MySQL的那些事儿
1、MySQL如何将select结果保存到一个数据库表中:
相关参考:MySql将查询结果插入到另外一张表
2、MySQL长事务导致的Table Metadata Lock:
现象:MySQL数据库表添加字段时卡死,报错为:Waiting for table metadata lock,此时数据库表无法删除和修改,只能read,这是因为MySQL出现了死锁(?)
解决方法:先执行 show processlist,查看当前那些id出现了上述错误,如下图:
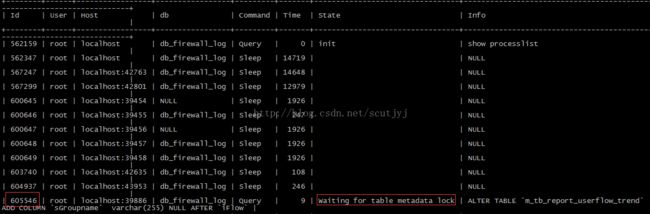
然后执行kill id,对于上图就是kill 605546;
接着执行select * from information_schema.innodb_trx\G,结果如下图:
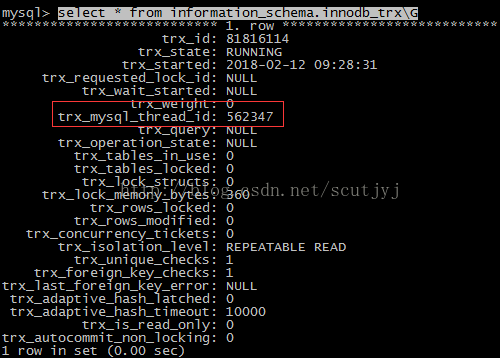
然后执行kill 562347;最后把数据库表删除即可(这一步不做,只要执行kill 562347就差不多了)
3、 MySQL提示Please DISCARD the tablespace before IMPORT:
这个是表删除不干净导致的,目录删除了 但是物理文件还在,可以使用show global variables like "%datadir%";查看mysql数据库文件保存的位置,然后删除 :表名.frm 表名.ibd;这两个文件 即可
4、MySQL报“open too many files”错误的解决方法:
相关参考:How to permanently raise ulimit 'open files' and MySQL 'open_files_limit'
对于centOS,下面测试可行:
Hi, I have a CentOS 7 / MySQL 5.6 server and I tried all suggestions i found online, and still cat /proc/xxxx/limits showed 1024 max open files. (where X is the pid from the mysqld process. The missing thing was a .configuration setting in the mysql service.
I did the following:
Go to services directory:
cd /etc/systemd/system/
Remove the symlink:
rm mysql.service
Copy service to services directory (so it won't be overwritten by any upgrade):
cp /usr/lib/systemd/system/mysqld.service mysqld.service
In the Service section add LimitNOFILE=1024000.
In my case it's now:
[Service]
User=mysql
Group=mysql
LimitNOFILE=1024000
Restart.
limits are now:
[root@dev system]# cat /proc/5981/limits
Max open files 1024000 1024000 files
5、MySQL 如何查看表的存储引擎:
show create table +表名;
6、如何插入包含datetime类型字段的记录:
相关参考:MySQL: Insert datetime into other datetime field
According to MySQL documentation, you should be able to just enclose that datetime string in single quotes, ('YYYY-MM-DD HH:MM:SS') and it should work.
7、MySQL数据导入导出指令:
a、导出.sql文件:
(1)mysqldump,
如:mysqldump -u {username} -p --databases {db_name} -t --tables {table_name} --where='{query_condition}'> test.sql
详细用法请参考MySQL mysqldump数据导出详解
mysqldump指令各个参数的说明:mysqldump数据导出详解(超详细)
(2)
SELECT * INTO OUTFILE 'data_path.sql' from table where id<100000b、导入.sql文件:source
如:mysql客户端登录后,先选择数据库:use {db_name};source /path_to_sql/test.sql
8、MySQL可以使用limit关键字实现分页查询:
详细参考:详解MySQL的limit用法和分页查询语句的性能分析
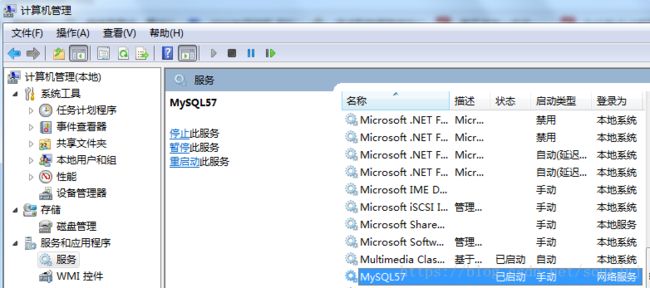
9、win7下启用MySQL服务:
当按照官网的教程,使用指令:MySQL安装路径\bin\mysqld或者使用网上教程:切换到bin路径下执行net start mysql均无法启动MySQL服务时,可以在win7的服务中手动启动MySQL服务,如下图:
10、在Ubuntu 16.04下,当MySQL被动更新了版本时(如使用apt-get install安装Plibmysqlclient-dev库【Python的mysql-python包依赖该库】),比如从5.7版本更新为8.0版本,此时连上数据库(使用root账户)后执行指令,如show databases,会出现如下错误:
![]()
解决方法:
执行以下指令:mysql_upgrade -u root -p ,输入root账户的密码即可。
11、数据库脏读、幻读、不可重复读问题:
相关参考:MySQL的四种事务隔离级别
另外的参考:数据库事务隔离级别-- 脏读、幻读、不可重复读(清晰解释)
12、MySQL集群:
先挖坑,再补充。
13、MySQL存储引擎相关:
相关参考:MySQL存储引擎中的MyISAM和InnoDB区别详解
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。
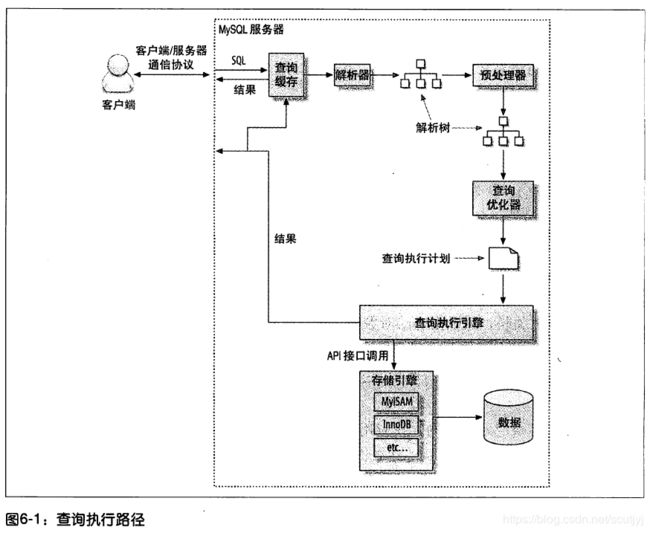
14、MySQL查询执行过程:
15、MySQL索引:
(1)为什么需要索引?
根本原因是避免进行全表扫描(或者说减少需要扫描的行数),可以类比二分查找,可以快速定位所需数据,提高查询速度。
(2)MySQL有哪些索引?
a、B+Tree索引(类似于B-Tree索引),每一个叶子节点包含指向下一个叶子节点的指针;
b、哈希索引,基于散列表(Hash table)实现,存储引擎对所有的索引列计算一个哈希值,目前只有Memory引擎显示支持哈希索引;
c、空间索引(spatial index),MyISAM引擎支持,用于存储地理数据;
d、全文索引(Full Text Index),MyISAM引擎支持;
(3)索引的缺点?
当数据量很大的时候,索引可能会引起性能下降,而且存储索引也会占用一定存储空间;
16、MySQL基本操作:
(1)已有数据库表增加字段:
ALTER TABLE `user`
ADD COLUMN `username` varchar(20) NULL DEFAULT '' COMMENT '用户名' AFTER `phone`,
ADD COLUMN `create_at` datetime NULL COMMENT '创建时间' AFTER `username`;
COLUMN 可以省略,AFTER表示添加在某个字段后面,没有则添加在最后面
(2)一条update语句更新多条记录的一个字段值:执行一条sql语句update多条记录实现思路
(3)insert多条记录条目时遇到unique key重复时:
使用insert ignore或者insert on duplicate key update:“INSERT IGNORE” vs “INSERT … ON DUPLICATE KEY UPDATE”
(4)join的用法:MySQL的JOIN(一):用法
(5)varchar和text的区别:Difference between VARCHAR and TEXT in mysql [closed]
(6)删除和添加字段:MySQL添加字段和删除字段
(7)获取字段的排序值:MySQL - Get row number on select
(8)offset和limit的用法:Mysql limit offset用法举例
例如:select * from student limit 9,4,表示从student表的10行开始取4行,即返回表中的10-13行
(9)使用联表join进行update:How to do 3 table JOIN in UPDATE query?
例如:
UPDATE TABLE_A a
JOIN TABLE_B b ON a.join_col = b.join_col AND a.column_a = b.column_b
JOIN TABLE_C c ON [condition]
SET a.column_c = a.column_c + 1(10)字符串拼接函数CONCAT:
使用方法:CONCAT(str1,str2,…)
返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
(11)GROUP_CONCAT函数:
把查询结果的行用逗号作为分隔符拼接起来;
(12)MySQL字符串操作函数:
常用的有replace(string, src_part, dst_part), length(str), locate(substr, str), substring(str, pos), left(string, length), right(string, length)等......
demo:
update `article` set content = concat(replace(content, substring(content, locate('haha', content)-11), ''), '"') where status = 1 and name = 'hehe' and content like '%haha%';相关参考: MySQL字符串函数:字符串截取
(13) 修改字段定义:
ALTER TABLE table_name MODIFY COLUMN new-column-definition;当需要修改字段名称时使用change;当需要修改字段类型时使用modify
相关参考:mysql中alter语句中change和modify的区别
(14)having的用法:mysql having的用法
17、MySQL按照时间查询相关记录:
(1)如何查询今天的数据:
select * from 表名 where to_days(时间字段名) = to_days(now());(2)如何查询最近7天的数据:
SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名);具体可参考:MySQL中, 如何查询某一天, 某一月, 某一年的数据
18、MySQL查询性能分析:
(1)首先要explain一下查询语句,explain结果各个字段的含义可以参考:【踩坑】MySQL时间索引失效
(2)可以结合《高性能MySQL》中查询优化的内容加深理解。
(3)索引命中相关:注意不要对索引字段使用not in,!=,否则会导致索引失效,进行全表扫描,这个可以结合索引的原理来理解。
19、MySQL的json类型相关:
相关参考:MySQL 5.7 JSON 实现简介
最好还是参考MySQL官方文档。
20、MySQL导入csv文件:
(1)mysql登录的时候要加上--local-infile
(2)登录后执行:
load data local infile 'csv_path/your_csv_file.csv' into table table_name
character set UTF8
fields terminated by ',' enclosed by '"' lines terminated by '\n' ignore 1 rows (field_1, field_2, ...);
注:使用ignore 1 rows是因为csv第一行是字段名
参数说明:
into outfile ‘导出的目录和文件名’
指定导出的目录和文件名
fields terminated by ‘字段间分隔符’
定义字段间的分隔符
optionally enclosed by ‘字段包围符’
定义包围字段的字符(数值型字段无效)
lines terminated by ‘行间分隔符’
定义每行的分隔符
(3)导入遇到的权限问题,secure_file_priv,具体参考:How should I tackle --secure-file-priv in MySQL?,mac__MySQL导出数据遇到secure-file-priv问题的解决方法
相关参考:How to import CSV file to MySQL table,MySQL import csv file ERROR 13 (HY000): Can't get stat of /path/file.csv (Errcode: 2),MYSQL import data from csv using LOAD DATA INFILE
21、mysql导出csv文件:
select 'order_id','product_name','qty'
union all
SELECT order_id,product_name,qty
FROM orders
WHERE foo = 'bar'
INTO OUTFILE '/var/lib/mysql-files/orders.csv'
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
LINES TERMINATED BY '\n';具体参考:How to output MySQL query results in CSV format?
22、MySQL需要支持emoji表情:
解决方案:数据库字符集需要设置为utf8mb4,同时客户端连接(代码中)也要charset为utf8mb4
原因分析:utf8一个字符最多3字节,而utf8mb4则扩展到一个字符最多能有4字节
具体参考: MySQL修改字符集为utf8mb4以支持 emoji 表情符号
23、MySQL的timestamp详解:
生产环境中部署着各种版本的MySQL,包括MySQL 5.5/5.6/5.7三个大版本和N个小版本,由于MySQL在向上兼容性较差,导致相同SQL在不同版本上表现各异,下面从几个方面来详细介绍时间戳数据类型。
时间戳数据存取
在MySQL上述三个大版本中,默认时间戳(Timestamp)类型的取值范围为'1970-01-01 00:00:01' UTC 至'2038-01-19 03:14:07' UTC,数据精确到秒级别,该取值范围包含约22亿个数值,因此在MySQL内部使用4个字节INT类型来存放时间戳数据:
1、在存储时间戳数据时,先将本地时区时间转换为UTC时区时间,再将UTC时区时间转换为INT格式的毫秒值(使用UNIX_TIMESTAMP函数),然后存放到数据库中。
2、在读取时间戳数据时,先将INT格式的毫秒值转换为UTC时区时间(使用FROM_UNIXTIME函数),然后再转换为本地时区时间,最后返回给客户端。
在MySQL 5.6.4及之后版本,可以将时间戳类型数据最高精确微秒(百万分之一秒),数据类型定义为timestamp(N),N取值范围为0-6,默认为0,如需要精确到毫秒则设置为Timestamp(3),如需要精确到微秒则设置为timestamp(6),数据精度提高的代价是其内部存储空间的变大,但仍未改变时间戳类型的最小和最大取值范围。
时间戳字段定义
时间戳字段定义主要影响两类操作:
1、插入记录时,时间戳字段包含DEFAULT CURRENT_TIMESTAMP,如插入记录时未指定具体时间数据则将该时间戳字段值设置为当前时间
2、更新记录时,时间戳字段包含ON UPDATE CURRENT_TIMESTAMP,如更新记录时未指定具体时间数据则将该时间戳字段值设置为当前时间
PS1:CURRENT_TIMESTAMP表示使用CURRENT_TIMESTAMP()函数来获取当前时间,类似于NOW()函数
根据上面两类操作,时间戳列可以有四张组合定义,其含义分别为:
1、当字段定义为timestamp,表示该字段在插入和更新时都不会自动设置为当前时间。
2、当字段定义为timestamp DEFAULT CURRENT_TIMESTAMP,表示该字段仅在插入且未指定值时被赋予当前时间,再更新时且未指定值时不做修改。
3、当字段定义为timestamp ON UPDATE CURRENT_TIMESTAMP,表示该字段在插入且未指定值时被赋值为"0000-00-00 00:00:00",在更新且未指定值时更新为当前时间。
4、当字段定义为timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,表示该字段在插入或更新时未指定值,则被赋值为当前时间。
PS1:在MySQL中执行的建表语句和最终表创建语句会存在差异,建议使用SHOW CREATE TABLE TB_XXX获取已创建表的建表语句。
时间戳类型使用建议
1、在只关心数据最后更新时间的情况下,建议将时间戳列定义为TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP;
2、在关心创建时间和更新时间的情况下,建议将更新时间设置为时间戳字段,将创建时间定义为DAETIME 或 TIMESTAMP DEFAULT '0000-00-00 00:00:00',并在插入记录时显式指定创建时间;
3、建议在表中只定义单个时间戳列,并显式定义DEFAULT 和 ON UPDATE属性;
4、虽然在MySQL中可以对时间戳字段赋值或更新,但建议仅在必要的情况下对时间戳列进行显式插入和更新;
5、建议将time_zone参数设置为system外的值,如中国地区服务器设置为'+8:00';
6、建议将MySQL线下测试版本和线上生产版本保持一致。
具体参考:细说MySQL的时间戳(Timestamp)类型,mysql之TIMESTAMP(时间戳)用法详解
24、mysql设置group_concat长度:
默认是1024字节,设置方法如下:
SET GLOBAL group_concat_max_len=102400;
SET SESSION group_concat_max_len=102400;可参考:MYSQL中group_concat有长度限制!默认1024
25、MySQL用户管理:
(1)创建用户:
CREATE USER 'username'@'host' IDENTIFIED BY 'password';(2)数据库表访问授权:
GRANT privileges ON databasename.tablename TO 'username'@'host';(3)撤销访问权限:
REVOKE privilege ON databasename.tablename FROM 'username'@'host';(4)更改用户密码:
SET PASSWORD FOR 'username'@'host' = PASSWORD('newpassword');(5)删除用户:
DROP USER 'username'@'host';相关参考:MySQL创建用户与授权
26、MySQL的json相关函数:
请参考:MySQL JSON数据类型操作
27、MySQL字符串处理函数:
时间转字符串:date_format(now(), '%Y-%m-%d'); 字符串转时间:str_to_date('2016-01-02', '%Y-%m-%d %H');
相关参考:MySQL日期 字符串 时间戳互转
28、Incorrect string value: '\xF0\x9F\x8E\xB6\xF0\x9F…' MySQL客户端sql语句emoji问题:
解决方法:SET NAMES utf8mb4;
相关参考:Incorrect string value: '\xF0\x9F\x8E\xB6\xF0\x9F…' MySQL
29、MySQL的IFNULL, NULLIF,ISNULL:
请参考:MySql 里的IFNULL、NULLIF和ISNULL用法
30、MySQL client的SQL语句包含unicode字符时(如\u00e4),在查询时like后面的字符串,应使用4个反斜杠,即应该用'\\\\u00e4', 而其他则用2个反斜杠,即'\\u00e4',例如:
select name from user where name like '%\\\\u00e4%';
update user set name = '\\u00e4hehe' where name like '%\\\\u00e4%';相关参考:MySQL: Querying for unicode entities
31、索引过长问题:
请参考:索引长度过长 ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes
32. MySQL join相关:
(1)一般用法是: select a.col1, ..., a.colm, b.col1, ..., b.coln from a join b on a.id = b.id where a.num > 1000,该sql先根据join表的条件(a.id = b.id)和join类型(inner join)得到联表后的中间表,该过程又叫匹配阶段,然后根据where对中间表进行filter,得到最后返回的查询结果
(2)join的实现原理
join的实现是采用Nested Loop Join算法,就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果有多个join,则将前面的结果集作为循环数据,再一次作为循环条件到后一个表中查询数据
(3)join的类型有inner join(也即join,inner为默认缺省), left join(也即left outer join), right join
(4)不同的类型主要区别是联表时的base不同,导致中间表的大小不一样: 假设tb_a有M行,tb_b有N行, 对于tb_a left join tb_b on tb_a.id = tb_b.id,则联表得到的大表的记录行数范围为[M, M * N],而如果改为right join, 联表得到的大表的记录行数范围为[N, N * M], 而如果为inner join,则联表得到的大表的记录行数范围为[0, min{M, N}];这也是一般小表join大表做法的来由
(5)join语句的优化原则
a.用小结果集驱动大结果集,将筛选结果小的表首先连接,再去连接结果集比较大的表,尽量减少join语句中的Nested Loop的循环总次数;
b.优先优化Nested Loop的内层循环(也就是最外层的Join连接),因为内层循环是循环中执行次数最多的,每次循环提升很小的性能都能在整个循环中提升很大的性能;
c.对被驱动表的join字段上建立索引;
d.当被驱动表的join字段上无法建立索引的时候,设置足够的Join Buffer Size
(6)相关参考:MySQL实战技巧-1:Join的使用技巧和优化;Mysql Join语法以及性能优化
33.如何确定一个表有多少行记录?(geek)
请使用explain: explain select count(1) from test_tb; 否则会全表扫描