SMASH方法使用辅助网络生成次优权重来支持网络的快速测试,从结果来看,生成的权重与正常训练的权重在准确率上存在关联性,整体搜索速度很快,仅需要单卡进行搜索,提供了一个很好的新思路。
来源:晓飞的算法工程笔记 公众号
论文: SMASH: One-Shot Model Architecture Search through HyperNetworks

- 论文地址:https://arxiv.org/abs/1708.05344
- 论文代码:https://github.com/ajbrock/SMASH
Introduction
常规的网络设计需要耗费大量的时间进行验证,为了节约验证时间,论文提出训练一个辅助网络HyperNet,用于动态生成不同结构模型的权重。尽管使用这些生成权重的性能不如常规学习到的权重,但在训练初期,使用生成权重的不同网络的相对性能可以在一定程度上映射出其最优状态时的相对性能。因此,论文提出one-shot模型结构搜索SMASH(one-Shot Model Architecture Search through Hypernetworks),结合辅助网络生成的权重,可以仅使用一轮训练来对大量的结构进行排序。
One-Shot Model Architecture Search through HyperNetworks

SMASH的逻辑如算法1,核心是通过辅助网络HyperNet根据不同的网络结构生成对应的权重,然后根据验证集表现进行排序:
- 首先训练辅助网络HyperNet,在每个训练阶段,随机采样一个网络,然后使用HyperNet生成权重,end-to-end地对其进行完整的反向训练。
- 在训练好HyperNet后,随机采样大量的网络结构,使用HyperNet生成的权重,然后在测试集上验证性能。
- 选择性能最好的结构进行最终的训练测试。
SMASH包含两个核心部分:
- 如何生成网络结构。论文采用基于存储体(memory bank)的前向网络,能够生成复杂且多分支的拓扑结构,并且能够使用二进制向量进行编码。
- 如何根据网络结构生成权重。训练一个辅助网络HyperNet,直接学习二进制结构编码到权重空间的映射。
论文认为,只要HyperNet学习到如何生成有效的权重,那么在验证集上,使用生成权重的网络的准确率会和正常训练的网络的准确率产生关联,此时,网络的结构将会变成影响验证集准确率的主要因子。
Defining Variable Network Configurations

为了能够生成多种的网络结构并且方便编码输入HyperNet,论文采用存储体(memory-bank)的方式进行网络表示,将网络视为一系列初始为0的存储体,每层的操作视为对存储体的读写。对于单分支网络,网络包含一个大的存储体,每次操作都覆盖存储体的内容(对ResNet是相加),对于DenseNet的多分枝网络,则读取所有前面的存储体,然后将结果写入空的存储体,而对于FractalNet,则构造更为复杂。
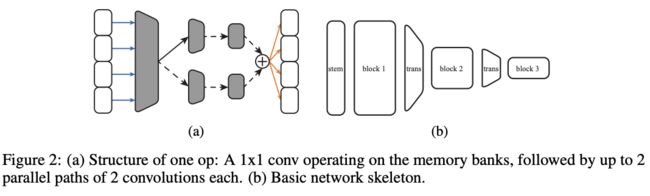
SMASH的基础模型包含多个block,如图2(b),每个block包含多个特定分辨率的存储体,前后block间的存储体分辨率为1/2倍,通过$1\times 1$卷积加平均池化进行下采样,$1\times 1$卷积和全连接输出层的权重是学习来的,不是生成的。
在采样网络时,每个block中的存储体个数以及每个存储体的channel数都是随机的,而block中的层则随机选择读写模式以及处理数据的op操作。当读入多个存储体时,在channel维度对存储体的tensor进行concat,而写入时则将结果与每个存储体中的tensor相加。在实验中,层仅允许读取所属的block的存储体。
op操作包含用于降维$1\times 1$卷积、多个常规卷积和非线性激活,如图2(a),每次随机选择4个卷积中一个激活,包括其卷积核大小,输出channel等超参也是随机的,$1\times 1$卷积的输出channel数与op的输出channel数成一定比例,比例也是随机选取的,特别说明:
- $1\times 1$卷积的权重由HyperNet生成,其它卷积则通过正常训练获得(算法1的first loop)。
- 为了保证可变的深度,每个block仅学习4个卷积,并且在block的op操作中共享其权值。限制最大卷积核大小以及最大输出channel数,假设选择的op操作的参数小于最大值,则将权重裁剪至目标大小。
- 下采样卷积和输出层同样基于输入的channel数对权重进行裁剪。
在设计时,为了让网络更多地采用HyperNet产生的权重,仅在下采样层中以及输出层之前使用BatchNorm,主要由于很难通过生成的方式产生这种运行时统计的结果。为了弥补这一举措,使用WeightNorm的改进版,将生成的$1\times 1$卷积核除以其欧几里得范数进行正则化(不是单独正则化各channel),这对SMASH十分有效,仅带来些许的性能下降。
Learning to map architectures to weights
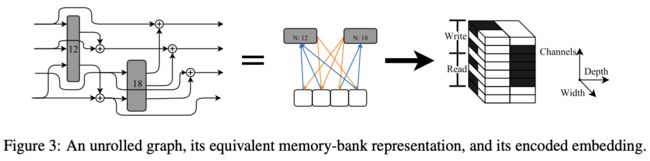
Hypernet采用全卷积网络,这样输出的$W$可以根据输入$c$的大小改变而改变,输入$c$为4维tensor(BCHW),batch size为1,这样输出就不会存在完全独立性。输出$W$的每个channel都对应$c$的一个子集,而权重$W$对应op操作的信息都embedding在$c$的channel中。
假设op读取1,2,4存储体然后写入2,4存储体,则输入$c$的1、2和4 channel会填入1,代表输入的存储体,而6、8 channel也会填入1,代表输出的存储体,剩余的channel用于描述op的其它超参数,比如膨胀值(dilation),输入$c$的width方向是对op操作的输出channel数的编码。
基于以上的Hypernet结构,naïve的实现要求输入$c$的大小和$W$的大小一致或者使用上采样来产生更多的输出,但这样效果不好。论文使用channel-based的权重压缩方法,不仅能够减小$c$的大小,还能保持HyperNet的表达能力。简单讲就是将输入$c$的分辨率设定为$W$的大小进行$1/k$,HyperNet的输出channel设定为$k$,最后将结果reshape成$W$的大小,具体可以看看论文的附录B。
Experiments
Testing the SMASH correlation
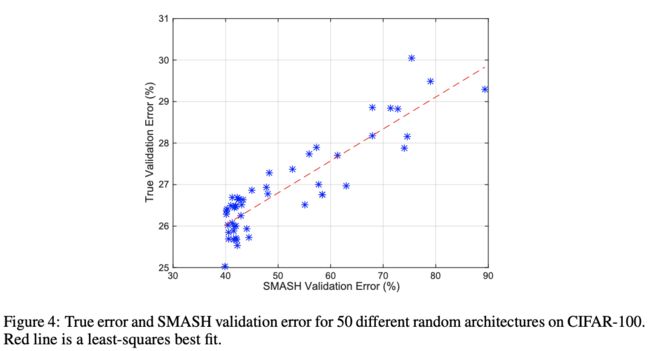
对比SMASH生成权重的网络与正常训练的网络的准确率,证明SMASH生成的权重可以快速地比较相对准确率。
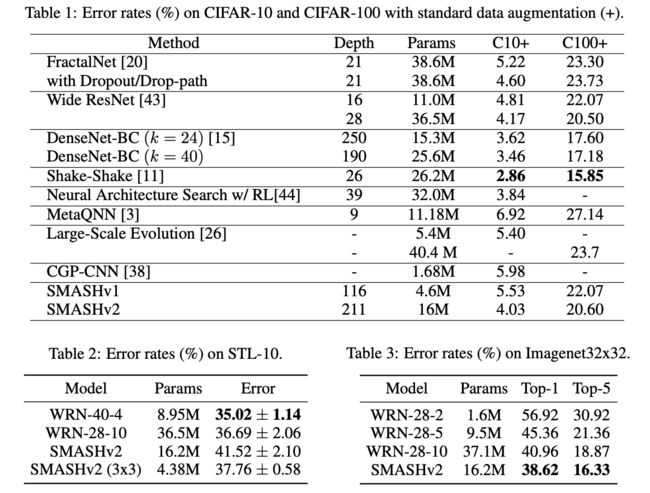
Benchmarking
CONCLUSION
SMASH方法使用辅助网络生成次优权重来支持网络的快速测试,从结果来看,生成的权重与正常训练的权重在准确率上存在关联性,整体搜索速度很快,仅需要单卡进行搜索,提供了一个很好的新思路。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
