Linux下MFS分布式文件系统中mfsmaster的高可用(mfs软件包的版本为3.103-1)
续我的上上上篇博文:https://mp.csdn.net/postedit/89097868。即MFS分布式文件系统已经安装部署好
一、部署mfsmaster高可用的原因:
在讲原因之前,可以先看看mfs读写原理图:
读操作
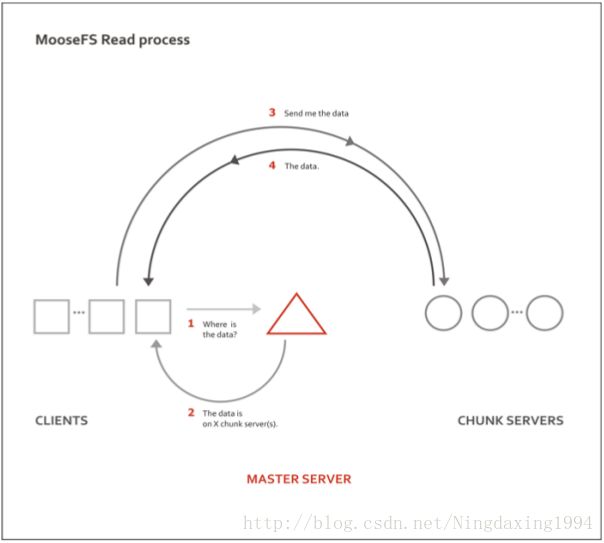
写操作

通过读写操作图可以清楚的看到,mfsmaster是调度器,是mfs最核心的地方,如果mfsmaster挂了,整个mfs架构会挂掉,对此我们要对mfsmaster进行高可用冗余操作。
MFS文件系统中,master负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复。多节点拷贝,是MFS的关键点,显然有极大可能存在单点故障。虽然有Metalogger,但是不能实现故障实时切换,服务要停止之后在Metalogger恢复元数据以及changelog_ml.*.mfs(服务器的变化日志文件),再次重新指定新的mfsmaster节点。
可以采用keepalived实现,但是要注意的是不仅仅是VIP的漂移,mfsmaster的工作目录都要进行漂移,这就涉及存储的共享,在这里采用pacemaker+corosync来实现故障切换)
构建思路:利用pacemaker构建高可用平台,利用iscis做共享存储,mfschunkserver做存储设备。
有人可能要问为什么不用keepalived,我想说的是就是keepalived是可以完全做的,但是keepalived不具备对服务的健康检查;整个corosync验证都是脚本编写的,再通过vrrp_script模块进行调用,利用pacemaker比较方便。
二、实验环境(rhel7.3版本)
1、selinux和firewalld状态为disabled
2、各主机信息如下:
| 主机 | ip |
|---|---|
| server1(mfsmaster,pacemaker,iscsi客户端) | 172.25.83.1 |
| server2(mfschunkserever1,iscsi服务端) | 172.25.83.2 |
| server3(mfschunkserever2) | 172.25.83.3 |
| server4(mfsmaster-backup,pacemaker,iscsi客户端) | 172.25.83.4 |
| 物理机(client) | 172.25.83.83/172.25.254.83 |
本来iscsi客户端是要在另外一台虚拟机上进行操作的,这里为了方便,直接将server2作为iscsi的服务端
3、停掉之前mfs分布式文件系统启动的服务,并卸载客户端挂载的目录。为后续的pcs集群做准备
#客户端
[root@foundation83 ~]# umount /mnt/mfsmeta
[root@foundation83 ~]# umount /mnt/mfs
#server2端
[root@server2 ~]# systemctl stop moosefs-chunkserve
#server3端
[root@server3 ~]# systemctl stop moosefs-chunkserve
#server1端(moosefs-cgiserv服务可以不用关闭,因为moosefs-cgisev服务只是用来提供web界面的)
[root@server1 ~]# systemctl stop moosefs-master
三、mfsmaster高可用的实现
首先要搭建基础的mfs分布式存储架构,本篇不做阐述。可以查看我的上篇博文。这里只需要在上篇博文的基础上添加server4作为mfsmaster-backup端即可。
[root@server1 ~]# scp moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm server4: #从server1端拷贝mfsmaster端需要安装的软件
[root@server4 ~]# ls
moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm
[root@server4 ~]# rpm -ivh moosefs-master-3.0.103-1.rhsystemd.x86_64.rpm #安装软件
[root@server4 ~]# vim /etc/hosts #编辑本地解析文件
172.25.83.1 server1 mfsmaster
[root@server4 ~]# vim /usr/lib/systemd/system/moosefs-master.service #修改moosefs-master服务的启动脚本
8 ExecStart=/usr/sbin/mfsmaster start #修改之前的内容
8 ExecStart=/usr/sbin/mfsmaster -a #修改之后的内容
[root@server4 ~]# systemctl daemon-reload
[root@server4 ~]# systemctl start moosefs-master #检查脚本是否有错误,即查看moosefs-master服务是否能够正常启动
[root@server4 ~]# systemctl stop moosefs-master #关闭moosefs-master服务,以便后续实验的开展
1、首先配置 iscsi客户端共享存储:
配置server2(iscsi服务端):
<1>添加一块新的磁盘,用于共享
[root@server2 ~]# fdisk -l #看到新添加的磁盘为/dev/vda
Disk /dev/vda: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
<2>对iscsi进行配置
[root@server2 ~]# yum install targetcli -y
[root@server2 ~]# systemctl start target
[root@server2 ~]# targetcli
targetcli shell version 2.1.fb41
Copyright 2011-2013 by Datera, Inc and others.
For help on commands, type 'help'.
/> ls
o- / .............................................................. [...]
o- backstores ................................................... [...]
| o- block ....................................... [Storage Objects: 0]
| o- fileio ...................................... [Storage Objects: 0]
| o- pscsi ....................................... [Storage Objects: 0]
| o- ramdisk ..................................... [Storage Objects: 0]
o- iscsi ................................................. [Targets: 0]
o- loopback .............................................. [Targets: 0]
/> backstores/block create my_disk1 /dev/vda #my_disk1这个名字随意给
/> iscsi/ create iqn.2019-04.com.example:server2 #iqn.2019-04.com.example:server2这个名字随意给,但格式要正确
/> iscsi/iqn.2019-04.com.example:server2/tpg1/acls create iqn.2019-04.com.example:client #iqn.2019-04.com.example:client这个名字随意给
/> iscsi/iqn.2019-04.com.example:server2/tpg1/luns create /backstores/block/my_disk1
/> ls
o- / .............................................................. [...]
o- backstores ................................................... [...]
| o- block ....................................... [Storage Objects: 1]
| | o- my_disk1 ............. [/dev/vda (20.0GiB) write-thru activated]
| o- fileio ...................................... [Storage Objects: 0]
| o- pscsi ....................................... [Storage Objects: 0]
| o- ramdisk ..................................... [Storage Objects: 0]
o- iscsi ................................................. [Targets: 1]
| o- iqn.2019-04.com.example:server2 ........................ [TPGs: 1]
| o- tpg1 .................................... [no-gen-acls, no-auth]
| o- acls ............................................... [ACLs: 1]
| | o- iqn.2019-04.com.example:client ............ [Mapped LUNs: 1]
| | o- mapped_lun0 ................... [lun0 block/my_disk1 (rw)]
| o- luns ............................................... [LUNs: 1]
| | o- lun0 ........................... [block/my_disk1 (/dev/vda)]
| o- portals ......................................... [Portals: 1]
| o- 0.0.0.0:3260 .......................................... [OK]
o- loopback .............................................. [Targets: 0]
配置server1(iscsi客户端):
<1>安装iscsi客户端需要安装的软件,对其进行配置,并登录
[root@server1 ~]# yum install iscsi-* -y #其实就一个包
[root@server1 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-04.com.example:client
[root@server1 ~]# iscsiadm -m discovery -t st -p 172.25.83.2
172.25.83.2:3260,1 iqn.2019-04.com.example:server2
[root@server1 ~]# iscsiadm -m node -l #或者命令"iscsiadm -m node -T qn.2019-04.com.example:server2 -p 172.25.83.2 -l"
Logging in to [iface: default, target: iqn.2019-04.com.example:server2, portal: 172.25.83.2,3260] (multiple)
Login to [iface: default, target: iqn.2019-04.com.example:server2, portal: 172.25.83.2,3260] successful.
[root@server1 ~]# fdisk -l /dev/sda
Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
<2>对服务端共享出来的磁盘(这里是/dev/sda)进行操作(分区,格式化,挂载)
#server1端的操作
[root@server1 ~]# fdisk /dev/sda #给磁盘/dev/sda进行分区,当然也可以不分区
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p):
Using default response p
Partition number (1-4, default 1):
First sector (2048-41943039, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-41943039, default 41943039):
Using default value 41943039
Partition 1 of type Linux and of size 20 GiB is set
Command (m for help): wq
The partition table has been altered!
[root@server1 ~]# mkfs.xfs /dev/sda1 #格式化磁盘分区
meta-data=/dev/sda1 isize=512 agcount=4, agsize=1310656 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5242624, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@server1 ~]# mount /dev/sda1 /mnt/ #下面对mnt目录以及其中的内容进行的修改相当于对/dev/sda1这块磁盘进行修改
[root@server1 ~]# cp -p /var/lib/mfs/* /mnt/ #使用-p同步权限,所属用户和所属组必须是mfs
[root@server1 ~]# ll /mnt/
total 3632
-rw-r----- 1 mfs mfs 87 Apr 8 17:49 changelog.11.mfs
-rw-r----- 1 mfs mfs 553 Apr 9 00:31 changelog.1.mfs
-rw-r----- 1 mfs mfs 139 Apr 8 21:22 changelog.4.mfs
-rw-r----- 1 mfs mfs 378 Apr 8 20:46 changelog.5.mfs
-rw-r----- 1 mfs mfs 2800 Apr 8 20:29 changelog.7.mfs
-rw-r----- 1 mfs mfs 186 Apr 8 19:54 changelog.8.mfs
-rw-r----- 1 mfs mfs 84 Apr 8 18:01 changelog.9.mfs
-rw-r----- 1 mfs mfs 120 Apr 9 00:32 metadata.crc
-rw-r----- 1 mfs mfs 3443 Apr 9 00:32 metadata.mfs
-rw-r----- 1 mfs mfs 3644 Apr 9 00:00 metadata.mfs.back.1
-rw-r--r-- 1 mfs mfs 8 Nov 23 20:46 metadata.mfs.empty
-rw-r----- 1 mfs mfs 3672832 Apr 9 00:32 stats.mfs
[root@server1 ~]# chown mfs.mfs /mnt #修改/mnt目录的所属用户和所属组为mfs(相当于修改的是磁盘/dev/sda1)
[root@server1 ~]# ll -d /mnt/
drwxr-xr-x 2 mfs mfs 278 Apr 9 11:54 /mnt/
[root@server1 ~]# umount /mnt
[root@server1 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server1 ~]# df
/dev/sda1 20960256 36576 20923680 1% /var/lib/mfs
#验证moosefs-master服务是否可以正常启动,因为/var/lib/mfs目录中的文件是挂载过来的。
[root@server1 ~]# systemctl start moosefs-master
[root@server1 ~]# ps ax
18708 ? S< 0:00 /usr/sbin/mfsmaster -a
[root@server1 ~]# systemctl stop moosefs-master
配置server4(iscsi客户端):
<1>安装iscsi客户端需要安装的软件,对其进行配置,并登录
[root@server4 ~]# yum install iscsi-* -y
[root@server4 ~]# vim /etc/iscsi/initiatorname.iscsi
InitiatorName=iqn.2019-04.com.example:client
[root@server4 ~]# iscsiadm -m discovery -t st -p 172.25.83.2
[root@server4 ~]# iscsiadm -m node -l #或者命令"iscsiadm -m node -T qn.2019-04.com.example:server2 -p 172.25.83.2 -l"
[root@server4 ~]# fdisk -l /dev/sda
Disk /dev/sda: 21.5 GB, 21474836480 bytes, 41943040 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xa7d46268
Device Boot Start End Blocks Id System
/dev/sda1 2048 41943039 20970496 83 Linux
<2>对服务端共享出来的磁盘(这里是/dev/sda1)进行挂载操作
[root@server4 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server4 ~]# df
/dev/sda1 20960256 36580 20923676 1% /var/lib/mfs
#验证moosefs-master服务是否可以正常启动,因为/var/lib/mfs目录中的文件是挂载过来的。
[root@server4 ~]# systemctl start moosefs-master
[root@server4 ~]# ps aux
mfs 6519 1.4 58.4 604540 461620 ? S< 13:48 0:00 /usr/sbin/mfsmaster -a
[root@server4 ~]# systemctl stop moosefs-master
2、配置 pacemaker+corosync+pcs:
配置server1和server4:
<1>首先要配置高可用的yum源:
[root@foundation83 ~]# cd /var/www/html/rhel7.3/
[root@foundation83 rhel7.3]# ls
addons EULA images LiveOS Packages repodata RPM-GPG-KEY-redhat-release
EFI GPL isolinux media.repo release-notes RPM-GPG-KEY-redhat-beta TRANS.TBL
[root@foundation83 rhel7.3]# find -name *.rpm #目的是查找corosync和pacemaker对应的rpm包的位置
./addons/HighAvailability/pacemaker-1.1.15-11.el7.x86_64.rpm
./addons/ResilientStorage/corosync-2.4.0-4.el7.x86_64.rpm
[root@server1 ~]# vim /etc/yum.repos.d/dvd.repo #在文件的最后添加如下的yum源,虽然下面的yum源中的内容也是系统自带的,但因为不再Packages这个目录中,所以需要手动添加如下的yum源。
[HighAvailability]
name=HighAvailability
baseurl=http://172.25.83.83/rhel7.3/addons/HighAvailability
gpgcheck=0
enabled=1
[ResilientStorage]
name=ResilientStorage
baseurl=http://172.25.83.83/rhel7.3/addons/ResilientStorage
gpgcheck=0
enabled=1
[root@server1 ~]# scp /etc/yum.repos.d/dvd.repo server4:/etc/yum.repos.d/dvd.repo #将此yum源发送到server4端- 验证yum源是否添加成功
<2>安装pacemaker+corosync+pcs,开启pcsd服务,并设置pcsd服务开机自启:
#在server1端安装软件pacemaker,corosync和pcs(集群化管理工具)
[root@server1 ~]# yum install pacemaker corosync -y
[root@server1 ~]# yum install pcs -y
#在server1端开启pcsd服务,并设置为开机自启
[root@server1 ~]# systemctl start pcsd
[root@server1 ~]# systemctl enable pcsd
#server4端的操作同server1端
<3>安装完pacemaker+corosync+pcs软件之后,会自动生成hacluster用户。为集群用户hacluster设置密码
[root@server1 ~]# passwd hacluster
Changing password for user hacluster.
New password: #我这里设置的密码为hacluster
BAD PASSWORD: The password contains the user name in some form
Retype new password:
passwd: all authentication tokens updated successfully.
#server4端的操作同server1。
值的注意的是server1端hacluster用户的密码必须和server4端hacluster用户的密码相同
<4>设置server1——>server1,server1——>server4的免密,为后续集群各节点之间的认证做准备。
[root@server1 ~]# ssh-keygen #一路敲击回车
[root@server1 ~]# ssh-copy-id server1
[root@server1 ~]# ssh-copy-id server4
[root@server1 ~]# ssh server1 #验证免密是否成功
Last login: Mon Apr 8 11:24:34 2019 from foundation83.ilt.example.com
[root@server1 ~]# logout
Connection to server1 closed.
[root@server1 ~]# ssh server4
Last login: Mon Apr 8 21:10:56 2019 from foundation83.ilt.example.com
[root@server4 ~]# logout
Connection to server4 closed.
<5>集群各节点(这里是server1和server4)之间进行认证:
[root@server1 ~]# pcs cluster auth server1 server4
Username: hacluster (此处需要输入的用户名必须为pcs自动创建的hacluster,其他用户不能添加成功)
Password:
server4: Authorized
server1: Authorized
<6>创建名为my_cluster的集群,其中server1和server4为集群成员:
[root@server1 ~]# pcs cluster setup --name mycluster server1 server4 #该集群的名字mycluster随意给
Destroying cluster on nodes: server1, server4...
server1: Stopping Cluster (pacemaker)...
server4: Stopping Cluster (pacemaker)...
server4: Successfully destroyed cluster
server1: Successfully destroyed cluster
Sending cluster config files to the nodes...
server1: Succeeded
server4: Succeeded
Synchronizing pcsd certificates on nodes server1, server4...
server4: Success
server1: Success
Restarting pcsd on the nodes in order to reload the certificates...
server4: Success
server1: Success
<7>启动集群,并设置集群开机自启
[root@server1 ~]# pcs cluster start --all #启动集群
server4: Starting Cluster...
server1: Starting Cluster...
[root@server1 ~]# pcs cluster enable --all #设置集群开机自启
server1: Cluster Enabled
server4: Cluster Enabled
<8>查看并设置集群属性:
查看当前集群状态:
pcs cluster status
[root@server1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: server1 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Mon Apr 8 22:23:25 2019 Last change: Mon Apr 8 22:18:31 2019 by hacluster via crmd on server1
2 nodes and 0 resources configured
PCSD Status:
server4: Online
server1: Online
查看集群中节点的状态:
pcs status nodes
[root@server1 ~]# pcs status nodes
Pacemaker Nodes:
Online: server1 server4
Standby:
Maintenance:
Offline:
Pacemaker Remote Nodes:
Online:
Standby:
Maintenance:
Offline:
检查pacemaker服务:
ps aux | grep pacemaker
[root@server1 ~]# ps aux | grep pacemaker
root 22545 0.0 0.6 133124 9252 ? Ss 22:18 0:00 /usr/sbin/pacemakerd -f
haclust+ 22546 0.0 0.9 136280 15064 ? Ss 22:18 0:00 /usr/libexec/pacemaker/cib
root 22547 0.0 0.4 136096 7104 ? Ss 22:18 0:00 /usr/libexec/pacemaker/stonithd
root 22548 0.0 0.3 105584 5056 ? Ss 22:18 0:00 /usr/libexec/pacemaker/lrmd
haclust+ 22549 0.0 0.5 127408 7672 ? Ss 22:18 0:00 /usr/libexec/pacemaker/attrd
haclust+ 22550 0.0 1.3 153588 20904 ? Ss 22:18 0:00 /usr/libexec/pacemaker/pengine
haclust+ 22551 0.0 0.7 186844 11660 ? Ss 22:18 0:00 /usr/libexec/pacemaker/crmd
root 23451 0.0 0.0 112648 956 pts/0 R+ 22:25 0:00 grep --color=autopacemaker
检验corosync的安装及当前corosync状态:
corosync-cfgtool -s
pcs status corosync
[root@server1 ~]# corosync-cfgtool -s
Printing ring status.
Local node ID 1
RING ID 0
id = 172.25.83.1
status = ring 0 active with no faults
[root@server1 ~]# pcs status corosync
Membership information
----------------------
Nodeid Votes Name
1 1 server1 (local)
2 1 server4
检查配置是否正确(假若没有输出任何则配置正确):
crm_verify -L -V
[root@server1 ~]# crm_verify -L -V #这里的错误是由于没有设置fence导致的
error: unpack_resources: Resource start-up disabled since no STONITH resources have been defined
error: unpack_resources: Either configure some or disable STONITH with the stonith-enabled option
error: unpack_resources: NOTE: Clusters with shared data need STONITH to ensure data integrity
Errors found during check: config not valid
查看我们创建的集群:
pcs status
[root@server1 ~]# pcs status
Cluster name: mycluster #我们之前创建的集群的名字
WARNING: no stonith devices and stonith-enabled is not false #有一处警告,该警告的含义是:没有设置fence
Stack: corosync
Current DC: server1 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Mon Apr 8 23:14:46 2019 Last change: Mon Apr 8 22:18:31 2019 by hacluster via crmd on server1
2 nodes and 0 resources configured
Online: [ server1 server4 ]
No resources #我们还没有添加资源,所以资源这里什么都没有
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
禁用STONITH:
pcs property set stonith-enabled=false
[root@server1 ~]# pcs property set stonith-enabled=false
禁用STONITH之后,再次检查配置,发现没有错误;再次查看我们创建的集群,发现没有警告
[root@server1 ~]# crm_verify -L -V #没有报错
[root@server1 ~]# pcs status #没有警告
Cluster name: mycluster
Stack: corosync
Current DC: server1 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Mon Apr 8 23:23:21 2019 Last change: Mon Apr 8 23:21:32 2019 by root via cibadmin on server1
2 nodes and 0 resources configured
Online: [ server1 server4 ]
No resources
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
<9>查看的内容:pcs resource资源属性配置(不需要进行操作)
Pacemaker / Corosync 是 Linux 下一组常用的高可用集群系统。Pacemaker 本身已经自带了很多常用应用的管理功能。但是如果要使用 Pacemaker 来管理自己实现的服务或是一些别的没现成的东西可用的服务时,就需要自己实现一个资源了。
其中Pacemaker 自带的资源管理程序都在 /usr/lib/ocf/resource.d 下。其中的 heartbeat 目录中就包含了那些自带的常用服务。那些服务的脚本可以作为我们自己实现时候的参考。更多关于自定义资源请参考博文:http://blog.csdn.net/tantexian/article/details/50160159
接下来针对一些常用的pcs命令进行简要讲解。
查看pcs resource针对资源操作用法: pcs resource help 查看pcs支持的资源代理标准: pcs resource standards [root@server1 ~]# pcs resource standards ocf lsb service systemd 注:Pacemaker 的资源主要有ocf、lsb、service、systemd几大类。LSB是为了促进Linux不同发行版间的兼容性, LSB(Linux Standards Base)开发了一系列标准,使各种软件可以很好地在兼容LSB标准的系统上运行, LSB即Linux标准服务, 通常就是/etc/init.d目录下那些脚本。Pacemaker可以用这些脚本来启停服务,可以通过pcs resource list lsb查看。 另一类OCF实际上是对LSB服务的扩展,增加了一些高可用集群管理的功能如故障监控等和更多的元信息。可以通过pcs resource list ocf看到当前支持的资源。 要让pacemaker可以很好的对服务进行高可用保障就得实现一个OCF资源。CentOS7使用systemd替换了SysV。Systemd目的 是要取代Unix时代以来一直在使用的init系统,兼容SysV和LSB的启动脚本,而且够在进程启动过程中更有效地引导加载服务。 查看默认资源管理器: pcs resource providers [root@server1 ~]# pcs resource providers heartbeat openstack pacemaker 查看某个资源的代理: pcs resource agents [standard[:provider]] [root@server1 ~]# pcs resource agents ocf:heartbeat #查看ocf:heartbeat这个资源的代理 查看pacemaker支持资源高可用的列表: pcs resource list
<10>开始配置我们的mfsmaster高可用(主/备)
(1)添加资源:vip
首先要做的是配置一个IP地址,不管集群服务在哪运行,我们要一个固定的地址来提供服务。在这里我选择 172.25.83.100作为浮动IP,给它取一个好记的名字vip 并且告诉集群每30秒检查它一次。
另外一个重要的信息是 ocf:heartbeat:IPaddr2。这告诉Pacemaker三件事情,第一个部分ocf,指明了这个资源采用的标准(类型)以及在哪能找到 它。第二个部分标明这个资源脚本的在ocf中的名字空间,在这个例子中是heartbeat。最后一个部分指明了资源脚本的名称。
[root@server1 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.83.100 cidr_netmask=32 op monitor interval=30s #其中vip这个资源的名字随意给
查看添加vip资源后的情况
[root@server1 ~]# pcs status #查看我们创建的集群,一个vip现在已经在server1上运行
Cluster name: mycluster
Stack: corosync
Current DC: server1 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Tue Apr 9 00:03:33 2019 Last change: Tue Apr 9 00:01:46 2019 by root via cibadmin on server1
2 nodes and 1 resource configured
Online: [ server1 server4 ]
Full list of resources:
vip (ocf::heartbeat:IPaddr2): Started server1 #添加的资源vip
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled[root@server1 ~]# pcs resource #查看我们创建好的资源,一个vip现在已经在server1上运行
vip (ocf::heartbeat:IPaddr2): Started server1
[root@server1 ~]# pcs resource show #同命令"pcs resource"
vip (ocf::heartbeat:IPaddr2): Started server1[root@server1 ~]# ip addr show eth0 #可以看到172.25.83.100这个ip
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:c5:33:5c brd ff:ff:ff:ff:ff:ff
inet 172.25.83.1/24 brd 172.25.83.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.83.100/32 brd 172.25.83.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fec5:335c/64 scope link
valid_lft forever preferred_lft forever 当然也可以在server4端打开监控,来实时监控集群中资源的状态
[root@server4 ~]# crm_mon #使用Ctrl+c退出监控
Stack: corosync
Current DC: server1 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Tue Apr 9 00:11:51 2019 Last change: Tue Apr 9 00:01:46 20
19 by root via cibadmin on server1
2 nodes and 1 resource configured
Online: [ server1 server4 ]
Active resources:
vip (ocf::heartbeat:IPaddr2): Started server1 #我们可以看到vip在server1上运行
为了验证vip这个资源的高可用,我们停掉pcs集群中的server1端,看vip是否在server4上运行
[root@server1 ~]# pcs cluster stop server1
server1: Stopping Cluster (pacemaker)...
server1: Stopping Cluster (corosync)...
#查看server4端的监控
Stack: corosync
Current DC: server4 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Tue Apr 9 00:14:53 2019 Last change: Tue Apr 9 00:01:46 20
19 by root via cibadmin on server1
2 nodes and 1 resource configured
Online: [ server4 ]
OFFLINE: [ server1 ]
Active resources:
vip (ocf::heartbeat:IPaddr2): Started server4 #从监控界面我们可以看到vip已经在server4上运行
[root@server4 ~]# ip addr show eth0 #当然vip(172.25.83.100)也已经存在于server4端的网卡上
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:f3:bd:01 brd ff:ff:ff:ff:ff:ff
inet 172.25.83.4/24 brd 172.25.83.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.83.100/32 brd 172.25.83.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fef3:bd01/64 scope link
valid_lft forever preferred_lft forever
为了查看是否回切,我们打开pcs集群中的server1端,看vip是在server4上运行还是在server1上运行
[root@server1 ~]# pcs cluster start server1
#在server4端查看监控
Stack: corosync
Current DC: server4 (version 1.1.15-11.el7-e174ec8) - partition with quorum
Last updated: Tue Apr 9 00:21:20 2019 Last change: Tue Apr 9 00:01:46 20
19 by root via cibadmin on server1
2 nodes and 1 resource configured
Online: [ server1 server4 ]
Active resources:
vip (ocf::heartbeat:IPaddr2): Started server4 #我们看到vip仍在server4上运行,也就验证了不回切
(2)添加资源:mfsdata(挂载信息)
[root@server1 ~]# pcs resource create mfsdata ocf:heartbeat:Filesystem device=/dev/sda1 directory=/var/lib/mfs fstype=xfs op monitor interval=30s
(3)添加资源:mfsd(启动moosefs-master服务)
[root@server1 ~]# pcs resource create mfsd systemd:moosefs-master op monitor interval=1min
在上述上各资源添加完成之后,在server4端查看监控,监控内容如下:
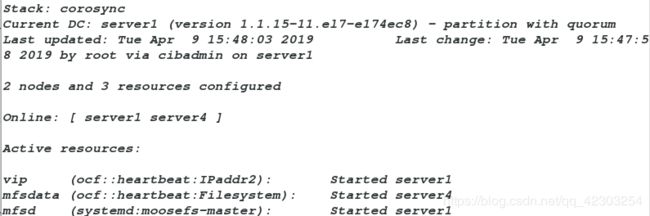
从上图我们可以看到三个资源(vip,mfsdata,mfsd)不在同一个服务端运行,这显然是不合理的。因此需要进行下面的操作,将这三个资源添加到一个资源组中
(4)将上述三个资源添加到一个资源组中:确保资源在同一个节点运行
[root@server1 ~]# pcs resource group add mfsgroup vip mfsdata mfsd #添加资源vip,mfsdata,mfsd到同一个资源组mfsgroup中。(其中mfsgroup这个资源组的名字是随意给的)
#其中添加的顺序是有严格限制的,按照资源添加的顺序,进行添加。就如同前面做过的实验RHCS套件一样。
再次在server4端查看监控,监控内容如下:
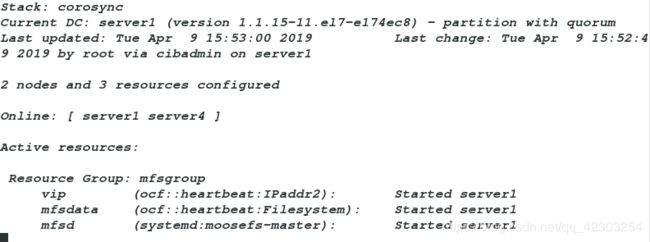
从上图我们可以看到三个资源在同一个服务端运行,表示配置正确。
为了验证该集群的高可用,我们停掉pcs集群中的server1端,看这三个资源是否在server4上运行
[root@server1 ~]# pcs cluster stop server1此时,我们查看监控,监控内容如下:
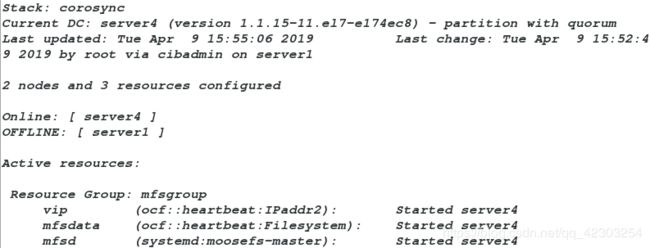
我们可以看到三个资源都在server4端运行,表示配置成功
3、修改server1,server2,server3,server4,物理机的本地解析文件:
#server1端
[root@server1 ~]# vim /etc/hosts
172.25.83.1 server1
172.25.83.100 mfsmaster
#server2端,server3端,server4端的操作同server1
#物理机
[root@foundation83 ~]# vim /etc/hosts
172.25.83.100 mfsmaster
4、开启server2和server3端的moosefs-chunkserver服务
[root@server2 ~]# systemctl start moosefs-chunkserver
[root@server3 ~]# systemctl start moosefs-chunkserver
5、在客户端(物理机)进行测试:
[root@foundation83 ~]# mfsmount
[root@foundation83 ~]# df
mfsmaster:9421 35622912 3052288 32570624 9% /mnt/mfs
[root@foundation83 ~]# cd /mnt/mfs
[root@foundation83 mfs]# ls
dir1 dir2
[root@foundation83 mfs]# ls dir1/
bigfile bigfile2 passwd
[root@foundation83 mfs]# ls dir2
passwd- 访问浏览器,看到的内容
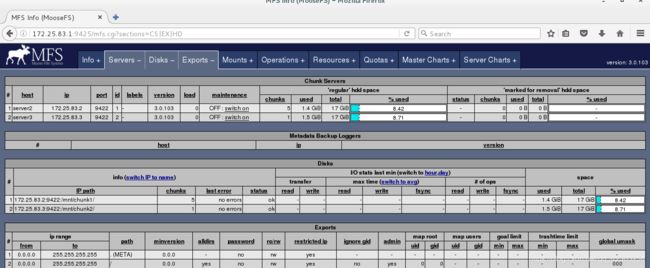
客户端挂载之后,在/mnt/mfs目录中有之前存在chunkserver端的内容,并且浏览器访问看到的内容也是正常的,表示配置成功。
为了表现实现mfsmaster高可用的优点,我们进行下面的实验:客户端往mfs分布式文件系统中写入内容,此时服务端(mfsmaster)端挂掉了,我们看看客户端会不会收到影响。
#客户端往mfs分布式文件系统中写内容。
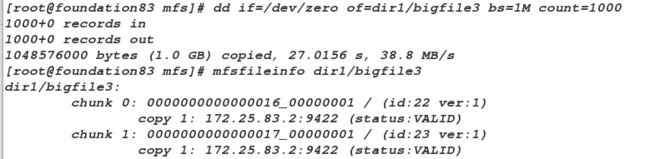
[root@foundation83 mfs]# dd if=/dev/zero of=dir1/bigfile3 bs=1M count=1000
#同时mfsmaster端挂掉mfsmaster服务
[root@server1 ~]# pcs cluster stop server4
#值的注意的是:两端的操作要同时进行,即两端都要卡顿一下- 我们会发现客户端没有受到一丁点的影响,这就是实现mfsmatser高可用的好处