爬虫实战之分布式爬取知乎问答数据
分布式爬取知乎
一、环境
- window7
- scrapy
- pycharm
- redis
- other PC
- MySQL
二、简介
之所以选择爬取知乎,一是很多人都在爬,那么一定有它爬取价值的地方;二呢分析后才发现,知乎是一个模拟登录、信息解析清洗、反反爬等较为经典的练习素材;我们在这次爬取中将会涉及到IP代理、随机更换UserAgent、scrapy-redis分布式。
数据维度:
问题:问题ID、标签、链接、题目、内容、问题创建时间、问题更新时间,回答数、评论数、关注数、浏览数、爬取时间、爬取更新时间
回答:回答ID、链接、问题ID、作者ID、内容、点赞数、评论数、回答创建时间、回答更新时间、爬取时间、爬取更新时间
三、网页分析与编程实现
一开始是使用scrapy直接模拟登录知乎后进行爬取,但到应用上redis后,发现其实不用登录也能爬取到知乎问答数据;这里既然需要介绍redis分布式爬取,就重点介绍应用redis分布式不登陆知乎的爬取方法,简单介绍下模拟登录下非分布式爬取。
知乎的模拟登录验证码的破解还是有点难度的,有时是数字字母验证,有时却是倒立的文字验证,验证方法我试过使用OCR自动识别数字字母,但识别准确度不高,还有待钻研 ,所以这次采用了较为便捷的selenium+webdriver方案
def start_requests(self): #scrapy 运行的入口,之前一直无法请求成功的原因是此处写成了start_request(self)
from selenium import webdriver
import time
import pickle
# Mycrawl_xici_ip.get_ips() #获取并保存IP
#ip_list_https = self.get_ip_list('https')
# with open('proxy_ip.txt' , 'r') as rf:
# ips_str = rf.read()
# ips_list = ips_str.split('\n')
try:
#response = scrapy.Request("http://ip.filefab.com/index.php") #测试,查看IP
f = open('E:/例程总汇/Python/ArticleSpider/ArticleSpider/cookies/zhihu/cookies.zhihu', 'rb')
cookie_dict = pickle.load(f)
f.close()
yield scrapy.Request(self.start_urls[1].format(6) , dont_filter=True, cookies=cookie_dict,
headers=self.header,callback=self.parse_JsonResponse , encoding="utf8" )
except:
brower = webdriver.Chrome(executable_path="D:/chromedriver/chromedriver.exe")
brower.get("https://www.zhihu.com/signin") # 进入登录界面
brower.find_element_by_css_selector(
".SignFlow-accountInput.Input-wrapper input[name='username']").send_keys(
USER) # 自动填充账号
brower.find_element_by_css_selector(".SignFlow-password .Input-wrapper input[name='password']").send_keys(
PASSWARD) # 自动填充密码
brower.find_element_by_css_selector(".Button.SignFlow-submitButton").click()
time.sleep(10) # 登录成功后自动跳转到首页,可以获取浏览cookies,验证已登录
Cookies = brower.get_cookies() # 获取cookies
# print(Cookies)
cookie_dict = {}
for cookie in Cookies:
cookie_dict[cookie["name"]] = cookie["value"]
# 写入文件
f = open('E:/例程总汇/Python/ArticleSpider/ArticleSpider/cookies/zhihu/cookies.zhihu', 'wb')
pickle.dump(cookie_dict, f)
f.close()
brower.close() # 浏览器关闭
yield scrapy.Request(self.start_urls[1].format(6) , dont_filter=True, cookies=cookie_dict, headers
=self.header , encoding="UTF8" , callback= self.parse_JsonResponse)登录成功后获取cookie值,保存到本地,下次再次启动时取出cookie值一起发送请求即可,但是每个cookie值都是有不同的生命周期的,所以需要不定期更新本地的cookie值。
模拟登录介绍完了,接下来的数据解析等跟分布式爬取下的差不多,就直接介绍分布式爬取方式。
注意此时已经不是同一个项目工程了,此次分布式爬取不采用登录知乎,而是分析出页面中加载更多问题的url,

发现请求这些url会相应返回Json格式的问题详细信息,
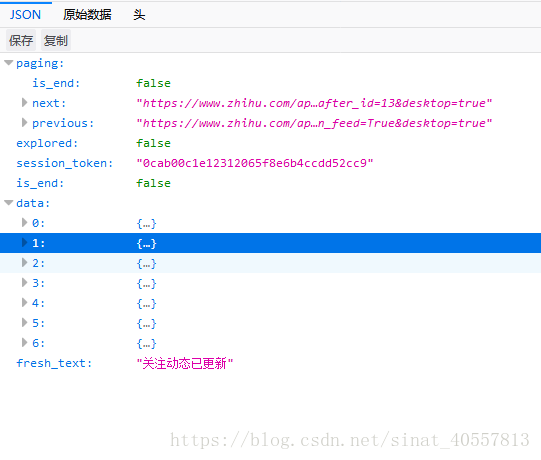
此时我们便可以利用json模块提取出问题的详细信息,
import json
ans_json = json.loads(response.text) # 浏览器打开answer_start_url分析可知,response返回json格式
is_end = ans_json['paging']["is_end"]
next_url = ans_json['paging']["next"]
for parse_item in ans_json["data"]:
question_item = ZhihuQuestionItem()
....
接下来就是构造持续爬取问题信息的url了,分析url可知变化的只有url里的after_id,而且是呈等差递增,所以
https://www.zhihu.com/api/v3/feed/topstory?action_feed=True&limit=7&session_token=7e46c167a2ff897996cbd056aa385b68&action=down&after_id=6&desktop=true
构造为:https://www.zhihu.com/api/v3/feed/topstory?action_feed=True&limit=7&session_token=7e46c167a2ff897996cbd056aa385b68&action=down&after_id={0}&desktop=true问题的回答提取也是同样道理,分析回答页面,下拉浏览更多回答,你会发现跟问题页面的浏览更多一毛一样,找到那个加载下一批次的url
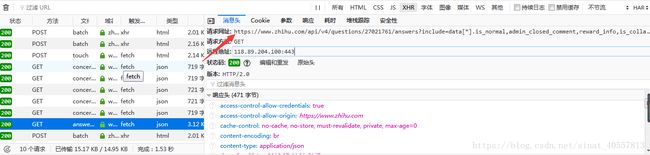
然后构造可持续爬取的url,分析发现只有question-id是变化的,当然limit和offset也是可以变化的,其大概意思是限定的响应数量和偏移量(总),故可构造成:
https://www.zhihu.com/api/v4/questions/27021761/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&limit=5&offset=15&sort_by=default
构造成:https://www.zhihu.com/api/v4/questions/{0}/answers?include=data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp;data[*].mark_infos[*].url;data[*].author.follower_count,badge[?(type=best_answerer)].topics&limit={1}&offset={2}&sort_by=default两个重要的url已经分析出来,接下来就是请求和解析之间的布局了,话不多说,直接上代码:
class ZhihuSpider(RedisSpider):
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
redis_key = 'zhihu:start_urls'
answer_start_url = 'https://www.zhihu.com/api/v4/questions/{0}/answers?sort_by=default&include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%3F%28type%3Dbest_answerer%29%5D.topics&limit={1}&offset={2}'
header = {
"authority": "www.zhihu.com",
'Connection':'keep-alive',
"Referer": "https://www.zhihu.com",
# 'User-Agent': "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36"
#"User-Agent":" Mozilla/5.0 (Windows NT 6.1; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0"
}
custom_settings = { #为zhihu spider自定义cookies_enabled
"COOKIES_ENABLED": True
}
def parse(self, response):
"""
提取出html页面中的所有url 并跟踪这些url进行一步爬取
如果提取的url中格式为 /question/xxx 就下载之后直接进入解析函数
"""
ans_json = json.loads(response.text) # 浏览器打开answer_start_url分析可知,response返回json格式
is_end = ans_json['paging']["is_end"]
next_url = ans_json['paging']["next"]
for parse_item in ans_json["data"]:
question_item = ZhihuQuestionItem()
if "question" not in parse_item["target"]:
continue
else:
question_id = parse_item["target"]["question"]["id"]
question_item["zhihu_id"] = question_id
question_item["title"] = parse_item["target"]["question"]["title"]
question_url = parse_item["target"]["question"]["url"]
request_url = re.sub('api.', '', question_url)
request_url = re.sub('questions', 'question', request_url)
question_item["url"] = request_url
topics = [x["reason_text"] for x in parse_item["uninterest_reasons"]]
question_item["topics"] = ','.join(topics)
excerpt = parse_item["target"]["question"]["excerpt"]
if not excerpt:
excerpt = ' '
question_item["content"] = excerpt
question_item["create_time"] = parse_item["target"]["question"]["created"]
question_item["update_time"] = parse_item["target"]["updated_time"]
question_item["answer_num"] = parse_item["target"]["question"]["answer_count"]
question_item["comments_num"] = parse_item["target"]["question"]["comment_count"]
question_item["watch_user_num"] = parse_item["target"]["question"]["follower_count"]
question_item["click_num"] = 0
question_item["crawl_time"] = datetime.datetime.now()
yield question_item
header = self.header.copy()
header.update({
"Referer": "https://www.zhihu.com/question/{0}".format(question_id),
"authority": "www.zhihu.com",
"authorization": "oauth c3cef7c66a1843f8b3a9e6a1e3160e20", # 当返回401错误码时,需进行HTTP认证
"Connection": "keep-alive",
})
# self.start_urls[2].format(question_id, 5, 10)
yield scrapy.Request(self.answer_start_url.format(question_id, 5, 10) , callback=self.parse_answer,
headers=header, meta={"question_id": question_id},
encoding="utf8")
# time.sleep(5)
if not is_end:
yield scrapy.Request(next_url, callback=self.parse ,
headers=self.header, encoding="utf8")
def parse_answer(self, response):
#解析回答页面
ans_json = json.loads(response.text) #浏览器打开answer_start_url可知,response返回json格式
is_end = ans_json['paging']["is_end"]
next_url = ans_json['paging']["next"]
question_id = response.meta.get("question_id")
#提取answer的具体字段
for answer in ans_json["data"]: #观察数据格式。data数组里包含字典,故使用for循环遍历
answer_item = ZhihuAnswerItem()
answer_item["zhihu_id"] = answer["id"]
answer_item["url"] = answer["url"]
answer_item["question_id"] = answer["question"]["id"]
answer_item["author_id"] = answer["author"]["id"] if "id" in answer["author"] else None
answer_item["content"] = answer["content"] if "content" in answer else None
answer_item["praise_num"] = answer["voteup_count"]
answer_item["comments_num"] = answer["comment_count"]
answer_item["create_time"] = answer["created_time"]
answer_item["update_time"] = answer["updated_time"]
answer_item["crawl_time"] = datetime.datetime.now()
yield answer_item #yield到pipelines
if not is_end:
header = self.header.copy()
header.update({
"Referer": "https://www.zhihu.com/question/{0}".format(question_id),
"authority" : "www.zhihu.com" ,
"authorization": "oauth c3cef7c66a1843f8b3a9e6a1e3160e20" , #当返回401错误码时,需进行HTTP认证
"Connection": "keep-alive" ,
})
yield scrapy.Request(next_url , headers=header , callback= self.parse_answer ,
encoding="utf8")大概讲下思路,由于是分布式爬取,看到代码前部分中的
redis_key = 'zhihu:start_urls'了吧,其实设置这个的目的是程序启动后会一直检测redis内存中是否含有zhihu:start_urls键,用来作为第一个爬取的url,即要爬取的网站信息的一个入口。在设置这个键值之前程序一直处于监控状态

直到某个人在redis-cli中lpush个起始url给redis内存


redis的设置和操作即将要说到。
scrapy-redis的下载和环境配置:
点击scrapy-redis下载redis压缩包,将里面的scrapy_redis文件夹复制到项目文件中,添加到项目中;
自定义的spider类继承RedisSpider类
class ZhihuSpider(RedisSpider):当然,settings.py里也要做一些相应的设置:
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #设置redis的查重方式
ITEM_PIPELINES = {
#'scrapy_redis.pipelines.MysqlTwistedPipline': 300 , #异步上传MySQL
'scrapy_redis.pipelines.RedisPipeline' : 200 ,
}
REDIS_URL = 'redis://192.168.1.101:6379'
SCHEDULER_PERSIST = True
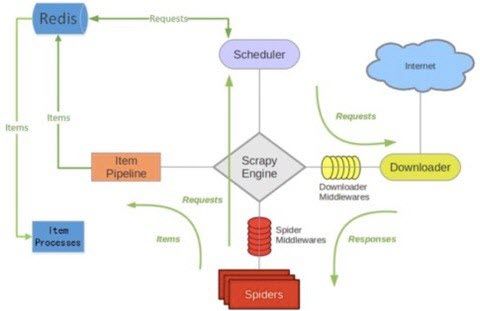
REDIS_START_URLS_KEY = 'zhihu:start_urls'这里要注意,此时的pipeline已经是scrapy-redis中的pipeline了,这些也是scrapy-redis通过替换scrapy中的一些架构来实现分布式的方式。
下面附上其结构图:
接下来讲到UserAgent的随机设置了。设置UserAgent真的有必要吗?
一般用python编写的爬虫,其向服务器发送的请求中默认的UserAgent很容易被服务器识别出来是爬虫,为了提高隐蔽性,防止爬虫被服务器识别,随机切换不同的UserAgent能起到一定的作用。
这里利用了fake_useragent模块中的UserAgent方法,其是一个专门对各种浏览器的不同版本UserAgent进行维护的一个平台API,我们直接调用就可以了,十分方便。
from fake_useragent import UserAgent
class RandomUserAgentMiddleware(object):
#随机更换user_agent
def __init__(self , crawler):
super(RandomUserAgentMiddleware, self).__init__()
#self.user_agent = crawler.settings.get("user_agent_list" , [])
#后期需要维护user_agent_list,故引入fake_useragent模块,专门的库维护网站
self.ua = UserAgent()
self.ua_type = crawler.settings.get("RANDOM_UA_TYPE" , "random") #默认值“random”
@classmethod #
def from_crawler(cls , crawler):
return cls(crawler)
def process_request(self , request , spider):
def get_ua(): #函数中定义函数,动态语言闭包特性
return getattr(self.ua , self.ua_type) #相当于self.ua.self.uatype,但这种形式无法实现ua.uatype
request.headers.setdefault("User-Agent" ,get_ua())
def process_response(self, request, response, spider):
return response其实就是在middlewares.py中随机获取到UserAgent后设置到request的headers里面,当然别忘了要到settings.py中配置,

这样随机切换UserAgent就设置完成了。
接下来是IP代理了,其实IP代理设置还是听简单的,但是有效IP的获取,IP池的维护等就复杂多了。
我们现在只讲IP代理的设置。
同样也是在middlewares.py中设置IP代理类
class proxyMiddleware(object):
def __init__(self , crawler):
super(proxyMiddleware , self).__init__()
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
# s = cls()
# crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
# return s
return cls(crawler)
def process_request(self , request , spider):
ip = 'https://50.93.200.95:1018' #可变成随机获取
print("Now checking ip is", ip)
request.meta["proxy"] = ip只要向每个request的meta中添加['proxy' : ip]就可以了,最后还得在settings.py中设置中间件

至此,IP代理设置完毕
更新:IP代理池的设置和有效IP的持续使用