LEGO: Learning Edge with Geometry all at Once by Watching Videos(2018)
LEGO-Net
摘要
人类即使使用单张图像也能准确恢复观察的自然场景的的3D几何结构,并能推广到现实应用,如增强现实和机器人技术。 最近的技术[19 Godard,60 Wang peng,64 T.Zhou ]使用无标注视频或立体图像进行无监督训练比监督训练的单目深度估计效果更好。其核心思想是图像合成,并利用光度差训练。但是如Fig 1所示,没有恢复好场景几何。
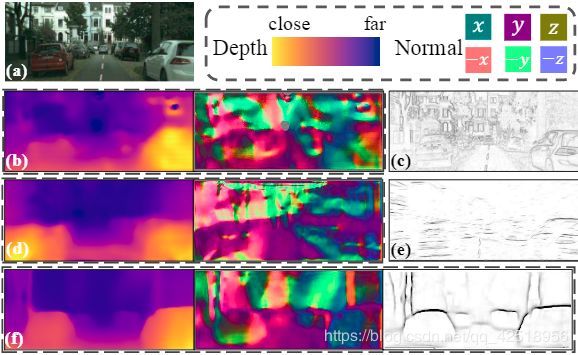
图1:(a)输入图像 (b)[64]的深度和法向量结果 (c)图像梯度的边缘 (d)[60]的深度和法向量 (e)[37]的无监督边缘检测 (f)我们的使用无监督结合深度、法向量、边缘的结果
我们认为这是由于无监督学习更倾向于优化每个像素(every-pixels)的光度差,不太注意几何边缘。使用的“几何边缘”项包括深度不连续处以及表面法向量变化的位置。3D几何通过过滤出同一表面内的内部边缘(图1(c)中的图像梯度的边缘),帮助模型发现中层(mid-level)边缘。反过来,发现的边缘可以帮助几何估计获得长范围的内容感知以及非局部正则化,使模型产生更详细的结果。
根据“as smooth as possible in 3D” (3D-ASAP)先验条件,构建两者之间内在关系,如果像素之间没有明显边缘,那么这些像素点在3D空间应该都在一个平面。 在KITTI 2015 [18], CityScapes [10] and Make3D [45]数据集进行了评估,并且在不同数据集上的迁移能力强。
2 相关工作
Structure from motion 和单目几何
使用特征匹配从video中估计3D的几何方法有SFM [56], SLAM [41, 14] and DTAM [42]。但是对低纹理(low texture),或视角的剧烈变化(drastic change)处理不好。其他单目几何的特殊功能,如:计算消失点[20],BRDF[43,26],或用主要层或box提取场景[47,50],只能获得稀疏的几何关系,并且需要满足很多前提条件(如Lambertian, Manhattan world))
通过CNN监督单目几何
Dense geometry,可以从单张图像中估计每个像素深度及法向量图[54, 12, 34, 36, 16],基于CNN方法比手动提取特征[23,32,31]有明显提高。 其他方法则添加conditional random field (CRF) [52, 38, 35]提升。Wang [53]提出在大平面使用基于dense CRF[28]的depth-normal regularization方法,在深度和法向量都明显提升,但监督学习数据难获得。
无监督单目几何
Deep3D【57】,用立体图像对监督,从左图根据监督合成右图。Garg【17】同样用立体对监督,但是深度是连续的,还是用Taylor展开来近似深度梯度。Godard【19】在Garg之后添加了平滑loss和左右一致性。Zhou【64】加入了相机位姿估计,从而学习单目视频深度,加入了一个解释mask移除动态场景像素。同时Vijayanarasimhan【51】对固定物体运动建模。Yang【60】引入法向量,并提出稠密的depth-normal一致性,但其正则化只应用在局部,并被图像梯度所影响,在平滑表面产生了错误的不连续结果。
Non-local smoothness(非局部光滑)
长范围且非局部的空间调节已经在像CRF[33]的传统图像模型广泛应用,其中不相邻节点被连接在一起并由high-order CRF或densely-connected CRF学习它们之间的相似度。这比只学习局部连接的方法效果要好,如:分割、图像视差、扣图。此外,快速双边滤波器【4】更有效 经过这些方法能够使用CNN作为后处理部分实现[3, 63, 53, 55],但由于其迭代循环效率不高。于是使用多尺度方法【62,7】来解决。
边缘检测
例如Sobel or Canny [6]的低级边缘学习方法,已经被带有语义边缘数据集[39,21]使用监督学习[59, 27, 2, 11]代替。 高层边缘可以通过隐式监督的非局部平滑性来学习,如【8】,通过在CNN后添加空间转换(DT),对平滑度做与CRF类似操作,改善语义分割,但与CRF相似,DT迭代传播到附近像素效率不高。Li【37】则使用光流[44]来得到运动边缘,从而监督边缘模块。
3. Preliminaries
用合成图像作用监督
给出It深度图Dt,经过估计的变换![]() 将Is双线性差值后变换到It平面上,最后比较合成的Is与真实It的光度差,来监督Dt和T。给定视频中多个源图像的集
将Is双线性差值后变换到It平面上,最后比较合成的Is与真实It的光度差,来监督Dt和T。给定视频中多个源图像的集![]() ,光度差定义如下:
,光度差定义如下:
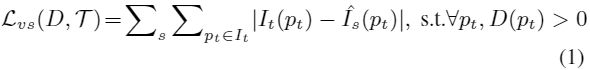
T对应It于每个S中源图像的变换矩阵
深度调节
只基于图像合成的监督是模糊的,因为一个像素可以被投射到多个坐标。之前方法【19,64】鼓励当没有明显图像梯度变化时使估计的梯度局部相似。比如【19 Godard】Dt被定义为了:
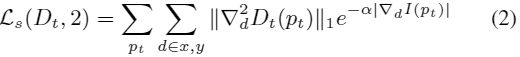
Ls(D,2)是空间平滑项,是在2D空间x和y方向的二阶梯度的L1范数惩罚
用depth-normal 一致性调节
Yang【60】认为当出现类似Fig1(b)这种不能正常表达视觉时,Eq(2)约束不够,从【64】中估计的法向量在地面处出现了变化。因此,他们引入了![]() 的法向量图
的法向量图![]() ,以及在
,以及在![]() 和
和![]() 之间的depth-normal一致性函数
之间的depth-normal一致性函数
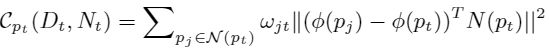
其中![]() 是
是![]() 的八个邻域集,
的八个邻域集,![]() 是从2D坐标
是从2D坐标![]() 反投影的3D点,
反投影的3D点,![]() 是3D空间的向量差,
是3D空间的向量差,![]() 是权重。 基于这个函数,提出了可微的depth-to-normal层,通过给定
是权重。 基于这个函数,提出了可微的depth-to-normal层,通过给定![]() 来估计
来估计![]() ,以及一个normal-to-depth,从
,以及一个normal-to-depth,从![]() 中重估计
中重估计![]() 。通过使用Eq1和Eq2两个损失,加上一阶平滑损失
。通过使用Eq1和Eq2两个损失,加上一阶平滑损失![]() ,
,![]() 可以被监督,而
可以被监督,而![]() 可以由最近的8个区域修改
可以由最近的8个区域修改
4 从video中用几何关系学习边缘
4.1. 3D-ASAP prior
3D-ASAP的核心假设是所有表面都在3D空间![]() ,这个先验对于大的非平面是有限制的,但它适合我们主要处理的街景,如道路、建筑墙壁等主要表面仍然是平面,需要满足以下两条件:
,这个先验对于大的非平面是有限制的,但它适合我们主要处理的街景,如道路、建筑墙壁等主要表面仍然是平面,需要满足以下两条件:
![]()
这意味着,任何这两点![]() 和
和![]() 中间连线的点都在同一个平面内。给定一个目标图像
中间连线的点都在同一个平面内。给定一个目标图像![]() ,从连续平面{S}集合的透视投影,估计的深度图
,从连续平面{S}集合的透视投影,估计的深度图![]() 和法向量图
和法向量图![]() 也需要大致对每个S满足这样的先验。特别是
也需要大致对每个S满足这样的先验。特别是![]() ,图像中任意两像素
,图像中任意两像素![]() 和
和![]() ,同一平面S的
,同一平面S的![]() 和
和![]() 在两者的normal方向应该是相同的,因此约束:
在两者的normal方向应该是相同的,因此约束:
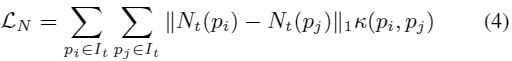
其中![]() 是相似度,如果
是相似度,如果![]() 和
和![]() 在相同S内,值为1否则为0。对于
在相同S内,值为1否则为0。对于![]() ,考虑三者之间关系,Eq(3)所示,给出两个不同像素
,考虑三者之间关系,Eq(3)所示,给出两个不同像素![]() 和
和![]() ,让两者连线中的任一像素
,让两者连线中的任一像素![]() 形成同一个3D line:
形成同一个3D line:
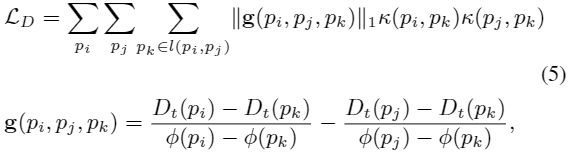
其中![]() 是从2D到3D空间的反投影函数,
是从2D到3D空间的反投影函数,![]() 是pi的齐次坐标。
是pi的齐次坐标。![]() 是pi和pj的连线上的像素集
是pi和pj的连线上的像素集
(LD主要检查三点是否属于同一平面,且共线)
使用多尺度方法估计
如果给出![]() ,比如是图像梯度,我们可以使用这两个能量函数作为深度和法向量的非局部平滑度损失,但由于像素过多不可行。简略办法是,舍去一个像素与其他像素的稠密连接换作周围像素集。本文对每个像素
,比如是图像梯度,我们可以使用这两个能量函数作为深度和法向量的非局部平滑度损失,但由于像素过多不可行。简略办法是,舍去一个像素与其他像素的稠密连接换作周围像素集。本文对每个像素![]() ,在其3D的x和y方向取N=1,2,4,8邻域的法向量和深度进行平滑处理。
,在其3D的x和y方向取N=1,2,4,8邻域的法向量和深度进行平滑处理。![]() 是像素
是像素![]() 进行(x,y)位移,于是
进行(x,y)位移,于是![]() 和
和![]() 变为:
变为:
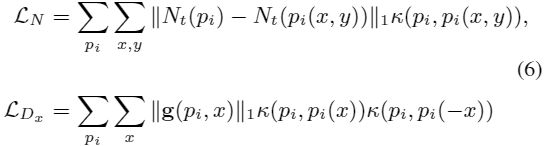
其中![]() 表示沿着x方向的平滑度,
表示沿着x方向的平滑度,![]() 是
是![]() 的简写
的简写
4.2 参数化并学习几何边缘
使用Eq(6)而不采用图像梯度,通过对目标图像估计边缘图![]() ,并同时学习
,并同时学习![]()
![]()
其中![]() 是pi,pj间的像素点包括端点,这用来表示测量两个像素间affinity的轮廓线索[48]。
是pi,pj间的像素点包括端点,这用来表示测量两个像素间affinity的轮廓线索[48]。
实际上,使用decoder网络对估计![]() 参数化,它是从深度网络的共享图像编码器进行解码得到的。将Eq(7)代回Eq(6),加上光度损失,来生成用来调整法向量图、深度图和边缘图的损失函数,如Fig2所示,分配给不同损失的不同部分。
参数化,它是从深度网络的共享图像编码器进行解码得到的。将Eq(7)代回Eq(6),加上光度损失,来生成用来调整法向量图、深度图和边缘图的损失函数,如Fig2所示,分配给不同损失的不同部分。
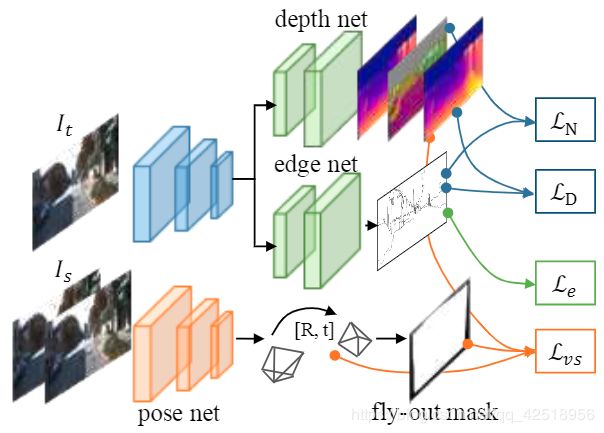
图2:损失包括四部分:合成图像损失![]() ,分别对应于深度和法向量图的3D-ASAP损失
,分别对应于深度和法向量图的3D-ASAP损失![]() ,以及边缘损失
,以及边缘损失![]()
,还是用了和【60】一样的depth-normal一致性损失
Overcoming the trivial solution
由于没有直接对![]() 进行监督,通过假设每个像素是一个边缘,用Eq(7)训练会产生正常结果,成功最小化了深度和法向量的平滑度。为了解决这个问题,添加了L2损失的正则化项帮助无边缘检测,如: 。另一种方法是使用交叉熵(cross-entropy)调整,但可能是因为只有稀疏边缘没有效果。
进行监督,通过假设每个像素是一个边缘,用Eq(7)训练会产生正常结果,成功最小化了深度和法向量的平滑度。为了解决这个问题,添加了L2损失的正则化项帮助无边缘检测,如: 。另一种方法是使用交叉熵(cross-entropy)调整,但可能是因为只有稀疏边缘没有效果。
解决训练中的双边缘:
在使用之前损失训练时发现,如Fig.3(b)的双边缘问题,与理想情况不同,深度在边缘不连续处有阶段性跳跃(Fig.3(a)的虚线),估计的深度在物体边缘变得平滑(实线)。因此,使用Eq(6)中的一个邻域计算深度3D-ASAP 的![]() 项,这与二阶梯度操作相似,在梯度变化的开始和结尾处出现非零值。为了减小
项,这与二阶梯度操作相似,在梯度变化的开始和结尾处出现非零值。为了减小![]() ,边缘图
,边缘图![]() 需要预测一个双边缘来抑制这个非零值。
需要预测一个双边缘来抑制这个非零值。
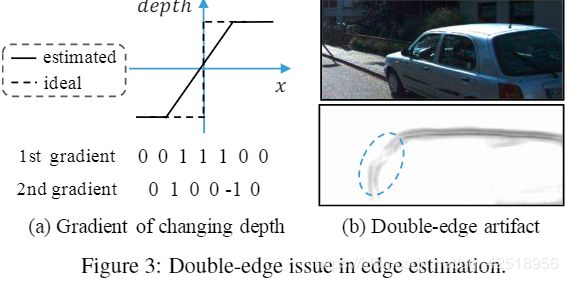
我们通过取出Eq(6)中由![]() 计算出的梯度图的负值来解决,对于每个x或y方向的边缘,双边缘的二阶梯度会得到一正一负两个值,于是使用
计算出的梯度图的负值来解决,对于每个x或y方向的边缘,双边缘的二阶梯度会得到一正一负两个值,于是使用![]() 代替
代替![]() 。 边缘decoder与深度decoder结构相同,并对从低尺度到高尺度的边缘上采样采用nearest方法
。 边缘decoder与深度decoder结构相同,并对从低尺度到高尺度的边缘上采样采用nearest方法
4.3 解决无效和局部梯度
无效梯度的Fly-out mask
之前的【64, 60】将序列长度调为3,以中间帧为目标图像,旁边两帧为源图像。当进行图像合成时,目标图像的像素点可能不会出现在源图中,如Fig 4,将造成像素的无效梯度。

图4:当相机从![]() 向
向![]() 变换时,用fly-out mask计算移出的像素
变换时,用fly-out mask计算移出的像素
处理局部梯度
与【64】中的局部梯度相似,空间变换操作是基于依赖周围四个像素的双线性插值。因此,基于multi-resolution的loss对于训练有效,训练loss为:
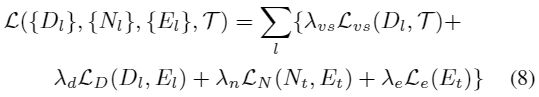
其中![]() 是用来调节有效集的平衡参数,如Fig 5,Dt和Nt的平滑度的重要性,并用深度和法向量找到所有的几何边缘
是用来调节有效集的平衡参数,如Fig 5,Dt和Nt的平滑度的重要性,并用深度和法向量找到所有的几何边缘