Bert改进模型汇总(4)
目录
ALBert
Intro
Factorized embedding parameterization
Cross-layer parameter sharing
Sentence Order Prediction(SOP)
Electra:Efficiently Learning an Encoder that Classifies Token Replacements Accurately
Reference
ALBert
论文地址 https://openreview.net/pdf?id=H1eA7AEtvS
GitHub(非官方中文预训练ALBERT) https://github.com/brightmart/albert_zh
Intro
最近各种大体量的预训练模型层出不穷,经常是一个出来刷榜没几天,另外一个又出现了。BERT、RoBERTa、XLNET等等都是代表人物。这些“BERT”们虽然一个比一个效果好,但是他们的体量都是非常大的,懂不懂就几千万几个亿的参数量,而且训练也非常困难。新出的ALBERT就是为了解决模型参数量大以及训练时间过长的问题。ALBERT最小的参数只有十几M, 效果要比BERT低1-2个点,最大的xxlarge也就200多M。可以看到在模型参数量上减少的还是非常明显的,但是在速度上似乎没有那么明显。最大的问题就是这种方式其实并没有减少计算量,也就是受推理时间并没有减少,训练时间的减少也有待商榷。
Factorized embedding parameterization
原始的BERT模型以及各种依据transformer来搞的预训练语言模型在输入的地方我们会发现它的E是等于H的,其中E就是embedding size,H就是hidden size,也就是transformer的输入输出维度。这就会导致一个问题,当我们的hidden size提升的时候,embedding size也需要提升,这就会导致我们的embedding matrix维度的提升。所以这里作者将E和H进行了解绑,具体的操作其实就是在embedding后面加入一个矩阵进行维度变换。E是永远不变的,后面H提高了后,我们在E的后面进行一个升维操作,让E达到H的维度。这使得embedding参数的维度从O(V×H)到了O(V×E + E×H), 当E远远小于H的时候更加明显。
Cross-layer parameter sharing
跨层参数共享,就是不管12层还是24层都只用一个transformer。之前transformer的每一层参数都是独立的,包括self-attention 和全连接,这样的话当层数增加的时候,参数就会很明显的上升。之前有工作试过单独的将self-attention或者全连接进行共享,都取得了一些效果。这里作者尝试将所有的参数进行共享,这其实就导致多层的attention其实就是一层attention的叠加。
Sentence Order Prediction(SOP)
这里作者使用了一个新的loss,其实就是更改了原来BERT的一个子任务NSP, 原来NSP就是来预测下一个句子的,也就是一个句子是不是另一个句子的下一个句子。这个任务的问题出在训练数据上面,正例就是用的一个文档里面连续的两句话,但是负例使用的是不同文档里面的两句话。这就导致这个任务包含了主题预测在里面,而主题预测又要比两句话连续性的预测简单太多。新的方法使用了sentence-order prediction(SOP), 正例的构建和NSP是一样的,不过负例则是将两句话反过来。实验的结果也证明这种方式要比之前好很多。但是这个这里应该不是首创了,百度的ERNIE貌似也采用了一个这种的。
SOP 目标补偿了一部分因为 embedding 和 FFN 共享而损失的性能。Bert 原版的 NSP 目标过于简单了,它把”topic prediction”和“coherence prediction”融合了起来。SOP 对其加强,将负样本换成了同一篇文章中的两个逆序的句子,进而消除“topic prediction”。
Electra:Efficiently Learning an Encoder that Classifies Token Replacements Accurately
论文地址 https://openreview.net/pdf?id=r1xMH1BtvB
ELECTRA的全称是Efficiently Learning an Encoder that Classifies Token Replacements Accurately,先来直观感受一下ELECTRA的效果:
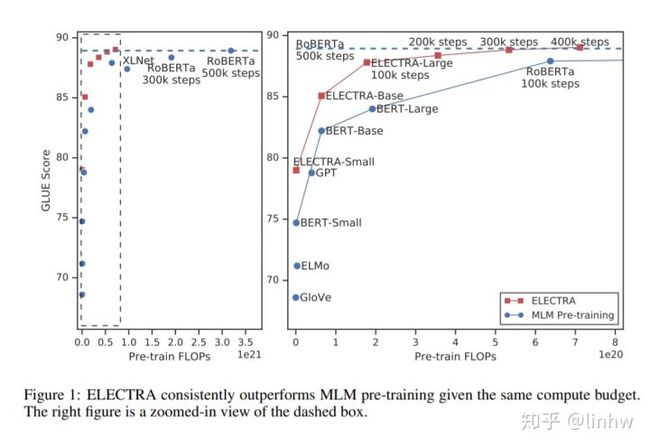
ELECTRA最主要的贡献是提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
作者提出的预训练模型如下图所示,包括了一个Generator和一个Discriminator,在预训练模型的训练中,需要训练两个神经网络。一个生成器G,一个分类器D,对于生成网络G,对于给定的输入x,生成网络在t位置按照下述方式生成输出token的xt。其中e是token对应的embedding。
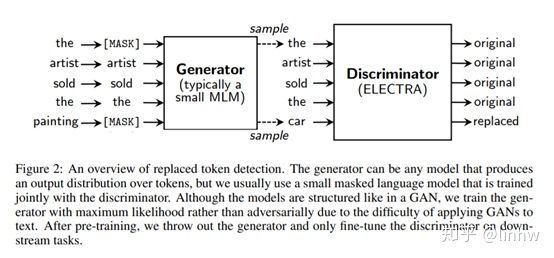
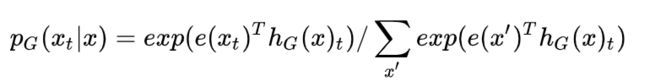
而对于给定位置t的token,鉴别器需要去鉴别这个单词是否经过替换。

生成器模型G会扮演一个MLM模型,对于给定的token输入x=[x1,x2,x3..xn],它会选择一些位置,并且将token替换成[mask],然后生成器会开始学习预测这个masked的元素。并且生成自己的预测结果,并且生成句子。
但上述结构有个问题,输入句子经过生成器,输出改写过的句子,因为句子的字词是离散的,所以梯度在这里就断了,判别器的梯度无法传给生成器,于是生成器的训练目标还是MLM(作者在后文也验证了这种方法更好),判别器的目标是序列标注(判断每个token是真是假),两者同时训练,但判别器的梯度不会传给生成器,目标函数如下:
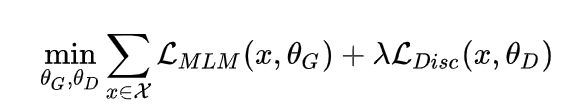
除了上述的基本模型以外,作者在训练中还增加了下述的方法:
Weight Sharing
生成器和判别器的权重共享是否可以提升效果呢?作者设置了相同大小的生成器和判别器,在不共享权重下的效果是83.6,只共享token embedding层的效果是84.3,共享所有权重的效果是84.4。作者认为生成器对embedding有更好的学习能力,因为在计算MLM时,softmax是建立在所有vocab上的,之后反向传播时会更新所有embedding,而判别器只会更新输入的token embedding。最后作者只使用了embedding sharing。
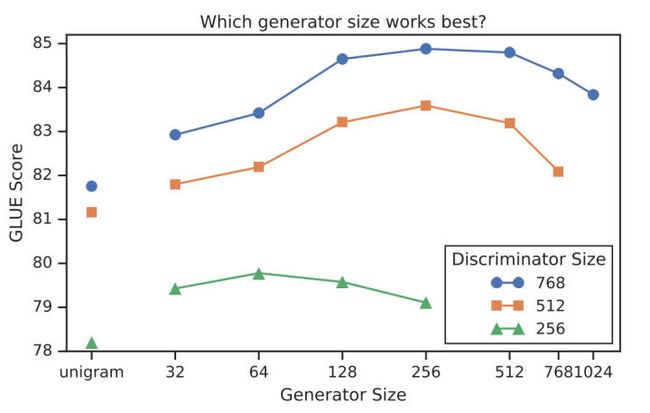
Smaller Generators
从权重共享的实验中看到,生成器和判别器只需要共享embedding的权重就足矣了,那这样的话是否可以缩小生成器的尺寸进行训练效率提升呢?作者在保持原有hidden size的设置下减少了层数,得到了下图所示的关系图:
可以看到,生成器的大小在判别器的1/4到1/2之间效果是最好的。作者认为原因是过强的生成器会增大判别器的难度(判别器:小一点吧,我太难了)。
训练算法:除了文中上述的两种方法,作者还实验了另外两种训练算法:
- Adversarial Contrastive Estimation:ELECTRA因为上述一些问题无法使用GAN,但也可以以一种对抗学习的思想来训练。作者将生成器的目标函数由最小化MLM loss换成了最大化判别器在被替换token上的RTD loss。但还有一个问题,就是新的生成器loss无法用梯度上升更新生成器,于是作者用强化学习Policy Gradient的思想,最终优化下来生成器在MLM任务上可以达到54%的准确率,而之前MLE优化下可以达到65%。
- Two-stage training:即先训练生成器,然后freeze掉,用生成器的权重初始化判别器,再接着训练相同步数的判别器。
Reference
如何看待瘦身成功版BERT——ALBERT?
ALBERT 论文解读
超越bert,最新预训练模型 ELECTRA 论文阅读笔记
ELECTRA: 超越BERT, 19年最佳NLP预训练模型