几种常见的卷积神经网络结构
几种常见的卷积神经网络结构
文章目录
- 几种常见的卷积神经网络结构
- 卷积神经网络的基本组成
- 部分常见的神经网络结构
- 走向深度:VGGNet
- 改进
- 神经网络结构
- 代码实现
- 从横交错:Inception(GoogLeNet)
- 改进
- 神经网络结构
- 代码实现
- 里程碑:ResNet
- 改进
- 神经网络结构
- 代码实现
- 继往开来:DenseNet
- 改进
- 神经网络结构
- 代码实现
- 特征金字塔:FPN
- 改进
- 神经网络结构
- 代码实现
- 为检测而生:DetNet
- 改进
- 神经网络结构
- 代码实现
卷积神经网络的基本组成

部分常见的神经网络结构

走向深度:VGGNet
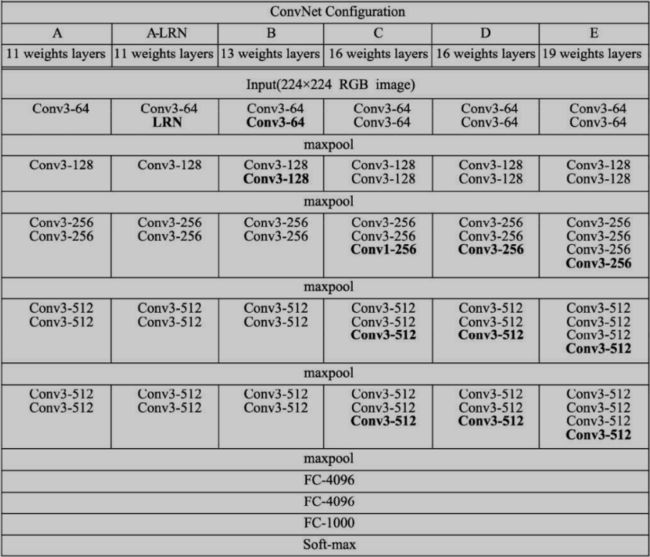
2014年的ImageNet亚军,探索了网络深度与性能的关系,用更小的卷积核与更深的网络结构,取得了较好的效果,成为卷积结构发展史上较为重要的一个网络。
VGGNet采用了五组卷积与三个全连接层,最后使用Softmax做分类。VGGNet有一个显著的特点:每次经过池化层(maxpool)后特征图的尺寸减小一倍,而通道数则增加一 倍(最后一个池化层除外)。
AlexNet中有使用到5×5的卷积核,而在VGGNet中,使用的卷积核 基本都是3×3,而且很多地方出现了多个3×3堆叠的现象,这种结构的优 点在于,首先从感受野来看,两个3×3的卷积核与一个5×5的卷积核是一 样的;其次,同等感受野时,3×3卷积核的参数量更少。更为重要的 是,两个3×3卷积核的非线性能力要比5×5卷积核强,因为其拥有两个激 活函数,可大大提高卷积网络的学习能力。
改进
在感受野上两个3x3的卷积核等价于一个5x5的卷积核,使用了两个3x3的卷积核来代替5x5的卷积核,减少了参数,同时也增加了非线性能力,提高了学习能力
dropout通过随机删减神经元来减少神经网络的过拟合,在训练时,每个神经元以概率p保留,即以1-p的概率停止工作,每次前向传播保留下来的神经元都不 同,这样可以使得模型不太依赖于某些局部特征,泛化性能更强。在测 试时,为了保证相同的输出期望值,每个参数还要乘以p。

神经网络结构
代码实现
VGG-16
import torch
from torch import nn
class VGG(nn.Module):
def __init__(self, num_classes=1000):
super(VGG, self).__init__()
layers = []
in_dim = 3
out_dim = 64
# 构造13个卷积层
for i in range(13):
layers += [
nn.Conv2d(in_dim, out_dim, 3, 1, 1),
nn.ReLU(inplace=True) # 可以实现inplace操作,即可以直接将运算结果覆盖到输入中,以节省内存
]
in_dim = out_dim
# 在第2、4、7、10、13个卷积层后增加池化层
if i == 1 or i == 3 or i == 6 or i == 9 or i == 12:
layers += [
nn.MaxPool2d(2, 2)
]
# 第10个卷积层后保持与第9层第通道数一致,都为512,其余加倍
if i != 9:
out_dim *= 2
self.features = nn.Sequential(*layers)
# VGGNet的3个全连接层,中间添加ReLU与Dropout
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
# 特征图的维度从[1,512,7,7]变到[1,512*7*7]
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
if __name__ == '__main__':
vgg = VGG(21)
input = torch.randn([1, 3, 224, 224])
print('input.shape:', input.shape)
scores = vgg(input)
print('score.shape:', scores.shape)
features = vgg.features(input)
print('features.shape:', features.shape)
print('vgg.features:', features.shape)
print('vgg.classifier:', vgg.classifier)
输出:
input.shape: torch.Size([1, 3, 224, 224])
score.shape: torch.Size([1, 21])
features.shape: torch.Size([1, 512, 7, 7])
vgg.features: torch.Size([1, 512, 7, 7])
vgg.classifier: Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=21, bias=True)
)
从横交错:Inception(GoogLeNet)
出自Google听说其命名是为了致敬LeNet,神经网络向广度发展的一个典型
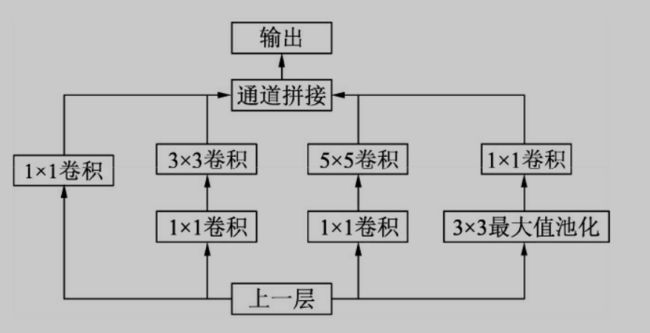
Inception v1网络一共有9个上述堆叠的模块,共有22层,在最后的 Inception模块处使用了全局平均池化。为了避免深层网络训练时带来的 梯度消失问题,作者还引入了两个辅助的分类器,在第3个与第6个 Inception模块输出后执行Softmax并计算损失,在训练时和最后的损失一 并回传。其中1×1的模块可以先将特征图 降维,再送给3×3和5×5大小的卷积核,由于通道数的降低,参数量也有了较大的减少。
Inception v2增加了 BN层,同时利用两个级联的3×3卷积取代了Inception v1版本中的5×5卷 积,这种方式既减少了卷积参数量,也增加了网络的非
线性能力。
改进
使用BN层
BN层首先对每一个batch的输入特征进行白化操作,即去均值方差 过程。假设一个batch的输入数据为x: B = { x 1 , … , x m } B={x_1,…,x_m} B={x1,…,xm},首先求该batch 数据的均值与方差
u B ← 1 m ∑ i = 1 m x i u_B\gets\frac{1}{m}\sum_{i=1}^{m}x_i uB←m1i=1∑mxi
σ B 2 ← 1 m ∑ i = 1 m ( x i − u B ) 2 \sigma_B^2\gets\frac{1}{m}\sum_{i=1}^{m}(x_i-u_B)^2 σB2←m1i=1∑m(xi−uB)2
以上公式中,m代表batch的大小, μ B μ_B μB为批处理数据的均值, σ B 2 σ^2_B σB2为 批处理数据的方差。在求得均值方差后,利用下面公式进行去均值方差操作:
x ^ i ← x i − u i σ 2 + ε \widehat{x}_i\gets\frac{x_i-u_i}{\sqrt{\sigma^2+\varepsilon}} x i←σ2+εxi−ui
白化操作可以使输入的特征分布具有相同的均值与方差,固定了每 一层的输入分布,从而加速网络的收敛。然而,白化操作虽然从一定程 度上避免了梯度饱和,但也限制了网络中数据的表达能力,浅层学到的 参数信息会被白化操作屏蔽掉,因此,BN层在白化操作后又增加了一 个线性变换操作,让数据尽可能地恢复本身的表达能力
y i ← γ x ^ i + β y_i\gets \gamma\widehat{x}_i+\beta yi←γx i+β
γ与β为新引进的可学习参数,最终的输出为yi。 BN层可以看做是增加了线性变换的白化操作,在实际工程中被证 明了能够缓解神经网络难以训练的问题。BN层的优点主要有以下3点:
- 缓解梯度消失,加速网络收敛。BN层可以让激活函数的输入数据 落在非饱和区,缓解了梯度消失问题。此外,由于每一层数据的均值与 方差都在一定范围内,深层网络不必去不断适应浅层网络输入的变化, 实现了层间解耦,允许每一层独立学习,也加快了网络的收敛。
- 简化调参,网络更稳定。在调参时,学习率调得过大容易出现震 荡与不收敛,BN层则抑制了参数微小变化随网络加深而被放大的问 题,因此对于参数变化的适应能力更强,更容易调参。
- 防止过拟合。BN层将每一个batch的均值与方差引入到网络中,由 于每个batch的这两个值都不相同,可看做为训练过程增加了随机噪音,可以起到一定的正则效果,防止过拟合。
在测试时,由于是对单个样本进行测试,没有batch的均值与方差, 通常做法是在训练时将每一个batch的均值与方差都保留下来,在测试时 使用所有训练样本均值与方差的平均值。
神经网络结构
inceptionV1
inceptionV2

代码实现
Inception v1
import torch
from torch import nn
import torch.nn.functional as F
# 定义一个conv+relu的类
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding)
def forward(self, x):
x = self.conv(x)
return F.relu(x, inplace=True)
# 定义googLeNet
class Inceptionv1(nn.Module):
def __init__(self, in_dim, hid_1_1, hid_2_1, hid_2_3, hid_3_1, out_3_5, out_4_1):
super(Inceptionv1, self).__init__()
# 定义四个子模块
self.branch1x1 = BasicConv2d(in_dim, hid_1_1, 1)
self.branch3x3 = nn.Sequential(
BasicConv2d(in_dim, hid_2_1, 1),
BasicConv2d(hid_2_1, hid_2_3, 3, padding=1)
)
self.branch5x5 = nn.Sequential(
BasicConv2d(in_dim, hid_3_1, 1),
BasicConv2d(hid_3_1, out_3_5, 5, padding=2)
)
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
BasicConv2d(in_dim, out_4_1, 1)
)
def forward(self, x):
b1 = self.branch1x1(x)
b2 = self.branch3x3(x)
b3 = self.branch5x5(x)
b4 = self.branch_pool(x)
# 连接子模块
output = torch.cat((b1, b2, b3, b4), dim=1)
return output
if __name__ == '__main__':
net_inceptionv1 = Inceptionv1(3, 63, 32, 64, 64, 96, 32)
print('net_inceptionv1:', net_inceptionv1)
input = torch.randn(1, 3, 256, 256)
print(input.shape)
output = net_inceptionv1(input)
print('output.shape', output.shape)
输出
net_inceptionv1: Inceptionv1(
(branch1x1): BasicConv2d(
(conv): Conv2d(3, 63, kernel_size=(1, 1), stride=(1, 1))
)
(branch3x3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1))
)
(1): BasicConv2d(
(conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
(branch5x5): Sequential(
(0): BasicConv2d(
(conv): Conv2d(3, 64, kernel_size=(1, 1), stride=(1, 1))
)
(1): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
)
)
(branch_pool): Sequential(
(0): MaxPool2d(kernel_size=3, stride=1, padding=1, dilation=1, ceil_mode=False)
(1): BasicConv2d(
(conv): Conv2d(3, 32, kernel_size=(1, 1), stride=(1, 1))
)
)
)
torch.Size([1, 3, 256, 256])
output.shape torch.Size([1, 255, 256, 256])
Inception v2
import torch
from torch import nn
import torch.nn.functional as F
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, padding=padding)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class Inceptionv2(nn.Module):
def __init__(self):
super(Inceptionv2, self).__init__()
self.branch1 = BasicConv2d(192, 96, 1, 0)
self.branch2 = nn.Sequential(
BasicConv2d(192, 48, 1, 0),
BasicConv2d(48, 64, 3, 1)
)
self.branch3 = nn.Sequential(
BasicConv2d(192, 64, 1, 0),
BasicConv2d(64, 96, 3, 1),
BasicConv2d(96, 96, 3, 1)
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),
BasicConv2d(192, 64, 1, 0)
)
def forward(self, x):
x0 = self.branch1(x)
x1 = self.branch2(x)
x2 = self.branch3(x)
x3 = self.branch4(x)
out = torch.cat((x0, x1, x2, x3), 1)
return out
if __name__ == '__main__':
net_inceptionv2 = Inceptionv2()
print('net_inceptionv2:', net_inceptionv2)
input = torch.randn(1, 192, 32, 32)
print('input.shape:', input.shape)
output = net_inceptionv2(input)
print('output.shape:', output.shape)
输出
net_inceptionv2: Inceptionv2(
(branch1): BasicConv2d(
(conv): Conv2d(192, 96, kernel_size=(1, 1), stride=(1, 1))
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(branch2): Sequential(
(0): BasicConv2d(
(conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1))
(bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(48, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch3): Sequential(
(0): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicConv2d(
(conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
(2): BasicConv2d(
(conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
(branch4): Sequential(
(0): AvgPool2d(kernel_size=3, stride=1, padding=1)
(1): BasicConv2d(
(conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1))
(bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
)
)
)
input.shape: torch.Size([1, 192, 32, 32])
output.shape: torch.Size([1, 320, 32, 32])
里程碑:ResNet
何凯明大神的作品,较好的解决了梯度下降的问题,获得了2015年ImageNet分类任务的第一名
ResNet(Residual Network,残差网络)较好的解决了梯度下降的问题,获得了2015年ImageNet分类任务的第一名。此后的分类、检测、分割等 任务也大规模使用ResNet作为网络骨架。
改进
ResNet的思想在于引入了一个深度残差框架来解决梯度消失问题, 即让卷积网络去学习残差映射,而不是期望每一个堆叠层的网络都完整 地拟合潜在的映射(拟合函数)。如图所示,对于神经网络,如果 我们期望的网络最终映射为H(x),左侧的网络需要直接拟合输出H(x), 而右侧由ResNet提出的子模块,通过引入一个shortcut(捷径)分支,将 需要拟合的映射变为残差F(x):H(x)-x。ResNet给出的假设是:相较于 直接优化潜在映射H(x),优化残差映射F(x)是更为容易的。由于F(x)+x是逐通道进行相加,因此根据两者是否通道数相同,存 在两种Bottleneck结构。对于通道数不同的情况,比如每个卷积组的第 一个Bottleneck,需要利用1×1卷积对x进行Downsample操作,将通道数变为相同,再进行加操作。对于相同的情况下,两者可以直接进行相 加。

神经网络结构

代码实现
import torch
import torch.nn as nn
class Bottleneck(nn.Module):
def __init__(self, in_dim, out_dim, stride=1):
super(Bottleneck, self).__init__()
# 网络堆叠层是由1x1、3x3、1x1这3个卷积层组成,中间包含BN层
self.bottleneck = nn.Sequential(
nn.Conv2d(in_dim, in_dim, 1, bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_dim, in_dim, 3, stride, 1, bias=False),
nn.BatchNorm2d(in_dim),
nn.ReLU(inplace=True),
nn.Conv2d(in_dim, out_dim, 1, bias=False),
nn.BatchNorm2d(out_dim)
)
self.relu = nn.ReLU(inplace=True)
# Downsample部分由一个包含BN层的1x1的卷积组成
self.downsample = nn.Sequential(
nn.Conv2d(in_dim, out_dim, 1, 1),
nn.BatchNorm2d(out_dim),
)
def forward(self, x):
identity = x
out = self.bottleneck(x)
identity = self.downsample(x)
# 将identity(恒等映射)与网络堆叠层进行相加,并经过ReLU输出
out += identity
out = self.relu(out)
return out
if __name__ == '__main__':
bottleneck_1_1 = Bottleneck(64, 256)
print('bottleneck_1_1', bottleneck_1_1)
input = torch.randn(1, 64, 56, 56)
output = bottleneck_1_1(input)
print('input.shape', input.shape)
print('output.shape', output.shape)
输出
bottleneck_1_1 Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
input.shape torch.Size([1, 64, 56, 56])
output.shape torch.Size([1, 256, 56, 56])
继往开来:DenseNet
2017CVPR的best论文奖
ResNet通过前层与后层的“短路连接”(Shortcuts),加强 了前后层之间的信息流通,在一定程度上缓解了梯度消失现象,从而可 以将神经网络搭建得很深。DenseNet最大化了这 种前后层信息交流,通过建立前面所有层与后面层的密集连接,实现了 特征在通道维度上的复用,使其可以在参数与计算量更少的情况下实现 比ResNet更优的性能。
改进
FPN将深层的语义信息传到底层,来补充浅层的语义信息,从而获 得了高分辨率、强语义的特征,在小物体检测、实例分割等领域有着非 常不俗的表现。
相比ResNet,DenseNet提出了一个更激进的密集连接机制:即互相连接所有的层,具体来说就是每个层都会接受其前面所有层作为其额外的输入。图1为ResNet网络的连接机制,作为对比,图2为DenseNet的密集连接机制。可以看到,ResNet是每个层与前面的某层(一般是2~3层)短路连接在一起,连接方式是通过元素级相加。而在DenseNet中,每个层都会与前面所有层在channel维度上连接(concat)在一起(这里各个层的特征图大小是相同的,后面会有说明),并作为下一层的输入。对于一个 L层的网络,DenseNet共包含 L ( L + 1 ) 2 \frac{L(L+1)}{2} 2L(L+1) 个连接,相比ResNet,这是一种密集连接。而且DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这一特点是DenseNet与ResNet最主要的区别。
神经网络结构

网络由多个Dense Block与中间 的卷积池化组成,核心就在Dense Block中。Dense Block中的黑点代表 一个卷积层,其中的多条黑线代表数据的流动,每一层的输入由前面的 所有卷积层的输出组成。注意这里使用了通道拼接(Concatnate)操 作,而非ResNet的逐元素相加操作。
DenseNet的结构有如下两个特性:
- 神经网络一般需要使用池化等操作缩小特征图尺寸来提取语义特 征,而Dense Block需要保持每一个Block内的特征图尺寸一致来直接进 行Concatnate操作,因此DenseNet被分成了多个Block。Block的数量一 般为4。
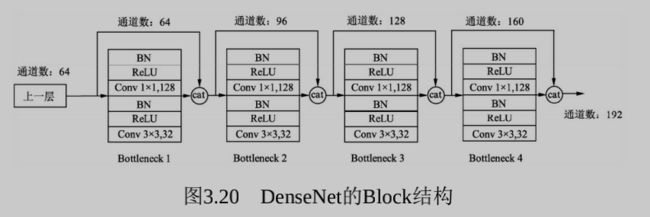
- 两个相邻的Dense Block之间的部分被称为Transition层,具体包括 BN、ReLU、1×1卷积、2×2平均池化操作。1×1卷积的作用是降维,起 到压缩模型的作用,而平均池化则是降低特征图的尺寸, 具体的Block实现细节如图3.20所示,每一个Block由若干个 Bottleneck的卷积层组成,对应图3.19中的黑点。Bottleneck由BN、 ReLU、1×1卷积、BN、ReLU、3×3卷积的顺序构成。
关于Block,有以下4个细节需要注意:
- 每一个Bottleneck输出的特征通道数是相同的,例如这里的32。同 时可以看到,经过Concatnate操作后的通道数是按32的增长量增加的, 因此这个32也被称为GrowthRate。
- 这里1×1卷积的作用是固定输出通道数,达到降维的作用。当几十 个Bottleneck相连接时,Concatnate后的通道数会增加到上千,如果不增 加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。1×1卷积 的通道数通常是GrowthRate的4倍。
- 特征传递方式是直接将前面所有层的特征Concatnate后 传到下一层,这种方式与具体代码实现的方式是一致的,而不像图3.19 中,前面层都要有一个箭头指向后面的所有层。
- Block采用了激活函数在前、卷积层在后的顺序,这与一般的网络 上是不同的。
代码实现
import torch
from torch import nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
def __init__(self, nChannels, growthRate):
super(Bottleneck, self).__init__()
interChannels = 4 * growthRate
self.bn1 = nn.BatchNorm2d(nChannels)
self.conv1 = nn.Conv2d(nChannels, interChannels, kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(interChannels)
self.conv2 = nn.Conv2d(interChannels, growthRate, kernel_size=3, padding=1, bias=False)
def forward(self, x):
out = self.conv1(F.relu(self.bn1(x)))
out = self.conv2(F.relu(self.bn2(out)))
out = torch.cat((x, out), 1)
return out
class Denseblock(nn.Module):
def __init__(self, nChannels, growthRate, nDenseBlock):
super(Denseblock, self).__init__()
layers = []
for i in range(int(nDenseBlock)):
layers.append(Bottleneck(nChannels, growthRate))
nChannels += growthRate
self.denseblock = nn.Sequential(*layers)
def forward(self, x):
return self.denseblock(x)
if __name__ == '__main__':
denseblock = Denseblock(64, 32, 6)
print('denseblock:', denseblock)
input = torch.randn(1, 64, 256, 256)
output = denseblock(input)
print('output.shape:', output.shape)
输出
denseblock: Denseblock(
(denseblock): Sequential(
(0): Bottleneck(
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(1): Bottleneck(
(bn1): BatchNorm2d(96, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(96, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(2): Bottleneck(
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(3): Bottleneck(
(bn1): BatchNorm2d(160, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(160, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(4): Bottleneck(
(bn1): BatchNorm2d(192, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(192, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
(5): Bottleneck(
(bn1): BatchNorm2d(224, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv1): Conv2d(224, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
)
)
)
output.shape: torch.Size([1, 256, 256, 256])
特征金字塔:FPN
为了解决多尺度问题
为了增强语义性,传统的物体检测模型通常只在深度卷积网络的最 后一个特征图上进行后续操作,而这一层对应的下采样率(图像缩小的 倍数)通常又比较大,如16、32,造成小物体在特征图上的有效信息较 少,小物体的检测性能会急剧下降,这个问题也被称为多尺度问题。
解决多尺度问题的关键在于如何提取多尺度的特征。传统的方法有 图像金字塔(Image Pyramid),主要思路是将输入图片做成多个尺度, 不同尺度的图像生成不同尺度的特征,这种方法简单而有效,大量使用 在了COCO等竞赛上,但缺点是非常耗时,计算量也很大。
改进
2017年的FPN(Feature Pyramid Network)方法融合了不同层的特征,较好地改善了多尺度检测问题。
神经网络结构
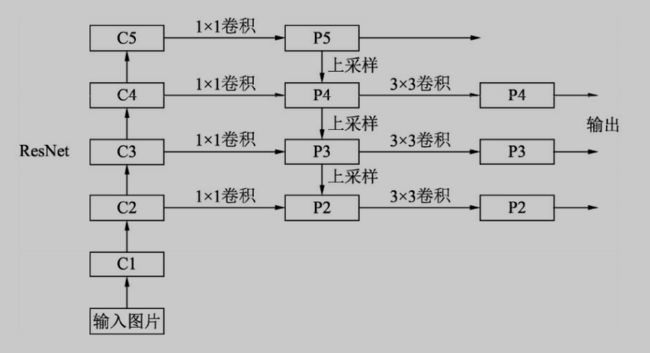
- 自下而上:最左侧为普通的卷积网络,默认使用ResNet结构,用 作提取语义信息。C1代表了ResNet的前几个卷积与池化层,而C2至C5 分别为不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构, 组内的特征图大小相同,组间大小递减。
- 自上而下:首先对C5进行1×1卷积降低通道数得到P5,然后依次进 行上采样得到P4、P3和P2,目的是得到与C4、C3与C2长宽相同的特 征,以方便下一步进行逐元素相加。这里采用2倍最邻近上采样,即直 接对临近元素进行复制,而非线性插值。
- 横向连接(Lateral Connection):目的是为了将上采样后的高语义 特征与浅层的定位细节特征进行融合。高语义特征经过上采样后,其长 宽与对应的浅层特征相同,而通道数固定为256,因此需要对底层特征 C2至C4进行1x1卷积使得其通道数变为256,然后两者进行逐元素相加得 到P4、P3与P2。由于C1的特征图尺寸较大且语义信息不足,因此没有 把C1放到横向连接中。
- 卷积融合:在得到相加后的特征后,利用3×3卷积对生成的P2至P4 再进行融合,目的是消除上采样过程带来的重叠效应,以生成最终的特 征图。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class Bottleneck(nn.Module):
expansion = 4 # 通道倍增数
def __init__(self, in_place, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_place, planes, 1, bias=True),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 3, stride, 1, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, self.expansion * planes, 1, bias=True),
nn.BatchNorm2d(self.expansion * planes)
)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.bottleneck(x)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# layers代表每一个阶段的Bottleneck的数量
class FPN(nn.Module):
def __init__(self, layers):
super(FPN, self).__init__()
self.inplanes = 64
# 处理输入的C1模块
self.conv1 = nn.Conv2d(3, 64, 7, 2, 3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(3, 2, 1)
# 搭建自上而下的C2、C3、C4、C5模块
self.layer1 = self._make_layer(64, layers[0])
self.layer2 = self._make_layer(128, layers[1], 2)
self.layer3 = self._make_layer(256, layers[2], 2)
self.layer4 = self._make_layer(512, layers[3], 2)
# 对C5减少通道数,得到P5
self.toplayer = nn.Conv2d(2048, 256, 1, 1, 0)
# 3x3卷积特征融合
self.smooth1 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth2 = nn.Conv2d(256, 256, 3, 1, 1)
self.smooth3 = nn.Conv2d(256, 256, 3, 1, 1)
# 横向连接,保证通道数相同
self.latlayer1 = nn.Conv2d(1024, 256, 1, 1, 0)
self.latlayer2 = nn.Conv2d(512, 256, 1, 1, 0)
self.latlayer3 = nn.Conv2d(256, 256, 1, 1, 0)
# 构建C2到C5,注意区分stride=1或2的情况
def _make_layer(self, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != Bottleneck.expansion * planes:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, Bottleneck.expansion * planes, 1, stride, bias=False),
nn.BatchNorm2d(Bottleneck.expansion * planes)
)
layers = []
layers.append(Bottleneck(self.inplanes, planes, stride, downsample))
self.inplanes = planes * Bottleneck.expansion
for i in range(1, blocks):
layers.append(Bottleneck(self.inplanes, planes))
return nn.Sequential(*layers)
# 自上而下的上采样模块
def _upsample_add(self, x, y):
_, _, H, W = y.shape
return F.upsample(x, size=(H, W), mode='bilinear') + y
def forward(self, x):
# 自下而上
c1 = self.maxpool(self.relu(self.bn1(self.conv1(x))))
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# 自上而下
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# 卷积融合,平滑处理
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
if __name__ == '__main__':
net_fpn = FPN([3, 4, 6, 3])
print('net_fpn.conv1:', net_fpn.conv1)
print('net_fpn.bn1:', net_fpn.bn1)
print('net_fpn.relu:', net_fpn.relu)
print('net_fpn.maxpool:', net_fpn.maxpool)
print('net_fpn.layer1:', net_fpn.layer1)
print('net_fpn.layer2:', net_fpn.layer2)
print('net_fpn.toplayer:', net_fpn.toplayer)
print('net_fpn.smooth1:', net_fpn.smooth1)
print('net_fpn.latlayer1', net_fpn.latlayer1)
input = torch.randn(1, 3, 224, 224)
output = net_fpn(input)
print('output[0].shape:', output[0].shape)
print('output[1].shape:', output[1].shape)
print('output[2].shape:', output[2].shape)
print('output[3].shape:', output[3].shape)
输出
net_fpn.conv1: Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
net_fpn.bn1: BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
net_fpn.relu: ReLU(inplace=True)
net_fpn.maxpool: MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
net_fpn.layer1: Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
)
net_fpn.layer2: Sequential(
(0): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(bottleneck): Sequential(
(0): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
(6): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(relu): ReLU(inplace=True)
)
)
net_fpn.toplayer: Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1))
net_fpn.smooth1: Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
net_fpn.latlayer1 Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1))
output[0].shape: torch.Size([1, 256, 56, 56])
output[1].shape: torch.Size([1, 256, 28, 28])
output[2].shape: torch.Size([1, 256, 14, 14])
output[3].shape: torch.Size([1, 256, 7, 7])
为检测而生:DetNet
如VGGNet和ResNet等,虽从各个角度出发 提升了物体检测性能,但究其根本是为ImageNet的图像分类任务而设计 的。而图像分类与物体检测两个任务天然存在着落差,分类任务侧重于 全图的特征提取,深层的特征图分辨率很低;而物体检测需要定位出物 体位置,特征图分辨率不宜过小,因此造成了以下两种缺陷:
- 大物体难以定位:对于FPN等网络,大物体对应在较深的特征图上 检测,由于网络较深时下采样率较大,物体的边缘难以精确预测,增加 了回归边界的难度。
- 小物体难以检测:对于传统网络,由于下采样率大造成小物体在 较深的特征图上几乎不可见;FPN虽从较浅的特征图来检测小物体,但 浅层的语义信息较弱,且融合深层特征时使用的上采样操作也会增加物 体检测的难度。
针对以上问题,旷视科技提出了专为物体检测设计的DetNet结构, 引入了空洞卷积,使得模型兼具较大感受野与较高分辨率,同时避免了FPN的多次上采样,实现了较好的检测效果。
DetNet的网络结构如图3.22所示,仍然选择性能优越的ResNet-50作 为基础结构,并保持前4个stage与ResNet-50相同,具体的结构细节有以 下3点:
- 引入了一个新的Stage 6,用于物体检测。Stage 5与Stage 6使用了 DetNet提出的Bottleneck结构,最大的特点是利用空洞数为2的3×3卷积 取代了步长为2的3×3卷积。
- Stage 5与Stage 6的每一个Bottleneck输出的特征图尺寸都为原图的 1 16 \frac{1}{16} 161 ,通道数都为256,而传统的Backbone通常是特征图尺寸递减,通道数递增。
- 在组成特征金字塔时,由于特征图大小完全相同,因此可以直接 从右向左传递相加,避免了上一节的上采样操作。为了进一步融合各通 道的特征,需要对每一个阶段的输出进行1×1卷积后再与后一Stage传回 的特征相加。
改进
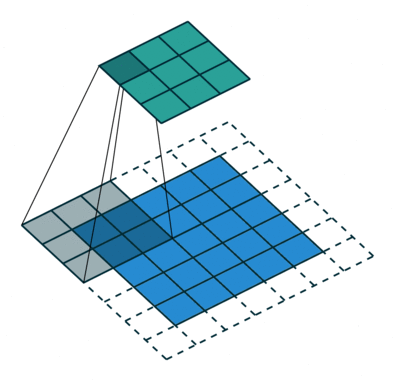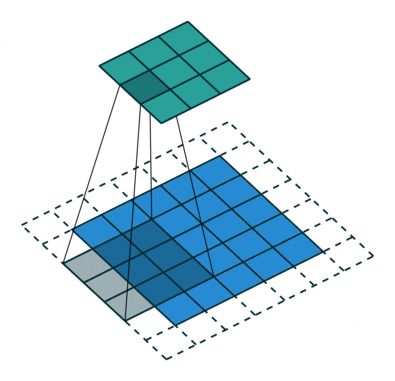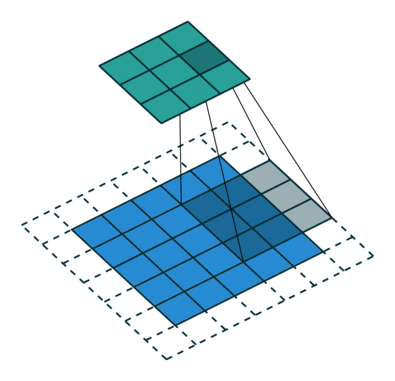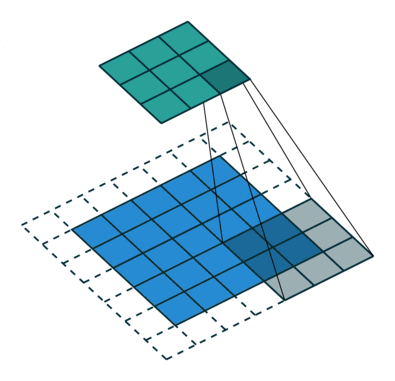
采用了空洞卷积
图a是普通的卷积过程,在卷积核紧密排列在特征图上滑动计算,而图b代表了空洞数为2的空洞 卷积,可以看到,在特征图上每2行或者2列选取元素与卷积核卷积。类 似地,图c代表了空洞数为3的空洞卷积。

在代码实现时,空洞卷积有一个额外的超参数dilation rate,表示空
洞数,普通卷积dilation rate默认为1,图中的b与c的dilation rate分别 为2与3。
在图3.11中,同样的一个3×3卷积,却可以起到5×5、7×7等卷积的 效果。可以看出,空洞卷积在不增加参数量的前提下,增大了感受野。 假设空洞卷积的卷积核大小为k,空洞数为d,则其等效卷积核大小k’计 算如式所示
k ′ = k + ( k − 1 ) × ( d − 1 ) k'=k+(k-1)\times (d-1) k′=k+(k−1)×(d−1)
空洞卷积的优点显而易见,在不引入额外参数的前提下可以任意扩 大感受野,同时保持特征图的分辨率不变。这一点在分割与检测任务中 十分有用,感受野的扩大可以检测大物体,而特征图分辨率不变使得物 体定位更加精准。
当然,空洞卷积也有自己的一些缺陷,主要表现在以下3个方面:
- 网格效应(Gridding Effect):由于空洞卷积是一种稀疏的采样方
式,当多个空洞卷积叠加时,有些像素根本没有被利用到,会损失信息 的连续性与相关性,进而影响分割、检测等要求较高的任务。 - 远距离的信息没有相关性:空洞卷积采取了稀疏的采样方式,导 致远距离卷积得到的结果之间缺乏相关性,进而影响分类的结果。
- 不同尺度物体的关系:大的dilation rate对于大物体分割与检测有 利,但是对于小物体则有弊无利,如何处理好多尺度问题的检测,是空 洞卷积设计的重点。
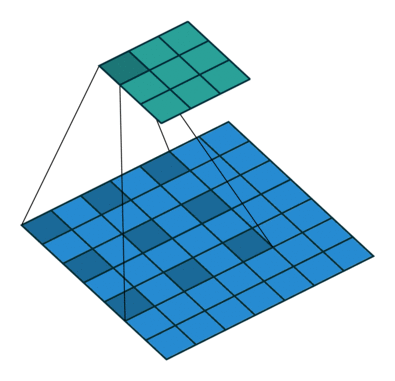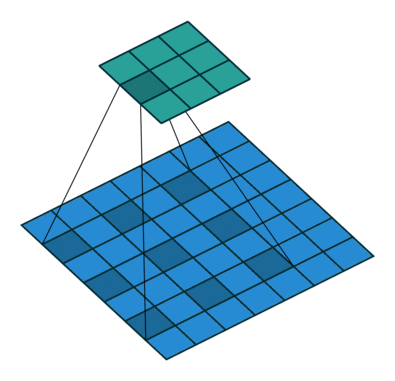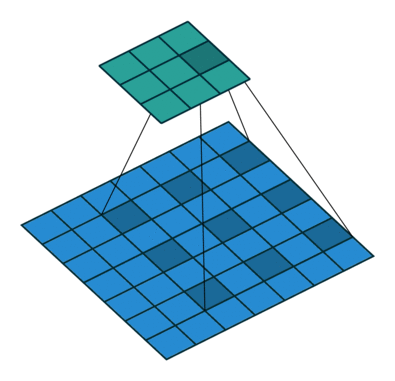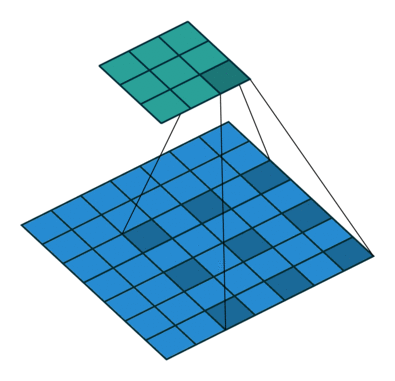
神经网络结构


代码实现
Bottlenck A与Bottlenck B
import torch
from torch import nn
class DetBottleneck(nn.Module):
def __init__(self, inplanes, planes, stride=1, extra=False):
super(DetBottleneck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(inplanes, planes, 1, bias=True),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=2, dilation=2, bias=False),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True),
nn.Conv2d(planes, planes, 1, bias=False),
nn.BatchNorm2d(planes)
)
self.relu = nn.ReLU(inplace=True)
self.extra = extra
if self.extra:
self.extra_conv = nn.Sequential(
nn.Conv2d(inplanes, planes, 1, bias=False),
nn.BatchNorm2d(planes)
)
def forward(self, x):
if self.extra:
identity = self.extra_conv(x)
else:
identity = x
out = self.bottleneck(x)
out += identity
out = self.relu(out)
return out
if __name__ == '__main__':
bottleneck_b = DetBottleneck(1024, 256, 1, True)
print('bottleneck_b:', bottleneck_b)
bottleneck_a1 = DetBottleneck(256, 256)
print('bottleneck_a1:', bottleneck_a1)
bottleneck_a2 = DetBottleneck(256, 256)
print('bottleneck_a2:', bottleneck_a2)
input = torch.randn(1, 1024, 14, 14)
output1 = bottleneck_b(input)
output2 = bottleneck_a1(output1)
output3 = bottleneck_a2(output2)
print('output1.shape:', output1.shape)
print('output2.shape:', output2.shape)
print('output3.shape:', output3.shape)