自然语言处理(NLP):21 音乐领域NLP比赛-语义理解NER应用(小数据集BERT快速验证)
专注于文本分类、关键词抽取、文本摘要、FQA问答系统、对话系统语义理解NLU、知识图谱等。结合工业界具体案例和学术界最新研究成果实现NLP技术场景落地。本文主要分析NER 在小规模数据集下BERT上快速验证,关于完成的意图识别和槽位抽取将在后续博客中总结分享。
博客:https://wenjie.blog.csdn.net/
作者:走在前方
更多精彩内容加入“NLP技术交流群” 学习。
主要内容
-
任务描述介绍
- 领域意图识别判断
- 槽位填充
-
数据预处理
- 预料中有多种标签,我们重点关注 singer,songer 标签进行实验
-
数据可视化处理
- 整体样本统计
- 句子长度分析,提供模型输入参数max_seq_len 设置多少合适
- 数据集标签类别分布,保证数据标签式均衡的
- 针对数据可视化这里采用pyecharts ,更加清晰效果非常好
-
模型训练
- 这里仅对槽位抽签进行训练(意图部分后续考虑),典型NER任务
- 数据格式转为规定的标准格式就可以直接训练了
-
在线服务测试
- 提供API Restfull 服务(小型业务python 即可,大型借助C++,go…语言进行推测)
任务描述
对话系统是自然语言处理中一个重要的研究方向,也是人机交互的一种重要形式。其中,用户话语(utterance)可以根据意图的不同进一步分为聊天、问答、命令等。对于任务完成式系统而言,能够正确解析用户命令是完成指定任务的基础。因此,本任务主要关注口语对话系统中的命令理解问题。
音乐领域的命令理解分为两个子任务:
- 音乐领域意图判断;
- 音乐领域槽填充接下里
音乐领域意图判断
音乐领域意图判断的目标为判断用户的某条话语(utterance)是否表达了一个音乐领域内的意图。
音乐领域槽填充
用户的某条话语(utterance)被标注为音乐领域意图后,为了完成该意图,需要将该话语中提及的相关参数提取出来,在此,话语中的相关参数被称为“槽”(slot)。比如说,在音乐领域中,最常见的槽是“歌手”和“歌曲”等。将相关参数识别出来的任务,称为槽填充。
数据预处理
训练预料
标签的示例数据:(这里每个标签给出3个数据进行slot抽取)
song=['大西安', '洛阳', '刹不住']
code=['no-music', 'random']
genre=['戏曲', '流行', '古典']
artist=['龙飘飘', '陈奕迅', '陈思思']
tag=['佛歌', '吉他曲', '流行']
lyrics=['东方红太阳升', '妈妈月光之下', '一闪一闪亮晶晶']
scene=['郊游', '胎教', '春天的']
mood=['快乐', '开心', '悲伤']
language=['en', '闽南语', 'th']
album=['中国音乐', '远方', '夜色钢琴曲']
关于NER slot抽取我们选择’artist’, ‘song’,其他TAG 我们填充‘O’(这个数据集比较小,大家也可以自己标注)。我们领域是音乐类,这里artist变更singer,更容易理解
最终,我们训练NER数据格式
这里最终提取seq.in 和 seq.out 两个文件作为我们后续训练NER 的输入
数据可视化分析
分析query的长度分布,为bert超参max_seq_len 服务。我们这里借助 pyecharts 可视化工具来完成效果展示。
关于更多的pyecharts内容请参考
《Python数据可视化 pyecharts实战》
《Python数据分析案例实战 视频课程》
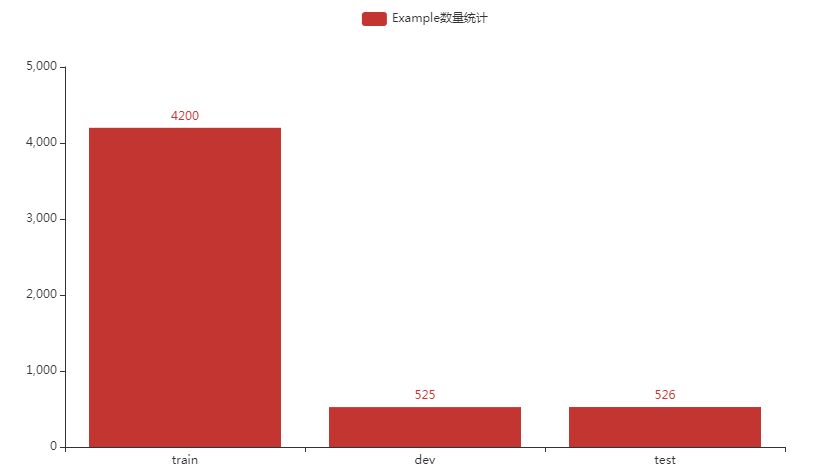
样本数量分布
样本的数据量不是很多,我们选择bert进行ner模型训练,效果如何?(后续
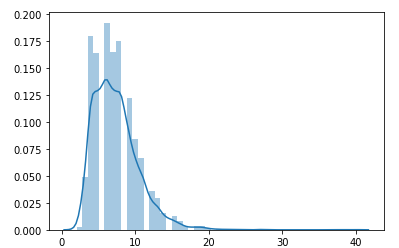
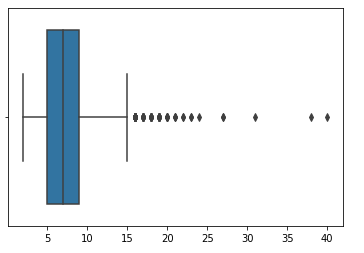
句子长度可视化分析
我们的query句子的长度可以设置max_seq_len = 16即可。
更多seaborn 可视化操作可以参考
《Python数据可视化库Seaborn》
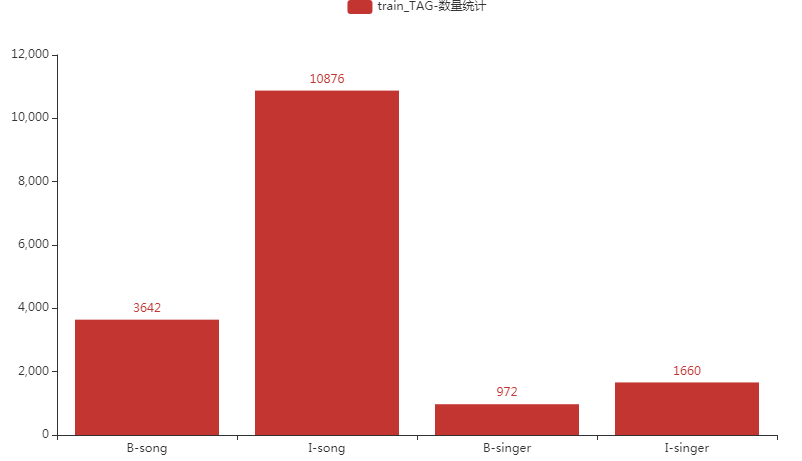
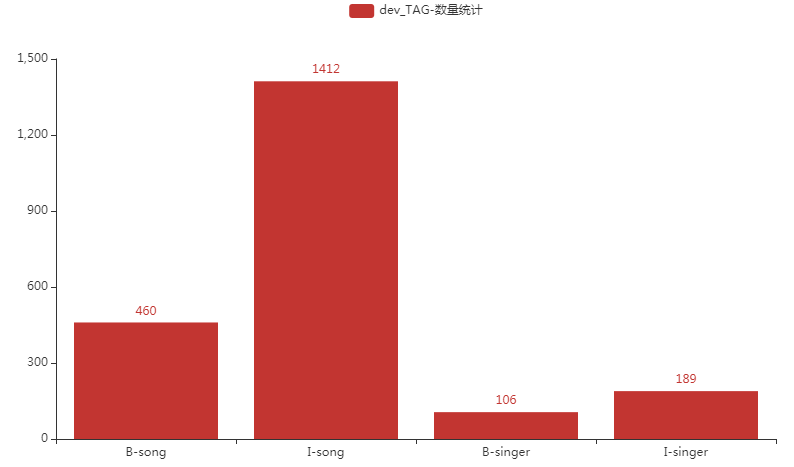
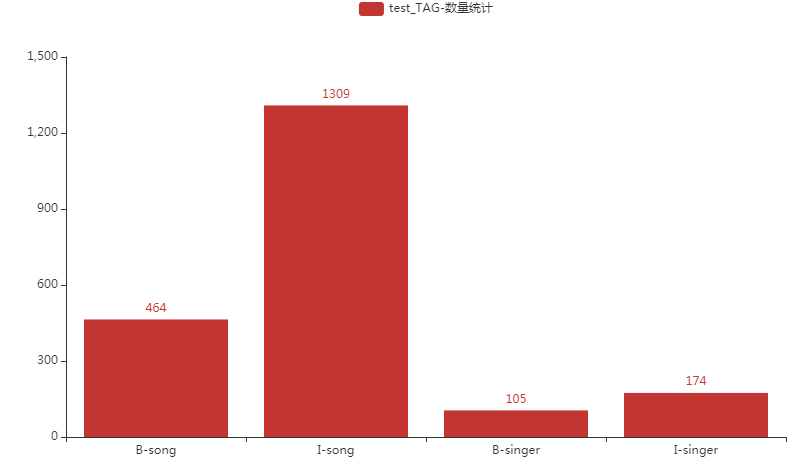
数据集标签类别分布
分别对train、dev、test数据进行标签可视化展示分析
模型训练
python3 main.py \
--model_name_or_path ../pretrained_models/bert-base-chinese/ \
--task ccks2018task2 \
--model_type bert \
--model_dir ccks2018task2_model \
--do_train --do_eval --use_crf \
--num_train_epochs 5 \
--train_batch_size 64 \
--eval_batch_size 64 \
--max_seq_len 16
下面我们截取训练过程主要日志数据,详细分析主要内容。
- bert模型输入,原始数据预处理过程
05/19/2020 13:38:20 - INFO - data_loader - guid: train-2
05/19/2020 13:38:20 - INFO - data_loader - tokens: [CLS] 我 要 听 起 床 好 。 [SEP]
05/19/2020 13:38:20 - INFO - data_loader - input_ids: 101 2769 6206 1420 6629 2414 1962 511 102 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - attention_mask: 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - slot_labels: 0 2 2 2 5 6 6 2 0 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - *** Example ***
05/19/2020 13:38:20 - INFO - data_loader - guid: train-3
05/19/2020 13:38:20 - INFO - data_loader - tokens: [CLS] 搜 索 护 花 使 者 。 [SEP]
05/19/2020 13:38:20 - INFO - data_loader - input_ids: 101 3017 5164 2844 5709 886 5442 511 102 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - attention_mask: 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - token_type_ids: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
05/19/2020 13:38:20 - INFO - data_loader - slot_labels: 0 2 2 5 6 6 6 2 0 0 0 0 0 0 0 0
- 验证数据集效果
数据量比较小,在进行第2个epoch就已经获得最后的模型了
05/19/2020 13:38:57 - INFO - train - precision recall f1-score support
song 0.89 0.93 0.91 461
singer 0.85 0.89 0.87 106
micro avg 0.88 0.92 0.90 567
macro avg 0.88 0.92 0.90 567
05/19/2020 13:38:57 - INFO - train - loss = 1.059001863002777
05/19/2020 13:38:57 - INFO - train - sementic_frame_acc = 0.900952380952381
05/19/2020 13:38:57 - INFO - train - slot_f1 = 0.8990509059534082
05/19/2020 13:38:57 - INFO - train - slot_precision = 0.8800675675675675
05/19/2020 13:38:57 - INFO - train - slot_recall = 0.9188712522045855
- 测试数据集效果
05/19/2020 13:39:18 - INFO - train - precision recall f1-score support
song 0.89 0.91 0.90 467
singer 0.91 0.94 0.93 106
micro avg 0.90 0.92 0.91 573
macro avg 0.90 0.92 0.91 573
05/19/2020 13:39:18 - INFO - train - loss = 1.171002409938309
05/19/2020 13:39:18 - INFO - train - sementic_frame_acc = 0.8954372623574145
05/19/2020 13:39:18 - INFO - train - slot_f1 = 0.9059534081104401
05/19/2020 13:39:18 - INFO - train - slot_precision = 0.8959044368600683
05/19/2020 13:39:18 - INFO - train - slot_recall = 0.9162303664921466
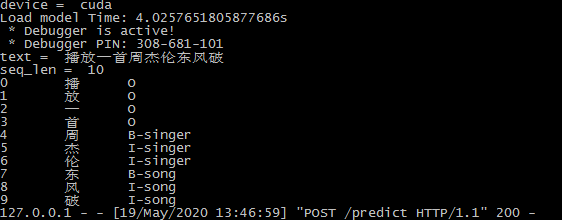
在线服务预测
- 通过api.py 启动服务
python3 api.py \
--model_name_or_path ../pretrained_models/bert-base-chinese/ \
--task ccks2018task2 \
--model_type bert \
--model_dir ccks2018task2_model \
--use_crf
- 通过命令行模式在线预测(也可以postman测试)
这里/predict/ 就是提取在线服务的一个接口。
我们发现虽然数据比较小,但是效果还不错。随着我们数据的不断增加,可以再次训练我们的模型,提升我们的效果。在gpu下推理大概13ms。(也可以尝试cpu下,效果上会慢些)。
关于性能推理是工业界追求的一个目标,有的时候为了保证线上推理速度,宁愿希望模型微小的效果,也要保证性能。
$ curl http://0.0.0.0:8000/predict \
> -H "Content-Type:application/json" \
> -X POST \
> --data '{"text": "播放一首周杰伦东风破","lang":"zh"}'
{
"errno": 0,
"errmsg": "success",
"time": 13,
"data": [
{
"word": "播",
"tag": "O"
},
{
"word": "放",
"tag": "O"
},
{
"word": "一",
"tag": "O"
},
{
"word": "首",
"tag": "O"
},
{
"word": "周",
"tag": "B-singer"
},
{
"word": "杰",
"tag": "I-singer"
},
{
"word": "伦",
"tag": "I-singer"
},
{
"word": "东",
"tag": "B-song"
},
{
"word": "风",
"tag": "I-song"
},
{
"word": "破",
"tag": "I-song"
}
]
}
- 后端日志数据
附录-扩展部分
大家可以尝试下面的方案,自己进行探索,这里不在进行详细的描述
- 规则方式抽取实体
规则方式抽取实体,是一种精确的匹配方式。对模型训练数据不足
- 训练数据扩充
自己标注或者从nlp相关的比赛获取数据