模型融合在kaggle比赛中的几种常见应用
目录
1.群众的力量是伟大的 — 集体智慧
1)Voting投票器
2)Averaging
3)Bagging
3)随机森林(Random forest)
2.站在巨人的肩膀上 — 层叠式递进
1)Blending
2)Stacking
3.一万个小时定律 — 熟能生巧
Boosting
总结
近年来,随着人工智能、机器学习的快速发展,大数据类的机器学习竞赛越来越多,国外的kaggle国内的天池都是举办此类比赛的重要平台,但是要想在这些比赛中脱颖而出获得丰厚奖金则是非常困难的,尤其是不用模型融合就能拿到奖金几乎是不可能的。今天我们就来聊一聊模型融合的几种常见方式。
模型融合简单来说就是通过对一组的基分类器以某种方式进行组合,以提升模型整体性能的方法。当然,模型融合不能起到决定性作用,在影响模型结果的因素中,一般来说是数据>特征>模型>模型融合。在业界流传着这么一句话,数据和特征决定了机器学习的上限,而模型和算法只是在逼近这个上限而已。所以,无论是在比赛中还是在处理实际问题的时候特征工程无疑是非常重要的,在数据和特征都无法提升比赛成绩的时候,模型融合或许就能派上用场了。
模型融合的三种信条:
1.群众的力量是伟大的 — 集体智慧
1)Voting投票器
Voting可以说是一种最为简单的模型融合方式。假如对于一个二分类模型,有3个基础模型,那么就采取投票的方式,投票多者为最终的分类。
Voting即投票机制,分为软投票和硬投票两种,其原理采用少数服从多数的思想。
硬投票:对多个模型直接进行投票,最终投票数最多的类为最终被预测的类。
软投票:和硬投票原理相同,增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
备注:此方法用于解决分类问题。
在sklearn实现如下:
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)])
eclf = eclf1.fit(x_train,y_train)
print(eclf1.predict(x_test))2)Averaging
Averaging,其原理是对模型结果取平均。
处理回归问题,直接取平均值作为最终的预测值。(也可以使用加权平均)
平均法存在问题就是:如果不同回归方法的预测结果波动幅度相差比较大,那么波动小的回归结果在融合时候起的作用就比较小。
3)Bagging
Bagging的思想是利用抽样生成不同的训练集,进而训练不同的模型,将这些模型的输出结果综合(投票或平均的方式)得到最终的结果。Bagging本质上是利用了模型的多样性,改善算法整体的效果。Bagging的重点在于不同训练集的生成,这里使用了一种名为Bootstrap的方法,即有放回的重复随机抽样,从而生成不同的数据集。具体流程如下图所示:

Bagging方法的出现,可以完美地解决了决策树过拟合的问题,同时bagging的使用也会使分类器分类效果得到了显著的提高。
应用场景:对不稳定的分类器做Bagging是一个好主意。在机器学习中,如果训练数据的一个小变化导致学习中的分类器的大变化,则该算法(或学习算法)被认为是不稳定的。
Bagging就是采用有放回的方式进行抽样,用抽样的样本建立子模型,对子模型进行训练,这个过程重复多次,最后进行融合。大概分为两步:
- 重复K次有放回地抽样建模,训练子模型。
- 模型融合:如果是分类问题用voting解决 。如果是回归问题用average解决。
在sklearn实现如下:
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
model1=DecisionTreeClassifier(max_depth=5)
model2=BaggingClassifier(model1,n_estimators=100,max_samples=0.3)
model2.fit(x_train,y_train)
print (model2.predict(x_test))3)随机森林(Random forest)
随机森林实际上就是Bagging算法的进化版,不同于Bagging算法的是,Bagging产生不同数据集的方式只是对行利用有放回的随机抽样,而随机森林产生不同数据集的方式不仅对行随机抽样也对列进行随机抽样。
在sklearn实现如下:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf.fit(x_train, y_train)
print(clf.feature_importances_)
print(clf.predict(x_test))2.站在巨人的肩膀上 — 层叠式递进
1)Blending
Blending主要是用不相交的数据训练不同的基础模型,将他们的输出取(加权)平均。Blending分为Uniform blending和Linear blending,前者在分类时使用一人一票的投票方式,回归时采用多个模型的平均值。后者是二次学习,使用线性模型将第一步中学习到的学习器的输出结果组合起来。相当于简化版的Stacking。
Bending是一种模型融合方法,主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。第一层我们在这70%的数据上训练多个模型,然后去预测那30%数据的label。在第二层里,我们就直接用这30%数据在第一层预测的结果做为新特征继续训练即可。
Blending的优点在于:
- 比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
- 避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
而缺点在于:
- 使用了很少的数据(第二阶段的blender只使用training set10%的量)
- blender可能会过拟合
- stacking使用多次的交叉验证会比较稳健
对于实践中的结果而言,stacking和blending的效果是差不多的,所以使用哪种方法都没什么所谓,完全取决于个人爱好。
2)Stacking
Stacking背后的基本思想是使用大量基分类器,然后使用另一种分类器来融合它们的预测结果,旨在降低泛化误差。Stacking算法分为2层,第一层是用不同的算法形成T个基础分类器,同时产生一个与原数据集大小相同的新数据集,利用这个新数据集和一个新算法构成第二层的分类器。在训练第二层分类器时采用各基础分类器的输出作为输入,第二层分类器的作用就是对基础分类器的输出进行集成。但是由于Stacking模型复杂度过高,比较容易造成过拟合。流程图如下所示:

下面放几张清晰的分步流程图。
首先,我们从stacking模型的训练开始阐述。在下图中我们可以看到,该模型的第一层有五个分类模型,第二层有一个分类模型。在第一层中,对于不同的分类模型,我们分别将训练数据分为 5 份,接下来迭代5次。每次迭代时,将 4 份数据作为训练集对每个分类模型进行训练,然后剩下一份数据在训练好的分类模型上进行预测并且保留结果。当5次迭代都完成以后,我们就获得了一个结果矩阵。该矩阵是一个N*1的矩阵,N是训练集的样本数。当5个模型都进行完上述操作后,我们就可以得到一个N*5的结果矩阵。然后将该矩阵导入到第二层的模型中进行训练,此时全部模型训练完毕。训练过程:

接下来我们开始阐述该模型的预测过程。在第一层中,对于不同分类模型,我们还是使用在训练时分成的5份训练数据进行五次迭代。每次迭代时,我们利用训练后的分类模型对预测集进行预测并保留下来。当5次迭代都完成以后,我们可以得到一个M*5的矩阵,M是预测集的样本数。 我们将这个矩阵按列取平均,缩减成M*1的矩阵。当5个模型都进行完上述操作后,我们就可以得到一个M*5的结果矩阵。然后将该矩阵导入到第二层中训练好的模型进行预测,就可以得到最终的预测结果。测试过程:

stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型。stacking两层模型都使用了全部的训练数据。
第一层模型:
首先数据有训练集和测试集两部分
- 对训练集进行五折交叉验证,把训练集划分为A,B两部分
- 对A部分进行训练,对B部分进行预测,得到a1,五折后则为a1,a2,a3,a4,a5,对他们合并,形成n行一列的数据
- 对测试集进行预测,会得到b1,b2,b3,b4,b5,将各部分相加取平均得到m行一列的数据
- 以上是一个模型,如果有三个模型,则可以得到A1,A2,A3,B1,B2,B3
- 在此之后,我们把A1、A2、A3并列合并得到一个n行三列的矩阵作为training data,B1、B2、B3并列合并得到一个m行三列的矩阵作为testing data,让下一层的模型基于他们进一步训练。

3.一万个小时定律 — 熟能生巧
Boosting
Boosting是一种提升算法,其思想是在算法迭代过程中,每次迭代构建新的分类器,重点关注被之前分类器分类错误的样本,如此迭代,最终加权平均所有分类器的结果,从而提升分类精度。Boosting与Bagging相比来说最大的区别就是Boosting是串行的,而Bagging中所有的分类器是可以同时生成的(分类器之间无关系),而Boosting中则必须先生成第一个分类器,然后依次往后进行。核心思想是通过改变训练集进行有针对性的学习,通过每次更新迭代,增加错误样本的权重,减小正确样本的权重。知错就改,逐渐变好。典型应用为:Adaboost、GBDT和Xgboost。流程图如下所示:

下面引用一个Boosting的例子:

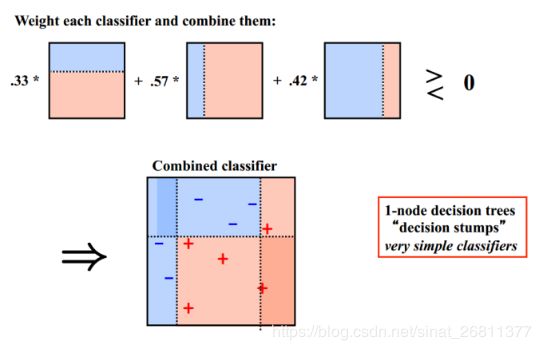
Boosting的思想是一种迭代的方法,它每次训练使用的都是同一个训练集。但是每次它会给这些分类错误的样例增加更大的权重,下一次迭代的目标就是能够更容易辨别出上一轮分类错误的样例。最终将这些弱分类器进行加权相加。
注意:Boosting下一次的迭代必须在上一次的基础上。
总结
我们发现,在比赛中获得名次较高的队伍都不同程度的使用了模型融合方法。尤其是在kaggle或天池这样的比赛中,排名靠前的队伍大都使用了像Xgboost、Lightgbm这样的Boosting算法,进而对这些模型的输出结果进行Bagging、Blending或Stacking,最终取得不错的成绩。因此,如果想要在kaggle或天池这样的平台比赛中胜出,在做好特征工程的同时也要用好模型融合这个杀手锏。