银行营销数据分析
银行营销
引文请求:此数据集可供研究使用。详情见[Moroetal.,2011]。如果计划使用此数据库,请包含此引用:[Moro等,2011]S.Moro,R.Laureano和P.Corez。数据挖掘技术在银行直接营销中的应用在P.Novais等(eds.)中,欧洲模拟和模拟会议-ESM"2011年,第117-121页,Guimarees,葡萄牙,2011年10月。欧洲SIS。网址:[PDF]http://hdl.handle.net/1822/14838[BIB]http://www3.dsi.uminho.pt/pcortez/bib/2011-esm-,需要数据源可取此网站下载。
详情如下:
1.txt1、标题:银行营销
2.来源创建人:PauloCorez(UNV.Minho)和S.RgioMoro(ISCTE-IUL)2012年@2012年
3.过去使用情况:对完整数据集进行了描述和分析:S.Moro、R.Laureano和P.Corez。数据挖掘技术在银行直接营销中的应用在P.Novaisetal.(eds.)中,欧洲模拟和模拟会议-ESM"2011,第117-121页,GuimareesES,葡萄牙,2011年10月。欧洲SIS。
4.相关信息:数据与葡萄牙银行机构的直接营销活动有关。营销活动基于电话呼叫。通常需要对同一客户端的多于一个的联系人,以便于(或未)订购产品(银行定期存款)。有两个数据集:1)具有所有示例的bank-full.csv,按日期排序(2008年5月至2010年11月)。2)bank.csv10%的示例(4521),从bank-full.csv.中随机选择提供最小数据集,以测试更高计算要求的机器学习算法(例如SVM)。分类目标是预测客户是否将预订定期存款(变量Y)。
5.实例数:bank-full.csv45211(bank.csv4521)
6.属性数:16个输出属性。
7.属性信息:有关更多信息,请阅读[Moro等,2011]。输入变量:#银行客户数据:
1-年龄(age)(数字)
2-工作(job):工作类型(类别:“管理员。”、“unknwn”、“失业”、“管理”、“女佣”、“企业家”、“学生”,“蓝领”、“自雇的”、“已退休的”、“技术员”、“服务”)
3-婚姻(marital):婚姻状况(类别:“已婚”、“离异”、“单一的”;注:"离异"意味着离婚或丧偶)
4-教育(education)(类别:“unknwn”、“次级的”、“主要的”、“第3次”)
5-默认(default):默认情况下是否有信用?(二进制:“是yes”、“否no”)
6-余额(balance):年平均余额,以欧元计(数字)
7-住房(housing):住房贷款?(二进制:“是yes”、“否no”)
8-贷款(loan):有个人贷款吗?(二进制:“是yes”、“否no”)与当前活动的最后联系人相关的:
9-联系人(contact):联系人通信类型(类别:“unknown”、“电话”、“cellular”)
10-天(day):上个月的最后一个联络日(数字)
11-月(month):上个月(类别:“简”、“2月2日”、"3月"等)。(“11月”、“12月”)
12-持续时间(duration):最后一个接触持续时间,单位为秒(数字)
13-活动(campaign):此活动期间执行的联系人数量以及此客户端(数字,包括上次联系人)
14-PM天(pdays):上次活动上次联系客户端后间隔的天数(数字,-1表示客户端未联系)
15-前(previous):此活动之前执行的联系人数量和此客户端(数字)
16-POUTET(poutcome):先前营销活动的结果(分类:“unknown”、“其他的”、“失败”、“成功”)输出变量(所需目标):
8.缺少属性值:无
数据分析具体代码如下:
#银行营销预测
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
class BankMarketData():
#探索数据
def detectData(self,filePath):
df = pd.read_csv(filePath,sep=";")
df.to_excel("bank_data/bank-full.xls")
#清洗数据以及数据抽取
def clean_choose_Data(self,filePath):
df = pd.read_excel(filePath)
filter1 = df['job'] != 'admin.'
filter2 = df['balance'] >0
filters = filter1 & filter2
df = df[filters]
df[['job','balance','duration','pdays','poutcome']].to_excel('bank_data/bank_cleaned_choose.xls')
#数据转换
def transfrom_Data(self,filePath):
df = pd.read_excel(filePath)
df['job'].replace(['unemployed', 'student', 'retired', 'self-employed', 'housemaid', 'services', 'blue-collar', 'technician','management', 'entrepreneur', 'unknown'], [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 5], inplace=True)
df['J'] = df['job']
df['B'] = df['balance']
df['D'] = df['duration']
df['P'] = df['pdays']
df['poutcome'].replace(['unknown','failure','success','other'],[0,1,2,0], inplace=True)
df['PC'] = df['poutcome']
df[['J','B','D','P','PC']].to_excel("bank_data/bank_transform_data.xls")
#数据标准化
def standarData(self,filePath):
df = pd.read_excel(filePath)
df = (df - np.mean(df,axis=0))/np.std(df,axis=0)
df[['J', 'B', 'D', 'P', 'PC']].to_excel("bank_data/bank_standar_data.xls")
#将数据分类以及绘制雷达图
def classifyData(self,filePath,k=5):
df = pd.read_excel(filePath)
kmeans = KMeans(k)
kmeans.fit(df[['J', 'B', 'D', 'P', 'PC']])
print(kmeans.cluster_centers_)
print(kmeans.labels_)
df['label'] = kmeans.labels_
df.to_excel("bank_data/bank_result_data.xls")
coreData = np.array(kmeans.cluster_centers_)
coreData.to_excel("bank_data/bank_center_data.xls")
# 绘制雷达图
# 1.组织数据
# 构造X轴值
xdata = np.linspace(0, 2 * np.pi, k, endpoint=False)
xdata = np.concatenate((xdata, [xdata[0]]))
ydata1 = np.concatenate((coreData[0], [coreData[0][0]]))
ydata2 = np.concatenate((coreData[1], [coreData[1][0]]))
ydata3 = np.concatenate((coreData[2], [coreData[2][0]]))
ydata4 = np.concatenate((coreData[3], [coreData[3][0]]))
ydata5 = np.concatenate((coreData[4], [coreData[4][0]]))
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
# 'o--'为点的形状
ax.plot(xdata, ydata1, 'o--', linewidth=1, label='customer1')
ax.plot(xdata, ydata2, 'o--', linewidth=1, label='customer2')
ax.plot(xdata, ydata3, 'o--', linewidth=1, label='customer3')
ax.plot(xdata, ydata4, 'o--', linewidth=1, label='customer4')
ax.plot(xdata, ydata5, 'o--', linewidth=1, label='customer5')
ax.set_thetagrids(xdata * 180 / np.pi, ['J', 'B', 'D', 'P', 'PC'])
ax.set_rlim(-3, 5)
plt.legend(loc='best')
plt.show()
if __name__ == '__main__':
ad = BankMarketData()
ad.detectData("bank_data/bank-full.csv")
ad.clean_choose_Data("bank_data/bank-full.xls")
ad.transfrom_Data("bank_data/bank_cleaned_choose.xls")
ad.standarData("bank_data/bank_transform_data.xls")
ad.classifyData("bank_data/bank_standar_data.xls",k=5)
"""
最后的kmeans分类结果以及数据意义如下:
'J', 'B', 'D', 'P', 'PC'
[[ 0.02216654 -0.05000923 -0.06517096 1.96174248 1.9887728 ] 客户群1
[-1.76713911 -0.08022154 -0.16501964 -0.33563193 -0.33761257] 客户群2
[ 0.40745133 -0.1343309 -0.27262972 -0.38310866 -0.38719431] 客户群3
[ 0.19034062 4.74854189 -0.10412082 -0.16329787 -0.13664836] 客户群4
[ 0.14365711 -0.05165223 2.48678883 -0.29658923 -0.32231959]]客户群5
"""
客户特征分析图:
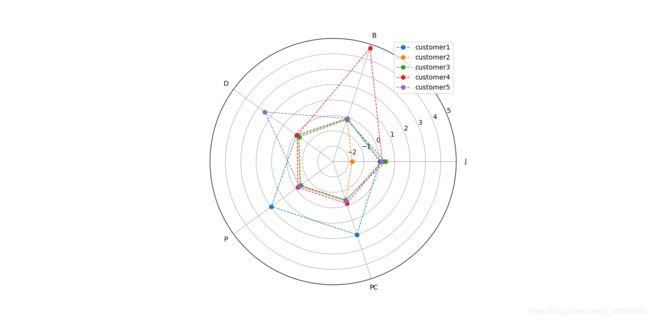
以数据和可视化图表为依据,针对聚类结果进行特征分析,通过如上图表观察可以看出:
• 客户群1 在P、PC属性上最大,在J、B、D上相对平均;
• 客户群2 在B、D、P、PC四个维度上相对平均,在J属性上最小;
• 客户群3 在J属性上最大,在B、D、P、PC上相对平均,没有明显的差异;
• 客户群4 在B属性上最大,在D、P、PC、J上相对平均;
• 客户群5 在D属性上最大,在P、PC、J、B属相上表现一般。
各个标签代表的意义如下:
J :工作(job):工作类型(类别:“管理员。”、“unknwn”、“失业”、“管理”、“女佣”、“企业家”、“学生”,“蓝领”、“自雇的”、“已退休的”、“技术员”、“服务”)
B : 余额(balance):年平均余额,以欧元计(数字)
D:持续时间(duration):最后一个接触持续时间,单位为秒(数字)
P:PM天(pdays):上次活动上次联系客户端后间隔的天数
PC:POUTET(poutcome):先前营销活动的结果
结合业务分析,通过比较各个指标在群间的大小对某一个群特征进行评价分析。在每个指标属性上都有最大、最下和次大、次小值,我们需要将其进行分析统计。例如客户群1在P、PC属性最大,在J指标上最小,因此可以说D在客户群1中为优势特征。以此类推,P、PC在客户群3上是劣势特征。从而总结出每个群的优势和弱势特征,具体如下表所示
客户群特征描述如下表:

注:
加粗字体 为最大属性指标;
加粗斜体 为次大或次小属性指标;
下划线_ 为最小属性指标。
由此,可看出客户群4是此次活动重点的营销对象;客户群5次之。与这些客户联系推荐关于预订定期存款方案的营销活动成功概率会比较大。