Recorder︱图像语义分割(FCN、CRF、MRF)、论文延伸(Pixel Objectness、)
图像语义分割的意思就是机器自动分割并识别出图像中的内容,我的理解是抠图…
之前在Faster R-CNN中借用了RPN(region proposal network)选择候选框,但是仅仅是候选框,那么我想提取候选框里面的内容,就是图像语义分割了。
简单的理解就是,图像的“分词技术”。
参考文献:
1、知乎,困兽,关于图像语义分割的总结和感悟
2、微信公众号,沈MM的小喇叭,十分钟看懂图像语义分割技术
.
.
一、FCN全卷积:Fully Convolutional Networks
一些简单的名词,下采样=卷积+池化(像素缩小),
上采样=反卷积(像素放大)Caffe和Kera里叫Deconvolution,而tensorflow里叫conv_transpose。CS231n这门课中说,叫conv_transpose更为合适。
- 卷积与反卷积过程:

- 池化与上池化:

池化层作用:池化操作能够减少计算量,同时也能防止计算结果过拟合
上池化作用:上池化的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0即OK。
1、反卷积
那么反卷积是一种认识”卷积“是什么的好办法。反卷积可以在任何卷积层上进行。那么得到的图像就是一些缩略图形式。

每一种反卷积的样子:

可以发现卷积程度越高,32x图像越模糊,8x跟ground truth还是挺接近的。这里就是感受野(receptive field),8x感受野较小,适合感受细节;32x感受野较大,适合感受宏观。
.
.
2、“带hole”的卷积——Dilated Convolutions
简单的卷积过程有一些问题:精度问题,对细节不敏感,以及像素与像素之间的关系,忽略空间的一致性等问题。那么新卷积方式hole卷积,用hole卷积核取代池化。
Dilated Convolutions:没有了池化感受野就不会变大,“疏松的卷积核”来处理卷积,可以达到在不增加计算量的情况下增加感受域,弥补不进行池化处理后的精度问题。
操作方式:人为加大了卷积核内部元素之间的距离:

这是水平X轴方向上的扩展,在Y轴上也会有同样的扩展,感受域在没有增加计算(相对于池化操作后)的情况下增大了,并且保留了足够多的细节信息,对图像还原后的精度有明显的提升。

.
.
.
3、DenseCRF Conditional Random Field:全连接条件随机场(DenseCRF)
每个像素点作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。
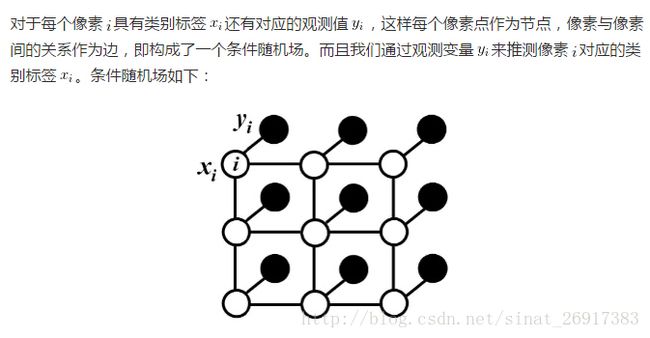
其中:yi:卷积后的值;i:像素;xi:类别标签
条件随机场符合吉布斯分布。
在全链接的 CRF 模型中,有一个对应的能量函数:

那么E(x)由两个部分组成,可以简单理解为:
E(x)=一元函数+二元函数
一元函数:来自于前端FCN的输出
二元函数:是描述像素点与像素点之间的关系,鼓励相似像素分配相同的标签,而相差较大的像素分配不同标签,而这个“距离”的定义与颜色值和实际相对距离有关。所以这样CRF能够使图片尽量在边界处分割。
全连接条件随机场的不同就在于,二元势函数描述的是每一个像素与其他所有像素的关系,所以叫“全连接”。
通过对这个能量函数优化求解,把明显不符合事实识别判断剔除,替换成合理的解释,得到对FCN的图像语义预测结果的优化,生成最终的语义分割结果。

4、马尔科夫随机场(MRF)
在Deep Parsing Network中使用的是MRF,它的公式具体的定义和CRF类似,只不过作者对二元势函数进行了修改:
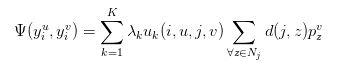
其中,作者加入λk为label context,因为只是定义了两个像素同时出现的频率,而λk可以对一些情况进行惩罚。
比如,人可能在桌子旁边,但是在桌子下面的可能性就更小一些。所以这个量可以学习不同情况出现的概率。
而原来的距离d(i,j)只定义了两个像素间的关系,作者在这儿加入了个triple penalty,即还引入了j附近的z,这样描述三方关系便于得到更充足的局部上下文。
5、高斯条件随机场(G-CRF)
这个结构使用CNN分别来学习一元势函数和二元势函数。
.
.
二、一些成型的分割结构
知乎,困兽,关于图像语义分割的总结和感悟在文中提到通用框架:
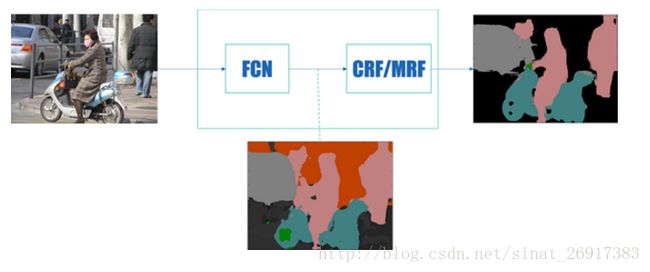
前端使用FCN进行特征粗提取,后端使用CRF/MRF优化前端的输出,最后得到分割图。
1、“Normalized cut”的图划分方法
它的思想主要是通过像素和像素之间的关系权重来综合考虑,根据给出的阈值,将图像一分为二。在实际运用中,每运行一次N-cut,只能切割一次图片,为了分割出图像上的多个物体,需要多次运行,下图示例了对原图a进行7次N-cut后,每次分割出的结果。

2、Grab Cut
增加了人机交互,在分割过程中,需要人工干预参与完成。需要人工选择主体候选框,然后将中部作为主体参考,然后剔除和主体差异较大的部分,留下结果。

此技术中,抠出来的部分叫“前景”,剔除的部分叫“背景”。缺点也很明显,首先,它同N-cut一样也只能做二类语义分割,说人话就是一次只能分割一类,非黑即白,多个目标图像就要多次运算。其次,它需要人工干预,这个弱点在将来批量化处理和智能时代简直就是死穴。
3、segNet

4、DeconvNet

这样的对称结构有种自编码器的感觉在里面,先编码再解码。这样的结构主要使用了反卷积和上池化。
5、DeepLab
现在的很多改进是基于这个网络结构的进行的。
为了保证之后输出的尺寸不至于太小,FCN的作者在第一层直接对原图加了100的padding,可想而知,这会引入噪声。
DeepLab非常优雅的做法:将pooling的stride改为1,再加上 1 padding。这样池化后的图片尺寸并未减小,并且依然保留了池化整合特征的特性。
因为池化层变了,后面的卷积的感受野也对应的改变了,这样也不能进行fine-tune了。所以,Deeplab提出了一种新的卷积,带孔的卷积:Atrous Convolution.
.
延伸一:Pixel Objectness —— 更好的自动抠图、图像检索、图像重定向技术
论文《Pixel Objectness》提出了一个用于前景对象分割的端到端学习框架。给定一个单一的新颖图像,我们的方法为所有“像对象”区域 - 即使对于在训练期间从未见过的对象类别,产生像素级掩码。我们将任务制定为使用深完全卷积网络实现的将前景/背景标签分配给每个像素的结构化预测问题。
我们的想法的关键是采用训练与图像级对象类别示例,以及采用相对较少的注释的边界级图像合。我们的方法大大改善了ImageNet和MIT数据集上的前景分割的最先进的水平 - 在某些情况下,有19%的绝对改进。此外,在超过100万的图像,我们显示它很好地归纳到用于训练的前景地图中看不见的对象类别。
最后,我们演示了我们的方法如何有利于图像检索和图像重定向,这两种方法在给定的高质量前景图的领域将会有好的效果。
论文成果在caffe有成品案例
github:https://github.com/suyogduttjain/pixelobjectness
paper:https://arxiv.org/abs/1701.05349
官方网址:http://vision.cs.utexas.edu/projects/pixelobjectness/
.
延伸二:一些前沿方法
来源于:PaperWeekly 第28期 | 图像语义分割之特征整合和结构预测
1、多尺度整合
这个方法在前一段时间是 PASCAL VOC 2012 排行榜上的第一,现在的第二。
语义分割中常见问题
关系不匹配(Mismatched Relationship)
场景中存在着可视模式的共现。比如,飞机更可能在天上或者在跑道上,而不是公路上。
易混淆的类别(Confusion Categories)
许多类别具有高度相似的外表。
不显眼的类别(Inconspicuous Classes)
场景中包括任意尺寸的物体,小尺寸的物体难以被识别但是有时候对于场景理解很重要。
Note: 这些大多数错误都部分或者完全和上下文关系以及全局信息有关系,而 PSPNet 就是为了整合不同区域的 context 来获取全局的 context 信息。
其中的一些 tricks:
图片输入的 CNN 是 ResNet,使用了 dilated convolution
Pyramid Pooling Module 中的 conv 是1×1的卷积层,为了减小维度和维持全局特征的权重
Pyramid Pooling Module 中的 pooling 的数量以及尺寸都是可以调节的
上采样使用的双线性插值
poly learning rate policy
数据扩增用了:random mirror, random resize(0.5-2), random rotation(-10 到 10 度), random Gaussian blur
选取合适的 batchsize
2、多级整合——RefineNet
这个方法在前一段时间是 PASCAL VOC 2012 排行榜上的第三,现在的第四。本方法主要想解决的限制是:多阶段的卷积池化会降低最后预测结果图片的尺寸,从而损失很多精细结构信息。
现有方法的解决办法:
反卷积作为上采样的操作
反卷积不能恢复低层的特征,毕竟已经丢失了
Atrous Convolution (Deeplab提出的)
带孔卷积的提出就是为了生成高分辨率的 feature map,但是计算代价和存储代价较高
利用中间层的特征
最早的 FCN-8S 就是这样做的,但是始终还是缺少强的空间信息
以上所说方法在我之前的文章中都有提到,感兴趣的同学可以猛戳以下链接,这里就不赘述了。
图像语义分割之FCN和CRF: https://zhuanlan.zhihu.com/p/22308032?group_id=820586814145458176
作者主张所有层的特征都是有用的,高层特征有助于类别识别,低层特征有助于生成精细的边界。所以有了接下来的网络结构,说实话我是觉得有点复杂。
.
延伸三:COCO-16 图像分割冠军:首个全卷积端到端实例分割模型
现有的主流实例分割方法,几乎都是在常用的物体检测方法的基础上进行简单直接的扩展,对于问题的理解还不够深入,计算效率和精确度都还有很大的提升空间。
例如,对于兴趣区域(Region of Interests, RoI)的分类和分割作为单独的两个步骤进行,没有充分利用这两个任务的关联性;对于分割子网络的训练没有考虑物体类别的差异;对于每个 RoI 运行一个分割子网络导致计算效率低下;RoI Pooling 应该用更精确的对齐方式……
