分布式架构中redis缓存穿透系统解决方案
理解概念
先了解决缓存的应用场景
Redis提供持久化的功能,保证数据的恢复机制。
Redis提供成熟的主备同步,故障切换的功能,从而保证了高可用性。
Redis的集群策略实现了负载均衡。

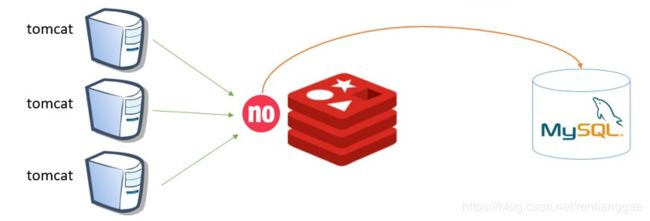
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中所以会查询数据库,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。
缓存击穿是指缓存中某个热点key在某个时间点过期的时候,恰好在这个时间点对这个Key有大量的并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
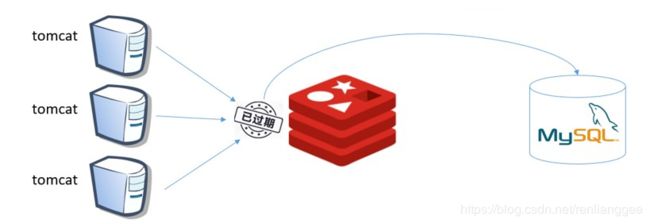
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到DB,DB瞬时压力过重雪崩。

代码演示问题
使用代码演示缓存穿透的问题,代码如下:
package cn.tx.service.impl;
import cn.tx.dao.UserDao;
import cn.tx.domain.Result;
import cn.tx.domain.User;
import cn.tx.service.UserService;
import cn.tx.utils.RedisUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Service;
import java.util.List;
/**
* 腾讯课程搜索 拓薪教育
* 樱木老师
*/
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Autowired
private RedisUtil redisUtil;
/**
* 通过主键查询用户
* @param id
* @return
*/
@Override
public Result selectUserById(Integer id) {
// 先从缓存中查询
Object object = redisUtil.getCacheObject(String.valueOf(id));
// 如果能查询到,直接返回
if(object != null){
return new Result("ok",200,object);
}
// 缓存中查询不到,查询数据库
User user = userDao.selectUserById(id);
// 传入到缓存中
if(user != null){
// 存入到redis缓存中,5秒钟过期时间
redisUtil.setCacheObject(String.valueOf(id),user,5);
return new Result("ok",200,user);
}
// 查询无果
return new Result("查询无果",500,new NullValueResult());
}
}
布隆过滤器原理
布隆过滤器是一个 bit 向量或者说 bit 数组,长这样。

如果我们要映射一个值到布隆过滤器中,我们需要使用多个不同的哈希函数生成多个哈希值,并对每个生成的哈希值指向的 bit 位置 1,例如针对值 “baidu” 和三个不同的哈希函数分别生成了哈希值 1、4、7,则上图转变为:
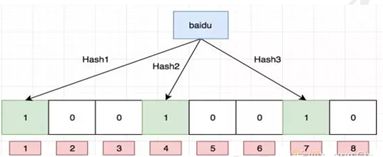
Ok,我们现在再存一个值 “tencent”,如果哈希函数返回 3、4、8 的话,图继续变为:

值得注意的是,4 这个 bit 位由于两个值的哈希函数都返回了这个 bit 位,因此它被覆盖了。现在我们如果想查询 “dianping” 这个值是否存在,哈希函数返回了 1、5、8三个值,结果我们发现 5 这个 bit 位上的值为 0,说明没有任何一个值映射到这个 bit 位上,因此我们可以很确定地说 “dianping” 这个值不存在。而当我们需要查询 “baidu” 这个值是否存在的话,那么哈希函数必然会返回 1、4、7,然后我们检查发现这三个 bit 位上的值均为 1,那么我们可以说 “baidu” 存在了么?答案是不可以,只能是 “baidu” 这个值可能存在。
这是为什么呢?答案跟简单,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值 “taobao” 即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断 “taobao” 这个值存在。
过小的布隆过滤器很快所有的 bit 位均为 1,那么查询任何值都会返回“可能存在”,起不到过滤的目的了。布隆过滤器的长度会直接影响误报率,布隆过滤器越长其误报率越小。
另外,哈希函数的个数也需要权衡,个数越多则布隆过滤器 bit 位置位 1 的速度越快,且布隆过滤器的效率越低;但是如果太少的话,那我们的误报率会变高。
演示布隆过滤器
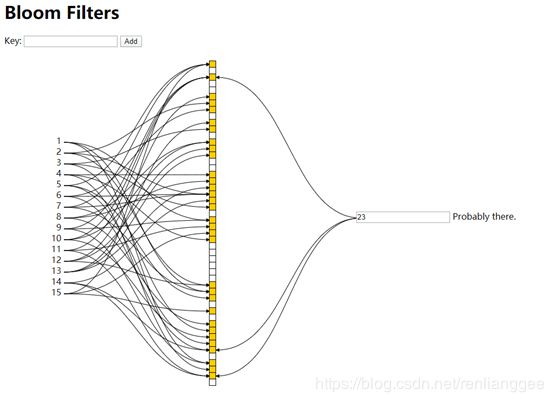
常见的应用场景,利用布隆过滤器减少磁盘 IO 或者网络请求,因为一旦一个值必定不存在的话,我们可以不用进行后续昂贵的查询请求。
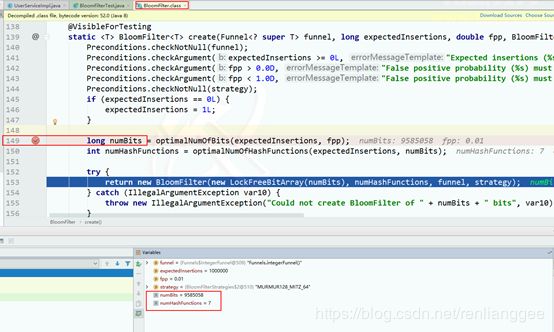
设置的容错率越小,布隆过滤器的数组越大,hash函数越多。可以根据源代码查看。
用布隆过滤器解决缓存穿透的问题
具体的代码如下:
package cn.tx.service.impl;
import cn.tx.dao.UserDao;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.List;
/**
* 腾讯课程搜索 拓薪教育
* 樱木老师
*/
@Service
public class BloomFilterUtil {
@Autowired
private UserDao userDao;
// 定义预存数据的个数
private static int size = 1000000;
// 初始化布隆过滤器对象 0.01表示容错率
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size,0.01);
/**
* 初始化的方法
*/
@PostConstruct
public void init(){
// 查询数据库中所有的id值
List<Integer> list = userDao.selectAllIds();
for (Integer id : list) {
// 存入到布隆过滤器中
bloomFilter.put(id);
}
}
/**
* 布隆过滤器,判断id是否可能存在
* @param id
* @return
*/
public boolean mightContain(Integer id){
return bloomFilter.mightContain(id);
}
}
修改业务层的代码
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
@Autowired
private RedisUtil redisUtil;
@Autowired
private BloomFilterUtil bloomFilterUtil;
/**
* 采用布隆过滤器的方式来解决缓存穿透
* @param id
* @return
*/
@Override
public Result selectUserById(Integer id) {
// 先从缓存中查询
Object object = redisUtil.getCacheObject(String.valueOf(id));
// 如果能查询到,直接返回
if(object != null){
// 返回正常的数据
return new Result("ok",200,object);
}else{
// 去布隆过滤器中判断该id是否存在
boolean b = bloomFilterUtil.mightContain(id);
if(!b){
return new Result("查询无果",500,new NullValueResult("无数据"));
}
}
// 缓存中查询不到,查询数据库
User user = userDao.selectUserById(id);
// 传入到缓存中
if(user != null){
// 存入到redis缓存中,5秒钟过期时间
redisUtil.setCacheObject(String.valueOf(id),user,5);
return new Result("ok",200,user);
}
// 查询无果
return new Result("查询无果",500,new NullValueResult("无数据"));
}
}
学习更多架构免费课程请关注:java架构师免费课程
每晚20:00直播分享高级java架构技术
扫描加入QQ交流群264572737

进入群内免费领取海量java架构面试题