K-Means原理详解与Java代码实现细节
本文作者:合肥工业大学 管理学院 钱洋 email:[email protected] 内容可能有不到之处,欢迎交流。
未经本人允许禁止转载。
最近,在使用K-means作为baseline跑数据,不想拿着别人的代码直接跑跑,自己在看了一些别人的代码后,自己改写了一份。只有真正的去写算法的底层源码,才能真能理解算法的内涵以及编程细节。
K-Means原理介绍
K-Means,即K均值算法,是一种非常常用的无监督聚类方法,使用时需要首先确定簇的数目即K值(后面有人改进,也可以自动确定较为合理的K值)。在确定需要聚的簇数目后,接着初始化K个聚类中心(也称为质心),通过计算每个数据样本与每个质心的距离,将数据样本分配到与其最近的质心代表的簇中。待所有点分配到K簇中后,计算每个簇中所有数据点的算术平均值(这是一种方法)作为新的质心。重新迭代,计算距离并将数据重新划分簇。不断的进行这种迭代操作,直至达到我们定义的迭代次数后,结束迭代,输出每个簇的结果。
以下为K-Means的算法步骤:
1.初始化簇的数目K,随机选择K个聚类中心。
2.重复以下操作,直到聚类中心不再发生变化:
a. 计算每个数据样本到聚类中心的距离,将数据样本划分到最近的的簇中。
b. 计算每个簇中所有数据各维度的均值,作为每个簇新的聚类中心。
3.输出每个簇所聚的数据样本。
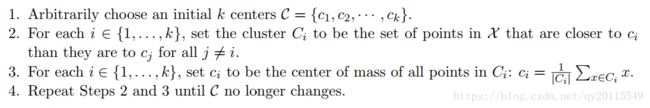
K-Means中的距离定义
使用K-Means聚类一个很重要的地方是定义距离公式,通过距离公式,可以将数据划分到最近的簇中。以下我列举了常用的几种距离:
Euclidean Distance(欧几里得距离):最常用的距离公式,其公式如下(数据维度为n):
Minkowski Distance(明式距离),公式如下:
Cos(余弦距离),公式如下:
Jaccard距离,公式如下:
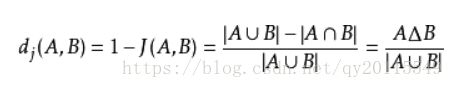
通常,我们在做文本聚类的时候,可以使用一定的编码方式(如One-Hot、TF-IDF、Doc2vec)等,编码之后,使用余弦距离或者Jaccard距离计算文本与质心的距离
初始化优化K-Means++
K个初始化质心的选择对最后的聚类的结果和算法收敛的时间有很大的影响,所以通过合适的方法选择K个质心很重要。Arthur D等人与2007年提出了一种特殊而简单的方法来选择K个质心。其将 D(x) D ( x ) 定义为样本数据到最近质心的距离,按照如下步骤初始化质心:
1. 从输入的样本集合中随机选择一个样本作为第一个聚类中心。
2. 计算数据中每个样本点到已有聚类中心的最短距离 D(xi)=argmin||xi−μr||22r=1,2,...kselected D ( x i ) = a r g m i n | | x i − μ r | | 2 2 r = 1 , 2 , . . . k s e l e c t e d 。
3. 基于 D(x) D ( x ) 较大的点,被选取作为聚类中心的概率较大的原则,重新选择一个新的聚类中心。
4. 重复第2和第3步骤,直至选择出K个聚类中心。
5. 利用这K个初始化的聚类中心运行标准K-means算法。

在论文k-means++: The advantages of careful seeding作者证明了通过这种初始化的算法的复杂度,这里就不做过多的分析了。
代码编写
借鉴的源码地址为:https://github.com/Hazoom/documents-k-means,即使用k-means对文档聚类。本人代码结构如下,使用的是K-means++初始化操作:
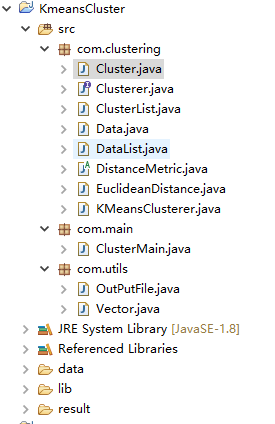
其中,com.clustering包里面存放的数据点、数据集合、单个簇、多个簇的操作,以及距离定义。com.util放的是向量的操作以及输出结果保存的操作。com.main为一个测试的主方法。如下,为本人测试的案例数据,第一列是数据的Title,其可以使文本的形式,后面的数据是样本各维度的值(这里共有两个维度):

main
如下程序,需要定义聚类的总数目(当然也可以判断质心不怎么发生改变为止),设置数据的维度(数据多少列)以及聚类的数目。首先,读入文件并使用DataList类中的方法,将数据处理成指定格式(编号、设置标题以及转化成向量)。接着,定义我们使用的距离计算。下一步,运行K-means方法。最后,输出聚类结果。
package com.main;
import java.io.IOException;
import com.clustering.ClusterList;
import com.clustering.Clusterer;
import com.clustering.DistanceMetric;
import com.clustering.DataList;
import com.clustering.EuclideanDistance;
import com.clustering.KMeansClusterer;
import com.utils.OutPutFile;
public class ClusterMain {
private static final int iter = 500; //设置总迭代次数
private static final int feature_number = 2; //设置特征维度
private static final int k = 3; //确定簇的数目
public static void main(String[] args) throws IOException {
//文档目录
String fileinput = "data/data.txt";
//读取文件,将其转化成向量形式
DataList documentList = new DataList(fileinput,feature_number);
//定义距离公式,这里使用欧几里得距离
DistanceMetric distance = new EuclideanDistance();
Clusterer clusterer = new KMeansClusterer(distance, iter);
//聚类
ClusterList clusterList = clusterer.runKMeansClustering(documentList, k);
System.out.println(clusterList);
//输出结果
OutPutFile.outputClusterAndContent("result/cluster"+k,clusterList);
}
}clustering
DataList :数据集合表示和操作的类:
package com.clustering;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import com.utils.Vector;
/** 数据集合表示和操作的类 */
public class DataList implements Iterable<Data> {
private final List datas = new ArrayList();
/** 构造空的DataList */
public DataList() {
}
public DataList(String input,int numFeatures) throws IOException {
BufferedReader reader = new BufferedReader( new InputStreamReader( new FileInputStream( new File(input)),"gbk"));
String s = null;
int i = 0;
while ((s=reader.readLine())!=null) {
//标题
String arry[] =s.split("\t");
//向量内容
String[] vectorString = arry[1].split("\\s+");
Vector vector = new Vector(numFeatures);
for (int j = 0; j < vectorString.length; j++) {
//向量添加值
vector.set(j, Double.parseDouble(vectorString[j]));
}
//文档的名称
String title =arry[0];
//输入编号,对应的向量,对应的名称
Data data = new Data(i, title);
data.setVector(vector);
datas.add(data);
i++;
}
reader.close();
}
/** 添加数据至DataList */
public void add(Data data) {
datas.add(data);
}
/** 数据集合移除 */
public void clear() {
datas.clear();
}
/** 将所有数据点设置为未分配 */
public void clearIsAllocated() {
for (Data data : datas) {
data.clearIsAllocated();
}
}
/** 获取id为index的数据点 */
public Data get(int index) {
return datas.get(index);
}
/** 确定集合是否为空 */
public boolean isEmpty() {
return datas.isEmpty();
}
@Override
public Iterator iterator() {
return datas.iterator();
}
/** 数据的数量 */
public int size() {
return datas.size();
}
/** 集合排序 */
public void sort() {
Collections.sort(datas);
}
/** 需要展示的结果 */
public String toString() {
StringBuilder sb = new StringBuilder();
for (Data data : datas) {
sb.append(" ");
//获取数据
sb.append(data.toString());
sb.append("\n");
}
return sb.toString();
}
}
Data :单个数据点表示的类:
package com.clustering;
import com.utils.Vector;
/** 单个数据点表示的类 */
public class Data implements Comparable<Data> {
private final String title;
private final long id;
private boolean allocated;
private Vector vector;
private int numFeatures;
public Data(long id, String title) {
this.id = id;
this.title = title;
}
/** 数据点清除分配 */
public void clearIsAllocated() {
allocated = false;
}
/** 继承,按照id排序输出 */
@Override
public int compareTo(Data data) {
if (id > data.getId()) {
return 1;
} else if (id < data.getId()) {
return -1;
} else {
return 0;
}
}
/** 获取数据id */
public long getId() {
return id;
}
/**获取数据标题 */
public String getTitle() {
return title;
}
/** 获取向量唯独 */
public int getNumFeatures() {
return numFeatures;
}
/**
* 获取数据向量
*/
public Vector getVector() {
return vector;
}
/** 确定数据是否被分配到簇 */
public boolean isAllocated() {
return allocated;
}
/** 标记该数据点已被分配 */
public void setIsAllocated() {
allocated = true;
}
/**
* 设置向量和维度
*/
public void setVector(Vector vector) {
this.vector = vector;
this.numFeatures = vector.size();
}
//默认输出
public String toString() {
return "Data: " + id + ", Title: " + title;
}
}EuclideanDistance :计算两个向量之间的欧几里得距离:
package com.clustering;
import com.utils.Vector;
/** 计算两个向量之间的欧几里得距离 */
public class EuclideanDistance extends DistanceMetric {
protected double calcDistance(Vector vector1, Vector vector2) {
return vector1.getEuclideanDistance(vector2);
}
}DistanceMetric :抽象类:计算距离,距离越近越相似(假如我们需要添加更多的距离计算方法,只要写一个继承类就行了):
package com.clustering;
import com.utils.Vector;
/**
* 抽象类:计算距离,距离越近越相似
*/
public abstract class DistanceMetric {
/** 计算数据点data距离cluster质心的距离 */
public double calcDistance(Data data, Cluster cluster) {
return calcDistance(data.getVector(), cluster.getCentroid());
}
/**
* 计算某一数据点data距离所有簇质心的最小值
* @param Data,数据点
* @param ClusterList,簇集合
* @return distance,最小距离
*/
public double calcDistance(Data data, ClusterList clusterList) {
double distance = Double.MAX_VALUE;
for (Cluster cluster : clusterList) {
distance = Math.min(distance, calcDistance(data, cluster));
}
return distance;
}
/** 计算向量之间的距离 */
protected abstract double calcDistance(Vector vector1, Vector vector2);
}Cluster :单个簇操作的类:
package com.clustering;
import com.utils.Vector;
/** 单个簇操作的类 */
public class Cluster implements Comparable<Cluster> {
private Vector centroid;
private final DataList datas = new DataList();
private final int numFeatures;
/** 随机取一个数据点作为质心 */
public Cluster(Data data) {
add(data);
centroid = new Vector(data.getVector());
numFeatures = data.getNumFeatures();
}
/** 簇中添加数据,并将该数据设置为已分配 */
public void add(Data data) {
data.setIsAllocated();
datas.add(data);
}
/** 将簇中的数据移除 */
public void clear() {
datas.clearIsAllocated();
datas.clear();
}
/** 对簇中的数据进行排序. */
@Override
public int compareTo(Cluster cluster) {
if (datas.isEmpty() || cluster.datas.isEmpty()) {
return 0;
}
return datas.get(0).compareTo(cluster.datas.get(0));
}
/** 获取质心 */
public Vector getCentroid() {
return centroid;
}
/** 获取数据 */
public DataList getDatas() {
return datas;
}
/** 簇中数据的数量 */
public int size() {
return datas.size();
}
/** 基于数据点的id,排序 */
public void sort() {
datas.sort();
}
/** 需要展示的结果 */
@Override
public String toString() {
return datas.toString();
}
/** 更新该 簇的质心 */
public void updateCentroid() {
centroid = new Vector(numFeatures);
//该簇中的数据进行循环
for (Data data : datas) {
centroid = centroid.add(data.getVector());
}
centroid = centroid.divide(size());
}
}
ClusterList : 多个簇操作的类:
package com.clustering;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
/** 多个簇操作的类 */
public class ClusterList implements Iterable<Cluster> {
private final ArrayList clusters = new ArrayList();
/** 添加一个簇 */
public void add(Cluster cluster) {
clusters.add(cluster);
}
/**
* 迭代后需要将簇的数据全部移除
*/
public void clear() {
for (Cluster cluster : clusters) {
cluster.clear();
}
}
/**
* 计算未分配的数据离质心的距离,确定一个离质心最远的一个点,这里采用的是欧几里得距离公式
* @param DistanceMetric,距离
* @param DataList,数据集合
* @return Data,数据点
*/
public Data findFurthestData(DistanceMetric distance, DataList dataList) {
double furthestDistance = Double.MIN_VALUE;
Data furthestData = null;
for (Data data : dataList) {
if (!data.isAllocated()) {
//找最远距离
double dataDistance = distance.calcDistance(data, this);
if (dataDistance > furthestDistance) {
furthestDistance = dataDistance;
furthestData = data;
}
}
}
return furthestData;
}
/**
* 寻找数据点data距离最近的簇
*
* @param DistanceMetric,距离
* @param data,数据
* @return Cluster,簇
*/
public Cluster findNearestCluster(DistanceMetric distance, Data data) {
Cluster nearestCluster = null;
double nearestDistance = Double.MAX_VALUE;
for (Cluster cluster : clusters) {
//计算距离
double clusterDistance = distance.calcDistance(data, cluster);
if (clusterDistance < nearestDistance) {
nearestDistance = clusterDistance;
nearestCluster = cluster;
}
}
return nearestCluster;
}
@Override
public Iterator iterator() {
return clusters.iterator();
}
/**返回簇的数量 */
public int size() {
return clusters.size();
}
/**
*数据点序号排序,然后排序cluster
*/
private void sort() {
for (Cluster cluster : this) {
cluster.sort();
}
Collections.sort(clusters);
}
/**
* 输出情况下展示结果
*/
public String toString() {
sort();
StringBuilder sb = new StringBuilder();
int clusterIndex = 0;
for (Cluster cluster : clusters) {
sb.append("Cluster ");
sb.append(clusterIndex++);
sb.append("\n");
sb.append(cluster);
}
return sb.toString();
}
/**基于各维度的算术平均值更新每个簇质心 */
public void updateCentroids() {
for (Cluster cluster : clusters) {
cluster.updateCentroid();
}
}
}
Clusterer :聚类接口:
package com.clustering;
/**
* 聚类接口
*/
public interface Clusterer {
public ClusterList runKMeansClustering(DataList documentList, int k);
}
KMeansClusterer :k-means聚类的实现:
package com.clustering;
import java.util.Random;
public class KMeansClusterer implements Clusterer {
private static final Random RANDOM = new Random();
private final int clusteringIterations;
private final DistanceMetric distance;
/**
* Construct a Clusterer.
* @param K-means聚类需要使用到的距离公式
* @param k-means的迭代次数
*/
public KMeansClusterer(DistanceMetric distance, int clusteringIterations) {
this.distance = distance;
this.clusteringIterations = clusteringIterations;
}
/** 计算所有未分配的数据点到质心的距离,基于最小原则给数据分配簇 */
private void assignUnallocatedDataPoints(DataList dataList, ClusterList clusterList) {
for (Data data : dataList) {
if (!data.isAllocated()) {
//寻找离data数据点最近的簇
Cluster nearestCluster = clusterList.findNearestCluster(distance, data);
//将数据data添加到该簇中
nearestCluster.add(data);
}
}
}
/** 基于最远距离创建一个新的簇 */
private Cluster createClusterBasedFurthestData(DataList dataList,ClusterList clusterList) {
//找离该中心点最远的点
Data furthestDocument = clusterList.findFurthestData(distance, dataList);
//创建一个新的簇
Cluster nextCluster = new Cluster(furthestDocument);
return nextCluster;
}
/** 随机选择一个数据点作为质心 */
private Cluster createClusterWithRandomlySelectedDataPoint(DataList dataList) {
int rndDataIndex = RANDOM.nextInt(dataList.size()); // 随机取数据编号
//将该编号对应的数据点进行分配,并将数据标记为已分配
Cluster initialCluster = new Cluster(dataList.get(rndDataIndex));
return initialCluster;
}
/** kmeans运行步骤*/
public ClusterList runKMeansClustering(DataList dataList, int k) {
ClusterList clusterList = new ClusterList();
dataList.clearIsAllocated(); //清除数据分配
//随机选择一个点,创建一个初始的簇
clusterList.add(createClusterWithRandomlySelectedDataPoint(dataList));
//如果簇的数量小于定义的簇的数量,则基于离质点最远的点,创建新的簇
while (clusterList.size() < k) {
clusterList.add(createClusterBasedFurthestData(dataList, clusterList));
}
//开始迭代
for (int iter = 0; iter < clusteringIterations; iter++) {
//基于质心和数据点的距离,分配没有分配的数据
assignUnallocatedDataPoints(dataList, clusterList);
//更新质心,取每个簇所有数据点的各维度的均值
clusterList.updateCentroids();
if (iter < clusteringIterations - 1) {
//簇中的数据清空,进行重新迭代分配
clusterList.clear();
}
}
return clusterList;
}
}通过看runKMeansClustering方法,便可以看到K-means这里使用的初始化方法,以及聚类的逻辑。
utils
Vector : 向量计算:
package com.utils;
import java.util.Arrays;
/**
* 向量计算
*/
public class Vector {
private final double[] elements;
/** 固定长度的向量构造 */
public Vector(int size) {
elements = new double[size];
}
/** 复制数组 */
public Vector(Vector vector) {
elements = Arrays.copyOf(vector.elements, vector.elements.length);
}
/** 向量的加和操作 */
public Vector add(Vector operAddition) {
Vector result = new Vector(size());
for (int i = 0; i < elements.length; i++) {
result.set(i, get(i) + operAddition.get(i));
}
return result;
}
/** 向量除以一个常数 */
public Vector divide(double divisor) {
Vector result = new Vector(size());
for (int i = 0; i < elements.length; i++) {
result.set(i, get(i) / divisor);
}
return result;
}
/** 获取向量的第i个值 */
public double get(int i) {
return elements[i];
}
/** 计算向量之间的欧几里得距离 */
public double getEuclideanDistance(Vector vector) {
double euclideanDistance = 0;
for (int i = 0; i < elements.length; i++) {
euclideanDistance += Math.pow(get(i) - vector.get(i), 2);;
}
return Math.sqrt(euclideanDistance);
}
/** 向量添加值 */
public void set(int i, double value) {
elements[i] = value;
}
/** 返回elements的长度 */
public int size() {
return elements.length;
}
@Override
public String toString() {
return Arrays.toString(elements);
}
}OutPutFile :结果输出操作:
package com.utils;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import com.clustering.Cluster;
import com.clustering.ClusterList;
import com.clustering.Data;
public class OutPutFile {
/** write the results to a file */
public static void outputCluster(String strDir,ClusterList clusterList) throws IOException{
BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream( new File(strDir)),"gbk"));
int i = 0;
for (Cluster cluster : clusterList) {
writer.write("Cluster" + i + ":" + cluster.getCentroid() + "\n");
for (Data doc: cluster.getDatas()) {
writer.write("\t" + doc.getTitle() + "\n");
}
i++;
}
writer.close();
}
public static void outputClusterAndContent(String strDir,ClusterList clusterList) throws IOException{
BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream( new File(strDir)),"gbk"));
int i = 0;
for (Cluster cluster : clusterList) {
writer.write("Cluster" + i + ":" + cluster.getCentroid() + "\n");
for (Data doc: cluster.getDatas()) {
writer.write("\t" + doc.getTitle() + "\t" + doc.getVector() + "\n");
}
i++;
}
writer.close();
}
}
运行结果
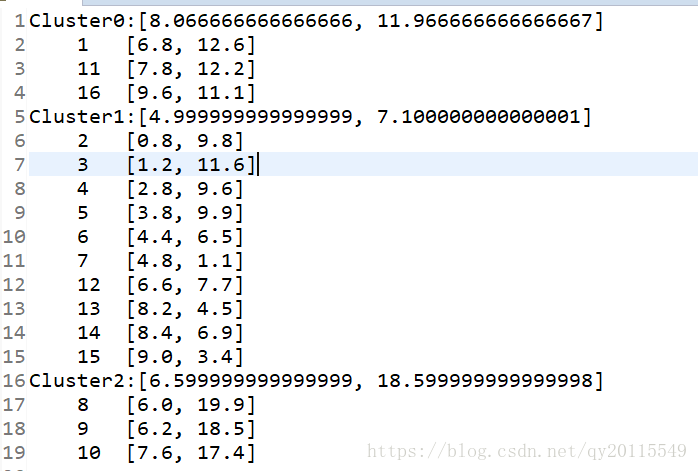
参考内容:
1.Arthur D, Vassilvitskii S. k-means++: The advantages of careful seeding[C]//Proceedings of the eighteenth annual ACM-SIAM symposium on Discrete algorithms. Society for Industrial and Applied Mathematics, 2007: 1027-1035.