对FCN网络的理解
文章目录
- 对FCN网络的理解
- 1.对FCN的简要介绍
- 2.FCN与CNN的比较
- 3.FCN的原理
- 4.FCN模型的实现过程
- 5.FCN的简要总结
- FCN论文地址及源码地址
对FCN网络的理解
1.对FCN的简要介绍
自从卷积神经网络(CNN)被提出后,在图像检测,图像分类的方面取得了很大的突破,并被广泛应用。
CNN的优点在于它可以自动学习到多层次的特征。CNN层层递进,从较浅的卷积层到较深的卷积层,卷积层的感知域逐步增大,因此我们学习到的特征从局部到抽象,这有助于提高识别性能。
我们通过CNN可以很好的判断图像包含的是什么物体,但是却很难分割出物体的具体轮廓。
针对图像分割问题,Jonathan Long等人提出了Fully Convolutional Networks (FCN),该网络试图从抽象的特征中恢复出每个像素所属的类别。可以说是从图像级别的分类进一步延伸到像素级别的分类。
总体来说,FCN是图像分类到图像分割的一个过渡桥梁。
2.FCN与CNN的比较
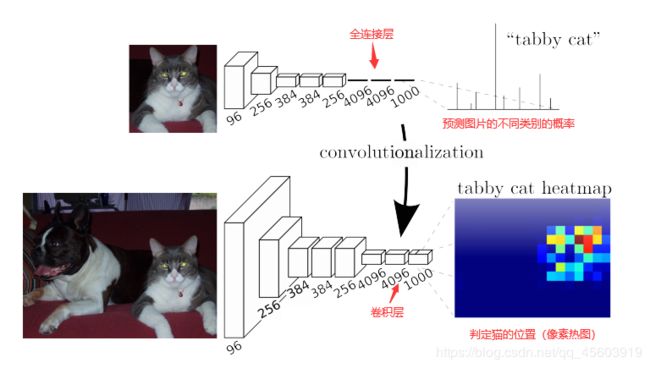
CNN:传统的CNN网络,在卷积层后一般会连接上若干个全连接层,将卷积后产生的特征图(feature map)映射成一个特征向量,如图最后输出一个长度为1000的特征向量,相对对应每种类别的预测概率。由此可见,CNN适用于图像级别的分类和回归的任务。
FCN:FCN是对图像进行像素级的分类,从而解决了语义级别的图像分割问题。FCN可以接受任意尺寸的输入图像,FCN将CNN网络后面的全连接层换成了卷积层,然后我们可以通过反卷积对最后卷积出来的特征图进行上采样,使它恢复至输入图像的相同尺寸,因此可以对每一个像素产生预测,然后通过对每个像素的预测概率在上采样后的特征图中进行像素的分类。因此FCN输出的是一张已经标记好的图,而不仅仅是一个概率值。
图像语义分割:
概念:FCN解决了语义级别的图像分割问题。因此我们需要对语义分割有个简单的概念。语义分割是在像素级别上进行讨论的。语义就是指图像内容或者图像目标,而分割就是在像素角度分割出图片中的不同目标。(如下图,我们内容就是人,马,车,那我们就是需要把这些内容给分割出来)

类型:
- 标准语义分割(standard semantic segmentation)也称为全像素语义分割,它是将每个像素分类为属于对象类的过程;
- 实例感知语义分割(instance aware semantic segmentation)是标准语义分割或全像素语义分割的子类型,它将每个像素分类为属于对象类以及该类的实体ID。
主要应用领域:地理信息系统,无人驾驶,医疗影像分析,机器人等。
这是一张无人驾驶通过车载摄像头或者激光雷达探查的图像输入到网络中分割出来的效果。(为了让大家更直观的感受)
3.FCN的原理
FCN的优越性主要体现在三种技术:
- 卷积化(Convolutional)
- 上采样(Upsample)
- 跳跃结构(Skip Layer)
卷积化(Convolutional):卷积化其实就是将普通的分类网络丢掉它们的全连接层换上对应的卷积层。
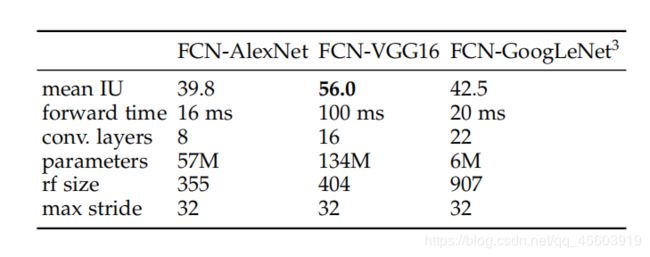
这里的分类网络有VGG16,AlexNet,GoogLeNet等。
论文中达到最高精度的分类网络是VGG16。
上采样(Upsample):上采样的主要目的是放大图像,在FCN网络中我们对各个像素进行了分类,且图像尺寸缩小了,因此我们需要将此时低分辨率的特征图还原到高分辨率的原图大小。因此上采样也是极为重要的。
-
插值法:主要采用双线性插值(因为FCN的上采样几乎不用这个,因此这里不过多介绍)
-
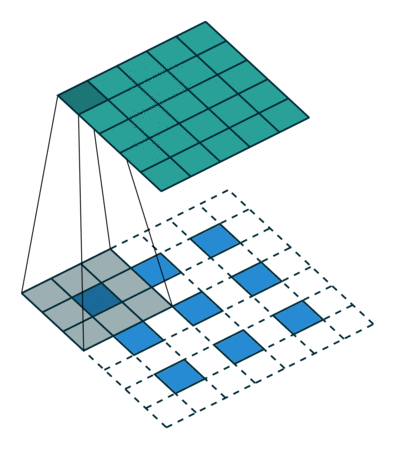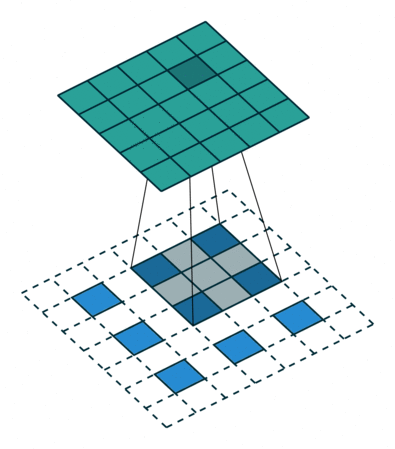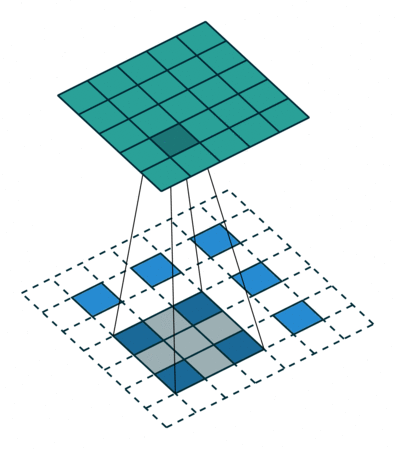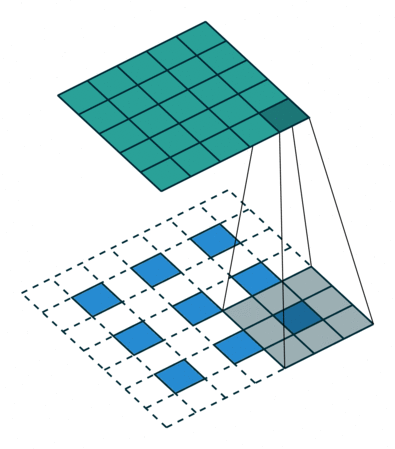
反卷积上采样:

上图是反卷积的一个过程,其实和卷积效果很像,由于我们输出的图片尺寸要大于反卷积的图片尺寸,因此会有一个自动填充(增加padding)的过程。
这里我们定义一下,输入图片尺寸为i,卷积核大小为k,步长为s,填充大小为p,输出图片尺寸为o,求输出尺寸的公式为
O = i − k + 2 ∗ p s + 1 O=\frac{i-k+2*p}{s}+1 O=si−k+2∗p+1
这里可以计算上面动图的输出o=(2-3+2*2)/1+1=4通过上面的反卷积过程我们其实可以发现在四周补0,其实对恢复图片的边沿信息是不利的,因此我们常见的反卷积应该是在每个像素与像素之间补0,这种反卷积的方式称作空洞卷积(微步卷积),专门针对初花导致分辨率降低,丢失信息提出的卷积思路。
-
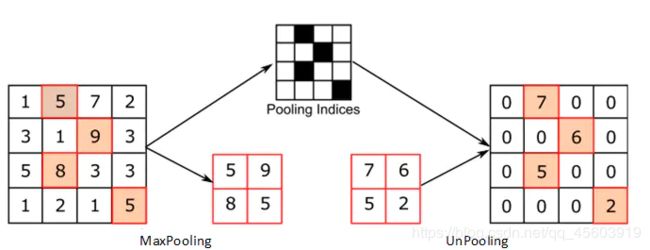
反池化上采样(做了解)
跳跃结构(Skip Layer):这个结构用来优化结果的,这里相当于把每一个池化层的结果进行上采样之后优化输出。
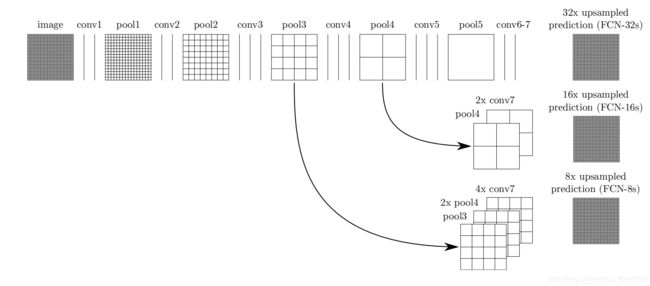
这里可以理解为分别将第7个卷积层卷积后的热图heatmap(我们把最后卷积出来的特征图为热图),第5层池化后的特征图,第3层池化后的特征图融合后进行反卷积的过程。目的是为了提高图片精度。
论文中提出除了图像融合之外还有一种shift-and-stitch技巧的方法来提高预测精度,这种技巧是一种折衷做法:输出更加密集且没有减小filter的接受域范围,但是相对于原始的设计filter不能感受更精细的信息。(具体信息可以参考论文)

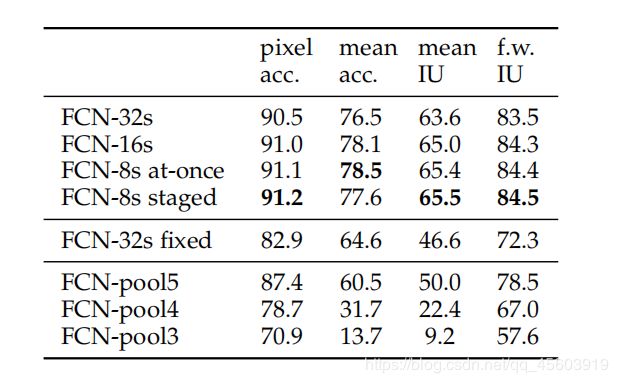
解释语义分割中的几个度量(参考:https://blog.csdn.net/majinlei121/article/details/78965435):
Pixel acc(像素精度):标记正确的像素占总像素的比例。
Mean acc(均像素精度):计算每个类别内被正确分类的像素数的比例,之后求所有类的平均
Mean IU(均交并比):语义分割最重要的度量。计算两个集合(真实值和预测值)的交集和并集之比,在每个类上计算IOU后平均。
FW IU(频权交并比):根据每个类出现的评率设置权重。
4.FCN模型的实现过程
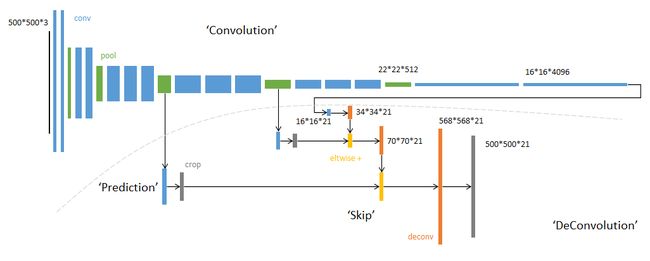
这是以AlexNet为基础,去除其全连接层换上卷积层的模型。
蓝色:卷积层
绿色:最大池化层
黄色:求和运算,即图片的融合过程
灰色:图片融合前裁剪为相同尺寸的图片
虚线:上方为卷积过程,下方为反卷积和图片融合的过程
模型实现过程简要还原(结合跳跃结构那张图和上图一起理解):
对图像进行前两次卷积后操作后,图像缩小到原来的1/4;
对图像进行第三次卷积操作conv3,pool3后,图像缩小为原来的1/8,并保留此时的特征图;
对图像进行第四次卷积操作conv4,pool4后,图像缩小为原来的1/16,并保留此时的特征图;
对图像进行第五次卷积操作conv5,pool5后,图像缩小为原来的1/32,接着进行卷积操作conv6,conv7后的图像被称作热图(heatmap);
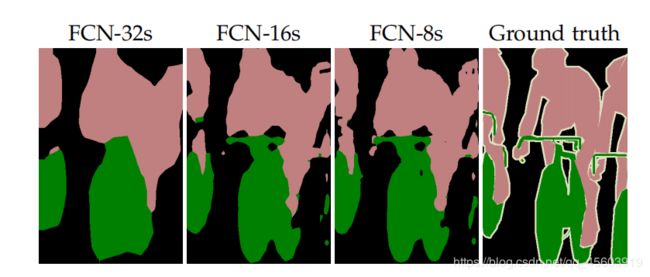
此时我们存在1/8的特征图,1/16的特征图,1/32的热图,,将热图进行反卷积取得FCN -32s,将1/16的特征图与upsampling操作(即将上下左右的像素点复制一遍)后的热图进行融合,并且进行反卷积得到FCN-16s,再将1/8的特征图与刚刚进行了upsampling融合的图片进行再次融合,再次进行反卷积,得到FCN-8s,就是精度最高的图片。
可以这么形象的理解,有一张白纸,我们第一次将conv7卷积核提取的特征放映到纸上,再依次将conv4,conv3卷积核提取的特征放映到纸上,那么我们呈现出来的就是我们提取出的目标 。
5.FCN的简要总结
FCN相比传统的CNN主要有两个优越性,首先FCN可以接受任何尺寸的图像输入,其次FCN通过卷积化,反卷积上采样,跳跃结构等特点在像素上进行分类,更加高效的进行图像内容的分割。
但是FCN 的缺陷也是存在的,虽说FCN-8s已经达到了一定程度的精确度,但是很明显得到的结果还是不够精细,上采样得到的结果还是存在模糊和平滑的现象,这是因为通过反卷积上采样我们无法特别好的找出像素点之间的关系(插值法就是用来找像素点之间的关系的,而反卷积法没有这种效果),很容易缺乏空间的一致性,因此我们对图像中的很多细节部分(小目标),没法很精确的分割。
用论文中提出的例子,很明显例一的FCN-8s,无法精确的分割出车的位置,例二的FCN-8s无法精确的分割出后面的观众。


FCN论文地址及源码地址
论文地址:https://arxiv.org/pdf/1605.06211v1.pdf
官方源码地址:https://github.com/shelhamer/fcn.berkeleyvision.org
FCN-tensorflow代码地址:https://github.com/EternityZY/FCN-TensorFlow