《Grokking Deep Learning》构建深层神经网络
构建第一个深层网络
一、学习间接相关
如果你的数据没有相关性,就创建有相关性的中间数据!

如果输入输出数据没有直接的相关性怎么办?
使用其中两个网络。第一种方法将创建一个与输出相关性有限的中间数据集。第二种方法将使用这种有限的相关性来正确预测输出。
因为输入数据集和输出数据集其实没有相关性,我们用输入数据集去创建一个中间层数据集,这个被创建的中间数据集和输出数据集有相关性。
二、创建相关性
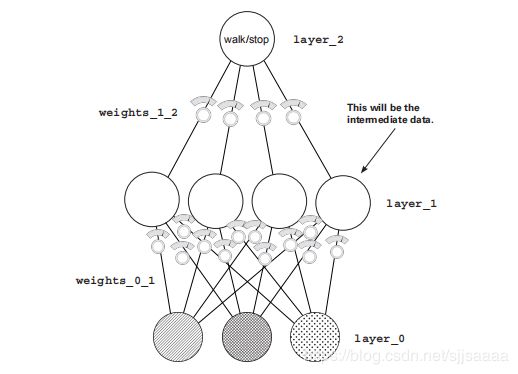
每一个圆点都是一个数据,每一排若干个圆点构成intermediate dataset,中间数据集如果 input 这一排圆,输入数据集和输出数据集本身没有相关性,我们中间曾加一个中间层,“人为"的创造相关性。
输入数据集给下一层网络训练,下一层网络输出中间数据集,中间数据集传递给输出层,中间数据集被认为是用于训练的数据集。
三、反向传播
堆叠神经网络综述
多层神经网络的训练关键叫:backpropagation
正向传播叫推理。推理就是神经网络已经训练好了,拿来直接使用。
反向传播往往是为了训练和优化权重参数。
在之前的权重学习过程,是输入层和输出层直接相关,也就是pred_y,true_y做对比,而如果曾加了一层,中间层并没有所谓的 true_y(output dataset)。
长距离错误归因
从第 1 层到第 2 层的权重准确地描述了每个第 1 层节点对第 2 层预测的贡献。
这意味着这些权重也准确地描述了每个第一层节点对第二层误差的贡献。
如何使用第 2 层的增量来计算第 1 层的增量?
将它乘以第 1 层的每个权重。这就像相反的预测逻辑。这个移动三角信号的过程叫做反向传播。
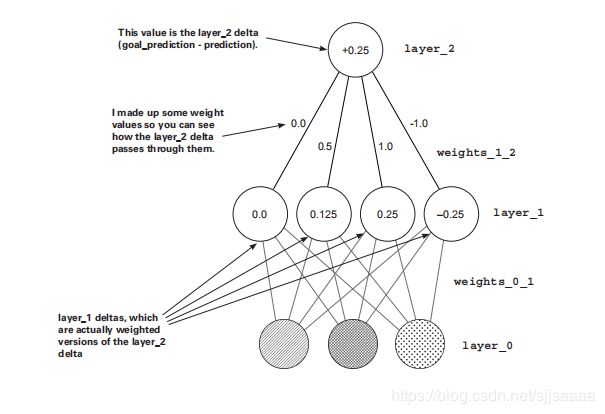
为什么会这样?
在神经经网络中,delta 变量告诉你这个节点的值下次应该改变的方向和数量。
所有的反向传播让你说,“如果你想让这个节点高 x 个数量,那么前面四个节点中的每一个都需要高/低 x *权重 1_2个数量,因为这些权重将预测放大权重 1_2 倍。”
当反向使用时,权重_1_2 矩阵以适当的量放大误差。它放大了误差,因此知道每个第 1 层节点应该向 上或向下移动多少。
通过层层推导的方式,去算总体的delta。
四、线性与非线性
还需要一个零件来训练这个神经网络,从两个角度来看:
第一个将显示为什么神经网络没有它就不能训练。
首先我将向你展示为什么神经网络目前被破坏了。然后,一旦你添加了这个片段,我将向你展示它是如何解决这个问题的。
例如简单的代数:
1 * 10 * 2 = 100
5 * 20 = 100
1 * 0.25 * 0.9 = 0.225 1 * 0.225 = 0.225
对于任何两次乘法,我可以用一次乘法完成同样的事情。
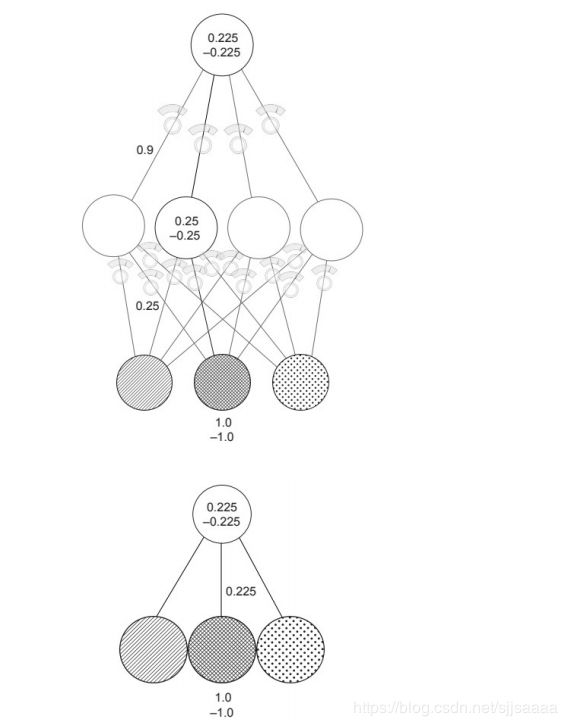
这两幅图各显示了两个训练示例,一个输入为 1.0,另一个输入为-1.0。
对于您创建的任何三层网络,都有一个行为相同的两层网络。堆叠两个神经网络(正如你现在所知)不会给你更多的能力。两个连续的加
权和只是一个加权和的更昂贵版本。
为什么神经网络仍然不起作用
四个节点中的每个节点都有一个来自每个输
入的权重。让我们从相关性的角度来考虑这个问题。中间层中的每个节点都与每个输入节点有一定的相关性。如果从一个输入到中间层的权重是 1.0,那么它订阅了该节点 100%的移动。如果该节点上升0.3,中间节点将随之上升。如果连接两个节点的权重为 0.5,则中间层中的每个节点订阅该节点移动的50%。中间节点能够避开一个特定输入节点的相关性的唯一方法是,如果它从另一个输入节点订阅附加
相关性。这个神经网络没有新的贡献。每个隐藏节点从输入节点订阅一点相关性。中间节点不能给对话 添加任何内容;他们没有自己的关联。它们或多或少与各种输入节点相关。
数据集任何输入和输出之间都没有相关性,中间层有什么帮助?
它混淆了一堆已经无用的关联。真正
需要的是中间层能够有选择地与输入相关联。
您希望中间层有时与输入相关,有时不相关。这给了它自己的相关性。这使得中间层有机会不仅仅是 x%与一个输入相关,y%与另一个输入相关。相反,只有当它愿意的时候,它才可以与一个输入 x%相关,但是其他时候根本不相关。这被称为条件相关,有时也称为相关。
有时关联的秘密
当该值低于 0 时,关闭该节点。
考虑这一点:
如果一个节点的值降到 0 以下,通常该节点仍然与输入保持相同的相关性。它的价值刚好是负数。但是,如果当节点为负时关闭节点(将其设置为 0),那么当节点为负时,它与任何输入都没有相关性。
该节点现在可以有选择地选择它希望何时与某个东西相关联。“使我与左输入完美相关,但只有当右输入关闭时。”
如果左输入的权重是1.0,右输入的权重是一个巨大的负数,那么同时打开左输入和右输入将导致节点始终为 0。但是如果只有左输入打开,节点将采用左输入的值。
中间节点要么总是与输入相关,要么总是不相关。这个“如果节点为负,将其设置为 0”逻辑的奇特术语是非线性。没有这种调整,神经网络是线性的。如果没有这种技术,输出层只能从两层网络中的相同相关性中进行挑选。它订阅输入层的片段,这意味着它不能解决新的街灯数据集。
五、第一个深层神经网络
下面的代码初始化权重并进行前向传播:
import numpy as np
np.random.seed(1)
def relu(x):
return (x > 0) * x
alpha = 0.2
hidden_size = 4
streetlights = np.array( [[ 1, 0, 1 ],
[ 0, 1, 1 ],
[ 0, 0, 1 ],
[ 1, 1, 1 ] ] )
walk_vs_stop = np.array([[ 1, 1, 0, 0]]).T
weights_0_1 = 2*np.random.random((3,hidden_size)) - 1
weights_1_2 = 2*np.random.random((hidden_size,1)) - 1
layer_0 = streetlights[0]
layer_1 = relu(np.dot(layer_0,weights_0_1))
layer_2 = np.dot(layer_1,weights_1_2)
这个代码和之前的神经网络的计算,输出=f(输入),模式是一样的,只是在中间层节点,增加加了relu激活函数,用于层架模型的非线性能力。
之前的weight1input1+weight2input2…+…weightN*inputN,通过矩阵的dot点积替换了,二者是等价的运算。
代码中的反向传播
反向传播是关于计算中间层的增量,以便可以执行梯度下降。要做到这一点,需要在第 2层为第 1 层取加权平均增量(由它们之间的权重加权)。然后关闭(设置为 0)没有参与正向预测的节点,因为它们不会导致错误。
import numpy as np
np.random.seed(1)#随机种子
def relu(x): #激活函数 用于turn on/off 某个节点数据
return (x > 0) * x
def relu2deriv(output): #激活函数的导数,用于计算导数值
return output>0
alpha = 0.2 #学习速率
hidden_size = 4 #隐藏层的神经元个数
weights_0_1 = 2*np.random.random((3,hidden_size)) - 1#随机 第一层节点-第二层节点之间 连接权重值
weights_1_2 = 2*np.random.random((hidden_size,1)) - 1#随机 第二层节点 - 第三层节点之间 连接权重值
for iteration in range(60):# #迭代60次,每次用全部数据集训练
layer_2_error = 0 #每次清零输出误差
for i in range(len(streetlights)): #每次遍历每一个数据样本点
layer_0 = streetlights[i:i+1]#输入层:获取第i+1个样本
layer_1 = relu(np.dot(layer_0,weights_0_1)) #第一层数据 点乘 【第一层到第二层】的权重矩阵 = 第二层节点值,接着relu过滤掉<0的数据,让<0节点失去相关性
layer_2 = np.dot(layer_1,weights_1_2) #让第二层数据和 点乘 【第二层到第三次】的权重矩阵 = 第三次输出层的节点值
layer_2_error += np.sum((layer_2 - walk_vs_stop[i:i+1]) ** 2) # 计算输出层节点 误差(累加每一个样本点)
layer_2_delta = (walk_vs_stop[i:i+1] - layer_2) # 计算真实输出样本 和 预测输出值 的差距 layer_2_delta,也就是输出层的预测差值
layer_1_delta=layer_2_delta.dot(weights_1_2.T)*relu2deriv(layer_1)# 计算中间层的预测差值,具体为什么这么乘,有推导公式后面给出
weights_1_2 += alpha * layer_1.T.dot(layer_2_delta)#更新中间层到输出层的权重值ha *
weights_0_1 += alpha * layer_0.T.dot(layer_1_delta) #更新输入层到中间层的权重值
if(iteration % 10 == 9):#每9次迭代输出一次输出层误差值
print("Error:" + str(layer_2_error))
运行:

目标是错误归因。
这是关于计算每个重量对最终误差的贡献。在第一个(两层)神经网络中,你计算了一个增量变量,它告诉你你希望输出预测值有多高或多低。看看这里的代码。你用同样的方法计算第
二层。
现在知道了最终预测应该向上或向下移动多少(增量),您需要计算出每个中间(layer_1)节点应该向上或向下移动多少。这些实际上是中间预测。一旦在 layer_1 处获得增量,就可以使用与之前相同的过程来计算权重更新(对于每个权重,将其输入值乘以其输出增量,并将权重值增加那么多)。

源代码:
import numpy as np
np.random.seed(1) #随机种子
def relu(x): #激活函数 用于turn on/off 某个节点数据
return (x > 0) * x
def relu2deriv(output): #激活函数的导数,用于计算导数值
return output>0
alpha = 0.2 #学习速率
hidden_size = 4 #隐藏层的神经元个数
streetlights = np.array( [[ 1, 0, 1 ], #input 数据集,一行一个数据样本点
[ 0, 1, 1 ],
[ 0, 0, 1 ],
[ 1, 1, 1 ] ] )
walk_vs_stop = np.array([[ 1, 1, 0, 0]]).T #output 数据集 ,一个元素为一个数据样本点
weights_0_1 = 2*np.random.random((3,hidden_size)) - 1 #随机 第一层节点-第二层节点之间 连接权重值
weights_1_2 = 2*np.random.random((hidden_size,1)) - 1 #随机 第二层节点 - 第三层节点之间 连接权重值
for iteration in range(100): # #迭代100次,每次用全部数据集训练
layer_2_error = 0 #每次清零输出误差
for i in range(len(streetlights)): #每次遍历每一个数据样本点
layer_0 = streetlights[i:i+1] #输入层:获取第i+1个样本
layer_1 = relu(np.dot(layer_0,weights_0_1)) #第一层数据 点乘 【第一层到第二层】的权重矩阵 = 第二层节点值,接着relu过滤掉<0的数据,让<0节点失去相关性
layer_2 = np.dot(layer_1,weights_1_2) #让第二层数据和 点乘 【第二层到第三次】的权重矩阵 = 第三次输出层的节点值
layer_2_error += np.sum((layer_2 - walk_vs_stop[i:i+1]) ** 2) # 计算输出层节点 误差(累加每一个样本点)
layer_2_delta = (walk_vs_stop[i:i+1] - layer_2) # 计算真实输出样本 和 预测输出值 的差距 layer_2_delta,也就是输出层的预测差值
layer_1_delta=layer_2_delta.dot(weights_1_2.T)*relu2deriv(layer_1) # 计算中间层的预测差值,具体为什么这么乘,有推导公式后面给出
weights_1_2 += alpha * layer_1.T.dot(layer_2_delta) #更新中间层到输出层的权重值
weights_0_1 += alpha * layer_0.T.dot(layer_1_delta) #更新输入层到中间层的权重值
if(iteration % 10 == 9): #每9次迭代输出一次输出层误差值
print("Error:" + str(layer_2_error))
layer_0 = streetlights[0] #拿第0个样本输入数据做测试
layer_1 = relu(np.dot(layer_0,weights_0_1)) #输入层 点乘 【输入层x中间层】 权重矩阵 然后relu
layer_2 = np.dot(layer_1,weights_1_2) #中间层输入数据 点乘 【中间层x输出层】权重矩阵 (这里没有用relu,现实当中根据需要可以用)
print(layer_2) #输出第0号样本点的输出值 和 真实output数据集 对比 一致

六、为什么深层网络很重要?
考虑这里显示的猫的图片。

进一步考虑一下,我有一个有猫和没有猫的图像数据集(我给它们贴上了这样的标签)。如果我想训练一个神经网络来获取像素值并预测图片中是否有猫,那么两层网络可能会有问题。
就像在最后一个街灯数据集中一样,没有单独的像素与图片中是否有猫相关。只有不同的像素配置与是否有猫相关。
这是深度学习的本质。深度学习就是创建中间层(数据集),其中中间层中的每个节点代表输入的不同配置 的存在与否。
这样,对于猫图像数据集,没有单个像素必须与照片中是否有猫相关联。相反,中间层将尝试识别可能与猫相关或不相关的不同像素配置(例如耳朵、猫眼或猫毛)。许多类似猫的配置的存在将会给最终层提供正确预测猫的存在或不存在所需的信息(相关性)。
你可以选择三层网络,继续堆叠越来越多的层。一些神经网络有数百层,每个节点都在检
测输入数据的不同配置中发挥作用。
神经网络反向传播的公式推导过程
三层全连接神经网络:
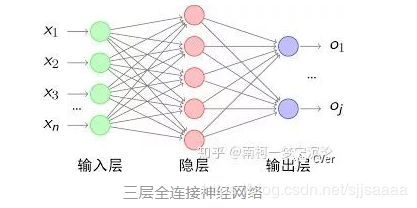
每一层的感知机,会将上一层感知机的输出作为输入,通过乘上权重矩阵以及加上列向量形式的偏置项,即可得到激活前的输出值,最后通过激活函数得到该层最终激活后的输出,具体计算公式如下:
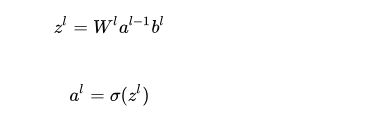
表示第l层(l=1,2,…,L)经过激活函数之前的输出,而 表示第l层经过激活函数之后的输出,σ表示激活函数。注意,每层的输入以及输出都是一个一维的列向量,我们假设上一层的输出是m×1的列向量,而当前层的输出是n×1的列向量,那么权重矩阵的维度应该是多少呢?应该为n×m。而当前层偏置项的维度为n×1。
我们的目标是得到一个神经网络,让它对我们的输入,能给出正确的输出。为了达到这个目的,我们需要预先给神经网络喂入大量标注过的数据,即不仅给它输入数据,也告诉它什么是对应正确的输出,让神经网络自己去学习调整内部的参数。
在训练过程中,我们首先需要定义一个误差函数(也称损失函数),用来度量神经网络的输出与正确的输出之间的差异。为了便于理解,我们这里使用简单直观的均方误差损失函数:

我们用L代表多层感知机总的层数, 表示多层感知机第L层经过激活函数后的输出,也即神经网络所预测的输出值。而y是训练数据中对应输入x实际的输出值y。
经过前向传播之后,我们就得到了当前神经网络的误差大小,下一步则是利用求得的误差对神经网络的参数进行更新,即对各层的权重矩阵 和偏置项 进行更新,使神经网络的误差减小,达到训练的目的。
在这里我们使用一种叫梯度下降的迭代算法完成参数的更新,通过求出误差对各个参数的导数大小,令参数向导数减小的方向变化即可。所以,我们现在的任务是求出误差函数对每个参数的导数。为了方便进一步的计算推导,以及避免重复计算,我们引入一个中间量 ,我们称它为delta误差,表示误差函数对于神经网络第l层激活前输出值的偏导数,即 :

根据神经网络误差函数的定义式,我们可以很容易地求出输出层的delta误差 ![]()
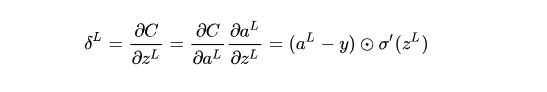
在公式里, ![]() 表示Hadmard积,即对应逐元素相乘,与矩阵乘法相区分。
表示Hadmard积,即对应逐元素相乘,与矩阵乘法相区分。
误差函数C对于输出层参数的导数,即对权重矩阵以及偏置项的导数可相应求得为:
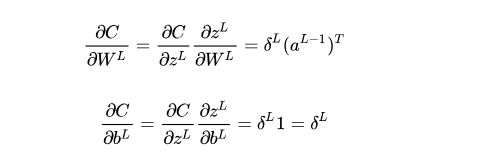
一旦求出了当前层的delta误差,误差函数对当前层各参数的导数便可以相应的求出。
得到了最后一层的delta误差,我们接下来利用我们的主角——反向传播算法,将delta误差逆向传播,即不断地根据后一层的delta误差求得前一层的delta误差,最终求得每一层的delta误差。其实在这里我们主要利用的是求导的链式法则。假设我们已经求得第l+1层的delta误差,我们可以将第l层的delta误差表示如下:
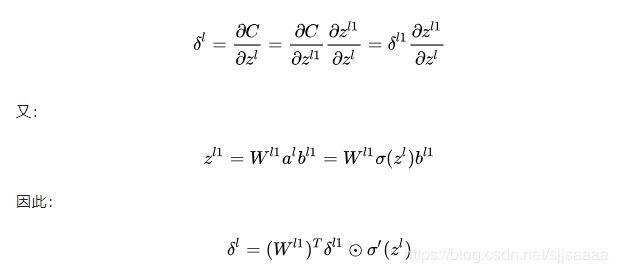
在求得每一层的delta误差后,我们可以很容易地求出误差函数C对于每一层参数的梯度:

最后我们可以通过梯度下降法来对每一层的参数进行更新:

![]()
在上述的分析中,我们只根据一组训练数据更新数据,而在一般的情况下,我们往往采用随机梯度下降法(SGD),即一次性训练一批数据,先求得这一批数据中每一个数据对应的误差梯度,最后再根据它们的平均值来对参数进行更新,即:
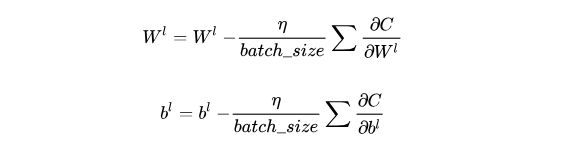
如何完成一个多层感知机的训练::
- 对神经网络各层参数即各层的权重矩阵和偏置项进行初始化,设置好训练的最大迭代次数,每个训练batch的大小,学习率
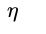
- 从训练数据中取出一个batch的数据
- 从该batch数据中取出一个数据,包括输入x以及对应的正确标注y
- 将输入x送入神经网络的输入端,得到神经网络各层输出参数
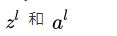
- 根据神经网络的输出和标注值y计算神经网络的损失函数
- 计算损失函数对输出层的delta误差
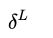
- 利用相邻层之间delta误差的递推公式

- 利用每一层的delta误差求出损失函数对该层参数的导数

- 将求得的导数加到该batch数据求得的导数之和上(初始化为0),跳转到步骤3,直到该batch数据都训练完毕
10.利用一个batch数据求得的导数之和,根据梯度下降法对参数进行更新
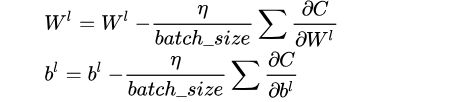
- 跳转到步骤2,直到达到指定的迭代次数
矩阵
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合,最早来自于方程组的系数及常数所构成的方阵。
矩阵的乘法:
是一种根据两个矩阵得到第三个矩阵的二元运算,第三个矩阵即前两者的乘积,称为矩阵积。

矩阵的点积:
用于向量相乘,表示为C=A.*B,A与B均为向量,C为标量,也称标量积、内积、数量积等。
矩阵的数量积:
数道量积(dot product; scalar product0,也称为点积、点乘)是接受在实数R上的两个向量并返回一个实数值标量的二元运算。它是欧几里得空间的标准内积。
线性
在线性代数里,矢量空间的一组元素中,若没有矢量可用有限个其他矢量的线性组合所表示,则称为线性无关或线性独立(linearly independent),反之称为线性相关(linearly dependent)。
假设V是域K上的向量空间。如果v1,v2,…,vn是V的向量,称它们为线性相关,如果从域K中有非全零的元素a1,a2,…,an,适合a1v1+a2v2+…+anvn=0(注意右边的零是V的零向量,不是K的零元)。如果K中不存在这样的元素,那么v1,v2,…,vn是线性无关。
对线性无关可以给出更直接的定义:向量v1,v2,…,vn线性无关,当且仅当它们满足以下条件:如果a1,a2,…,an是K的元素,适合:a1v1+a2v2+…+anvn=0,那么对所有i=1,2,…,n都有ai=0.
在V中的一个无限集,如果它任何一个有限子集都是线性无关,那么原来的无限集也是线性无关。
线性相关性是线性代数的重要概念,因为线性无关的一组向量可以生成一个向量空间,而这组向量则是这向量空间的基。
相关性:
- 含有零向量的向量组,必定线性相关;
- 含有两个相等向量的向量组,必定线性相关;
- 若一向量组相关,则加上任意个向量后,仍然线性相关;即局部线性相关,整体必线性相关;
- 整体线性无关,局部必线性无关;
- 向量个数大于向量维数,则此向量组线性相关;
- 若一向量组线性无关,即使每一向量都在同一位置处增加一分量,仍然线性无关;
- 若一向量组线性相关,即使每一向量都在同一位置处减去一分量,仍然线性相关;
- 若a1,a2,…,a8线性无关,而b,a1,a2,…,a8线性相关,则b必可由a1,a2,…,a8线性表示,且表示系数唯一;
- 有向量组Ⅰ{ a1,a2,…,as}和Ⅱ{b1,b2,…bt},其中t>s,且Ⅱ中每个向量都可由Ⅰ线性表示,则向量组Ⅱ必线性相关。即向量个数多的向量组,若可被向量个数少的向量组线性表示,则向量个数多的向量组必线性相关。
10.若一向量组b1,b2,…bt可由向量组a1,a2,…,as线性表示,且b1,b2,…bt线性无关,则t≤s。即线性无关的向量组,无法以向量个数较少的向量组线性表示。