矩阵元安全多方详细介绍
第一章 MPC&JUGO
1.概述
大数据时代,海量数据的交叉计算可以为科研、医疗、金融等提供更好支持。许多企业或组织出于信息安全或利益的考虑,内部数据是不对外开放的。形成一个个数据孤岛,数据的价值无法体现或变现。安全多方计算(MPC)可以很好解决这一难题。保证各方数据安全的同时,又得到预期计算的结果。
为了让数据安全地碰撞出更多价值,打破数据在行业、企业间流动的壁垒,矩阵元推出了JUGO安全多方计算平台。JUGO提供安全多方计算底层平台,并集成了通用MPC算法的SDK。同时提供编写高级语言Frutta的IDE,方便用户将Frutta语言编写的程序转换成电路。用户可以在平台上编写MPC算法并发布,也可以发起计算任务,邀请第三方进行安全多方计算或可以申请参与他人发起的计算任务。
用户将计算节点部署到本地,可以选择JUGO开放服务平台作为代理(也可以是第三方), 节点之间通过代理进行加密通讯,所有节点不保留任何数据。整个计算过程没有任何明文或原始数据传播或存在,最后计算结果发送给事前约定的接收方。
JUGO开放服务平台是一个数据加工厂,也是一个算法和数据集市。在保护数据安全的前提下帮助卖方用户数据增值、变现,帮助买方用户寻找所需的数据和服务。
为了数据的流动是矩阵元的口号和愿景,流动的数据才更有价值。
JUGO特性:
- 支持semi-honest通用两方算法:GC+OT。
- 支持Frutta编写的IDE,提供MPC算法的SDK,用户使用IDE和SDK进行开发。
- 支持加法(addition),比较(comparison)多方算法。
- 后续支持通用多方算法和硬件加速
2.MPC名词解释
| 名称 | 全称 | 中文名称 | 说明 |
|---|---|---|---|
| MPC | Secure Multi-Party Computation | 安全多方计算 | 一种保护数据安全隐私的多方计算算法。 |
| GC | Garbled Circuit | 加密电路 | 一种通过加密处理电路的方式。 |
| OT: | Oblivious Transfer | 不经意传输 | 一种安全的选择、传输协议。 |
一、MPC介绍
1.安全多方计算的价值
MPC是密码学的一个重要分支,旨在解决一组互不信任的参与方之间保护隐私的协同计算问题,为数据需求方提供不泄露原始数据前提下的多方协同计算能力。
在目前个人数据毫无隐私的环境下,对数据进行确权并实现数据价值显得尤为重要。MPC就是实现此目的的计算协议,在整个计算协议执行过程中,用户对个人数据始终拥有控制权,只有计算逻辑是公开的。计算参与方只需参与计算协议,无需依赖第三方就能完成数据计算,并且参与各方拿到计算结果后也无法推断出原始数据。
2.安全多方计算的来源
安全多方计算(MPC:Secure Muti-Party Computation)研究由图灵奖获得者、中国科学院院士姚期智教授在1982年提出,姚教授以著名的百万富翁问题来说明安全多方计算。百万富翁问题指的是,在没有可信第三方的前提下,两个百万富翁如何不泄露自己的真实财产状况来比较谁更有钱。通过研究此问题,形象地说明了安全多方计算面临的挑战和问题解决思路,经Oded Goldreich、Shaft Goldwasser等学者的众多原始创新工作,安全多方计算逐渐发展成为密码学的一个重要分支。
3.问题抽象
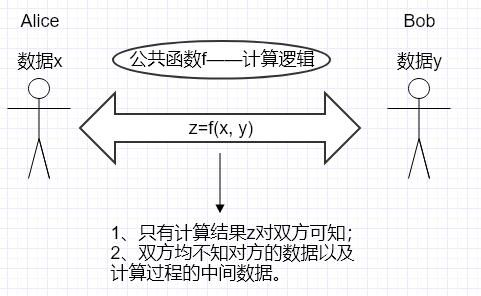
安全多方计算可以抽象的理解为:两方分别拥有各自的私有数据,在不泄漏各自私有数据的情况下,能够计算出关于公共函数 的结果。整个计算完成时,只有计算结果对双方可知,且双方均不知对方的数据以及计算过程的中间数据。
4.什么是安全多方计算?
多个持有各自私有数据的参与方,共同执行一个计算逻辑计算逻辑(如,求最大值计算),并获得计算结果。但过程中,参与的每一方均不会泄漏各自数据的计算,被称之为MPC计算。
举个例子,Bob和Alice想弄清谁的薪资更高,但因为签署了保密协议而不能透露具体薪资。如果Bob和Alice分别将各自的薪资告诉离职员工Anne,这时Anne就能知道谁的薪资更高,并告诉Bob和Alice。这种方式就是需保证中间人Anne完全可信。
而通过MPC则可以设计一个协议,在这个协议中,算法取代中间人的角色,Alice和Bob的薪资以及比较的逻辑均交由算法处理,参与方只需执行计算协议,而不用依赖于一个完全可信的第三方。
安全多方计算所要确保的基本性质就是:在协议执行期间发送的消息中不能推断出各方持有的私有数据信息,关于私有数据唯一可以推断的信息是仅仅能从输出结果得到的信息。
4.1.什么是算法
算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。
如果一个算法有缺陷,或不适合于某个问题,执行这个算法将不会解决这个问题。不同的算法可能用不同的时间、空间或效率来完成同样的任务。一个算法的优劣可以用空间复杂度与时间复杂度来衡量。
算法具有以下五个重要特征:
- 有穷性:算法的有穷性是指算法必须能在执行有限个步骤之后终止;
- 确切性:算法的每一步骤必须有确切的定义;
- 输入项:一个算法有0个或多个输入,以刻画运算对象的初始情况,所谓0个输入是指算法本身定出了初始条件;
- 输出项:一个算法有一个或多个输出,以反映对输入数据加工后的结果。没有输出的算法是毫无意义的;
- 可行性:算法中执行的任何计算步骤都是可以被分解为基本的可执行的操作步,即每个计算步都可以在有限时间内完成(也称之为有效性)。
注意:文档中提到的“算法”,特指MPC底层算法;“计算逻辑”特指为执行具体运算而编写的算法,运行在MPC底层算法之上。
4.2.MPC问题分类
-
由算法适用性来看,MPC既适用于特定的算法,如加法、乘法、AES,集合交集等;也适用于所有可表示成计算过程的通用算法。
-
根据计算参与方个数不同,可分为只有两个参与方的2PC和多个参与方(≥3)的通用MPC。
-
安全两方计算所使用的协议为Garbled Circuit(GC)+Oblivious Transfer(OT);而安全多方计算所使用的协议为同态加密+秘密分享+OT。
-
在安全多方计算中,安全挑战模型包括半诚实敌手模型和恶意敌手模型。市场大部分场景满足半诚实敌手模型,也是JUGO技术产品所考虑的敌手模型。
-
半诚实敌手模型:计算方存在获取其他计算方原始数据的需求,但仍按照计算协议执行。半诚实关系即参与方之间有一定的信任关系,适合机构之间的数据计算;
-
恶意敌手模型:参与方根本就不按照计算协议执行计算过程。参与方可采用任何(恶意)方式与对方通信,且没有任何信任关系。结果可能是协议执行不成功,双方得不到任何数据;或者协议执行成功,双方仅知道计算结果。更多适用于个人之间、或者个人与机构之间的数据计算。
5.MPC算法基本原理(2PC半诚实模型)
下面介绍安全两方计算的半诚实模型下的MPC算法原理:
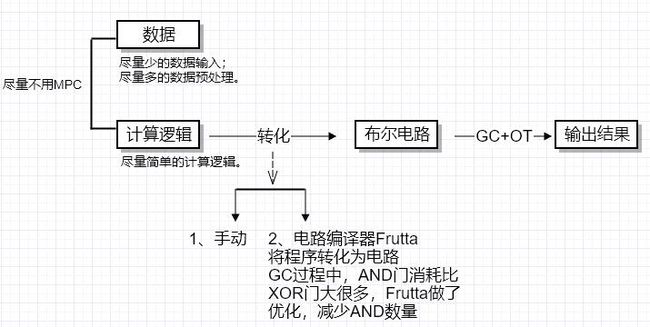
5.1.MPC算法执行过程
- 先对输入数据做预处理。
遵循原则:1、尽量少的数据输入;2、尽量多的数据预处理
——数据量太大时会大幅降低算法执行效率。
- 计算逻辑转化为布尔电路。
遵循原则:尽量简单的计算逻辑
——由于MPC是计算密集型和通信密集型算法,若计算逻辑很复杂,会对执行效率产生很大影响。
转化方式:手动/电路编译器Frutta
- 将输入的布尔电路做GC和OT算法(详细在下面叙述),得到输出结果。
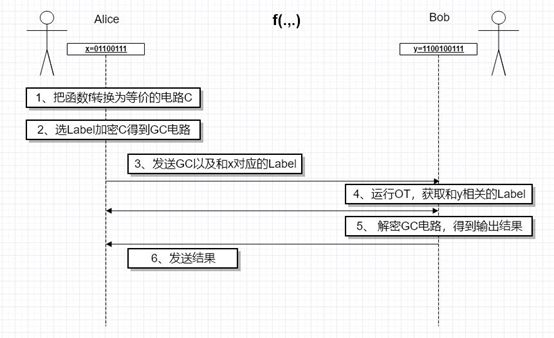
5.2.GC+OT的两方计算基本框架
GC+ OT是在两方semi-honest模型下的通用型算法,即可以支持任意计算逻辑的安全两方计算。
总体框架如下图:

6.小结
安全多方计算是一种在不泄漏原始数据的情况下,对数据进行的计算。上述内容首先介绍了MPC的价值及来源,然后详述了两方安全计算的技术实现原理,主要包括GC和OT算法,并对一些技术基础知识做了简要概述。
二、JUGO与MPC
1.JUGO定位
针对企业级用户,基于MPC的安全数据交易平台。通过在本地部署MPC节点,进行数据协同计算。
2.JUGO特性
-
支持semi-honest通用两方算法:GC+OT。
-
支持Frutta编写的IDE,提供MPC算法的SDK,用户使用IDE和SDK进行开发。
-
支持加法(addition),比较(compare)等多种算法。
-
以浏览件插件的形式提供MPC个人体验。
-
后续支持通用多方算法和硬件加速。
3.JUGO架构
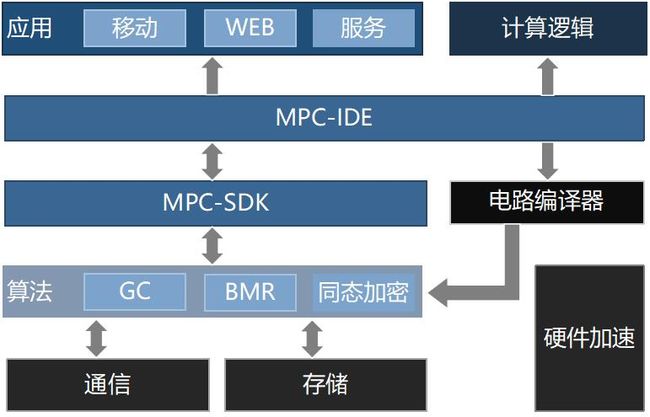
针对计算逻辑提供者,MPC-IDE实现计算逻辑的编写,并通过集成的电路编译器转化为电路文件;作为数据执行方,矩阵元提供的MPC-SDK直接为计算逻辑提供者服务;并且矩阵元对MPC-SDK内部算法实现GPU、FPGA等硬件加速,使协同计算过程更快地完成。
三、MPC应用场景
1.MPC适用场景
1.1.数据安全查询
政府部门的系统中往往储存了大量的公民和企业经营数据,很多商业机构需要查询信息用作商业用途,但政府不希望数据被泄露或被拷贝走,同时,有些场景下商业机构也不希望政府知道其查询条件。利用安全多方计算技术,可以实现数据的安全查询。
数据安全查询的解决方案还可应用在商业竞争、数据合作等众多领域中。
1.2.联合数据分析
跨机构的合作以及跨国公司的经营运作等经常需要从多个数据源获取数据,拼凑成全量数据再进行分析,已有的数据分析算法可能导致隐私暴露和数据所有权的转移,应用安全多方计算技术可以使原始数据在无需归集与共享的情况下实现计算,保护目标数据持有方的隐私及资产安全。
2.MPC应用范围
不论是在全球范围内流动的资源、货物、资本、技术、人、数据或是观念,还是由于各种现实世界摩擦造成的冲突、监管和制约等等,都在影响着各方对于经济、文化、教育、医疗、公共管理等各行各业信息的判断和使用。
数据的流动和协同分析在各行业都有着极其重要的价值,也推生了众多的应用需求:
1、金融业
金融本身就是一个经营风险的行业,风控与征信是金融业管理风险的重要手段。传统数据分析模式面临的难题是,数据采集范围局限、平台上传数据积极性低、更新不及时、接入门槛高等问题。而MPC征信模式可支持的数据本地采集方式,弥补了传统征信数据老旧、风险评估状况滞后的缺陷,更能支持数据类型多样化的协同计算,将数据分析范围从金融信贷数据,扩展至医疗、保险、交通等行业的征信评价体系中,获得更为广泛的社会信用评价画像。
2、制造业
制造业的数字化改造已经为各类制造业企业带来了更精准、更先进的工艺,以及更优良的产品。而对行业整体供给数据、生产频度、维修情况等的综合分析,能为行业降本增效提供有力数据支撑,减少产能过剩之痛。制造业全球分布的特性,以及相对金融业较低的信息技术运用程度,使得数据的流通和共享存在一定阻力。MPC技术在制造业的运用,可以使数据互操作脱离国家边境线的限制,为全球制造供应链优化提供保障;通过对行业整体数据或市场需求情况的深度挖掘和多维护剖析,可以准确地配置全球生产体系,更加灵活地安排各地市场产品的投放,随时把握产业动向。
3、医疗业
医疗数据的敏感性使得医疗机构、保险、药企、医疗设备供应商之间难以实现低成本、高效的医疗信息数据交换和共享,进而导致行业内大量的数据资源没有得到有效使用和深度分析。MPC技术在医疗行业的应用,可以在相对封闭的医疗数据参与方间,建立起安全可信的数据交换网络,实现医疗数据价值的最大效用。
第二章 简易教程
1.编程语言&开发环境
1.1.计算逻辑编程语言
Frutta语言
1.2.IDE开发环境
操作系统windows(后续支持linux),chrome浏览器(需先安装Frutta谷歌浏览器插件)
1.3.MPC应用部署
环境搭建(要求linux系统)
安装nginx
安装JDK,配置JDK环境变量
2.安装插件
使用JUGO-IDE之前,需要先安装Frutta谷歌浏览器插件。安装后可在JUGO-IDE中使用Frutta语言编写算法。
安装步骤:
第一步,请点击下载Frutta谷歌浏览器插件的安装包,并在本地解压。
第二步,在Chrome浏览器地址栏输入chrome://extensions/,启用开发者模式,然后点击按钮“加载已解压的扩展程序”,选择插件所在的文件夹即可。
注意:由于该插件暂未上传Google插件商店,所以只能以开发者模式运行。打开chrome://extensions/,如下图示开启开发者模式。由于是以开发者模式运行该插件的,Chrome浏览器会弹出“请停用以开发者模式运行的扩展程序”的提示,此时点击“取消”才可以继续使用Frutta谷歌浏览器插件。
3.JUGO-IDE
JUGO-IDE是JUGO技术产品面向开发者提供的用来编写MPC算法的开发工具。
结合Frutta谷歌浏览器插件,开发者无需搭建任何环境就可以快速编写、编译、运行和发布算法。
通过使用JUGO-IDE,开发者可使用Frutta语言编写算法,并通过JUGO-IDE编译成可在JUGO技术产品上执行的电路文件和java模板文件。详情
4.Frutta语言
Frutta是矩阵元为安全多方计算的算法电路文件生成而专门定制的编程语言。它是一门类高级语言,也是一门面向过程的编程语言。Frutta支持大部分运算符、数据类型,表达方式灵活实用。目前只有矩阵元提供的在线ide可以进行编译运行。ide可以把Frutta文件编译成可在JUGO平台上执行的电路文件。详情
5.开发编程
5.1.计算逻辑编程
计算逻辑:为实现某个场景下的安全多方计算所编写的算法。
使用Frutta语言,在JUGO-IDE中可以快速完成计算逻辑的编程、验证和发布。
5.2.JUGO-SDK
JUGO-SDK是JUGO技术产品面向开发者提供的安全多方计算应用开发工具包。
开发者通过使用JUGO-SDK与其他JUGO技术产品,可以高效快速的开发MPC(安全多方计算)应用。每个集成了SDK的应用将作为计算节点接入到计算网络中。应用调用SDK可以实现安全多方计算以满足业务需求。
集成流程:
- IDE上编写电路算法;
- 编译算法并生成电路文件JAVA包装类;示例查看
- 项目中引入步骤2中的JAVA包装类;
- 集成API,完成应用开发;
5.3.应用部署
应用包含三大部分的代码。包括:1)算法代码、2)服务端应用代码、3)前端页面展示代码。
实现流程:
1) MPC应用部署
准备工作:
环境搭建(要求linux系统)
安装nginx
安装JDK,配置JDK环境变量
2) 项目打包
描述:
项目依赖gradle进行构建;
可通过gradle指令进行打包,文件输出在同级build目录下;
可通过JAVA IDE打包可执行文件;
gradle指令:
>clean build
Copy3) 项目运行
描述:
在环境中执行以下指令进行监听;
后续可通过统计目录nohup.out查看输出日志
指令参考:
>nohup java -jar MPCAcceptApp.jar &//启动接收方节点
>nohup java -jar MPCStartApp.jar &//启动发起方节点
Copy4) 项目调试
部署完毕。
在浏览器中输入
http://ip:port/swagger-ui.html ,可调试发起方接口。
在浏览器中输入
http://ip:port/swagger-ui.html ,可调试接收方接口。详情
第三章 Frutta语言
1.什么是Frutta
Frutta是矩阵元为安全多方计算的算法电路文件生成而专门定制的编程语言。它是一门类高级语言,也是一门面向过程的编程语言。Frutta支持大部分运算符、数据类型,表达方式灵活实用。目前只有矩阵元提供的在线ide可以进行编译运行。ide可以把Frutta文件编译成可在JUGO平台上执行的电路文件。
2.程序结构
在我们学习Frutta语言的基本构建块之前,让我们先来看看一个最小的Frutta程序结构,在接下来的章节中可以以此作为参考。
Frutta语言主要包括以下部分:
- 预处理器指令
- 输入输出定义
- 函数
- 变量
- 语句&表达式
- 注释
1. #parties 2 /* 两个参与方 */
2.
3. #input 1 int32 /* 参与方1,可以是基础类型,也可以是数组,结构体等复杂类型 */
4. #input 2 int32 /* 参与方2 */
5. #output 1 int32 /* 输出方 */
6.
7. /* 主函数,完成加法操作 */
8. function void main()
9. {
10. output1 = input1 + input2;
11. }一、基本语法
Frutta程序由各种Token组成,Token可以是关键字、标识符、常量、字符串值,或者是一个符号。
- 分号
在Frutta程序中,分号是语句结束符。也就是说,每个语句必须以分号结束。它表明一个逻辑实体的结束。
- 注释
注释就像是程序中的帮助文本,它们会被编译器忽略。它们以 /* 开始,以字符 */ 终止。
您不能在注释内嵌套注释,注释也不能出现在字符串或字符值中。
- 标识符
标识符是用来标识变量、函数,或任何其他用户自定义项目的名称。一个标识符以字母 A-Z 或 a-z 或下划线 _ 开始,后跟零个或多个字母、下划线和数字(0-9)。
标识符内不允许出现标点字符,比如 @、$ 和 %。标识符是区分大小写。因此,Manpower 和 manpower 是两个不同的标识符。下面列出几个有效的标识符:
mohd zara abc move_name a_123 myname50 _temp j a23b9 retVal
Copy- 关键字
下表列出了Frutta中的保留字。这些保留字不能作为常量名、变量名或其他标识符名称。对于输入输出,请按照顺序,依次写。输入个数跟参与计算方个数保持一致。比如有3个计算方个数,那么请依次定义input 1 xxx, input 2 xxx, input 3 xxx。输出也同样。
else typedef return for void if struct abs max min
int8 uint8 int16 uint16 int32 uint32 int64 uint64 bool
input1 input2 ... inputN output1 output2 ... outputN
Copy- 空格
只包含空格的行,被称为空白行,可能带有注释,编译器会完全忽略它。
在Frutta中,空格用于描述空白符、制表符、换行符和注释。空格分隔语句的各个部分,让编译器能识别语句中的某个元素(比如 int)在哪里结束,下一个元素在哪里开始。因此,在下面的语句中:type age;。在这里,type 和 age 之间必须至少有一个空格字符(通常是一个空白符),这样编译器才能够区分它们。另一方面,在下面的语句中:
fruit = apples + oranges;
Copyfruit 和 =,或者 = 和 apples 之间的空格字符不是必需的,但是为了增强可读性,您可以根据需要适当增加一些空格。
二、预处理器
预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。
所有的预处理器命令都是以井号(#)开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。
在Frutta中,支持两类预编译器指令:
- include
支持包含外部文件,外部文件支持以下几类外部文件:
- Frutta文件
使用Frutta实现的文件,里面实现的函数可以在当前文件里面调用。注意,只支持当前文件,不支持非当前目录,比如不支持#include "./lib/math.wir",只支持#include "math.wir"。一个完整的示例如下:
1. // math.wir
2. function int32 add(int32 x, int32 y)
3. {
4. return x + y;
5. }
6.
7. function int32 sub(int32 x, int32 y)
8. {
9. return x - y;
10. }
11.
12. function int32 mul(int32 x, int32 y)
13. {
14. return x * y;
15. }
16.
17. function int32 div(int32 x, int32 y)
18. {
19. return x / y;
20. }
21.
22. typedef struct Point
23. {
24. int32 x;
25. int32 y;
26. }
27.
28. /* 求两个点之间的距离 */
29. function int32 dis(Point p1, Point p2)
30. {
31. int32 x = sub(p1.x, p2.x);
32. int32 y = sub(p1.y, p2.y);
33.
34. return add(mul(x, x), mul(y, y));
35. }
36.
37. // include.wir
38. #include "math.wir"
39.
40. #parties 2
41. #input 1 Point
42. #input 2 Point
43. #output 1 int32
44.
45. function void main()
46. {
47. output1 = dis(input1, input2);
48. }
Copy- define
简单替换程序中的标识符。不支持宏参数,以及##连接符与#符。
1. #define NAME expression三、数据类型
1.基本类型
Frutta语言中,任何运算都表示为整数运算,因此Frutta语言以下几类基本类型:
| 类型 | 位数 | 数值范围 |
|---|---|---|
| bool | 8 | 取值为0和1 |
| int8 | 8 | -128 ~ 127 |
| uint8 | 8 | 0 ~ 255 |
| int16 | 16 | -32768 ~ 32767 |
| uint16 | 16 | 0 ~ 65535 |
| int32 | 32 | -2147483648 ~ 2147483647 |
| uint32 | 32 | 0 ~ 4294967295 |
| int64 | 64 | -9223372036854775808 ~ 9223372036854775807 |
| uint64 | 64 | 0 ~ 18446744073709551615 |
也可以定义不同字节数的自定义类型。
1. typedef signed bytelength type;
2. typedef unsigned bytelength utype;
Copy2.数据类型的隐式转换
Frutta在以下四种情况下会进行隐式转换:
a. 算术运算式中,低类型能够转换为高类型。
b. 赋值表达式中,右边表达式的值自动隐式转换为左边变量的类型,并赋值给他。
c. 函数调用中参数传递时,系统隐式地将实参转换为形参的类型后,赋给形参。
d. 函数有返回值时,系统将隐式地将返回表达式类型转换为返回值类型,赋值给调用函数。
当不同类型的数据进行操作时,应当首先将其转换成相同的数据类型,然后进行操作,转换规则是由低级向高级转换。
转换规则如下示:
Copyint8->uint8->int16->uint16->int32->uint32->int64->uint64。
举一个int8 -> uint8的例子:
1. int8 a = -41;
2. int8 b = -90;
3. uint8 c = a + b;
4. // 最终结果为 125
Copy3.结构体(struct)
Frutta支持类C语言的Struct,来定义结构体。结构体允许定义可存储不同类型数据项的变量。
1) 定义结构
1. typedef struct Point
2. {
3. int32 x;
4. int32 y;
5. }
6.
7. typedef struct Circle
8. {
9. Point p;
10. uint32 radius;
11. }
Copy以上定义可以使用 Point,Circle 定义结构体变量。
2) 访问结构成员
为了访问结构的成员,我们使用成员访问运算符(.)。成员访问运算符是结构变量名称和我们要访问的结构成员之间的一个英文句号。如定义一个变量Circle c访问它的成员变量x需要这样c.p.x。
4.数组
Frutta语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。
1) 声明数组
在Frutta中要声明一个数组,需要指定元素的类型和元素的数量,如下所示:type arrayName [ arraySize ]
Frutta支持多维数组,如下所示:type arrayName [row][col];
2) 初始化数组
在Frutta中,您可以逐个初始化数组,也可以使用一个初始化语句,如下所示:type balance[5] = {0, 0, 0, 0, 0};
大括号{ }之间的值的数目不能大于我们在数组声明时在方括号[ ]中指定的元素数目。
3) 访问数组元素
数组元素可以通过数组名称加索引进行访问。元素的索引是放在方括号内,跟在数组名称的后边。例如: type salary = balance[9];
上面的语句将把数组中第 10 个元素的值赋给 salary 变量。
四、常量
Frutta中,有整型常量和bool常量。
- bool常量:在Frutta中,内置两个bool常量true和false,二进制分别表示00000001和00000000。如:
bool flag = true。
Copy- 整型常量:整型常量可以使用10进制和16进制表示。16进制需要以0x开头。如:
uint32 YEAR = 365。五、变量
Frutta中,变量其实只不过是程序可操作的多个Wire的组合。Frutta中每个变量都有不同数量的Wire,运算符可应用于变量上。
变量的名称可以由字母、数字和下划线字符组成。它必须以字母或下划线开头。大写字母和小写字母是不同的。
变量定义指定一个数据类型(数据类型必须是类型定义里面声明的),并包含了该类型的一个或多个变量的列表,如:
type variable_list;
Copy变量可以在声明的时候被初始化(指定一个初始值)。初始化器由一个等号,后跟一个常量表达式组成,如下所示:
type variable_name = value;
六、运算符
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。Frutta语言内置了丰富的运算符,并提供了以下类型的运算符:
1.算术运算符
| 运算符 | 描述 |
|---|---|
| + | 把两个操作数相加 |
| - | 从第一个操作数中减去第二个操作数 |
| * | 把两个操作数相乘 |
| / | 分子除以分母 |
| % | 取模运算符,整除后的余数 |
2.关系运算符
| 运算符 | 描述 |
|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 |
3.位运算符
| 运算符 | 描述 |
|---|---|
| & | 如果同时存在于两个操作数中,二进制 AND 运算符复制一位到结果中。 |
| \ | 如果存在于任一操作数中,二进制 OR 运算符复制一位到结果中。 |
| ^ | 如果存在于其中一个操作数中但不同时存在于两个操作数中,二进制异或运算符复制一位到结果中。 |
| << | 二进制左移运算符。左操作数的值向左移动右操作数指定的位数。 |
| >> | 二进制右移运算符。左操作数的值向右移动右操作数指定的位数。 |
4.赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 |
七、操作符
1.按位取线
支持按位取变量的线
支持以VAR{start:length}方式获取某个变量从start开始的length根线,返回值可以赋值
给某个变量,也可以直接参与计算。
1. #parties 2
2. #input 1 int32
3. #input 2 int32
4. #output 1 int32
5.
6. function void main()
7. {
8. output1 = input1{0:8} + input2{0:8};//上面的数从0开始,取8个bit进行运算
9. }八、控制语句
1.条件判断语句
判断结构要求程序员指定一个或多个要评估或测试的条件,以及条件为真时要执行的语句(必需的)和条件为假时要执行的语句(可选的)。
| 语句 | 描述 |
|---|---|
| if语句 | 一个 if 语句 由一个布尔表达式后跟一个或多个语句组成。 |
| if...else语句 | 一个 if 语句 后可跟一个可选的 else 语句,else 语句在布尔表达式为假时执行。 |
| 嵌套 if 语句 | 可以在一个 if 或 else if 语句内使用另一个 if 或 else if 语句。 |
2.循环判断语句
循环语句允许我们多次执行一个语句或语句组,Frutta只支持for循环语句,如下所示:
1. for(type i=0; iCopy 注意:
-
不支持break,continue语句
-
结束条件i
-
不支持外部类型声明如for(; i
九、函数
1.函数定义
函数是一组一起执行一个任务的语句。每个Frutta程序都至少有一个函数,即主函数 main() ,所有简单的程序都可以定义其他额外的函数。
Frutta的函数定义如下:
1. function return_type foo(paramtype1 name1, paramtype2 name2, paramtype3[5] name3)
2. {
3. return blah;
4. }
5.
6. // 一个例子如下
7. function int32 add(int32 x, int32 y)
8. {
9. return x + y;
10. }
11. // 调用
12. output1 = add(input1, input2);
Copy一个函数的所有组成部分:
-
返回类型:一个函数可以返回一个值。return_type 是函数返回的值的数据类型。有些函数执行所需的操作而不返回值,在这种情况下,return_type 是关键字 void。
-
函数名称:这是函数的实际名称。函数名和参数列表一起构成了函数签名。
-
参数:参数就像是占位符。当函数被调用时,您向参数传递一个值,这个值被称为实际参数。参数列表包括函数参数的类型、顺序、数量。参数是可选的,也就是说,函数可能不包含参数。
-
函数主体:函数主体包含一组定义函数执行任务的语句。
2.内置函数
在Frutta中,内置以下函数:
| 函数 | 函数定义 | 函数说明 |
|---|---|---|
| abs | intxxx abs(intxxx) | 取绝对值,输入输出为有符整数。如下:int32 y = abs(x) |
| min | (u)intxxx min((u)intxxx, (u)intxxx) | 取两个数中的最小值,输入可以为有符和无符整数,如果同时有有符和无符,有符自动转换为无符,返回值为无符。如下:int16 min(x, y) |
| max | (u)intxxx max((u)intxxx, (u)intxxx) | 取两个数中的最大值,输入可以为有符和无符整数,如果同时有有符和无符,有符自动转换为无符,返回值为无符。如下:int16 max (x, y) |
第四章 JUGO-IDE
1.什么是JUGO-IDE
JUGO-IDE是JUGO技术产品面向开发者提供的用来编写MPC算法的开发工具,结合Frutta谷歌浏览器插件,开发者无需搭建任何环境就可以快速编写、编译、运行和发布算法。
通过使用JUGO-IDE,开发者可使用Frutta语言编写算法,并通过JUGO-IDE编译成可在JUGO技术产品上执行的电路文件和java模板文件。https://jugo.juzix.net/ide/
2.支持语言
Frutta语言。
Frutta作为类C的高级语言,可以将编写的计算逻辑在JUGO-IDE生成电路文件和java模板文件,并在JUGO技术产品中执行计算。详情
3开发环境
操作系统windows(后续支持linux),chrome浏览器(需先安装Frutta谷歌浏览器插件)
..
第一步,请点击下载Frutta谷歌浏览器插件的安装包,并在本地解压。
第二步,在Chrome浏览器地址栏输入chrome://extensions/,启用开发者模式,然后点击按钮“加载已解压的扩展程序”,选择插件所在的文件夹即可。
注意:由于该插件暂未上传Google插件商店,所以只能以开发者模式运行。打开chrome://extensions/,如下图示开启开发者模式。由于是以开发者模式运行该插件的,Chrome浏览器会弹出“请停用以开发者模式运行的扩展程序”的提示,此时点击“取消”才可以继续使用Frutta谷歌浏览器插件。 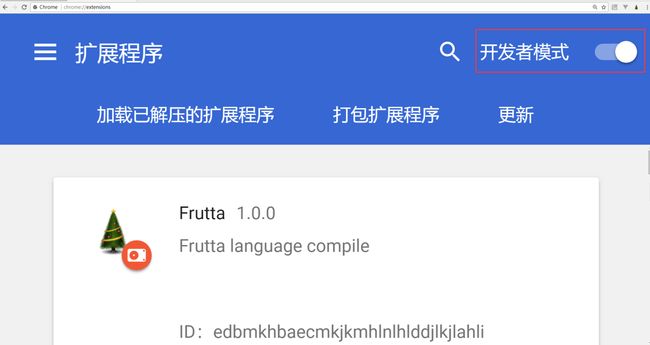
一、界面
1.启动页
1)JUGO-IDE启动页默认包含一个欢迎页和一个算法工程,开发者可根据需要进行增删。
2)开发者在未登录JUGO技术产品的情况下首次进入JUGO-IDE启动页的时候,即会自动弹出登录弹窗,提供了登录、忘记密码、注册等功能入口。开发者登录后才可以使用JUGO-IDE提供的访问算法库、发布算法的功能。当然,开发者也可以点击“暂不登录”关闭该登录弹窗继续使用MPC-IDE,不会对工程编译等功能造成影响。
3)JUGO-IDE启动时,编辑区默认打开JUGO-IDE欢迎页,该页面中提供了JUGO-IDE、Frutta、JUGO技术产品、MPC的简单介绍和详情页面链接,开发者可以点击“详情”去往详情页面进行深入了解。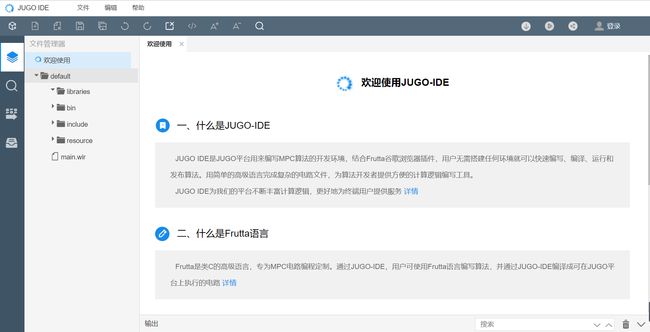
2.菜单栏
1)文件管理
功能描述:提供“新建工程、新建文件、导入本地文件、导出到本地、保存当前文件、保存所有文件、删除当前文件”等功能。
操作示例:
-
新建工程:点击头部“工具栏文件--新建工程”,会弹窗创建算法工程弹窗,开发者输入算法名称后,即在当前文件管理器中新建一个算法工程。
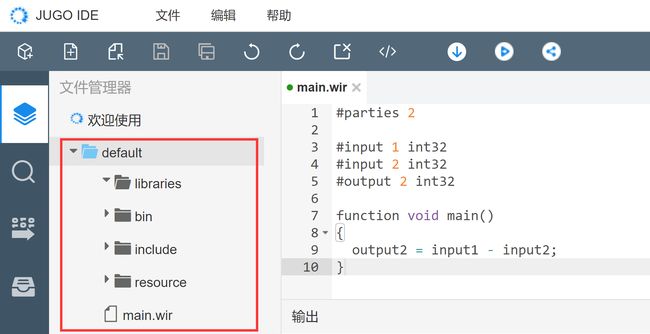
-
算法工程目录结构:
-
libraries: 引用的算法存放目录;
-
bin: 当前算法工程编译成功生成的java模板文件的存放目录;
-
Include: 算法工程头文件存放目录;
-
Resource: 算法工程源文件存放目录;
- main.wir: 当前算法工程入口文件
注意:当前算法工程的编译入口文件为“main.wir”。 如果选中其它文件点击编译,JUGO-IDE会自动定位到当前选中文件所属的算法工程,并编译该算法工程中的“main.wir”。如果需要编译其它文件,需要在“main.wir”中引入该文件后再点击“编译”。
- 新建文件:点击头部“工具栏文件--新建文件”,即在当前工程目录下新建一个Untitled1.wir文件,并自动在编辑区打开。
功能限制:IDE当前文件系统中至少有一个工程。
- 导入本地文件:点击头部工具栏“文件--导入本地文件”,选择某一文件后该文件即被导入进JUGO-IDE文件管理器,并自动在编辑区打开。
功能限制:IDE当前文件系统中至少有一个工程。
- 导出到本地:点击头部工具栏“文件--导出到本地”,会将IDE中当前选中的文件或文件夹导出到本地,文件夹的格式为“文件夹名”.rar,文件的格式和当前选中的文件在IDE中的格式保持一致。
功能限制:需要在IDE中选中文件或文件夹。
- 保存/全部保存:点击头部工具栏“文件--保存”,会保存当前文件;点击头部工具栏“文件--全部保存”,会保存文件管理器中的所有文件;
功能限制:当前窗口中有需要保存的文件
- 删除:点击头部工具栏“文件--删除”,会删除当前编辑区窗口打开的文件;
功能限制:当前有选中的文件
2)编辑操作
功能描述:提供对当前文件“撤销、恢复、复制、剪切、粘贴、查找、替换、格 式化、在文件中查找、在文件中替换”等常规功能。
操作示例:
在文件中查找/替换:点击头部工具栏“编辑--在文件中查找/替换”,左侧边栏会弹出搜索窗口,实现全局关键字的查找/替换功能。
功能限制:当前编辑区窗口中有打开的文件
3)帮助
功能描述:提供对操作员的帮助文档。
操作示例:
-
欢迎使用:点击头部工具栏“帮助--欢迎使用”,即会回到JIDE的欢迎页面,该页面中提供了JIDE的简介及使用的大致流程。
-
帮助文档:点击头部工具栏“帮助--帮助文档”,即会跳转到JUGO技术产品的文档中心,文档中心中包含了比较详细的开发流程。
3.工具栏
1)文件管理
功能描述:控制文件管理器的展开或收起。
操作步骤:文件管理器窗口默认展开,点击左侧工具栏“文件管理![]() ”控制文件管理器窗口的展开与收起
”控制文件管理器窗口的展开与收起
2)全局搜索
功能描述:提供全局的搜索、替换功能。
操作步骤:
第一步:点击左侧工具栏“搜索![]() ”按钮,调出全局搜索功能窗口;
”按钮,调出全局搜索功能窗口;
第二步:输入关键字即可即时出现搜索结果,关键字支持区分字母大小写、全字匹配、正则表达式;
第三步:点击搜索结果自动跳转到当前文件;
第四步:替换操作支持单个替换和全部替换,输入替换内容后,可以选择单个替换和全部替换;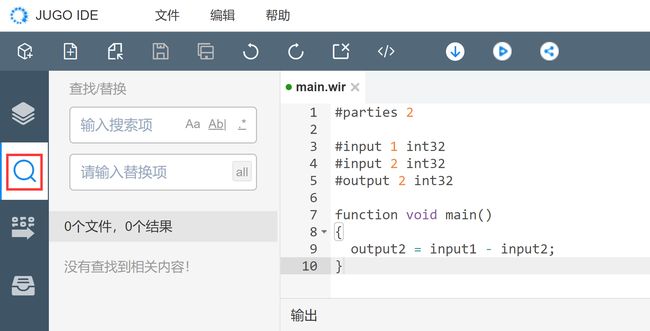
3)运行算法
功能描述:对进行编译成功的电路文件进行测试运行。
操作步骤:
第一步:点击左侧工具栏“运行![]() ”按钮,调出运行算法面板;
”按钮,调出运行算法面板;
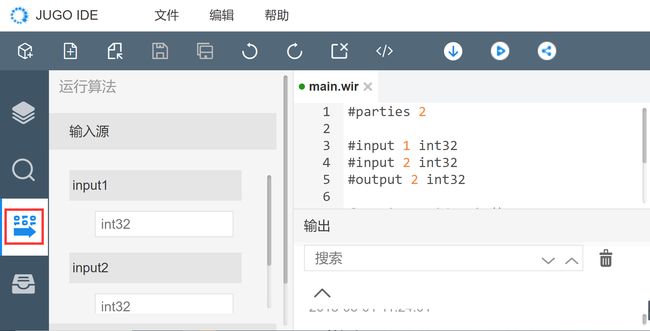
第二步:如果当前选中的工程没有编译成功,则提示没有数据;
第三步:如果当前选中的工程已经编译成功,则可输入输入项运行该算法;
第四步:运行成功,则会在输出栏提示运行成功并输入运行结果;
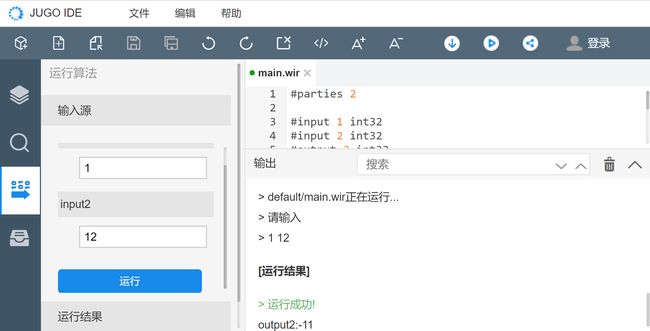
第五步:运行成功后,即可看到运行结果,格式如“name:value”,”name”即为当前运行的算法代码中的输出变量的名称,”value”为算法代码中输出变量的值。
4)算法库
功能描述:所有已上传到算法中心的算法,都可在算法库中调用,点击图标进入算法库页面。
操作步骤:
注意:进入算法库需要用户已登录,未登录状态则需要进行登录。
第一步:点击左侧工具栏“算法库![]() ”按钮,调出算法库面板;算法列表中展示每一个算法的名称、简介和发布者,支持关键字搜索算法;
”按钮,调出算法库面板;算法列表中展示每一个算法的名称、简介和发布者,支持关键字搜索算法;
第二步:点击某一个算法,即跳往该算法的详情界面,开发者可以了解到算法更多的信息,并提供了下载该算法的功能入口。
功能限制:需要开发者登录之后才能访问,如果开发者未登录,IDE会自动弹出登录弹窗提示开发者登录。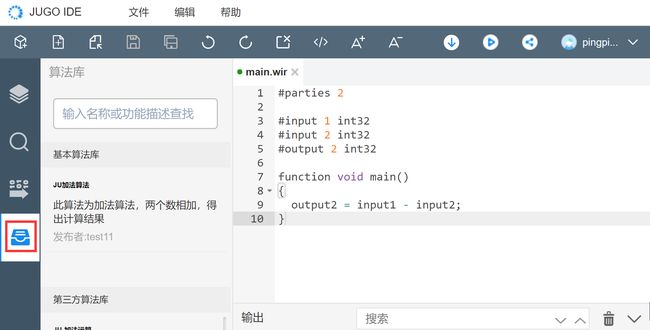
3.编辑区
1)语法检查
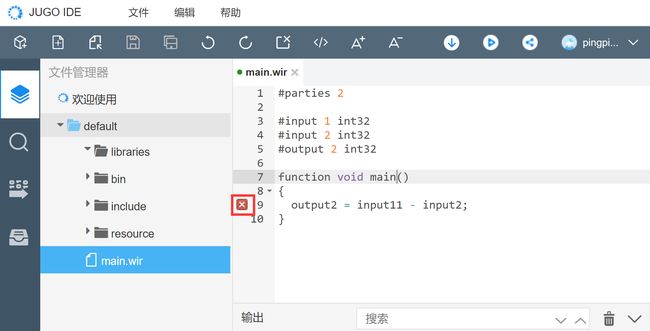
功能描述:对当前编辑的文件执行“保存”或者“编译”的操作时,会进行语法检查,错误的地方有红色叉号标识,鼠标悬浮在该行文字上时会显示具体的错误信息。
2)查找/替换
功能描述:输入关键字进行查找/替换,支持区分字母大小写、全字匹配、正则表达式。搜索结果支持上一个、下一个定位操作,替换操作支持单个替换和当前编辑区文件全部替换操作。
3)多个窗口展示
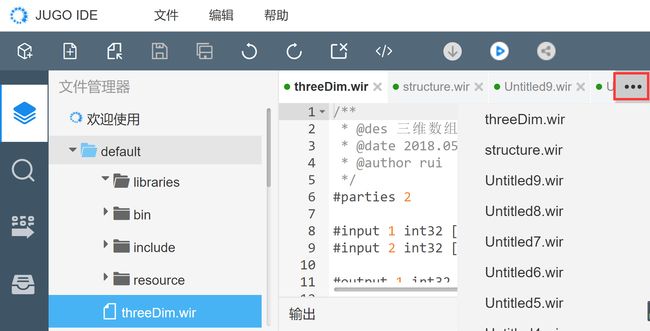
功能描述:编辑区打开文件过多时,隐藏的部分文件可在右侧“更多文件”入口打开。
操作步骤:点击右侧更多文件“...”标识,即可调出文件列表,其中加黑显示的是已经在编辑区显示的文件,灰色显示的是隐藏的文件;
4)窗口右键操作
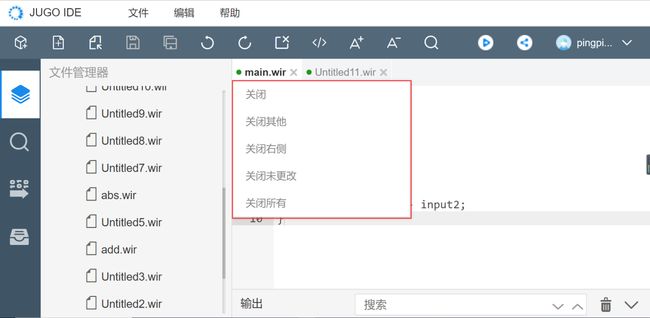
功能描述:提供“关闭、关闭其他、关闭右侧、关闭未更改、关闭所有”功能。
操作步骤:选中某一文件名,单击右键即可调出右键操作菜单。
5)文件状态标识
功能描述:每个文件名称左侧出现红色小圆点图标,则表示该文件更改后尚未保存;出现绿色小圆点图标,则表示该文件已保存。
二、快捷键
| 键名 | 操作 | 功能限制 |
|---|---|---|
| Alt+p | 新建工程 | 无 |
| Alt+N | 新建文件 | IDE当前文件系统中至少有一个工程 |
| Ctrl+O | 导入本地文件 | IDE当前文件系统中至少有一个工程 |
| Ctrl+S | 保存 | IDE当前文件系统中有未保存的文件 |
| Ctrl+Alt+S | 全部保存 | IDE当前文件系统中有未保存的文件 |
| Ctrl+delete | 删除 | 当前有选中的文件 |
| Ctrl+Z | 撤销 | 当前编辑区窗口中有打开的文件 |
| Ctrl+Y | 恢复 | 当前编辑区窗口中有打开的文件 |
| Ctrl+C | 复制 | 当前编辑区窗口中有打开的文件 |
| Ctrl+X | 剪切 | 当前编辑区窗口中有打开的文件 |
| Ctrl+V | 粘贴 | 当前编辑区窗口中有打开的文件 |
| Ctrl+F | 查找 | 当前编辑区窗口中有打开的文件 |
| Ctrl+H | 替换 | 当前编辑区窗口中有打开的文件 |
| Ctrl+L | 代码格式化 | 当前编辑区窗口中有打开的文件 |
| F2 | 重命名 | 当前有选中的文件 |
| F8 | 编译 | IDE当前文件系统中至少有一个工程 |
三、编写流程
1.文件格式
1) 输入文件格式
JUGO-IDE目前支持所有格式文件的编辑,但是编译功能仅限于.wir格式的文件。
2) 输出文件格式
在JUGO-IDE中对一个.wir格式的文件进行编译将生成一个.gc格式的电路文件和一个.java格式的java模板文件;.gc文件可通过“导出”按钮导出到本地,.java文件放置于工程“bin”目录,可通过菜单栏或者工具栏中“导出到本地”功能导出到本地,.java文件可在java-sdk中使用。。
2.自动补全
功能描述:JUGO-IDE编辑区在输入过程中即时显示自动补全提示。
3.编程
功能描述:JUGO-IDE编辑区提供查找、替换、代码格式化、字体放大、字体缩小、撤销、恢复等常用功能。
流程:编辑--保存--编译
错误类型反馈:
1)开发者在执行保存操作时,如果代码中有语法错误,错误的地方行号处有红色叉号标识,鼠标悬浮在该行文字上时会显示具体的错误信息。
2)开发者在执行编译操作时,如果编译出错,IDE输出区域会有红色的错误信息输出,点击错误信息,编辑区会自动打开当前发生错误的文件。
措施:开发者在执行保存或者编译时如果有错误信息提示,需要重新编辑文件纠错后再执行保存或者编译操作。
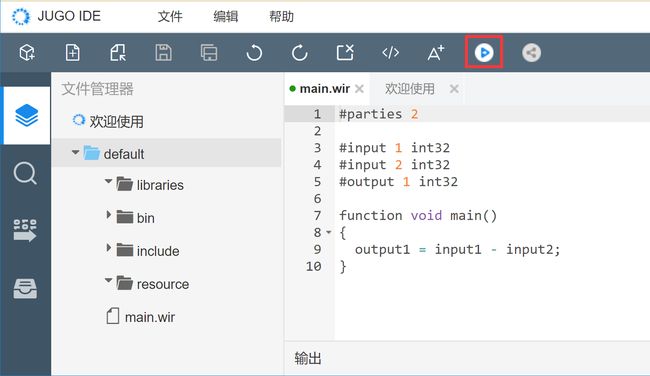
4.运行
功能描述:JUGO-IDE编辑区提供“查找、替换、代码格式化、字体放大、字体缩小、撤销、恢复”等常用功能。
流程:当前工程编译成功后执行运行
错误类型反馈:
1)当前项目没有编译成功
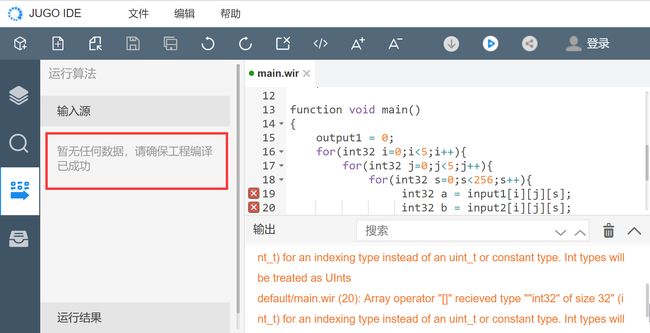
措施:开发者需要先对当前工程进行编译,编译成功后才能运行算法。
2)无效参数
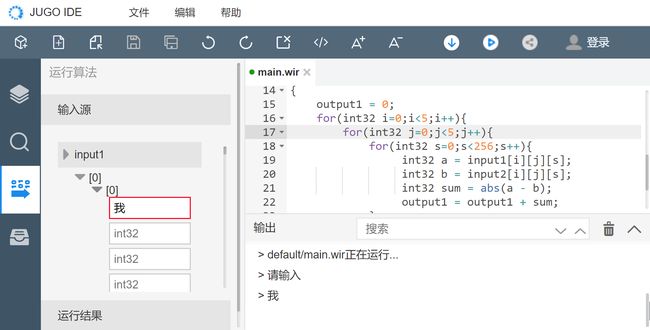
措施:当前项目编译成功后运行的时候,会对输入参数进行类型和范围校验,存在不合法的参数时无法点击“运行”按钮。
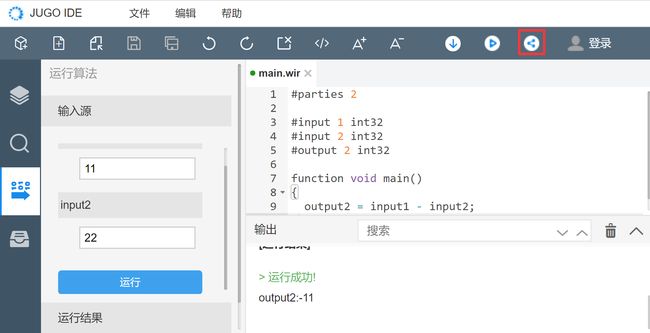
5.发布
功能限制:
1)需要开发者登录。
2)当前项目编译成功并通过了运行测试。
用途:开发者可将已通过运行测试的算法发布到JUGO技术产品的算法库中,算法库是JUGO技术产品的算法仓库,开发者使用JUGO-IDE发布的算法会生成一个唯一的算法ID,通过这个算法ID可以下载该算法,并通过JUGO-SDK使用该算法。详情
6.算法库
功能限制:需要开发者登录。
用途:开发者可以访问到JUGO技术产品的算法中心的所有算法。算法列表中展示每一个算法的名称、简介和发布者,支持关键字搜索算法;点击某一个算法,即跳往该算法的详情界面,开发者可以了解到算法更多的信息,并提供了下载该算法的功能入口。
7.导出
功能描述:开发者可以通过导出功能将JUGO-IDE中当前选中的文件或文件夹导出到本地,文件夹的格式为“文件夹名”.rar,文件的格式和当前选中的文件在IDE中的格式保持一致。
四、登录
开发者登录后才可以访问JUGO-IDE提供的访问算法库、发布算法的功能。
第五章、JUGO-SDK
1.概述
SDK(SoftwareDevelopmentKit)通常是为研发应用软件所提供的开发工具的集合。而JUGO-SDK是为安全多方计算应用所提供的开发工具包。通过JUGO-SDK,开发者可以高效的研发MPC(安全多方计算)应用。
JUGO-SDK提供了丰富的应用开发接口,而且还是MPC的计算节点——通过SDK的调用,应用可以实现数据上传、算法调用、计算邀请、任务受理、MPC本地计算等功能。使得数据在不离开本地的情况下,获取计算结果。
本文档旨在为开发者介绍JUGO-SDK的使用及注意事项。
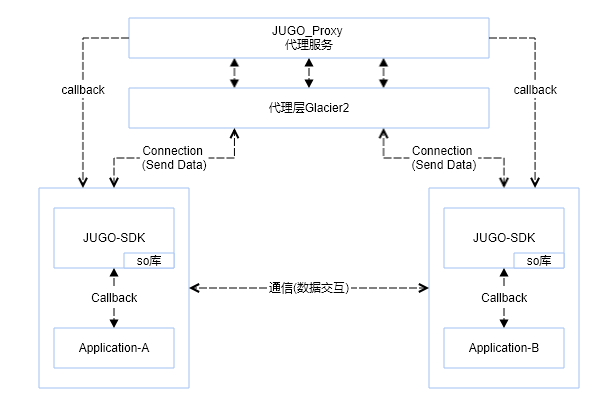
2.编程语言&开发环境
| 支持语言: | JAVA语言 |
|---|---|
| JDK 版本: | JDK1.8 |
| 开发工具: | 推荐使用 IntelliJ IDEA |
| 开发环境: | 操作系统window/linux,ICE-3.6 |
| 调试环境: | 算法库目前仅支持.so动态库(Linux平台运行),完整的计算流程需要在Linux环境上进行,部分开发功能可在window上进行调试。 |
| 运行环境: | 目前仅支持运行在Linux环境,推荐:CentOS Linux release 7.2.1511 (Core) |
| 电路文件: | 后缀格式规定为:.gc |
| 其他: | JUGO-SDK使用了Ice中的Glacier2进行防火墙穿透,需要阅读者具备分布式系统中间件(Ice)的基础知识 |
一、JUGO-SDK使用步骤
本章节主要介绍JUGO-SDK的使用步奏
1.引入JUGO-SDK
SDK仓库地址:http://sdk.juzix.net/content/groups/public/
Maven
1.
2. com.juzix.jugo
3. mpc-node-sdk
4. 1.3.0
5.
CopyGradle
1. compile "com.juzix.jugo:mpc-node-sdk:1.3.0"
CopyJar包引用下载
下载后会得到一个zip包,解包后将对应jar包全部拷贝到本地项目中依赖引用。
2.配置算法动态库
底层算法逻辑使用c/c++进行编写,JAVA使用JNI进行调用。目前仅提供了Linux环境下的动态库(.so),因此测试环节需在Linux完成。下载解压后会得到一个libjuzixmpc.so,libjuzixMpcSDK.so动态库文件,需要更改配置文件mpc-node-config.conf进行配置 。
注:此项操作必须完成,否则无法完成计算操作。
算法动态库 下载
3.配置文件创建
计算任务在执行过程中,需要获取电路文件的配置信息时,JUGO-SDK将使用默认方式进行获取,默认方式为存档在classespath路径;如自定义实现了CircuitManager,则无需提供配置文件。此处规定,配置文件名为:mpc-node-config.conf,必须在目录config下。配置文件可位于classes源码目录或者${user.dir}工作目录。如果使用IDEA开发工具,则可将配置文件放置在:${project.dir}/src/main/resources/config/mpc-node-config.conf。
文件内容如下:
1. node {
2. isDebug=false
3. # 是否使用Glacier2进行消息路由 false 不使用, true 使用
4. isRouterModel=false
5. circuit {
6. # 电路文件下载地址,此处将IP和port更改为实际地址即可
7. download.url = "http://xxx:port/file_api/file/download?arithmeticId=%s&user=%s"
8. # 电路文件本地存储目录
9. local.dirPath = /home/test/developer/jugompc
10. }
11. jni {
12. # jni调用的动态库文件目录
13. library.path=/home/test/developer/jnilib
14. }
15. }
Copy注:完成以上2步操作基本完成了对JUGO-SDK的集成。请务必注意算法库的文件路经配置正确。
4.配置节点为服务节点
在节点启动时,分为服务节点启动,和非服务节点启动两种。
服务节点是,只有任务请求通过代理服务回调传输,剩余过程直接与对端节交互。在调用API-初始化节点(initContext)时,如果参数mode传入SERVER,则必须进行配置操作。
非服务节点是,任务请求和中间计算通讯均通过代理服务器回调传输。
当节点需要作为服务节点启动时,需提供服务配置文件,并在初始化时通过参数args传入。
1)服务配置文件:config.node-server
1. # 当前节点作为服务提供的Endpoints信息
2. NodeServer.Endpoints=tcp -h 0.0.0.0 -p 12001
3. NodeServer.Nodepoint=tcp -h47.100.43.6 -p 12001
4. Ice.ThreadPool.Server.Size=4
5. Ice.ThreadPool.Server.SizeMax=4
6. Ice.ThreadPool.Client.Size=1
7. Ice.ThreadPool.Client.SizeMax=1
8.
9. #tcp keepalive
10. Ice.ACM.Close=4 # CloseOnIdleForceful
11. Ice.ACM.Heartbeat=0 # HeartbeatOff
12. #Ice.ACM.Heartbeat=3
13. Ice.ACM.Timeout=10
Copy注:在创建电路实例中的
args=new String[]{“--Ice.Config=config.node-server”}
Copy2)服务节点和非服务节点间无法执行计算。
二、API接口
| API | 说明 |
|---|---|
| YourCircuitWrapper() | 初始化上下文, 构建电路对象 |
| doCompute() | 启动计算任务 |
| setInputCallbackForORG() | 设置发起方计算数据源回调CALLBACK |
| setInputCallbackForDST() | 设置受邀方计算数据源回调CALLBACK |
| setOutputCallbackORG() | 设置发起方结果处理回调CALLBACK |
| setOutputCallbackDST() | 设置受邀方结果处理回调CALLBACK |
| invite() | 是否接受计算邀请 |
| getLocal() | 获取电路文件路径 |
| setDataLogLevel() | 控制计算数据是否输出到文件,并根据级别进行打印输出。 |
以下是API接口的详细介绍。
1.创建电路实例
接口:YourCircuitWrapper circuit=new YourCircuitWrapper();
注意:电路文件包装类,仅可实例化一次,建立与代理连接。
描述:创建电路实例,并完成链路初始化工作,与JUGO代理服务进行会话连接,后续数据通信都依赖此连接通道进行。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| pcbId | String | 是 | 电路ID,一般与电路文件名相同,此值会用于进行本地电路文件搜索。如:xxx.gc |
| user | String | 是 | 节点用户名,用于连接JUGO平台代理服务进行鉴权。获取方式从JUGO开发服务平台已注册 |
| password | String | 是 | 用户名对应密码,用于连接JUGO代理服务会话连接鉴权。此密码对应JUGO开发服务平台已注册账号对应的密码 |
| mode | NodeCommunicateMode | 是 | 节点启动模式,有两种类型SERVER -节点初始化后同时作为服务节点启动CALLBACK -节点初始化后作为回调节点启动有关二者差异的描述请参考JUGO-SDK使用步骤章节 |
| proxyEndpoint | String | 是 | JUGO代理服务的Endpoints连接信息。例如:ProxyGlacier2/router:tcp -h 192.168.7.167 -p 4502 -t 11000 |
| jugoEndpoint | String | 否 | 当前节点的Endpoint信息,当mode == SERVER时,此值必填。mode == CALLBACK时可不填 |
| args | Array | 是 | 启动配置信息。如:携带节点服务配置信息:--Ice.Config=config.conf |
返回参数说明:
| 参数 | 说明 |
|---|---|
| 无返回参数 | 需处理调用过程中可能触发的异常MPCException |
示例代码:
1. try {
2. YourCircuitWrapper yourCircuit=new YourCircuitWrapper("mycircuitId","admin01","password",NodeCommunicateMode.SERVICE
3. , "ProxyGlacier2/router:tcp -h 192.168.7.167 -p 4502 -t 11000", null, "--Ice.Config=config.conf");
4. } catch (MPCException e) {
5.
6. }
Copy2.开启计算任务
接口:yourCircuit.doCompute();
注意:调用前请确保成功构建了YourCircuitWrapper实例对象。
描述:通过调用doCompute,可以启动一次计算任务。该接口由任务发起方进行调用,被邀请方无需调用该接口。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| roomId | String | 是 | 计算实例ID,该值由JUGO开发服务平台提供,当创建好一次计算任务后会产生该值 |
| args | Array | 否 | 计算条件,参数可任意扩展,但需要保证所有计算参与方对此字段的解析过程一致即可。如:此处传递A=15 B=15 C=17,各其它参与方收到数据后按规则解析参数结构获取 |
| takerList | List | 是 | 计算参与方用户名列表,列表中第一个元素为计算任务发起者 |
| resultReceiverList | List | 是 | 计算结果接收方列表,计算完成后该列表中用户都会收到计算结果 |
返回参数说明:
| 参数 | 说明 |
|---|---|
| 无返回参数 | 需处理调用过程中可能触发的异常MPCException |
示例代码:
1. try {
2. String[] argsAttach = new String[]{"n=3","m=4"};
3. List takerList = Arrays.asList(new String[]{"admin01","admin02"});
4. List resulReceiverList = Arrays.asList(new String[]{"admin01"});
5. yourCircuit.doCompute("1111", argsAttach, takerList, resulReceiverList);
6. } catch (MPCException e) {
7. e.printStackTrace();
8. }
Copy3.发起方获取源数据
接口:yourCircuit.setInputCallbackForORG();
注意:此函数用于设置计算发起方的源数据获取方式。
描述:此函数接受一个InputCallback()接口的具体实现, 可自行定义计算源数据的获取逻辑。设置时请注意电路文件定义的数据结构规范,如果是数组则需要保证数组元级及元素个数与预定义的一致。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| taskId | String | 是 | 任务ID,回调传入。每发起一次计算就会产生一个新的任务ID |
| algorithmId | String | 是 | 算法ID,回调传入。每一次任务对应一个算法ID |
| args | Array | 是 | 附加参数,此参数就是在调用startTask时传入的args参数,可以使用此参数携带条件(如果业务需要的话),任何参与方收到的参数都是一致的 |
返回参数说明:
| 类型 | 说明 |
|---|---|
| 返回具体类型由电路文件定义 | 无 |
示例代码:
1. yourCircuit.setInputCallbackForORG(new InputCallback() {
2. @Override
3. public Int32[][] input(String taskId, String algorithmId, String[] args) {
4. return new Int32[2][2];
5. }
6.
7. @Override
8. public void onFailure(Throwable e, String[] args){
9. // 异常处理
10. }
11. });
Copy说明:
上述示例中假定生成的电路java文件中定义的入参类型为:Int32[][],一个Int32的二维数组,且元素个数为[2][2]。
4.受邀方获取源数据
接口:yourCircuit.setInputCallbackForDST();
注意:此函数用于设置受邀发起方的源数据获取方式。
描述:此函数接受一个InputCallback()接口的具体实现, 可自行定义计算源数据的获取逻辑。设置时请注意电路文件定义的数据结构规范,如果是数组则需要保证数组元级及元素个数与预定义的一致。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| taskId | String | 是 | 任务ID,回调传入。每发起一次计算就会产生一个新的任务ID |
| algorithmId | String | 是 | 算法ID,回调传入。每一次任务对应一个算法ID |
| args | Array | 是 | 附加参数,此参数就是在调用startTask时传入的args参数,可以使用此参数携带条件(如果业务需要的话),任何参与方收到的参数都是一致的 |
返回参数说明:
| 类型 | 说明 |
|---|---|
| 返回具体类型由电路文件定义 | 无 |
示例代码:
1. yourCircuit.setInputCallbackForDST(new InputCallback() {
2. @Override
3. public Int32[][] input(String taskId, String algorithmId, String[] args) {
4. return new Int32[3][3];
5. }
6.
7. @Override
8. public void onFailure(Throwable e, String[] args){
9. // 异常处理
10. }
11. });
Copy说明:
上述示例中假定生成的电路java文件中定义的入参类型为:Int32[][],一个Int32的二维数组,且元素个数为[3][3]。因此在回调函数中input的返回一定是[3][3]及的多维数组。
5.设置发起方结果处理回调
接口:yourCircuit.setOutputCallbackForORG();
注意:N/A。
描述:设置一个回调函数,用于处理获取到的结果。该结果返回的数据类型与电路文件算法电路的返回类型一致。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| taskId | String | 是 | 任务ID,回调传入。每发起一次计算就会产生一个新的任务ID |
| algorithmId | String | 是 | 算法ID,回调传入。每一次任务对应一个算法ID |
| resultCode | int | 是 | 结果错误码,0表示成功获取数据。 |
| result | 是 | 计算结果,其类型根据电路决定,是动态变化的。可能为:Int32/Int64/Int32[]/Int32[][] | |
| args | String[] | 是 | 计算条件,由发起方规定,所有参与方都会接收该参数。 |
| type | MPCTaskType | 是 | 任务类型:ALICE(0),BOB(1),枚举值用于标识当前任务类型为发起方(ALICE)或受邀方(BOB)。 |
返回参数说明
| 类型 | 说明 |
|---|---|
| void | 无返回值 |
示例代码:
1. yourCirciut.setOutputCallback(new OutputCallback(Int32.class) {
2. @Override
3. public void onResult(String taskId, String algorithmId, int resultCode, Int33 result, String[] args, MPCTaskType type) {
4. // 处理结果
5. }
6.
7. @Override
8. public void onFailure(Throwable e, String[] args){
9. // 异常处理
10. }
11. }
Copy注意:示例中的数据类型(Int32)由具体电路文件决定。
6.设置受邀方结果处理回调
接口:yourCircuit.setOutputCallbackForDST();
注意:N/A。
描述:设置一个回调函数,用于处理获取到的结果。该结果返回的数据类型与电路文件算法电路的返回类型一致。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| taskId | String | 是 | 任务ID,回调传入。每发起一次计算就会产生一个新的任务ID |
| algorithmId | String | 是 | 算法ID,回调传入。每一次任务对应一个算法ID |
| resultCode | int | 是 | 结果错误码,0表示成功获取数据。 |
| result | 是 | 计算结果,其类型根据电路决定,是动态变化的。可能为:Int32/Int64/Int32[]/Int32[][] | |
| args | String[] | 是 | 计算条件,由发起方规定,所有参与方都会接收该参数。 |
| type | MPCTaskType | 是 | 任务类型:ALICE(0),BOB(1),枚举值用于标识当前任务类型为发起方(ALICE)或受邀方(BOB)。 |
返回参数说明
| 类型 | 说明 |
|---|---|
| void | 无返回值 |
示例代码:
1. yourCirciut.setOutputCallback(new OutputCallback(Int32.class) {
2. @Override
3. public void onResult(String taskId, String algorithmId, int resultCode, Int33 result, String[] args, MPCTaskType type) {
4. // 处理结果
5. }
6.
7. @Override
8. public void onFailure(Throwable e, String[] args){
9. // 异常处理
10. }
11. }
Copy注意:示例中的数据类型(Int32)由具体电路文件决定。
7.处理邀请结果
接口:InvitationManager->invite();
注意:此接口提供了默认实现,如需更改则需要在调用doCompute()前重新进行设置。可调用yourCircuit.setInvitationManager();进行更改。
描述:一个接口,并提供回调函数,当节点收到计算邀请后该回调会被触发,可在回调函数中提供业务逻辑来决定是否同意计算邀请。该接口提供了一个默认实现类(DefaultInvitationManager)
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| taskId | String | 是 | 任务ID,回调传入。每发起一次计算就会产生一个新的任务ID |
| starter | String | 是 | 计算发起者用户名 |
| algorithmId | String | 是 | 算法ID,回调传入。每次任务都对应有一个算法ID |
| numberOfParticipants | int | 是 | 参与计算方人数 |
| takersList | List |
是 | 计算参与方用户名列表 |
返回参数说明:
| 类型 | 说明 |
|---|---|
| boolean | 计算邀请确认结果,true 同意参与计算,false 拒绝参与计算 |
示例代码:
1. yourCircuit.setInvitationManager(new InvitationManager() {
2. @Override
3. public boolean invite(String taskId, String starter, String algorithmId, int numberOfParticipants, List takersList) {
4. // 这里实现业务逻辑
5. return true;
6. }
7. });
Copy8.获取本地电路文件
接口:CircuitManager -> getLocal();
注意:如需更改则在调用doCompute前重新进行设置。可调用yourCircuit.setCircuitManagerManager();预先设置。
描述:此接口提供了默认实现类(DefaultCircuitManager)。当需要自定义电路文件路径时可重新提供接口实现。JUGO-SDK默认会根据算法ID(algorithmId)去电路仓库进行下载(由JUGO开发服务平台提供)。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| algorithmId | String | 是 | 算法ID,优先会根据算法ID作为文件名进行本地搜索(后缀.gc),如果不存在则会从电路文件仓库进行下载 |
返回参数说明:
| 类型 | 说明 |
|---|---|
| String | 返回电路文件存储在本地的全路径 |
示例代码:
1. // 示例提供了根据不同ID返回不同文件类型的电路文件
2. yourCircuit.setCircuitManager(new CircuitManager() {
3. @Override
4. public String getLocal(String algorithmId) {
5. if(algorithmId.equals("1")){
6. return "/home/juzhen/work2018/jugo/jugompc/circuits-files/adder_32bit.gc";
7. }
8. if(algorithmId.equals("2")){
9. return "/home/juzhen/work2018/jugo/jugompc/circuits-files/AES-expanded.gc";
10. }
11. return "";
12. }
13. });
Copy9.设置日志级别
接口:NodeContext->setDataLogLevel();
注意:如需更改则在调用doCompute前重新进行设置。可调用NodeContext.setDataLogLevel();预先设置。
描述:此接口主要应用于当需要对计算过程中的数据进行记录的场景,设定开关并指定级别则可以对计算过程中数据进行控制。
参数说明:
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| switch | boolean | 是 | 日志开关,是否输出:true 输出数据, 不输出数据。输出日志目录指定方式在初始化创建电路实例时在数组中添加:--Mpc.Data=/opt/data |
| level | int | 是 | 日志级别:0 trace,1 debug,2 info, 3 warn,4 error |
返回参数说明:
| 类型 | 说明 |
|---|---|
| int | 设置结果,0标识成功 |
示例代码:
1. // 示例:设置开关开,并将级别设置为1(debug)
2. NodeContext.setDataLogLevel(true,1);
三、返回码一览
| 错误码 | 说明 |
|---|---|
| 0 | 计算成功 |
| 100 | 程序未知异常 |
| 1001 | 连接失败,网络不通 |
| 1007 | 参与计算节点异常下线 |
| 1008 | 有节点拒绝参与计算 |
| 1009 | 电路文件缺失 |
第六章、经典案例
1.业务逻辑
百万富翁经典问题由图灵奖获得者、中国科学院院士姚期智教授在1982年提出。问题中有两个百万富翁——Alice和Bob,他们想知道彼此之间谁更富有,却又不想让对方知道自己任何财富信息。由此问题的解决方案延伸出密码学的一个重要分支——安全多方计算(MPC:Secure Multi-Party Computation)。
本案例要将百万富翁问题场景还原:
1)计算的任意一方,在案例应用中输入身价数值,并发起计算;
2)而另一方在收到的任务邀请中填入数值,即可进行MPC计算。
3)最终双方将获得唯一的计算结果:发起方比接收方富有,或发起方没有比接收方富有。
在此过程中,双方既无法获取对方的身价数值,也无法从交互的数据中推导出对方的身价数值。
2.使用算法
由JUGO IDE所编译的32位比大小算法电路文件。
一、代码
JUGO开放服务平台中已部署完整案例应用,可直接访问。
在线地址:https://jugo.juzix.net/demo/,
若您想体验案例完整的部署流程并在本地使用,请参照以下介绍:
案例中集成了三大部分的代码。包括,
1)算法代码。
2)服务端应用代码。
3)前端页面展示代码。
1.算法代码
1. #parties 2
2. #input 1 uint32
3. #input 2 uint32
4. #output 1 uint32
5. function void main()
6. {
7. /* 数据比较电路 (output1=1 && input1>input2)*/
8. output1 = input1/input2;
9. if(output1>0)
10. {
11. output1 = 1;
12. }
13. }
Copy2.服务端代码
1)初始化节点
描述
引入JUGO平台SDK库;
初始化节点,启动节点监听(包括发起方节点和接收方节点);
JUGO的节点初始化是以异步形式进行返回。
代码参考:
1. compare = new Compare(SystemProperties.getDefault().getCompare(), SystemProperties.getDefault().getNode1UserName(), SystemProperties.getDefault().getNode1Password(), mode,SystemProperties.getDefault().getNode1Endpoint(), null, argsAttach);
2. //设置返回的callback对象,处理结果返回数据,对于发起方使用setOutputCallbackForORG.对于被邀请方使用setOutCallbackForDST
3. compare.setOutputCallback(new OutputCallback(Uint32.class){
4. @Override
5. public void onResult(String taskId, String algorithmId, int resultCode, Uint32 result,String[] args, MPCTaskType mpcTaskType) {
6. logger.debug("获取到结果:任务ID:{},算法ID:{},错误码:{},值:{}",
7. taskId, algorithmId, resultCode, result.getValue().toString());
8. //根据返回值进行判断结果
9. if(resultCode == 0){
10. resultMapper.insertData(id, "获取最终结果,返回数据结果:我方值大于等于对方值,任务id:" + taskId, new Date(),Const.getType_one());}
11. else{
12. resultMapper.insertData(id, "获取最终结果,返回数据结果:对方值较大,任务id:" + taskId ,new Date(), Const.getType_one());}
13. }
14. @Override
15. public void onFailure(Throwable e,String[] args) {
16. e.printStackTrace();
17. }
18. });
19. // 邀请方定义输入参数。对于输入发起方调用setInputCallbackForORG方法,被邀请方调用setInputCallbackForDST方法。
20. compare.setInputCallbackForORG(new InputCallback() {
21. @Override
22. public Uint32 onInput(String taskId, String algorithmId, String[] args) {
23. resultMapper.insertData(id, "准备参与计算参数,发起计算,任务id:" + taskId, new Date(),Const.getType_one());
24. //初始化后台输入参数
25. return new Uint32(BigInteger.valueOf(3));
26. }
27. @Override
28. public void onFailure(Throwable e,String[] args) {
29. e.printStackTrace();
30. }
31. });
Copy2)节点启动任务
描述:
如果是被邀请方,无需启动任务
如果是发起方,需要进行启动任务
JUGO的节点初始化是以异步形式进行返回
代码参考:
1. //初始化计算双方
2. List takerList = Arrays.asList(new String[] { "admin01", "admin02" });
3. //初始化接收结果的参与方
4. List resulReceiverList = Arrays.asList(new String[] { "admin01" , "admin02"});
5. //启动节点任务
6. compare.doCompute(SystemProperties.getDefault().getRoomId(), argsAttach, takerList, resulReceiver
三、实现流程
1.MPC应用部署
1)准备工作
环境搭建(要求linux系统)
安装nginx
安装JDK,配置JDK环境变量
2.项目打包
1)描述:
项目依赖gradle进行构建;
可通过gradle指令进行打包,文件输出在同级build目录下;
可通过JAVA IDE打包可执行文件;
2)gradle指令:
1.>clean build
Copy3.配置说明及修改
1)jar包同级目录/config/mpc-config/mpc-node-config.conf修改:
node {
isDebug=false
#是否使用Glacier2进行消息路由 false 不使用, true 使用
isRouterModel=false
circuit {
#电路文件下载地址,此处将IP和port更改为实际地址即可
download.url = "http://xxx:port/file_api/file/download?arithmeticId=%s&user=%s"
#电路文件本地存储目录 同2.4路径
local.dirPath = /home/mpc/gc
}
jni {
# jni调用的动态库文件目录 同2.3路径
library.path=/home/mpc/jnilib
}
}
Copyjar包中配置修改,以application.properties为例,路径 jar:// BOOT-INF\classes application.properties:
#运行服务端口 端口配置
server.port=8082
server.session-timeout=60
server.tomcat.max-threads=0
server.tomcat.uri-encoding=UTF-8
server.context-path=/
#JDBC配置。需要修改对应的url、username和password
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/mpc?useUnicode=true&charaterEncoding=utf-8
spring.datasource.username=mpc
spring.datasource.password=Juzhen123!
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
spring.datasource.maxWait=60000
spring.datasource.timeBetweenEvictionRunsMillis=60000
spring.datasource.minEvictableIdleTimeMillis=300000
spring.datasource.validationQuery=SELECT 1 FROM DUAL
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
env=dev
#房间id,可以随便填写
localRoomId=1
#算法名称,后续会根据路径去查询对应算法
cirName=Compare
#本节点的用户名
node1Name=test002
#被邀请的用户名(同另一方用户名)
node2Name=test001
#节点接入密码(暂不使用,随意输入)
nodePassword=123456
#节点接入地址,将ip和prot修改成实际使用
nodeEndpoint=ProxyGlacier2/router:tcp -h 192.168.112.158 -p 4502 -t 11000
Copy4.项目运行
1)描述:
在环境中执行以下指令进行监听;
后续可通过统计目录nohup.out查看输出日志
2)指令参考:
1.>nohup java -jar MPCAcceptApp.jar &//启动接收方节点
Copy2.>nohup java -jar MPCStartApp.jar &//启动发起方节点
Copy5.项目调试
部署完毕
在浏览器中输入
http://ip:port/swagger-ui.html,可调试发起方接口
在浏览器中输入
http://ip:port/swagger-ui.html,可调试接收方接口
6.在线版本
https://jugo.juzix.net/demo/
第七章 网站使用手册
1.注册
![]()
- 访问JUGO开放服务平台后,点击右上角“注册”按钮,跳转到用户注册页面。
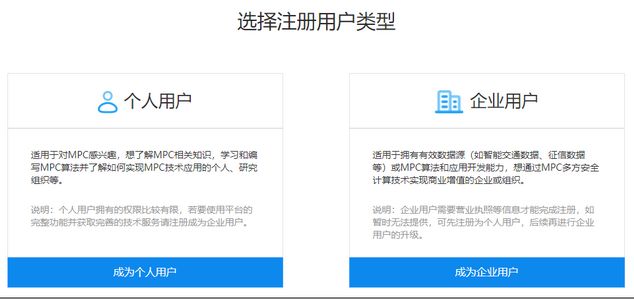
- 您可要选择注册成为个人用户或企业用户,两者区别见上图。个人用户可升级为其用户。
1.1.个人用户注册
- 注册
点击“成为个人用户”,跳转到个人用户注册页面。
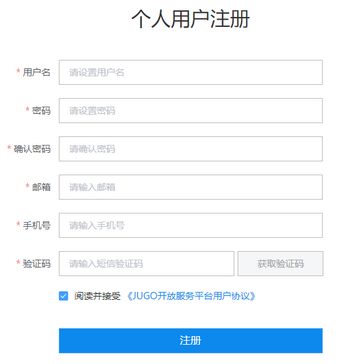
按要求填写相关信息并点击注册。其中用户名要求:用户名4-20个字符,可由英文、数字及下划线组成,字母开头。
- 生成并下载证书
注册成功后需要创建身份证书,作为参加安全多方计算的身份凭据。点击确定生成证书文件。
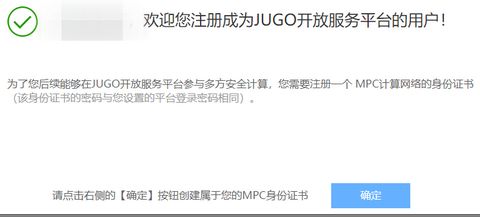
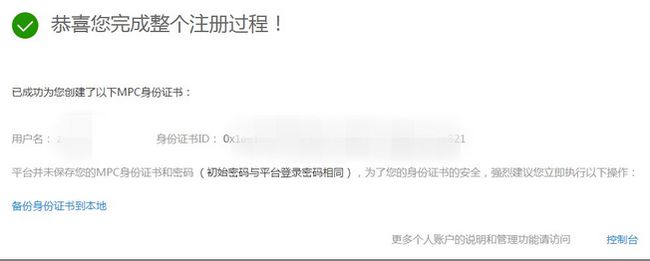
证书初始密码与您设置的账号登录密码一致,建议您及时备份到本地。
1.2.企业用户注册
- 注册
在注册页面,点击“成为企业用户”,跳转到企业用户注册页面。
注册三步:
-
基础信息填写;
-
上传企业信息;
-
信息审核。
企业信息需要JUGO开放服务平台管理员审核后,用户方可使用。
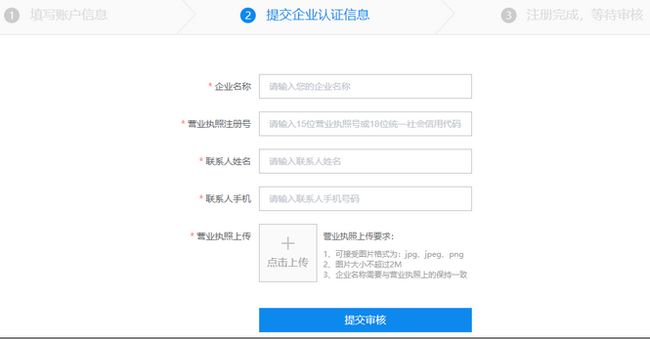
- 生成并下载证书
同1.1个人用户注册——生成并下载证书