pinot架构
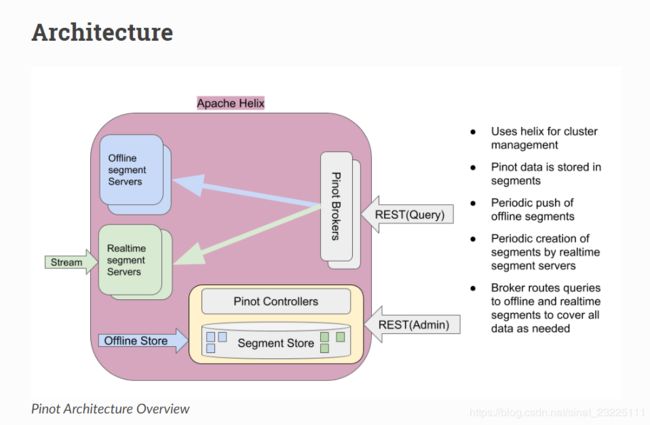
以下信息翻译自官网pinot架构部分:
表: 表是引用相关数据集合的逻辑抽象。它由列和行(文档)组成。
段: 表中的数据被分成(水平的)分片,称为段
Pinot 组件
1、Pinot Controller
管理其他pinot组件(代理、服务器)以及控制将表/段分配给服务器。
2、Pinot Server
托管一个或多个段,并为来自这些段的查询提供服务
3、Pinot Broker
接受来自客户机的查询并将其路由到一个或多个服务器,并向客户机返回综合响应。
Pinot利用Apache Helix进行集群管理。Helix是一个集群管理框架,用于管理分布式系统中复制的、分区的资源。Helix使用Zookeeper存储集群状态和元数据。
简单地说,Helix根据节点的职责将节点分为三个逻辑组件:
Helix的架构
Participant
承载分布式、分区资源的节点
Spectator
观察每个参与者的当前状态并使用该信息访问资源的节点。旁观者会被告知集群中的状态变化(参与者的状态,或者参与者的分区的状态)。
Controller
观察和控制Participant节点。它负责协调集群中的所有转换,并确保在保持集群稳定性的同时满足状态约束
Pinot的 Controller 托管Helix Controller,此外还托管用于Pinot集群管理和数据摄取的REST api。可以有多个Pinot控制器实例来实现冗余。如果有多个控制器,那么Pinot希望所有的控制器都配置为相同的后端存储系统,这样它们就可以拥有段的公共视图(例如,NFS)。Pinot可以使用其他存储系统,如HDFS或ADLS。
Pinot的 Servers 被建模为Helix的Participant,托管Pinot表(在Helix术语中称为资源)。表的 segment被建模为(资源的)Helix分区。因此,Pinot服务器承载一个或多个helix资源的一个或多个helix分区(即一个或多个表的一个或多个段)。
Pinot 的 Brokers可理解为Helix的 Spectators。它们需要知道表的每个 segment (以及每个segment 的副本)的位置,并将请求路由到托管被查询的表的各个段的适当服务器。 broker 确保只查询一次表中的所有行,以便返回正确、一致的查询结果。只要精度不满足, brokers (或 servers)可以进行优化以删除某些段。对于混合表, brokers 确保实时段数据和离线段数据之间的重叠只查询一次。 Helix提供了一个框架,通过该框架,旁观者可以了解资源的每个分区所在的位置(即 participant)。 broker使用此机制来了解承载特定表的 segments 的 brokers
Pinot 的表
Pinot支持实时、离线或混合表。Pinot表中的数据包含在属于该表的 segments 中。Pinot表被建模为一个 Helix 的资源。表的每个 segment 都被建模为一个 Helix 的分区。
表的 Schema 定义列名及其元数据。表配置和Schema 存储在zookeeper中。
离线表从外部数据存储中摄取预构建的pinot段,而实时表从流式框架(如Kafka) 中摄取数据并构建segments。
混合的Pinot表本质上同时具有实时表和离线表。在这样的表中,离线的 segments 可以被周期性地推送(比如,一天一次)。离线表上的保留可以设置为一个高值(比如几年),因为段是定期进入的,而实时表上的保留可以很小(比如几天) 一旦将一个离线 segment 推送去覆盖最近的时间段, brokers 就会在那个时间段自动切换去使用离线表的segment ,并且使用realtime表来覆盖离线 segments 还不可用的稍后的 segments 。
注意,查询不知道离线表或实时表的存在。它只指定查询中的表名
有关如何根据需求自定义表配置,请参阅表配置一节。
Ingesting Offline data
离线表的 Segments 是在Pinot之外构建的,通常是在Hadoop中通过map-reduce作业构建,然后通过 Controller提供的REST API摄取到Pinot中。Pinot提供了一些库,用于在hadoop作业中从AVRO、JSON或CSV格式的输入文件中创建Pinot的 segments ,并通过REST api将构建的 segments 推给 controllers 。
当接收到离线的 segment 时, controller 查找该表的配置并将该 segment 分配给承载该表的服务器。它可以根据为该表配置的副本数量为每个段分配多个服务器。
Pinot支持针对不同用例进行优化的不同 segment 分配策略。
一旦分配了 segments ,Pinot服务器就会通过Helix来“托管”这个 segment。服务器下载 segments (作为缓存的本地副本提供查询)并将其加载到本地内存中。只要服务器托管该段,所有段数据都在内存中维护。
一旦服务器加载了 segment,Helix就会通知 brokers 这些 segments的可用性。 brokers 开始包含用于查询的新段。根据表的类型、段分配策略和用例, Brokers 支持不同的路由策略。
离线 segments 中的数据是不可变的(不能添加、删除或修改行)。但是,段可以用修改后的数据替换。
Ingesting Realtime Data
实时表的 Segments 由Pinot servers 构建,其中的行来自Kafka等数据流。从流中获取的行一旦被获取,就可以立即用于查询处理,从而支持需要实时图表分析的应用程序。
在大规模安装中,流中的数据通常被多个流分区分割。底层流可能提供消费者实现,该实现允许应用程序使用来自分区的任何子集的数据,包括所有分区(或仅来自一个分区)。
pinot表可以配置为在两种模式中使用流:
LowLevel: 这是首选的消费方式。Pinot为每个分区创建独立的分区级消费者。根据配置的副本数量,可以为每个分区创建多个使用者,确保同一服务器主机上不存在两个副本。因此,您需要至少提供与配置的replcias数量相同的主机。
HighLevel: Pinot创建一个从所有分区消费的流级消费者。所使用的每个消息可以来自流的任何分区。根据配置的副本数量,将创建多个流级别的使用者,以确保同一服务器主机上不存在两个副本。因此,您需要提供与配置的副本数量相同的主机。
当然,底层流应该支持任何一种消费模式,以便Pinot表使用这种模式。Kafka支持这两种模式。有关在Pinot中支持其他数据流的更多信息,请参见可插流。
在任何一种模式下,Pinot服务器都将摄取的行存储在易失性内存中,直到满足以下条件之一:
1、消费了一定数量的行
2、这种消费持续了一段时间
在达到这些限制之一,服务器做以下工作:
暂停消费
将到目前为止使用的行保存到非易失性存储中
继续在易失性内存中使用新行。
持久化的行形成了我们所称的完整 segment (与驻留在易失性内存中的消费 segment 相反)。
在 LowLevel 模式下,完成的 segments 被持久化到pinot服务器的本地非易失性存储和pinot集群的 segments 存储中(参见pinot架构概述)。这使得替换pinot服务器或扩展容量等的机制变得简单和自动化。Pinot有特殊的机制,可以确保完成的 segments 在所有副本之间是等价的。
在segments 完成期间, controller 从提交服务器的所有副本中选择一个获胜者。提交者服务器构建 segment 并将其上传到 controller。所有其他非提交服务器遵循这两条路径之一:
1、如果内存中的segment 与提交的segment 等价,那么非提交服务器也会在本地构建该段并替换内存中的段
2、如果内存中的segment 与提交的segment 不等效,则非提交服务器将从控制器下载该segment 。
在 HighLevel 模式下,服务器将使用的行保存到本地存储(而不是 segment 存储)。由于行消耗可以来自任何分区,因此不可能保证跨副本的段的等价性。
Pinot Segments
segment 以柱状格式显示,因此可以直接将其映射到内存中,以便为查询提供服务。
列可以是单值的,也可以是多值的。列类型可以是STRING、INT、LONG、FLOAT、DOUBLE或BYTES。可以将列声明为模式中的度量或维度(或具体地说,作为时间维度)。列可以有默认的空值。例如,整数列的默认空值可以是0。注意:在添加到模式之前,byte列的默认值必须是十六进制编码的。
Pinot使用字典编码将值存储为字典ID。列可以配置为“no-dictionary”列,在这种情况下存储原始值。字典ID的编码使用的是有效存储的最小位数(例如,一个基数为3的列将只对每个字典ID使用3位)。
每个列都有一个前向索引,并进行了适当的压缩,以便有效地使用内存。此外,可以为任何一组列配置可选的反向索引。反向索引虽然占用更多的存储空间,但提供了更好的查询性能。
还支持星型树索引之类的专门索引。