质数判定方法
update on 2018/12/01 12:51
最前边的一些话
-
如果你连素数都不知道是什么,我建议你可以试试滚学科了
-
如果你可以秒切这道题,那么这篇文章也帮不了你这个dalao,你也可以
滚去看别的文章了 -
这篇文章的源码基本有10k,LZ在后边敲的时候都一卡一卡的,希望能耐心看下去,
另外来骗个赞
0:一些前言
在 O I OI OI中,素数自古以来就是常考点,在 N O I P NOIP NOIP等竞赛中,也多次涉及到关于素数的知识点,对于一个 O I e r D b OIerDb OIerDb来说,应对这些考试最好的方法就是如何快速判断一个数是不是素数和打出一个大范围的质数表。
接下来,我们将要学习这些方法。
另:lz不太会用 LaTeX \LaTeX LATEX,凑合看吧
1:如何判断一个数是不是质数。
- 1:根据定义:素数就是一个数除了 1 1 1和他本身没有其他因数的数叫做质数。
于是我们对于一个 N N N,可以可以从 2 2 2枚举到 N − 1 N-1 N−1,从而判断这个数是不是质数。
代码如下:
bool Is_prime(int n);
{
if(n==1)return false;
if(n==2)return true;
for(register int i=2;i<n;i++)
if(n%i==0)return false;
return true;
}
时间复杂度为 O ( N ) O(N) O(N)。
对于上述程序显然不能满足我们的需求,如 N N N较大时,这样的程序肯定会超时,我已我们要想办法优化以上程序。
优化一
我们不难发现 N N N的因数是成对出现的,所以对于任何一个整数 N N N,我们只需要从 1 1 1枚举到 N \sqrt{N} N就可以了。
于是代码如下:
bool Is_prime(int n);
{
if(n==1)return false;
if(n==2)return true;
for(register int i=2;i*i<=n;i++)
if(n%i==0)return false;
return true;
}
上述程序时间复杂度为 O ( N ) O(\sqrt{N}) O(N)
优化2
根据lz多年的经验,已经达到 O ( N ) O(\sqrt{N}) O(N)的算法验证是不是素数的算法已经是最快的算法,知道有一天看到了这篇文章
证明:令 x ≥ 1 x≥1 x≥1,将大于等于 5 5 5的自然数表示如下:
. . . . . . 6 x − 1 , 6 x , 6 x + 1 , 6 x + 2 , 6 x + 3 , 6 x + 4 , 6 x + 5 , 6 ( x + 1 ) , 6 ( x + 1 ) + 1...... ......6x-1,6x,6x+1,6x+2,6x+3,6x+4,6x+5,6(x+1),6(x+1)+1...... ......6x−1,6x,6x+1,6x+2,6x+3,6x+4,6x+5,6(x+1),6(x+1)+1......
可以看到,不在6的倍数两侧,即 6 x 6x 6x两侧的数为 6 x + 2 , 6 x + 3 , 6 x + 4... 6x+2,6x+3,6x+4... 6x+2,6x+3,6x+4...由于 2 ( 3 x + 1 ) , 3 ( 2 x + 1 ) , 2 ( 3 x + 2 ) , 2(3x+1),3(2x+1),2(3x+2), 2(3x+1),3(2x+1),2(3x+2),
所以它们一定不是素数,再除去 6 x 6x 6x本身,显然,素数要出现只可能出现在 6 x 6x 6x的相邻两侧。
所以,基于以上条件,我们假如要判定的数为 n n n,则 n n n必定是 6 x − 1 6x-1 6x−1或 6 x + 1 6x+1 6x+1的形式,对于循环中 6 i − 1 6i-1 6i−1, 6 i 6i 6i, 6 i + 1 6i+1 6i+1, 6 i + 2 , 6 i + 3 , 6 i + 4 6i+2,6i+3,6i+4 6i+2,6i+3,6i+4,其中如果 n n n能被 6 i 6i 6i, 6 i + 2 6i+2 6i+2, 6 i + 4 6i+4 6i+4整除,则 n n n至少得是一个偶数,
但是 6 x − 1 6x-1 6x−1或 6 x + 1 6x+1 6x+1的形式明显是一个奇数,故不成立;另外,如果 n n n能被 6 i + 3 6i+3 6i+3整除,则n至少能被 3 3 3整除,
但是 6 x 6x 6x能被 3 3 3整除,故 6 x − 1 6x-1 6x−1或 6 x + 1 6x+1 6x+1(即 n n n)不可能被 3 3 3整除,故不成立。综上,循环中只需要考虑 6 i − 1 6i-1 6i−1和 6 i + 1 6i+1 6i+1的情况,
即循环的步长可以定为 6 6 6,每次判断循环变量 k k k和 k + 2 k+2 k+2的情况即可,代码如下:
bool Is_prime(int n)
{
if(n==1) return false;
if(n==2||n==3) return true;
if(n%6!=1&&n%6!=5) return false;
for(register int i=5;i*i<=n;i+=6)
if(n%i==0||n%(i+2)==0) return false;
return true;
}
理论上讲整体速度应该会是优化1代码的三倍的3倍。即 O ( N 3 ) O(\frac{\sqrt{N}}{3}) O(3N)
暂且就这么认为吧
小结:在对于素数的判断时,一般用第一种的优化方法就可以了,但是如果遇到了毒瘤出题人,最好是用第二种方法。
2:质数的筛法
0:使用第一种优化的方法从 1 1 1到 N N N判断每一个数是不是素数,时间复杂度为 O ( N N ) O(N\sqrt{N}) O(NN)
代码:
bool Is_prime(int n);
{
if(n==1)return false;
if(n==2)return true;
for(register int i=2;i*i<=n;i++)
if(n%i==0)return false;
return true;
}
const int N=100010
bool prime[N];
void make_prime()
{
for(ri i=1;i<=N;i++)
prime[i]=Is_prime(i);
return;
}
1:一般筛法(埃拉托斯特尼筛法):
基本思想:素数的倍数一定不是素数
实现方法:用一个长度为 N + 1 N+1 N+1的数组保存信息( t r u e true true表示素数, f a l s e false false表示非素数),先假设所有的数都是素数(初始化为 t r u e true true),从第一个素数 2 2 2开始,把 2 2 2的倍数都标记为非素数(置为 f a l s e false false),一直到大于 N N N;然后进行下一趟,找到 2 2 2后面的下一个素数 3 3 3,进行同样的处理,直到最后,数组中依然为 t r u e true true的数即为素数。
P . S . : P.S.: P.S.:特别的, 1 1 1既不是素数,也不是合数,所以 1 1 1要置为 f a l s e false false
例如,我们要求 1 − 100 1-100 1−100之间的素数,整个过程是这样的。
我们先把 2 2 2标记上 t r u e true true,然后把从 2 − 100 2-100 2−100中所有 2 2 2的倍数标为 f a l s e false false

然后我们找到下一个素数 3 3 3标记为 t r u e true true,把 3 3 3的倍数标为 f a l s e false false
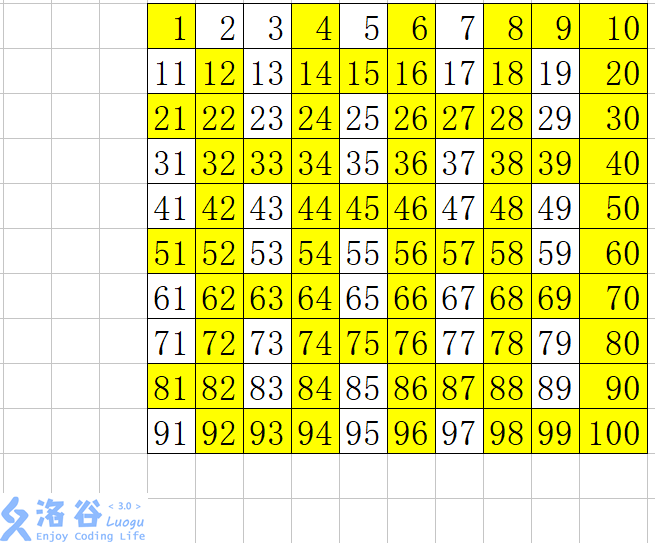
然后我们又找到了 5 5 5,把 5 5 5的倍数标为 f a l s e false false
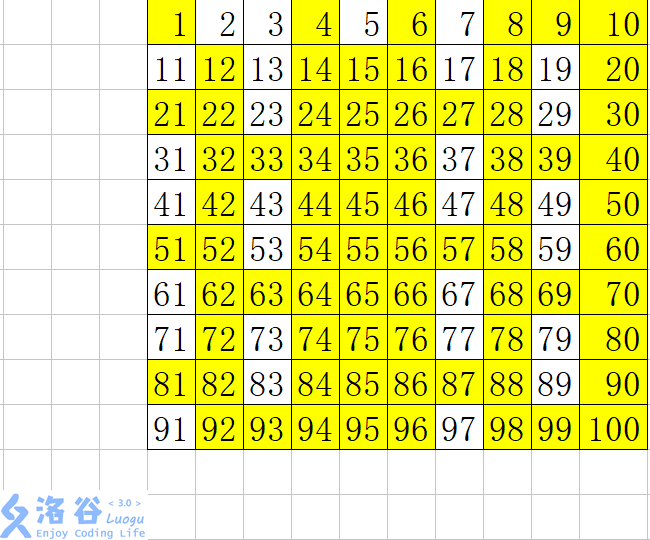
我们重复着上述过程,完成了对 1 − 100 1-100 1−100以内素数的检索。

另附这里有一张动图,还不懂的同学可以参照这幅图理解

代码如下:
#include此方法的复杂度为 O ( ∑ p < n n p ) = O ( n l o g l o g n ) O(\sum_{p<n}\frac{n}{p})=O(nloglogn) O(∑p<npn)=O(nloglogn)
通过上述代码,我们发现此方法还可以继续优化,因为上述的方法中,每一个有多组因数可能会被筛多次,例如: 30 30 30会被 2 , 3 , 5 2,3,5 2,3,5各筛一次导致计算冗余,我们可以对此方法进行改进,得到更加高效的筛法(欧拉筛)
代码如下:
#include这个方法可以保证每个和合数在 N / M N/M N/M的最小素因子时被筛出,所以时间复杂度仅为 O ( N ) O(N) O(N)已经可以满足大部分需求,在竞赛中,这种方法也可以在极短的时间内求出关于 N N N的质数表。
但是这个算法的弊端在于,为了判断一个大数是否是素数必须从从头开始扫描,而且空间代价也受不了,故不能离散的判断。
所以,我们要引入更高效的算法——Miller_Rabin算法。
Miller_rabin算法描述
首先介绍一下 m i l l e r miller miller r a b i n rabin rabin算法。
miller_rabin是一种素性测试算法,用来判断一个大数是否是一个质数。 miller_rabin是一种随机算法,它有一定概率出错,设测试次数为 s s s,那么出错的概率是 4 − s 4^{-s} 4−s,至于为什么我也不会证明。我觉得它的复杂度是 O ( s l o g 2 n ) O(slog^2n) O(slog2n),因为你要进行 s s s次,每次要进行一次快速幂,每次快速幂要 O ( l o g n ) O(log n) O(logn)次快速乘,每次快速乘又是 l o g n log n logn的,所以这一部分是 l o g 2 n log^{2} n log2n的,另一部分是把 n n n分解成 u ∗ 2 k u*2^{k} u∗2k,复杂度是 l o g n log n logn,所以 k k k是 l o g n log n logn量级的,对于 k k k,每次要快速乘,所以这一部分的复杂度也是 l o g 2 n log^{2}n log2n的,于是总复杂度 O ( m l o g 2 n ) O(mlog^{2}n) O(mlog2n)
下面开始介绍miller_rabin的做法。
首先我们知道,根据费马小定理,如果 p p p为质数且 a a a与 p p p互质,那么有
a p − 1 ≡ 1 ( m o d p ) a^{p-1}\equiv1\pmod{p} ap−1≡1(modp)
如果我们让 a < n a<n a<n,那么只需要满足 p p p为质数即可。但是反过来,满足
a p − 1 ≡ 1 ( m o d p ) a^{p-1}\equiv1\pmod{p} ap−1≡1(modp)
的 p p p不一定是质数。但是幸运的是,对于大多数的 p p p,费马小定理的逆定理是对的,但是为了让我们得到正确是结果,我们需要提高正确率。所以接下来我们需要二次探测。
若 n n n为质数,并且
x 2 ≡ 1 ( m o d n ) x^{2}\equiv1\pmod{n} x2≡1(modn)
那么 x = 1 x=1 x=1或 x = n − 1 x=n-1 x=n−1,因为 x 2 = 1 x2=1 x2=1,则 x = 1 x=1 x=1或 x = − 1 x=-1 x=−1,而在模意义下这个 − 1 -1 −1就成了 n − 1 n-1 n−1。我们来证明一下为什么在 x 2 ≡ 1 ( m o d p ) x^{2}\equiv1\pmod{p} x2≡1(modp),且 x ≠ 1 ( m o d p ) x≠1(mod p) x̸=1(modp),且
x ≠ p − 1 ( m o d p ) x≠p-1(mod p) x̸=p−1(modp)时 p p p不是质数。
x 2 ≡ 1 ( m o d p ) x^{2}\equiv1\pmod{p} x2≡1(modp)
x 2 − 1 ≡ 0 ( m o d p ) x^{2}-1\equiv0\pmod{p} x2−1≡0(modp)
( x − 1 ) ( x + 1 ) ≡ 0 ( m o d p ) (x-1)(x+1)\equiv0\pmod{p} (x−1)(x+1)≡0(modp)
所以有 p ∣ ( x − 1 ) p ∣ ( x − 1 ) p|(x-1)p|(x-1) p∣(x−1)p∣(x−1)或 p ∣ ( x + 1 ) p ∣ ( x + 1 ) p|(x+1)p|(x+1) p∣(x+1)p∣(x+1)或$p|(x+1)(x-1) $
因为 x ≠ p − 1 ( m o d x≠p-1(mod x̸=p−1(mod p ) p) p)
所以 ( x + 1 ) m o d (x+1)mod (x+1)mod p ≠ 0 p≠0 p̸=0, p p p不整除 x + 1 x+1 x+1
因为 x ≠ 1 ( m o d x≠1(mod x̸=1(mod p ) p) p)
所以 ( x − 1 ) (x-1) (x−1) m o d mod mod p ≠ 0 p≠0 p̸=0,pp不整除 x − 1 x-1 x−1
所以只能是 p ∣ ( x + 1 ) ( x − 1 ) p|(x+1)(x-1) p∣(x+1)(x−1)
由此我们可以发现 x + 1 x+1 x+1和 x − 1 x-1 x−1都不含 p p p的所有因子,而它们的乘积却含有的 p p p的全套因子,那么在相乘时 x + 1 x+1 x+1和 x − 1 x-1 x−1分别提供了一个非 1 1 1非 p p p的因子,才能使乘积是 p p p的倍数,当然这两个因子可能相同。
那么,我们可以证明出 p p p可以表示为两个非 1 1 1非 p p p的数的乘积,那么就证明了 p p p是合数而不是质数了。
我们可以根据这个性质进行二次探测。
如果我们设要测试的数为 n , n, n,若 n n n是 2 2 2或 n n n是偶数,那么我们可以直接判断 n n n的奇偶,否则令 p = n ? 1 p=n?1 p=n?1,将 p p p分解成 u ∗ 2 k u*2^{k} u∗2k,枚举 k k k来不断进行二次探测。则那么我们随机一个底数 x x x,快速幂求出 x u x^{u} xu m o d mod mod n n n ,然后不断的 x ∗ x x*x x∗x m o d mod mod p p p来进行二次探测。
至于为什么在代码中这么做是对的,我看到一个很好的解释,在这里分享一下。
a p − 1 ≡ 1 ( m o d p ) a^{p-1}\equiv1\pmod{p} ap−1≡1(modp)
a u ∗ 2 k ≡ 1 ( m o d p ) a^{u*2{k}}\equiv1\pmod{p} au∗2k≡1(modp)
a u ∗ 2 k − 1 ∗ a u ∗ 2 k − 1 ≡ 1 ( m o d p ) a^{u*2^{k-1}}*a^{u*2^{k-1}}\equiv1\pmod{p} au∗2k−1∗au∗2k−1≡1(modp)
那么我们把 a u ∗ 2 k − 1 a^{u*2^{k-1}} au∗2k−1看作 x x x,那么就是在当前 a u ∗ 2 k − 1 ≡ 1 ( m o d p ) a^{u*2^{k-1}}\equiv1\pmod{p} au∗2k−1≡1(modp)的时候验证是否是 p − 1 p-1 p−1或者 1 1 1即可。
另外最后别忘了用费马小定理来判断一下,代码中的 x x x其实的 x p − 1 ≡ 1 ( m o d p ) x^{p-1}\equiv1\pmod{p} xp−1≡1(modp)之后的结果,所以只需要看最后的 x x x是否是 1 1 1即可。
代码实现如下:
#include (话说这个应该归到判断素数的里边啊算了不搬了)
另附:某位大佬在 P P T PPT PPT上的一个神仙算法
此算法是 O ( n 3 4 / l o g n ) O(n^{\frac{3}{4}}/log n) O(n43/logn)的,并且在该算法在洲阁筛和min25筛中应用广泛(作为一部分)
这个算法名字好像叫做 t h e M e i s s e l , L e h m e r , L a g a r i a s , M i l l e r , O d l y z k o m e t h o d the Meissel, Lehmer, Lagarias, Miller, Odlyzko method theMeissel,Lehmer,Lagarias,Miller,Odlyzkomethod,网上的资料比较少。
首先放几个定义,定义比较多。。。
P i P_i Pi表示第 i i i个素数,
P I i PI_i PIi表示 i i i以内素数个数,
F n , m F_{n,m} Fn,m表示 n n n以内不等于第 i i i至 m m m个素数及其倍数的数的个数,
P 2 n , m P2_{n,m} P2n,m表示 n n n以内只有两个素因数且最小的素因数大于 P m P_m Pm的数的个数,
P 3 n , m P3_{n,m} P3n,m表示 n n n以内只有三个素因数且最小的素因数大于 P m P_m Pm的数的个数。
- 注意,接下来提到的除法都是指向下取整。
f明显可以递归计算,转移方程: f [ n , m ] = f [ n , m − 1 ] + f [ n / p [ m ] , m − 1 ] f[n,m] = f[n,m-1] + f[n/p[m],m-1] f[n,m]=f[n,m−1]+f[n/p[m],m−1]
根据大佬的 P P T PPT PPT,计算f的时间复杂度是 O ( m ∗ n 1 2 ) O(m*n^{\frac{1}{2}}) O(m∗n21)。
但是蒟蒻我根本不会证明。。
然后是 p 2 p2 p2的计算方法。 p 2 [ n , m ] = ∑ P i [ n / k ] − p i [ k ] + 1 p2[n,m] = \sum_{P_i[n/k]} - pi[k] + 1 p2[n,m]=∑Pi[n/k]−pi[k]+1,其中 k k k是所有大于 P m P_m Pm且小于 n 1 2 n^{\frac{1}{2}} n21的素数。
接着是p3的计算方法。 p 3 [ n , m ] = ∑ p 2 [ n / k , p i [ k ] − 1 ] p3[n,m] = \sum_{p2[n/k,pi[k]-1]} p3[n,m]=∑p2[n/k,pi[k]−1],其中 k k k是所有大于 P m P_m Pm且小于 n 1 3 n^{\frac{1}{3}} n31的素数。
先介绍第一种计算 P i n Pi_n Pin的方法。线性筛预处理前 n 1 2 n^\frac{1}{2} n21的 p p p和 P i Pi Pi。
pi [ n ] = p i [ n 1 3 ] + f [ n , p i [ n 1 3 ] ] − 1 − p 2 [ n , p i [ n 1 3 ] ] [n]=pi[n^{\frac{1}{3}}]+f[n,pi[n^{\frac{1}{3}}]]-1-p2[n,pi[n^{\frac{1}{3}}]] [n]=pi[n31]+f[n,pi[n31]]−1−p2[n,pi[n31]]。减一是为了排除掉1。
这种方法的时间复杂度是 O ( n 5 6 / l o g ( n ) ) O(n^{\frac{5}{6}} / log(n)) O(n65/log(n))。时间复杂度的瓶颈在f的计算上,其中 p i [ n 1 3 ] ≈ n 1 3 / l o g n pi[n^{\frac{1}{3}}] ≈ n^{\frac{1}{3}} / log n pi[n31]≈n31/logn。
为了进一步改善时间复杂度,我们要尽量减少 f f f的计算。以下是经过改进的第二种方法。
还是线性筛预处理前 n 1 2 n^{\frac{1}{2}} n21的 p p p和 p i pi pi。
得到:
p i [ n ] = p i [ n 1 4 ] + f [ n , p i [ n 1 4 ] ] − 1 − p 2 [ n , p i [ n 1 4 ] ] − p 3 [ n , p i [ n 1 4 ] ] pi[n] = pi[n^{\frac{1}{4}}] + f[n,pi[n^{\frac{1}{4}}]] - 1 - p2[n,pi[n^{\frac{1}{4}}]] - p3[n,pi[n^{\frac{1}{4}}]] pi[n]=pi[n41]+f[n,pi[n41]]−1−p2[n,pi[n41]]−p3[n,pi[n41]]
计算 p 3 p3 p3的时间复杂度还不到 O ( n 2 3 ) O(n^{\frac{2}{3}}) O(n32),所以瓶颈还在 f f f上,总时间复杂度为 O ( n 3 4 / l o g n ) O(n^{\frac{3}{4}} / log n) O(n43/logn)。
代码看看就好了。。。。
#include例题:
p3383【模板】线性筛素数
P1865 A % B Problem
可自己练习话说题目很基础啊