用Python实现电脑与手机之间的文件快速传输
有的时候想在Linux和手机之间互传文件那可真是一个难啊
看了这篇文章相信你会喜欢这种传输文件的方式
只需要电脑配置好Python即可
废话,不使用数据线和第三方工具,不用考虑各种驱动等等问题的文件传输肯定香啊
本文参考了微信公众号 “学习python的正确姿势” 11月18日的原创文章提供的方法, 地址为 https://mp.weixin.qq.com/s/7wFtS0nVRsHQF-Rh82kDKg
以下均为我学习之后的个人操作
1.移动端获取PC端文件
python3.7 -m http.server
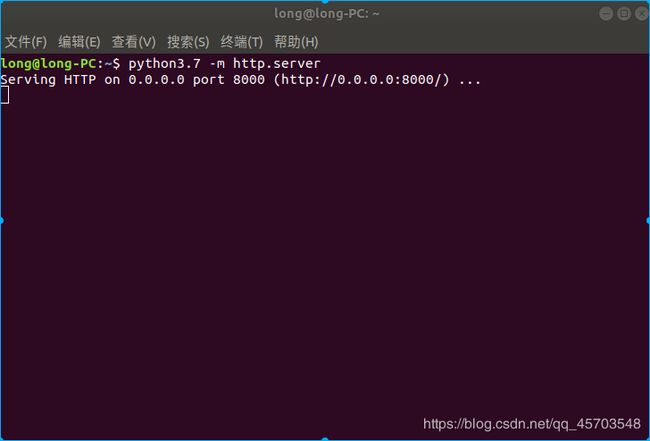
在终端只要执行这个命令,电脑就会默认监听8000端口,也可以修改监听的端口
# 监听3579端口
python3.7 -m http.server 3579
只要保持手机和电脑处于同一局域网(通俗来说就是连接着同一个wifi),在手机浏览器输入电脑的ip和端口就可以看到电脑端的文件啦
电脑的IP地址通过ifconfig命令获取

在手机浏览器中输入 “IP:端口”就可以访问了
http://192.168.1.111:8000/

然后实战操作一番,将电脑中的pdf文档下载到本地

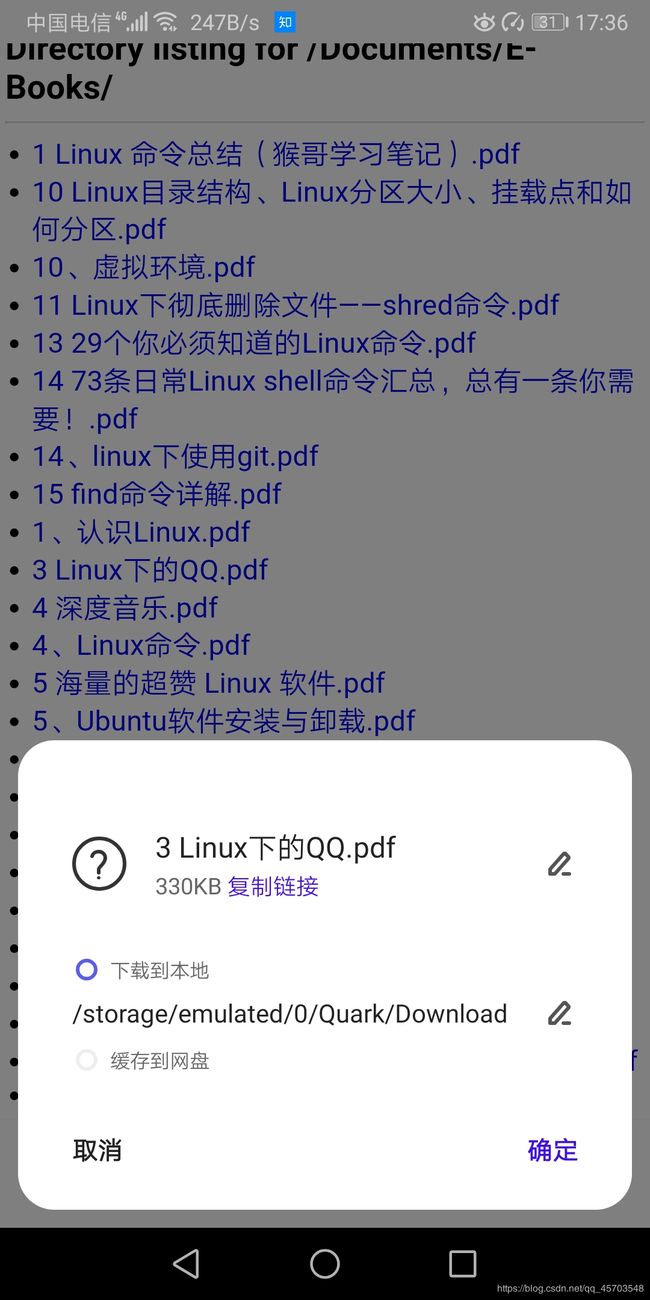
下载成功了
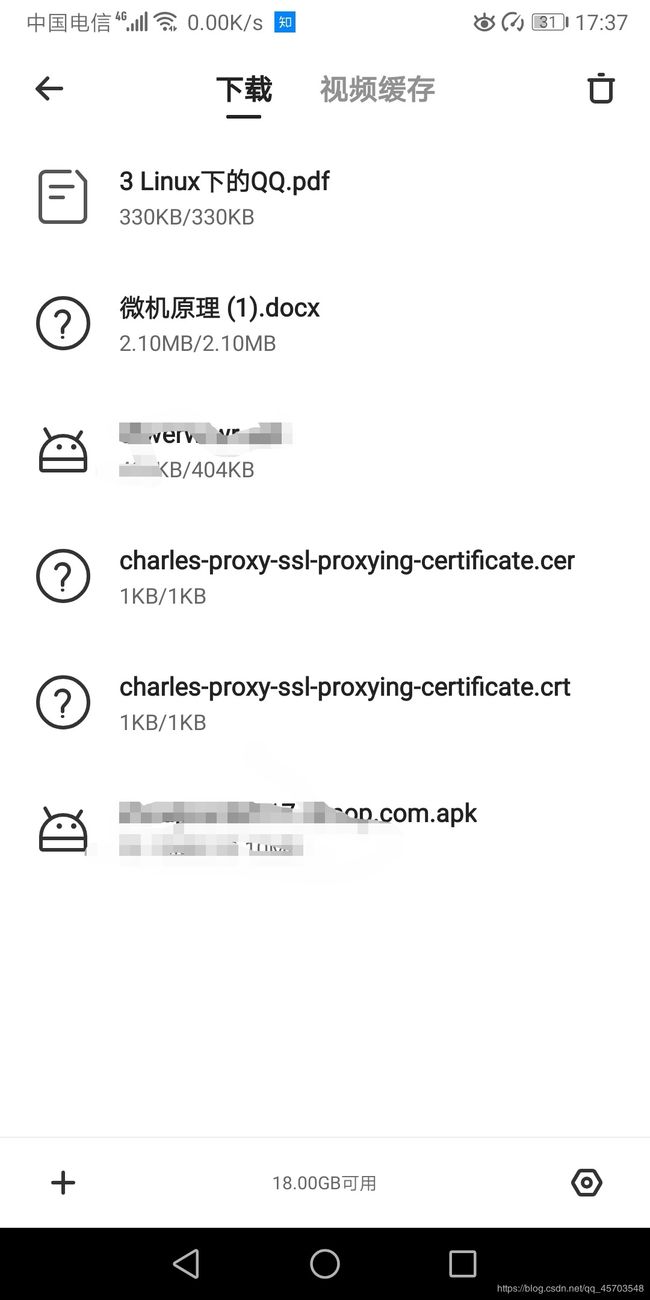
手机访问成功和文件下载成功之后终端都会有提示
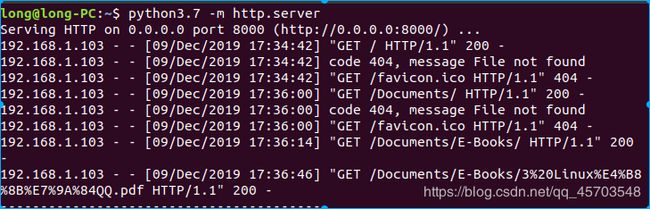
这种方法只能实现从电脑端下载文件,并不能把手机文件传输到电脑,下面的方法可以实现传输文件到电脑
2.移动端上传文件到PC端
这个呢有人已经做好了并发布在了github,感觉有用的朋友去github给作者点个star
https://github.com/Tallguy297/SimpleHTTPServerWithUpload
以下是源代码
#!/usr/bin/env python3
"""Simple HTTP Server With Upload.
This module builds on http.server by implementing the standard GET
and HEAD requests in a fairly straightforward manner.
see: https://gist.github.com/UniIsland/3346170
"""
__version__ = "0.1"
__all__ = ["SimpleHTTPRequestHandler"]
__author__ = "bones7456"
__home_page__ = "https://gist.github.com/UniIsland/3346170"
import os
import posixpath
import http.server
import socketserver
import urllib.request, urllib.parse, urllib.error
import html
import shutil
import mimetypes
import re
import argparse
import base64
from io import BytesIO
class SimpleHTTPRequestHandler(http.server.BaseHTTPRequestHandler):
"""Simple HTTP request handler with GET/HEAD/POST commands.
This serves files from the current directory and any of its
subdirectories. The MIME type for files is determined by
calling the .guess_type() method. And can reveive file uploaded
by client.
The GET/HEAD/POST requests are identical except that the HEAD
request omits the actual contents of the file.
"""
server_version = "SimpleHTTPWithUpload/" + __version__
def do_GET(self):
"""Serve a GET request."""
f = self.send_head()
if f:
self.copyfile(f, self.wfile)
f.close()
def do_HEAD(self):
"""Serve a HEAD request."""
f = self.send_head()
if f:
f.close()
def do_POST(self):
"""Serve a POST request."""
r, info = self.deal_post_data()
print((r, info, "by: ", self.client_address))
f = BytesIO()
f.write(b'')
f.write(b"\nUpload Result Page \n")
f.write(b"\nUpload Result Page
\n")
f.write(b"
\n")
if r:
f.write(b"Success:")
else:
f.write(b"Failed:")
f.write(info.encode())
f.write(("
back" % self.headers['referer']).encode())
f.write(b"
Powered By: bones7456, check new version at ")
f.write(b"")
f.write(b"here.\n\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
if f:
self.copyfile(f, self.wfile)
f.close()
def deal_post_data(self):
uploaded_files = []
content_type = self.headers['content-type']
if not content_type:
return (False, "Content-Type header doesn't contain boundary")
boundary = content_type.split("=")[1].encode()
remainbytes = int(self.headers['content-length'])
line = self.rfile.readline()
remainbytes -= len(line)
if not boundary in line:
return (False, "Content NOT begin with boundary")
while remainbytes > 0:
line = self.rfile.readline()
remainbytes -= len(line)
fn = re.findall(r'Content-Disposition.*name="file"; filename="(.*)"', line.decode())
if not fn:
return (False, "Can't find out file name...")
path = self.translate_path(self.path)
fn = os.path.join(path, fn[0])
line = self.rfile.readline()
remainbytes -= len(line)
line = self.rfile.readline()
remainbytes -= len(line)
try:
out = open(fn, 'wb')
except IOError:
return (False, "Can't create file to write, do you have permission to write?")
else:
with out:
preline = self.rfile.readline()
remainbytes -= len(preline)
while remainbytes > 0:
line = self.rfile.readline()
remainbytes -= len(line)
if boundary in line:
preline = preline[0:-1]
if preline.endswith(b'\r'):
preline = preline[0:-1]
out.write(preline)
uploaded_files.append(fn)
break
else:
out.write(preline)
preline = line
return (True, "File '%s' upload success!" % ",".join(uploaded_files))
def send_head(self):
"""Common code for GET and HEAD commands.
This sends the response code and MIME headers.
Return value is either a file object (which has to be copied
to the outputfile by the caller unless the command was HEAD,
and must be closed by the caller under all circumstances), or
None, in which case the caller has nothing further to do.
"""
path = self.translate_path(self.path)
f = None
if os.path.isdir(path):
if not self.path.endswith('/'):
# redirect browser - doing basically what apache does
self.send_response(301)
self.send_header("Location", self.path + "/")
self.end_headers()
return None
for index in "index.html", "index.htm":
index = os.path.join(path, index)
if os.path.exists(index):
path = index
break
else:
return self.list_directory(path)
ctype = self.guess_type(path)
try:
# Always read in binary mode. Opening files in text mode may cause
# newline translations, making the actual size of the content
# transmitted *less* than the content-length!
f = open(path, 'rb')
except IOError:
self.send_error(404, "File not found")
return None
self.send_response(200)
self.send_header("Content-type", ctype)
fs = os.fstat(f.fileno())
self.send_header("Content-Length", str(fs[6]))
self.send_header("Last-Modified", self.date_time_string(fs.st_mtime))
self.end_headers()
return f
def list_directory(self, path):
"""Helper to produce a directory listing (absent index.html).
Return value is either a file object, or None (indicating an
error). In either case, the headers are sent, making the
interface the same as for send_head().
"""
try:
list = os.listdir(path)
except os.error:
self.send_error(404, "No permission to list directory")
return None
list.sort(key=lambda a: a.lower())
f = BytesIO()
displaypath = html.escape(urllib.parse.unquote(self.path))
f.write(b'')
f.write(("\nDirectory listing for %s \n" % displaypath).encode())
f.write(b'\n')
f.write(("\nDirectory listing for %s
\n" % displaypath).encode())
f.write(b"
\n")
f.write(b")
f.write(b"")
f.write(b"\n")
f.write(b"
\n")
f.write(b'![[PARENTDIR]](data:image/gif;base64,R0lGODlhGAAYAMIAAP///7+/v7u7u1ZWVTc3NwAAAAAAAAAAACH+RFRoaXMgaWNvbiBpcyBpbiB0aGUgcHVibGljIGRvbWFpbi4gMTk5NSBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tACH5BAEAAAEALAAAAAAYABgAAANKGLrc/jBKNgIhM4rLcaZWd33KJnJkdaKZuXqTugYFeSpFTVpLnj86oM/n+DWGyCAuyUQymlDiMtrsUavP6xCizUB3NCW4Ny6bJwkAOw==) Parent Directory
Parent Directory
\n')
for name in list:
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAMIAAP///7+/v7u7u1ZWVTc3NwAAAAAAAAAAACH+RFRoaXMgaWNvbiBpcyBpbiB0aGUgcHVibGljIGRvbWFpbi4gMTk5NSBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tACH5BAEAAAEALAAAAAAYABgAAANdGLrc/jAuQaulQwYBuv9cFnFfSYoPWXoq2qgrALsTYN+4QOg6veFAG2FIdMCCNgvBiAxWlq8mUseUBqGMoxWArW1xXYXWGv59b+WxNH1GV9vsNvd9jsMhxLw+70gAADs='
fullname = os.path.join(path, name)
displayname = linkname = name
# Append / for directories or @ for symbolic links
if os.path.isdir(fullname):
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAMIAAP///+jNlr+/v6KXfm5SG2lPGjc3NwAAACH+RFRoaXMgaWNvbiBpcyBpbiB0aGUgcHVibGljIGRvbWFpbi4gMTk5NSBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tACH5BAEAAAIALAAAAAAYABgAAANjKLrc/jDKSau9WJbN9y1BKIZFVQzjOHRdsw1wDIMpyYAFke9ELa4Lmm9IWBkUwqHPiFQSmYKkU1U4Rqe1YrWJTUGlWK0VjP12R2Jubx1guwPQqGxOj22DrLzeujD4/4CBgAoJADs='
displayname = name + "/"
linkname = name + "/"
if os.path.islink(fullname):
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAPf/AJaWlpqampubm5ycnJ2dnZ6enp+fn6CgoKGhoaKioqOjo6SkpKWlpaampqioqKmpqaqqqqurq6ysrK2tra6urq+vr7CwsLGxsbKysrOzs7S0tLW1tba2tre3t7i4uLm5ubq6uru7u7y8vL29vb6+vr+/v8LCwsPDw8bGxtDQ0NTU1NXV1dbW1tfX19jY2Nra2tzc3N3d3eDg4OHh4eLi4uPj4+Tk5OXl5efn5+np6erq6uvr6+zs7O7u7u/v7/Dw8PHx8fLy8vPz8/T09PX19fb29vf39/j4+Pr6+vv7+/39/f7+/v///wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwAAAAAGAAYAAAI/wCZCBxIsKDBgwgLrsigwUXChEVGYNBwIYKIJA8LFunwocKGDA8ieMg4kAiHDxRmCGyhIAEKkhtR2iCYYYEAkiNQ3ijYIQGAjDkuVFBJsIcBAhcyttCgoSCQBQcUFMn44gIFEiwE/oAqIAfJIREeQLDAZIeCAwO8IuQRowYSIxQgBFhAoQBatQaFiLCQoQIFCxEMREUwoAEPhEA0dMQwQSwCIEFYpKCR8IfiCjWYgJCr4AhJyx13CFRhQYECGBmRcKwgmmAEBCsyltBQQUfBGwUG4MjoYMOIgjsSIJBAskGGEAR3IEhw4AdJExIeyBCIY/kBHySZLNEwgcGGDQYQNBbPLpAIBgULEhB4AIQ8wRMFBIhQ4j4gADs='
displayname = name + "@"
if name.endswith(('.bmp','.gif','.jpg','.png')):
dirimage = name
if name.endswith(('.avi','.mpg')):
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAMIAAP///7+/v7u7u1ZWVTc3NwAAAAAAAAAAACH+RFRoaXMgaWNvbiBpcyBpbiB0aGUgcHVibGljIGRvbWFpbi4gMTk5NSBLZXZpbiBIdWdoZXMsIGtldmluaEBlaXQuY29tACH5BAEAAAEALAAAAAAYABgAAANvGLrc/jAuQqu99BEh8OXE4GzdYJ4mQIZjNXAwp7oj+MbyKjY6ntstyg03E9ZKPoEKyLMll6UgAUCtVi07xspTYWptqBOUxXM9scfQ2Ttx+sbZifmNbiLpbEUPHy1TrIB1Xx1cFHkBW4VODmGNjQ4JADs='
if name.endswith(('.idx','.srt','.sub')):
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAPf/AAAbDiAfDSoqHjQlADs+J3sxJ0BALERHMk5LN1pSPUZHRk9NQU1OR05ZUFBRRFVXTVdYTVtVQFlVRFtbSF5bTVZWUltbUFlZVFtcVlxdWl5eWl1gWmBiV2FiXWNhXGRjXWlpYmtqZ2xtZmxsaG5ubHJva3Jzb3J0bHN0b3Z5dHd8eXh4dX18dXx/dnt8e31+eahMP4JdWIdnZox4cpVoYKJkXrxqablwcNA6Otg7O/8AAPwHB/0GBvgODvsMDPMbG/ceHvkSEuYqKvYqKvU2NvM6OvQ6OsFQUNVbW8N4eNd0duNeXu9aWvFUVOVqau1jY+1mZu5mZuh5eYSFgIWGgYaFgIiGgYqKiY6LioyMiY2NiYyMio2OiI6OjZCSjZSQi5OSkJGUkpSVk5WVlJWVlZiZlpiZmJ6emp2dnZSko6GhnKGhoKOjoaKnoqSkpKSmpKWmpaampqqrqKurqKqrqq2sqq6urrSyrrCwsLa3tb63tbi4t7q6ur+/vsCbm96Li9iUlMqursmwr9KwsN69veSCguiMjOiOjuaQkOWVleaXmOGfn+aYmOaamuebm+adneecnOeenuiQkOWgoOWsrOasrOWxseW2tue3t+e8vOi+vsHBwcfHx8jIxs7Mx8nJyMvLy8zMy83NzM7Pzs/Pz9PR0dTU1NXV1dXW1tbW1tfX19bb29jY2NnZ2djb29ra2tvb2tvb29za2tzc3N3d3d7e3t/f3+bCwufDw+fGxuTJyejCwujHx+nHx+vPz+rT0+rU1OrX1+vX1+rY2Ojf3+Hh4eLi4uPj4+Hn5+Tk5OXl5ebm5ufn5+nn5+jo6Onp6erp6evr6+zs7PDn5/Dq6vDt7fHv7/Lu7vPu7vPv7/Dw8PHx8fLy8vPz8/Tx8fbz8/T09PX19fX39/b29vj39/j4+Pn4+Pn5+fr5+fr6+vv7+/z7+/z8/P39/f7+/v/+/v///wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwAAAAAGAAYAAAI/wDhCRxIsKDBgwgTZis00F27hAbRNSpSaSC7ZM6ePQsXjdmzZekKUpOio0lBVShjJXvYjp07gsEm/dLhqKC2aNG2LesES13BXJTg4dLBi2C7kPDSyQFTRY26c8akZbolkJGOaQTZFTO2LA8KCCA+zDFTp4aggVCCmCtYrJUxNiI4nAjh4o2HGW1CrhvCxGC5cOVqvcCgQQUWGRtanOkG75qOQwXbhWvZ7lOZMIGSsJjihY5AYTowFWRnipUtT6BGWIARY8IXPc1eXtIxrKC7cqJCjdJCIcIBAwRoaLqU6IkRHthGnwPzoEGKDBISMHDAZWAvHUTWjaa1J42NAgAELMBAMGCNwHbWekQxqA4VMkBKSokZE8AKtHLpjuHxo0OSQXfuLKJIOHdc0IECFaxgQivpxHGDDpYc9McS5oBTAhxUbNHFFX2I4Q4fR+iwi0GPCCGLK6rYgQYJWZDhBil7cMMJDjpAAg85L8ETCRDVqAONMuGMA0446rDjEzzi5KDDD4j48g48huxAyCqtODNZOeWcM85DAxEDzDcE+YDEK5u0EostbZ2SyizsQASPE4PAo4466TxVZzptuqmLN266GRAAOw=='
if name.endswith('.iso'):
dirimage = 'data:image/gif;base64,R0lGODlhGAAYAPf/AKysrLGxsbe3t7i4uLm5uLm5ubq6ury8vL29vb6+vry+wb2+wKfeu7XGsbjNtr3UprnVqbbcvqjOzKTM0KbdwKvX2anZ1b/CxbTbw63R5LHS5b3T5dexrtuxrty+p+KvpOCxo8bLnsvJotjAptTPs9HRtcDAwMHBwcLCwsPDw8PCxMLDxsTDwsTEw8TExMXFxcbGxsfHx8jIyMnJycrJysrKysvLy87Ly8zMzM3Nzc7Ozs/PzsDe3NDQ0NHR0dLR0NLS0tPT09TU1NXV1dXW1tbW1tfX19HZ0dLb0NjV1NrW1djY2NnZ2dra2t3a2tzc3N3d3d7e3d/f3t/f38HU5cPf6sff68/e69Pf6sDi3Nng59zh5d7k5ujEw+nFxOnGxunIx+vLx+zNyePTy+Hf3+3Y0eDg3+Tg3+Dg4OHh4uLi4eLi4uPj4uPj4+Hj5OPk4+Th4OTk4+Tk5OXl5OXl5eXm5ebl5Obm5ebm5ubn5ufn5ufn5+Lm6uXo6unj4+rl5Ojo5+jo6Onp6Onp6erq6erq6urr6+vr6uvr6+vs6+zp6e3r6uzs6+zs7O3t7e3u7e7u7e7u7u/v7u/v7+fv9ezu8e3u8PDp6fHr6/Dw8PHx8PHx8fLy8fLy8vPy8vPz8vPz8/Tz8/T08/T09PX19PX19fX29fb19Pb29vf39vf39/j49/j4+Pn4+Pn5+Pn5+fr6+fr6+vv7+vv7+/z8+/z8/P39/P39/f7+/f7+/v7//////wAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwAAAAAGAAYAAAI/wB3CRxIsKBBg4hi6GCyBs+eQIH2PJSIB82QGYgKDnqBowmeRpEiTSo0qVGmSI3oGJkxSOOLGkXkIJpkBEEQHzagZEq5siXBjTOGtJnpwweKBFCE7FTJ0mXQoZH2TIGCh4kjR4jkFGn684UMIXIGTWkSpQ0bOTIbaa3hc+BGGUSeFIkyhxCkT6hKDaKztq3AQS5m3EgSZw4gRplIvbq1KxIUI2w1umDBAQycPIQkgVo1K9etWXSARP6pooGID1/+POKEKtatXLFSfQLCdWChBRIYPPAgBpMpVrV20WIFKpMUF4UKElKwIYOFCCTKKCrUSBWsUpkY3WmR/KcLN1quVPLJgmTRrViBPHlyJAgPDL+7BsW4AyhRJUpcQO3S1YePpUN62FHbXy/sUYgkobQiCSKvnHIED1ZgscUb72l0gh6OsCYLLY60QcYYJWBQgQZUXEBIQYWYYAYnitmSCy2ldHJJGCNAQMEEK3TnVgo5jMJZLra8UoomjfjRBQghOEADfIW88AIdtdyCSyyocMJeHWd40cEPA+4SSGA+TLJLLauAIkkhesgRhxJOLCHDHgXhwVETbTjCiiuiSHIIIGo8UYghTcyAR0GgyDCAAAYMEMAJO/QwAwEAFHCAAQXIMMpBmzhSyCCD4JHGFA0FMkghMxEUEAA7'
# Note: a link to a directory displays with @ and links with /
f.write((' %s
%s
\n'
% (urllib.parse.quote(linkname), dirimage , html.escape(displayname))).encode())
f.write(b"
\n\n\n")
length = f.tell()
f.seek(0)
self.send_response(200)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(length))
self.end_headers()
return f
def translate_path(self, path):
"""Translate a /-separated PATH to the local filename syntax.
Components that mean special things to the local file system
(e.g. drive or directory names) are ignored. (XXX They should
probably be diagnosed.)
"""
# abandon query parameters
path = path.split('?',1)[0]
path = path.split('#',1)[0]
path = posixpath.normpath(urllib.parse.unquote(path))
words = path.split('/')
words = [_f for _f in words if _f]
path = os.getcwd()
for word in words:
drive, word = os.path.splitdrive(word)
head, word = os.path.split(word)
if word in (os.curdir, os.pardir): continue
path = os.path.join(path, word)
return path
def copyfile(self, source, outputfile):
"""Copy all data between two file objects.
The SOURCE argument is a file object open for reading
(or anything with a read() method) and the DESTINATION
argument is a file object open for writing (or
anything with a write() method).
The only reason for overriding this would be to change
the block size or perhaps to replace newlines by CRLF
-- note however that this the default server uses this
to copy binary data as well.
"""
shutil.copyfileobj(source, outputfile)
def guess_type(self, path):
"""Guess the type of a file.
Argument is a PATH (a filename).
Return value is a string of the form type/subtype,
usable for a MIME Content-type header.
The default implementation looks the file's extension
up in the table self.extensions_map, using application/octet-stream
as a default; however it would be permissible (if
slow) to look inside the data to make a better guess.
"""
base, ext = posixpath.splitext(path)
if ext in self.extensions_map:
return self.extensions_map[ext]
ext = ext.lower()
if ext in self.extensions_map:
return self.extensions_map[ext]
else:
return self.extensions_map['']
if not mimetypes.inited:
mimetypes.init() # try to read system mime.types
extensions_map = mimetypes.types_map.copy()
extensions_map.update({
'': 'application/octet-stream', # Default
'.py': 'text/plain',
'.c': 'text/plain',
'.h': 'text/plain',
})
parser = argparse.ArgumentParser()
parser.add_argument('--bind', '-b', default='', metavar='ADDRESS',
help='Specify alternate bind address '
'[default: all interfaces]')
parser.add_argument('port', action='store',
default=8000, type=int,
nargs='?',
help='Specify alternate port [default: 8000]')
args = parser.parse_args()
PORT = args.port
BIND = args.bind
HOST = BIND
if HOST == '':
HOST = 'localhost'
Handler = SimpleHTTPRequestHandler
with socketserver.TCPServer((BIND, PORT), Handler) as httpd:
serve_message = "Serving HTTP on {host} port {port} (http://{host}:{port}/) ..."
print(serve_message.format(host=HOST, port=PORT))
httpd.serve_forever()
我已经克隆了github的仓库,之后执行此Python脚本
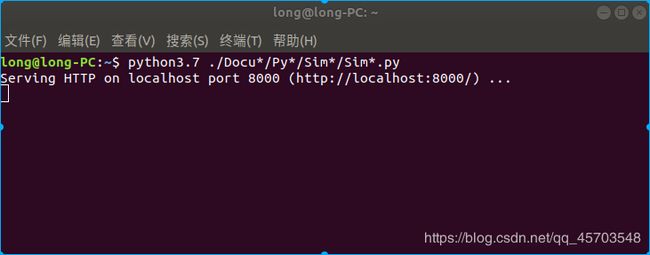
然后在手机端输入 http://192.168.1.111:8000
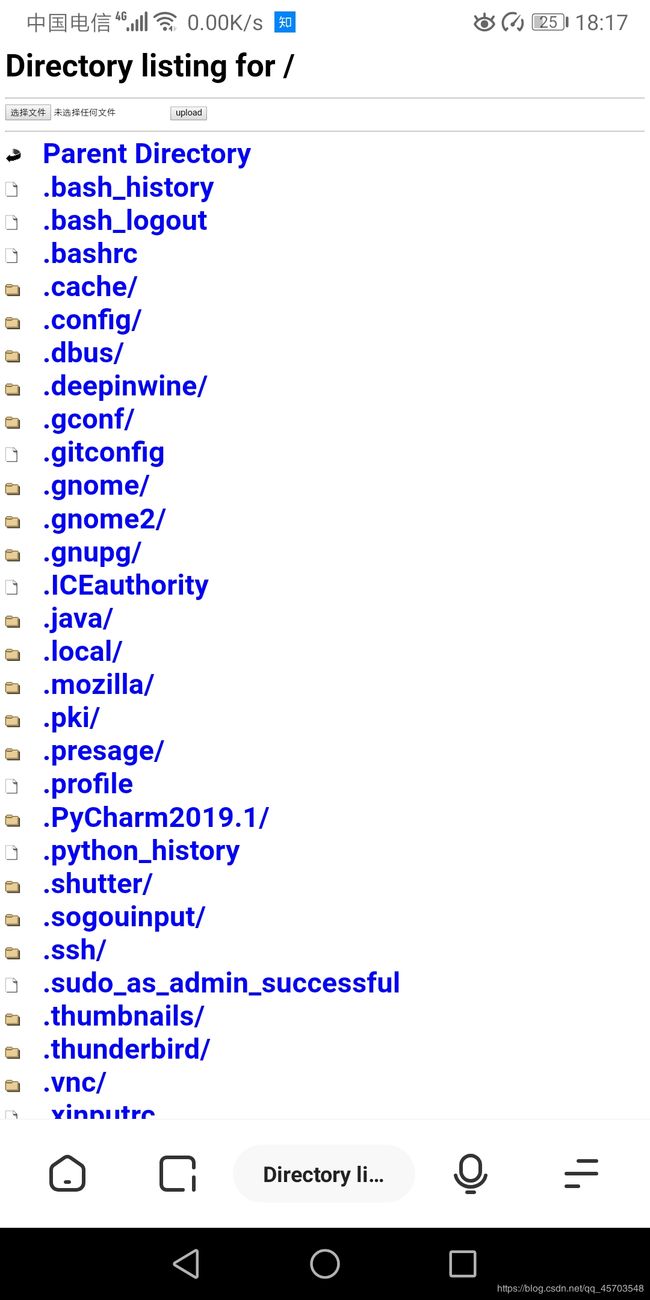
有了选择上传和upload两个选项
小试牛刀,将手机中的一首歌曲《晴天》上传到电脑


上传成功后终端的显示
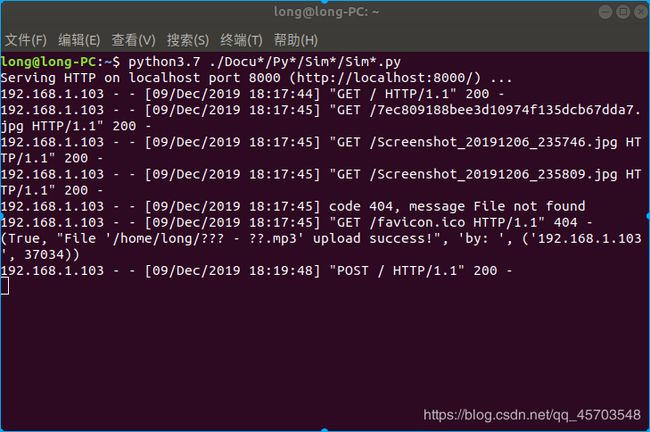
看我的家目录下是否多了MP3文件

文件名中的中文乱码了,一丢丢的遗憾