编译:将高级语言翻译成汇编语言或机器语言的过程。
源程序----预处理器----经过预处理的源程序-----编译器-----汇编语言程序-----汇编器-----可重定位的机器代码------链接器/加载器------目标机器代码。

SDT语法制导翻译
零、语言及其文法
1.字母表
正闭包
克林闭包
串
串上的运算——连接、幂运算
2.文法的定义
G=(Vt,Vn,P,S)
终结符、非终结符、产生式集合、开始符号



3.语言的定义
推导:
规约:
句型:一个句型中既可以包含终结符,又可以包含非终结符,也可能是空串。
句子:不包含非终结符的句型。
语言(L(G)):由文法G的开始符号S推导出的所有句子构成的集合称为文法G生成的语言,记为L(G)。
4.文法的分类
Chomsky
上下文无关文法(CFG)
正则文法(RG):左线性文法、右线性文法
5.CFG的分析树
推导的图形化表示。
短语:给定一个句型,其分析树的每一棵子树的边缘称为该句型的一个短语。
直接短语:如果子树只有父子两代结点,那么这棵子树的边缘称为该句型的一个直接短语。
一、词法分析
主要任务:从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型。将识别出的单词转换成统一的机内表示——词法单元(token)形式。
token:<种别码,属性值>
1.正则表达式
一种用来表示正则语言的方法。
2.正则定义
3.有穷自动机(FA)
转换图
最长子串匹配
4.有穷自动机的分类


DFA算法:
5.从正则表达式到有穷自动机
RE——》NFA——》DFA
6.从NFA到DFA的转换
子集构造法
空闭包构造
7.识别单词的DFA
识别标识符的DFA
识别无符号数的DFA
识别各进制无符号整数的DFA
识别注释的DFA
识别Token的DFA
词法分析阶段的错误处理
词法分析器的实现
一、TINY语言的特征
1.TINY语言无过程,无声明,所有变量都是整型。
2.他只有两个控制语句:if语句和repeat语句。if语句有一个可选的else部分且必须有关键字end结束
3.read和write完成输入输出
4.“{”和“}”中的语句为注释,但注释不能嵌套
程序清单1是该语言的一个求阶乘的示例
程序清单1:
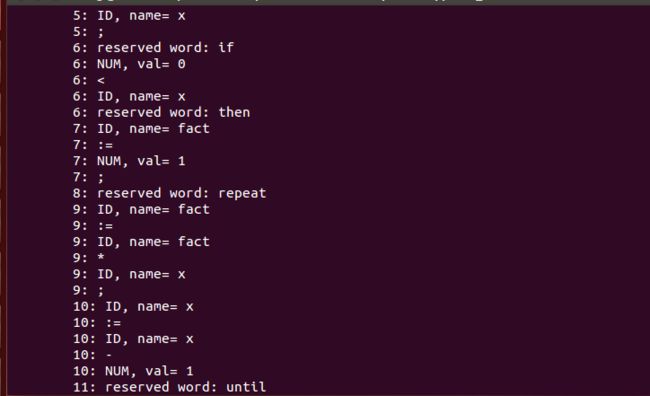
{ Sample program in TINY language - computes factorial } read x; { input an integer } if 0 < x then { don't compute if x <= 0 } fact := 1; repeat fact := fact * x; x := x - 1 until x = 0; write fact { output factorial of x } end
二、开发环境
Ubuntu,使用lex进行词法分析
三、词法分析
1.关键字:if,then,else,end,repeat,until,read,write
所有的关键字都是保留字,且全部小写。
2.专用符号:+ - * / = < ( ) ; :=
3.其他标记是ID和NUM,通过下列正则表达式定义:
letter = [a-zA-Z]
digit = [0-9]
实现: