @return */ public HTable getTable(String tableName) { HTable hTable = null; try { hTable = (HTable)connection.getTable(TableName.valueOf(tableName)); }catch (Exception e){ e.printStackTrace(); } return hTable; } }在util包下创Scala object类DateUtils,用于格式化日志的日期,代码如下:
/** * 格式化日期工具类 */ object DateUtils { //指定输入的日期格式 val YYYYMMDDHMMSS_FORMAT= FastDateFormat.getInstance("yyyy-MM-dd hh:mm:ss") //指定输出格式 val TARGET_FORMAT = FastDateFormat.getInstance("yyyyMMddhhmmss") //输入String返回该格式转为log的结果 def getTime(time:String) = { YYYYMMDDHMMSS_FORMAT.parse(time).getTime } def parseToMinute(time:String) = { //调用getTime TARGET_FORMAT.format(getTime(time)) } }(2). 在domain包下创建以下几个Scala样例类:
ClickLog:用于封装清洗后的日志信息:
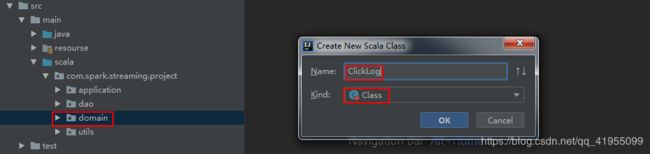
然后将该类声明为样例类,在class关键字前增加case关键字:

ClickLog 类完整代码如下:/** * 封装清洗后的数据 * @param ip 日志访问的ip地址 * @param time 日志访问的时间 * @param courseId 日志访问的实战课程编号 * @param statusCode 日志访问的状态码 * @param referer 日志访问的referer信息 */ case class ClickLog (ip:String,time:String,courseId:Int,statusCode:Int,referer:String)再创建样例类 CourseClickCount 用于封装课程统计的结果,样例类 CourseSearchClickCount 用于封装搜索引擎的统计结果,因为创建过程与上面的ClickLog 类一样,这里不再展示,直接给出完整代码:
CourseClickCount 类完整代码如下:/** * 封装实战课程的总点击数结果 * @param day_course 对应于Hbase中的RowKey * @param click_count 总点击数 */ case class CourseClickCount(day_course:String,click_count:Int)CourseSearchClickCount 类完整代码如下:
/** * 封装统计通过搜索引擎多来的实战课程的点击量 * @param day_serach_course 当天通过某搜索引擎过来的实战课程 * @param click_count 点击数 */ case class CourseSearchClickCount(day_serach_course:String,click_count:Int)(3). 在dao包下创建以下Scala的object类:
CourseClickCountDao :用于交互HBase,把课程点击数的统计结果写入HBase:
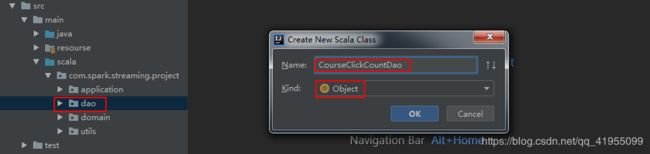
CourseClickCountDao 类的完整代码如下:/** * 实战课程点击数统计访问层 */ object CourseClickCountDao { val tableName = "ns1:courses_clickcount" //表名 val cf = "info" //列族 val qualifer = "click_count" //列 /** * 保存数据到Hbase * @param list (day_course:String,click_count:Int) //统计后当天每门课程的总点击数 */ def save(list:ListBuffer[CourseClickCount]): Unit = { //调用HBaseUtils的方法,获得HBase表实例 val table = HBaseUtils.getInstance().getTable(tableName) for(item <- list){ //调用Hbase的一个自增加方法 table.incrementColumnValue(Bytes.toBytes(item.day_course), Bytes.toBytes(cf), Bytes.toBytes(qualifer), item.click_count) //赋值为Long,自动转换 } } }CourseClickCountDao :用于交互HBase,把搜引擎搜索数量的统计结果写入HBase,创建过程与CourseClickCountDao 类一致故不再展示,完整代码如下:
object CourseSearchClickCountDao { val tableName = "ns1:courses_search_clickcount" val cf = "info" val qualifer = "click_count" /** * 保存数据到Hbase * @param list (day_course:String,click_count:Int) //统计后当天每门课程的总点击数 */ def save(list:ListBuffer[CourseSearchClickCount]): Unit = { val table = HBaseUtils.getInstance().getTable(tableName) for(item <- list){ table.incrementColumnValue(Bytes.toBytes(item.day_serach_course), Bytes.toBytes(cf), Bytes.toBytes(qualifer), item.click_count) //赋值为Long,自动转换 } } }注意: 代码中的HBase表需要提前创建好,详情请看本节的 8.在HBase中创建项目需要的表。
(4). 在application包下创建Scala的object类 CountByStreaming,用于处理数据,是本项目的程序入口,最为核心的类:
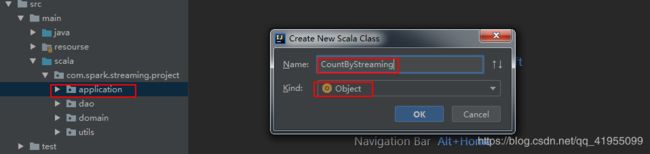
CountByStreaming 类的完整代码如下:object CountByStreaming { def main(args: Array[String]): Unit = { /** * 最终该程序将打包在集群上运行, * 需要接收几个参数:zookeeper服务器的ip,kafka消费组, * 主题,以及线程数 */ if(args.length != 4){ System.err.println("Error:you need to input:" 5.编写python脚本产生数据
编写一个python脚本,命名为 generate_log.py,用于产生用户日志:
import random import time //创建url访问数组class/112,数字代表的是实战课程id url_paths = [ "class/112.html", "class/128.html", "class/145.html", "class/146.html", "class/500.html", "class/250.html", "class/131.html", "class/130.html", "class/271.html", "class/127.html", "learn/821", "learn/823", "learn/987", "learn/500", "course/list" ] //创建ip数组,随机选择4个数字作为ip如132.168.30.87 ip_slices = [132,156,124,10,29,167,143,187,30,46,55,63,72,87,98,168,192,134,111,54,64,110,43] //搜索引擎访问数组{query}代表搜索关键字 http_referers = [ "http://www.baidu.com/s?wd={query}", "https://www.sogou.com/web?query={query}", "http://cn.bing.com/search?q={query}", "https://search.yahoo.com/search?p={query}", ] //搜索关键字数组 search_keyword = [ "Spark SQL实战", "Hadoop基础", "Storm实战", "Spark Streaming实战", "10小时入门大数据", "SpringBoot实战", "Linux进阶", "Vue.js" ] //状态码数组 status_codes = ["200","404","500","403"] //随机选择一个url def sample_url(): return random.sample(url_paths, 1)[0] //随机组合一个ip def sample_ip(): slice = random.sample(ip_slices , 4) return ".".join([str(item) for item in slice]) //随机产生一个搜索url def sample_referer(): //一半的概率会产生非法url,用于模拟非法的用户日志 if random.uniform(0, 1) > 0.5: return "-" refer_str = random.sample(http_referers, 1) query_str = random.sample(search_keyword, 1) return refer_str[0].format(query=query_str[0]) //随机产生一个数组 def sample_status_code(): return random.sample(status_codes, 1)[0] //组合以上的内容,产生一条简单的用户访问日志 def generate_log(count = 10): //获取本机时间并将其作为访问时间写进访问日志中 time_str = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) //存储日志的目标文件(换成你自己的) f = open("/home/hadoop/data/click.log","w+") //组合用户日志 while count >= 1: query_log = "{ip}\t{local_time}\t\"GET /{url} HTTP/1.1\"\t{status_code}\t{referer}".format(url=sample_url(), ip=sample_ip(), referer=sample_referer(), status_code=sample_status_code(),local_time=time_str) f.write(query_log + "\n") count = count - 1 //执行main,每次产生100条用户日志 if __name__ == '__main__': generate_log(100)6.创建日志存放目录并编写Flume的配置文件
(1). 创建日志存储的目录用于存放日志,位置自定义,但是一定要与python脚本及即将要编写的Flume配置文件中监控的目录一致,否则将无法收集。在home目录下创建data文件夹,并创建click.log文件,即最后日志存放在
~/data/click.log中。
(2). 在Flume的配置文件目录下新建一个文件,即在$FLUME_HOME/conf下新建一个文件 streaming_project.conf
streaming_project.conf的完整配置如下:exec-memory-kafka.sources = exec-source #exec的源,用于监控某个文件是否有 数据追加 exec-memory-kafka.sinks = kafka-sink exec-memory-kafka.channels = memory-channel exec-memory-kafka.sources.exec-source.type = exec exec-memory-kafka.sources.exec-source.command = tail -F /home/hadoop/data/click.log #被监控的文件,目录必须正确 exec-memory-kafka.sources.exec-source.shell = /bin/sh -c exec-memory-kafka.channels.memory-channel.type = memory exec-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink exec-memory-kafka.sinks.kafka-sink.brokerList = hadoop01:9092 #Kafka集群的某个活动节点的ip exec-memory-kafka.sinks.kafka-sink.topic = streamtopic #Kafka的主题 exec-memory-kafka.sinks.kafka-sink.batchSize = 10 exec-memory-kafka.sinks.kafka-sink.requiredAcks = 1 exec-memory-kafka.sources.exec-source.channels = memory-channel #关联三大组件 xec-memory-kafka.sinks.kafka-sink.channel = memory-channel7.创建Kafka主题
在Linux终端执行以下命令:
$KAFKA_HOME/bin/./kafka-topics.sh --create --zookeeper hadoop01:2181 --replication-factor 3 --partitions 3 --topic streamtopic
主题的名字自定义,副本的个数小于等于Kafka集群中存活节点的个数,zookeeper写任意一台存活的zookeeper的主机ip。8.在HBase中创建项目需要的表
在Linux终端执行以下命令:
(1). 进入Hbase shell:$HBASE_HOME/bin/./hbase shell
在Hbase shell中执行以下命令:
(2). 创建名字空间 ns1:create_namespace 'ns1'
(3). 创建课程访问统计表,列族为info:create 'ns1:courses_clickcoun', 'info'
(4). 创建搜索引擎统计表,列族为info:create 'ns1:courses_search_clickcount', 'info'9.测试后端代码
(1). 启动Flume,监控存储日志的文件。
在Linux终端下执行以下命令:
$FLUME_HOME/bin/./flume-ng agent -n exec-memory-kafka -f FLUME_HOME/conf/streaming_project.conf
(2). 调用Linux的crontab命令,周期性调用python脚本,源源不断产生数据,有关于crontab命令的使用可自行查找相关资料,这里不详细展,在LInux终端下执行命令:crontab -e,进入任务设置,键盘输入 i ,进入insert模式,编写脚本如下:

编写完后在键盘下敲esc健退出insert模式,输入 :wq保存退出。
注意: 如果要停止产生日志,可以执行命令:crontab -e,进入任务设置,在那一行脚本前输入 #,代表注释那一行脚本。
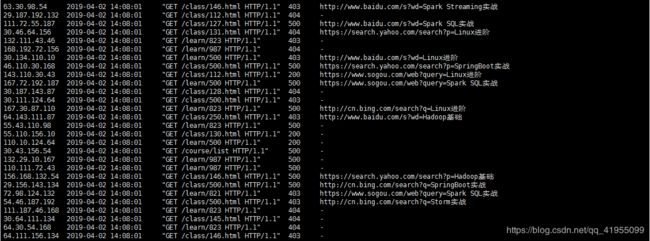
(3). 启动一个kafak控制台消费者,检测Flume是否成功收集到日志:
在Linux终端输入命令:$KAFKA_HOME/bin/./kafka-console-consumer.sh --topic streamtopic --zookeeper hadoop01:2181,如果成功则终端控制台会有如下显示:
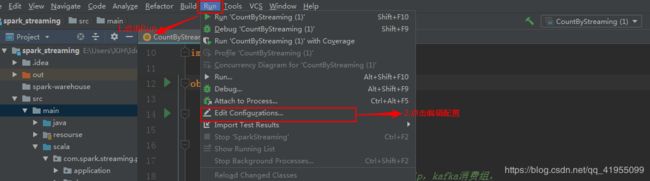
(4). 运行本项目的核心类 CountByStreaming ,因为我们设置main方法要接收许多参数,因此在运行前需要配置一下该类:
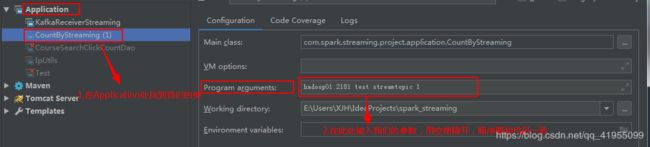
配置完成后运行程序即可。
注意: 有的小伙伴的电脑可能运行内存不足报如下异常:
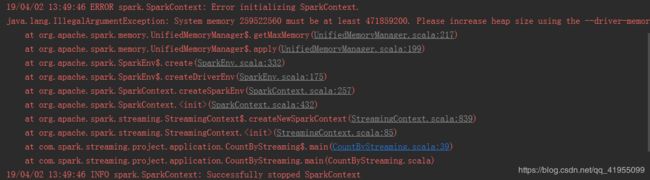
只需要在代码中增加如下配置就可以解决:
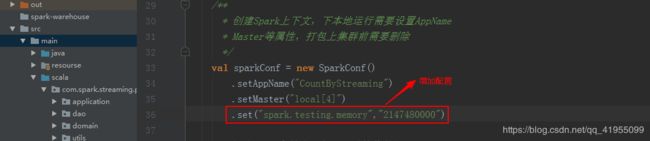
(5). 进入hbase shell,查看结果:
在hbase shell下输入以下命令:
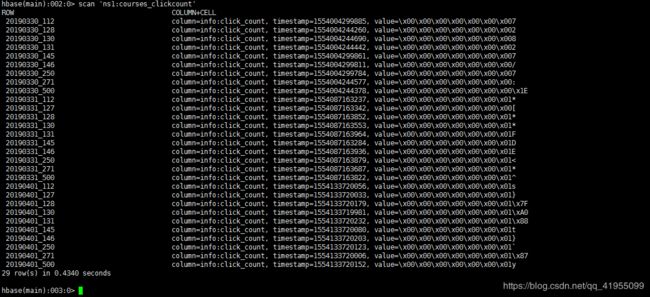
scan 'ns1:courses_clickcount':扫描课程点击统计表,得到如下结果:
scan 'ns1:courses_search_clickcount':扫描搜索引擎搜索统计表,得到如下结果:

至此,后端的代码及测试已经完成。 -
2.前端开发实战
1.构建工程
构建Java Web工程项目,并添加Maven支持。
2.引入依赖
<properties> <hbase.version>1.2.0-cdh5.7.0</hbase.version> <hadoop.version>2.6.0-cdh5.7.0</hadoop.version> <spring.version>4.3.3.RELEASE</spring.version> <spring_mvc.vserion>4.3.3.RELEASE</spring_mvc.vserion> <mybatis.version>3.2.1</mybatis.version> <mysql.version>5.1.17</mysql.version> </properties> <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> </repository> </repositories> <dependencies> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <dependency> <groupId>c3p0</groupId> <artifactId>c3p0</artifactId> <version>0.9.1.2</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>${mybatis.version}</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-context-support</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-jdbc</artifactId> <version>${spring.version}</version> </dependency> <dependency> <groupId>org.springframework</groupId> <artifactId>spring-webmvc</artifactId> <version>${spring_mvc.vserion}</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis-spring</artifactId> <version>1.3.0</version> </dependency> <dependency> <groupId>org.aspectj</groupId> <artifactId>aspectjweaver</artifactId> <version>1.8.10</version> </dependency> <dependency> <groupId>javax.servlet</groupId> <artifactId>jstl</artifactId> <version>1.2</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>net.sf.json-lib</groupId> <artifactId>json-lib</artifactId> <version>2.4</version> <classifier>jdk15</classifier> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-databind</artifactId> <version>2.9.3</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-core</artifactId> <version>2.9.3</version> </dependency> <dependency> <groupId>com.fasterxml.jackson.core</groupId> <artifactId>jackson-annotations</artifactId> <version>2.9.3</version> </dependency> </dependencies>3.创建MySQL表
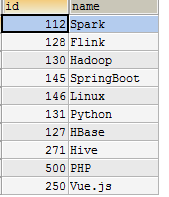
创建course用于根据课程id(HBase存储的数据)查询课程名:
create table course(id int,name varchar(30))
插入数据后得到如下表格:
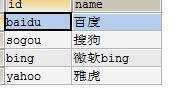
创建course用于根据搜索引擎id(HBase存储的数据)查询搜索引擎名:
create table search_engine(id varchar(10),name varchar(30))
插入数据后得到如下表格:
4.配置SSM框架
(1). 在resources目录下创建如下xml文件:
(2). 在Web/WEB-INF 下创建dispatcher-servlet.xml:

(3). 以上xml文件的完整内容:
beans.xml:<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx" xmlns:aop="http://www.springframework.org/schema/aop" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx-4.3.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop-4.3.xsd" default-autowire="byType"> <!-- 配置数据源 换成你的数据库url--> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <property name="driverClass" value="com.mysql.jdbc.Driver"/> <property name="jdbcUrl" value="jdbc:mysql://hadoop01:3306/jdbc?user=root&password=root"/> <property name="user" value="root"/> <property name="password" value="root"/> <property name="maxPoolSize" value="20"/> <property name="minPoolSize" value="2"/> <property name="initialPoolSize" value="3"/> <property name="acquireIncrement" value="2"/> </bean> <!-- 配置SessionFactory --> <bean id="SessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <property name="dataSource" ref="dataSource"/> <property name="configLocation" value="classpath:mybatis-config.xml"/> </bean> <!-- 包扫描 --> <context:component-scan base-package="com.ssm.dao,com.ssm.service,com.ssm.dao" /> <!-- 事务管理器 --> <bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource"/> </bean> <!-- 配置事务 --> <tx:advice id="txAdvice" transaction-manager="txManager"> <tx:attributes> <tx:method name="*" propagation="REQUIRED" isolation="DEFAULT"/> </tx:attributes> </tx:advice> <!-- 配置事务切面 --> <aop:config> <aop:advisor advice-ref="txAdvice" pointcut="execution(* *..*Service.*(..))" /> </aop:config>mybatis-config.xml:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <!-- 创建别名关系 --> <typeAliases> <typeAlias type="com.ssm.domain.Course" alias="_Course"/> <typeAlias type="com.ssm.domain.SearchEngine" alias="_SearchEngine"/> </typeAliases> <!-- 创建映射关系 --> <mappers> <mapper resource="CourseMapper.xml"/> <mapper resource="SearchEngineMapper.xml"/> </mappers> </configuration>CourseMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 定义名字空间 --> <mapper namespace="course"> <select id="findCourseName" parameterType="int" resultType="_Course"> select id,`name` from course where id = #{id} </select> </mapper>SearchEngineMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 定义名字空间 --> <mapper namespace="searchEngine"> <select id="findEngineName" parameterType="String" resultType="_SearchEngine"> select `name` from search_engine where id = #{name} </select> </mapper>dispatcher-servlet.xml:
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mvc="http://www.springframework.org/schema/mvc" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/mvc http://www.springframework.org/schema/mvc/spring-mvc-4.3.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd"> <!-- 配置包扫描路径 --> <context:component-scan base-package="com.ssm.controller"/> <!-- 配置使用注解驱动 --> <mvc:annotation-driven /> <mvc:default-servlet-handler/> <!-- 配置视图解析器 --> <bean class="org.springframework.web.servlet.view.InternalResourceViewResolver"> <property name="prefix" value="/"/> <property name="suffix" value=".jsp"/> </bean> </beans>(4). 配置Web/WEB-INF/web.xml:
<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd" version="4.0"> <!-- 指定spring的配置文件beans.xml --> <context-param> <param-name>contextConfigLocation</param-name> <param-value>classpath:beans.xml</param-value> </context-param> <!-- 确保web服务器启动时,完成spring的容器初始化 --> <listener> <listener-class>org.springframework.web.context.ContextLoaderListener</listener-class> </listener> <!-- 配置分发器 --> <servlet> <servlet-name>dispatcher</servlet-name> <servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>dispatcher</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> </web-app>至此,SSM整合配置已经完成。
5.创建工程包结构
在java目录下创建以下包结构:
6.编写代码
(1). 在util包下新健Java类 HBaseUtils用于访问HBase,完整代码如下:
public class HBaseUtils { private Configuration configuration = null; private Connection connection = null; private static HBaseUtils hBaseUtil = null; private HBaseUtils(){ try { configuration = new Configuration(); //zookeeper服务器的地址 configuration.set("hbase.zookeeper.quorum","hadoop01:2181"); connection = ConnectionFactory.createConnection(configuration); }catch (Exception e){ e.printStackTrace(); } } /** * 获得HBaseUtil实例 * @return */ public static synchronized HBaseUtils getInstance(){ if(hBaseUtil == null){ hBaseUtil = new HBaseUtils(); } return hBaseUtil; } /** * 根据表名获得表对象 */ public HTable getTable(String tableName){ try { HTable table = null; table = (HTable)connection.getTable(TableName.valueOf(tableName)); return table; }catch (Exception e){ e.printStackTrace(); } return null; } /** * 根据日期查询统计结果 */ public Map<String,Long> getClickCount(String tableName,String date){ Map<String,Long> map = new HashMap<String, Long>(); try { //得到表实例 HTable table = getInstance().getTable(tableName); //列族 String cf = "info"; //列 String qualifier = "click_count"; //定义扫描器前缀过滤器,只扫描给定日期的row Filter filter = new PrefixFilter(Bytes.toBytes(date)); //定义扫描器 Scan scan = new Scan(); scan.setFilter(filter); ResultScanner results = table.getScanner(scan); for(Result result:results){ //取出rowKey String rowKey = Bytes.toString(result.getRow()); //取出点击次数 Long clickCount = Bytes.toLong(result.getValue(cf.getBytes(),qualifier.getBytes())); map.put(rowKey,clickCount); } }catch (Exception e){ e.printStackTrace(); return null; } return map; } }(2). 在domain包下新建以下JavaBean用于封装信息:
Course:/** *课程类,实现Comparable接口用于排序 */ public class Course implements Comparable<Course>{ private int id; //课程编号 private String name; //课程名 private Long count; //点击次数 public Long getCount() { return count; } public void setCount(Long count) { this.count = count; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } /** * 降序排序 */ public int compareTo(Course course) { return course.count.intValue() - this.count.intValue(); } }SearchEngine:
/** * 搜索引擎类 */ public class SearchEngine { private String name; private Long count; public String getName() { return name; } public void setName(String name) { this.name = name; } public Long getCount() { return count; } public void setCount(Long count) { this.count = count; } }(3). 在dao包下新建以下接口:
CourseClickCountDao:/** * 课程统计结果Dao */ public interface CourseClickCountDao { public Set<Course> findCourseClickCount(String tableName, String date); }SearchEngineCountDao:
/** * 索索引擎统计Dao */ public interface SearchEngineCountDao { public List<SearchEngine> findSearchEngineCount(String tableName, String date); }(4). 在dao包下的impl包新建以下Java类实现dao下的接口:
CourseClickCountDaoImpl:/** * 课程点击统计Dao实现类 */ @Repository("CourseClickCountDao") public class CourseClickCountDaoImpl extends SqlSessionDaoSupport implements CourseClickCountDao { public Set<Course> findCourseClickCount(String tableName, String date) { Map<String,Long> map = new HashMap<String, Long>(); Course course = null; Set<Course> set = new TreeSet<Course>(); map = HBaseUtils.getInstance().getClickCount(tableName,date); for (Map.Entry<String, Long> entry : map.entrySet()) { //Rowkey的结构:20190330_112,112为课程的id int id = Integer.parseInt(entry.getKey().substring(9)); //查询课程名并封装进bean course = getSqlSession().selectOne("course.findCourseName",id); //将课程名封装进bean course.setCount(entry.getValue()); set.add(course); } return set; } }CourseClickCountDaoImpl:
/** * 搜索引擎统计Dao实现类 */ @Repository("SearchEngineCountDao") public class SearchEngineCountDaoImpl extends SqlSessionDaoSupport implements SearchEngineCountDao { public List<SearchEngine> findSearchEngineCount(String tableName, String date) { Map<String,Long> map = new HashMap<String, Long>(); List<SearchEngine> list = new ArrayList<SearchEngine>(); SearchEngine searchEngine = null; //调用HBaseUtil查询结果 map = HBaseUtils.getInstance().getClickCount(tableName,date); System.out.println(map); for ( Map.Entry<String, Long> entry : map.entrySet()){ //取出搜索引擎的名字 String name = entry.getKey().split("\\.")[1]; //查询引擎名字,封装进bean searchEngine = getSqlSession().selectOne("searchEngine.findEngineName",name); //把搜索引擎的点击次数封装进bean searchEngine.setCount(entry.getValue()); list.add(searchEngine); } return list; } }(5). 在service包新建如下接口,用于为controller层提供服务:
CourseClickService:/** * 课程点击统计Service类 */ public interface CourseClickService { public List<Course> findCourseClickCount(String tableName, String date); }SearchEngineService:
/** * 搜索引擎点击Service实现类 */ public interface SearchEngineService { public List<SearchEngine> findSearchEngineCount(String tableName, String date); }(6). 在service包下的impl包新建如Java类,实现service包下的接口:
CourseClickServiceImpl :/** * 课程点击统计Service实现类 */ @Service("CourseClickService") public class CourseClickServiceImpl implements CourseClickService { //注入CourseClickCountDaoImpl类 @Resource(name = "CourseClickCountDao") private CourseClickCountDao courseClickCountDao; /** * 将点击率TOP5的课程封装进list */ public List<Course> findCourseClickCount(String tableName, String date) { List<Course> list = new ArrayList<Course>(); //Set集合里的bean根据点击数进行的降序排序 Set<Course> set = courseClickCountDao.findCourseClickCount(tableName,date); Iterator<Course> iterator = set.iterator(); int i = 0; //将TOP5课程封装进list while (iterator.hasNext() && i++ < 5){ list.add(iterator.next()); } return list; } }SearchEngineServiceImpl :
/** * 搜索引擎点击统计Service实现类 */ @Service("SearchEngineService") public class SearchEngineServiceImpl implements SearchEngineService { //注入SearchEngineCountDao @Resource(name = "SearchEngineCountDao") private SearchEngineCountDao searchEngineDao; public List<SearchEngine> findSearchEngineCount(String tableName, String date) { return searchEngineDao.findSearchEngineCount(tableName,date); } }(6). 在controller包中新建以下Java类,用于响应Web的请求:
CourseClickController :/** * 课程点击Controller */ @Controller public class CourseClickController { //注入CourseClickService @Resource(name = "CourseClickService") private CourseClickService service; //页面跳转 @RequestMapping("/courseclick") public String toGetCourceClick(){ return "courseclick"; } /** * sponseBody注解的作用是将controller的方法返回的对象通过适当的转换器转 * 换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML */ @ResponseBody @RequestMapping(value = "/getCourseClickCount",method = RequestMethod.GET) public JSONArray courseClickCount(String date){ //如果url没有传值,传入一个默认值 if(date == null || date.equals("")){ date = "20190330"; } List<Course> list = null; list = service.findCourseClickCount("ns1:courses_clickcount",date); //封装JSON数据 return JSONArray.fromObject(list); } }SearchEngineController :
/** * 搜索引擎点击Controller */ @Controller public class SearchEngineController { //注入SearchEngineService @Resource(name = "SearchEngineService") private SearchEngineService searchEngineService; //页面跳转 @RequestMapping("/searchclick") public String toGetCourceClick(){ return "searchclick"; } /** * sponseBody注解的作用是将controller的方法返回的对象通过适当的转换器转 * 换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML */ @ResponseBody @RequestMapping(value = "/getSearchClickCount",method = RequestMethod.GET) public JSONArray searchClickCount(String date){ //如果url没有传值,传入一个默认值 if(date == null || date.equals("")){ date = "20190330"; } List<SearchEngine> list = null; list = searchEngineService.findSearchEngineCount("ns1:courses_search_clickcount",date); //封装JSON数据 return JSONArray.fromObject(list); } }(6). 在Web目录下新建js目录,引入echarts和jquery(自行去官网下载),在Web目录下新建两个jsp文件courseclick.jsp、searchclick.jsp用于展示数据,得到如下目录:
courseclick.jsp:<%@ page contentType="text/html;charset=UTF-8" language="java" %> <head> <meta charset="UTF-8"/> <!-- 设置每隔60秒刷新一次页面--> <meta http-equiv="refresh" content="60"> <title>学习网实战课程实时访问统计</title> <script src="js/echarts.min.js"></script> <script src="js/jquery-1.11.3.min.js"></script> <style type="text/css"> div{ display: inline; } </style> </head> <body> <div id="main" style="width: 600px;height:400px;float: left;margin-top:50px"></div> <div id="main2" style="width: 700px;height:400px;float: right;margin-top:50px"></div> <script type="text/javascript"> var scources = []; var scources2 = []; var scources3 = []; var scources4 = []; //获得url上参数date的值 function GetQueryString(name) { var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)"); var r = window.location.search.substr(1).match(reg);//search,查询?后面的参数,并匹配正则 if(r!=null)return unescape(r[2]); return null; } var date = GetQueryString("date"); $.ajax({ type:"GET", url:"/getCourseClickCount?date="+date, dataType:"json", async:false, error: function (data) { alert("失败啦"); }, success:function (result) { if(scources.length != 0){ scources.clean(); scources2.clean(); scources3.clean(); scources4.clean(); } for(var i = 0; i < result.length; i++){ scources.push(result[i].name); scources2.push(result[i].count); scources3.push({"value":result[i].count,"name":result[i].name}); } for(var i = 0; i < 3; i++){ scources4.push({"value":result[i].count,"name":result[i].name}); } } }) // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 var option = { title: { text: '学习网实时实战课程访问量', subtext: '课程点击数', x:'center' }, tooltip: {}, /* legend: { data:['点击数'] },*/ xAxis: { data: scources }, yAxis: {}, series: [{ name: '点击数', type: 'bar', data: scources2 }] }; <!--------------------------------------------------------------------------- --> // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); var myChart = echarts.init(document.getElementById('main2')); // 指定图表的配置项和数据 var option = { title: { text: '学习网实时实战课程访问量', subtext: '课程点击数', x:'center' }, tooltip: { trigger: 'item', formatter: "{a}
{b}: {c} ({d}%)" }, legend: { orient: 'vertical', x: 'left'/*, data:scources*/ }, series: [ { name:'课程点击数', type:'pie', selectedMode: 'single', radius: [0, '30%'], label: { normal: { position: 'inner' } }, labelLine: { normal: { show: false } }, data:scources4 }, { name:'课程点击数', type:'pie', radius: ['40%', '55%'], label: { normal: { formatter: '{a|{a}}{abg|}\n{hr|}\n {b|{b}:}{c} {per|{d}%} ', backgroundColor: '#eee', borderColor: '#aaa', borderWidth: 1, borderRadius: 4, rich: { a: { color: '#999', lineHeight: 22, align: 'center' }, hr: { borderColor: '#aaa', width: '100%', borderWidth: 0.5, height: 0 }, b: { fontSize: 16, lineHeight: 33 }, per: { color: '#eee', backgroundColor: '#334455', padding: [2, 4], borderRadius: 2 } } } }, data:scources3 } ] }; // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); </script> </body> </html>courseclick.jsp:
<%@ page contentType="text/html;charset=UTF-8" language="java" %> <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"/> <!-- 设置每隔60秒刷新一次页面--> <meta http-equiv="refresh" content="60"> <title>学习网课程搜索引擎访问统计</title> <script src="js/echarts.min.js"></script> <script src="js/jquery-1.11.3.min.js"></script> <style type="text/css"> div{ display: inline; } </style> </head> <body> <div id="main" style="width: 600px;height:400px;float: left;margin-top:50px"></div> <div id="main2" style="width: 700px;height:400px;float: right;margin-top:50px"></div> <script type="text/javascript"> var scources = []; var scources2 = []; var scources3 = []; //获得url上参数date的值 function GetQueryString(name) { var reg = new RegExp("(^|&)"+ name +"=([^&]*)(&|$)"); var r = window.location.search.substr(1).match(reg);//search,查询?后面的参数,并匹配正则 if(r!=null)return unescape(r[2]); return null; } var date = GetQueryString("date"); $.ajax({ type:"GET", url:"/getSearchClickCount?date="+date, dataType:"json", async:false, success:function (result) { if(scources.length != 0){ scources.clean(); scources2.clean(); scources3.clean(); } for(var i = 0; i < result.length; i++){ scources.push(result[i].name); scources2.push(result[i].count); scources3.push({"value":result[i].count,"name":result[i].name}); } } }) // 基于准备好的dom,初始化echarts实例 var myChart = echarts.init(document.getElementById('main')); // 指定图表的配置项和数据 var option = { title: { text: '学习网实时课程搜索引擎访问量', subtext: '搜索引擎搜索数', x:'center' }, color: ['#3398DB'], tooltip : { trigger: 'axis', axisPointer : { // 坐标轴指示器,坐标轴触发有效 type : 'shadow' // 默认为直线,可选为:'line' | 'shadow' } }, grid: { left: '3%', right: '4%', bottom: '3%', containLabel: true }, xAxis : [ { type : 'category', data : scources, axisTick: { alignWithLabel: true } } ], yAxis : [ { type : 'value' } ], series : [ { name:'直接访问', type:'bar', barWidth: '60%', data:scources2 } ] }; <!--------------------------------------------------------------------------- --> // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); var myChart = echarts.init(document.getElementById('main2')); // 指定图表的配置项和数据 var option = { title : { text: '学习网搜索引擎搜索图', subtext: '搜索引擎使用比例', x:'center' }, tooltip : { trigger: 'item', formatter: "{a}
{b} : {c} ({d}%)" }, legend: { x : 'center', y : 'bottom', data:scources }, toolbox: { show : true, feature : { mark : {show: true}, dataView : {show: true, readOnly: false}, magicType : { show: true, type: ['pie', 'funnel'] }, restore : {show: true}, saveAsImage : {show: true} } }, calculable : true, series : [ { name:'搜索数', type:'pie', radius : [20, 110], center : ['25%', '50%'], roseType : 'radius', label: { normal: { show: false }, emphasis: { show: true } }, lableLine: { normal: { show: false }, emphasis: { show: true } }, data:scources3 }, { name:'搜索数', type:'pie', radius : [30, 110], center : ['75%', '50%'], roseType : 'area', data:scources3 } ] }; // 使用刚指定的配置项和数据显示图表。 myChart.setOption(option); </script> </body> </html>
五、项目结果展示
1.启动前端Web项目的TomCat服务器,在url地址栏中输入查询的日期:
![]()
2.得到如下漂亮的展示结果:

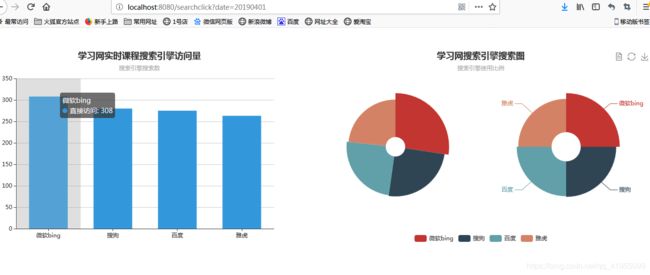
配合页面每隔60秒刷新一次数据,后台数据每隔60秒产生一批,Spark Streaming每隔60秒处理一批数据,形成了数据实时产生实时处理实时展示的。
六、总结
- 1.在本项目中,我们从后端到前端,由里到外系统地学习了大数据实时流处理的流程,总结一下过程如下后台每隔60s执行一次python脚本产生一批用户日志存储在目标文件中 -> Flume监控目标文件并收集 -> 收集后的日志传给Kafka -> Spark Streaming消费Kafka的数据处理完将结果写入HBase,前端SSM整合读取HBase的数据,并且响应jsp页面的Ajax请求,将数据以JSON格式发给前端页面,最后前端页面使用Echarts展示数据。
2.本项目只是实现了其中的两个功能,但是还可以挖掘更多的功能,比如统计IP
地址来获取每个省份最受欢迎课程TOP3,及每门课程在哪个省份最受欢迎等等,能够分析中很多具有价值的信息,这也是大数据魅力值所在! - 更多内容请阅读 萧邦主的技术博客导航