大数据(二) --分布式文件系统(HDFS)
分布式文件存储
- 分布式引入
- 基本的HDFS写操作
- 备份机制
- 写数据的详细流程
- HDFS读操作
- 元数据持久化
- 安全模式
- HDFS总结
- HDFS角色
- HDFS机制
- HDFS流程
- HDFS优缺点
- 优点
- 缺点
分布式引入
大数据时代的到来, 数据的增长呈现爆炸式的状态. 数据的大小从原来的MB, GB级别一跃成为当前的TB, PB甚至EB级别. 海量数据的产生已不再适合用传统的方法对数据进行存储, 那么我们应该怎么合理得来存储数据呢? 假设Boss给你6台服务器, 让你用这6台服务器去存储10PB的数据(服务器可以把数据全部装下), 那么你会怎么做呢?
首先, 你可能会想到的将这些数据分成六份, 每台服务器上装相同大小的数据. 很快你的工作就完成了, 简答而不费脑, 等时间就行了. 时间到了, 你也该走了.
为什么这么说呢? 一段时间之后, 你早已经忘记自己把数据存在哪台服务器上了. 这时如果Boss让你找某某数据在那, 你怎么办? 能怎么办, 只能挨个服务器去找呗, 找到之后再把数据从服务器上拿下来. 存的时候一时爽, 取的时候就给自己带来了无尽的麻烦. 所以说, 这种方法是不行的.
那你可能就会想了, 既然这样我找个秘书来给我记着点, 帮我记好哪些数据存在在哪台服务器上, 到时候Boss跟我要数据我就跟你要, 找不出来我拿你问罪.
真有那么一天来了, Boss找你让你尽快找到***数据, 而且这个数据很大. 这时候你想了想这么大的数据半天的时间就能传完了, 就答应Boss半天时间内给他拿过去. 紧接着你就去找秘书要数据了, 你问他知道数据在哪吗? 他很干脆地说知道, 然后你就放心了, 让他尽快把数据发给你. 结果快到半天的时间了, 你发现秘书还没找你, 这时候你也急了, 就去质问你的秘书他是怎么回事, 这么久了还不把数据给你. 秘书接着回了一句, 马上就好. 不一会, 就把数据发给你了. 当你还在接收数据的时候, Boss来找你要数据了, Boss一看这数据竟然刚开始传送! 本来今天脾气不好的他开始对你发飙, 一顿说下来之后, 你又被炒了.
虽然这次数据很快就找到了, 但是数据在传送的过程中经过了两次IO操作, 严重浪费了时间, 降低了工作效率.
第三次, 你算学精了. 这回你还是找了个秘书来帮你记数据, 只不过在找数据的时候, 你跟秘书说让他把数据的信息发给你, 包括这些数据的id号, 上传时间, 存储位置等元数据, 你自己去获取数据. 这次是比较顺利地达到了Boss的要求.
这第三次存储的方式基本就是我们分布式存储的思想. 这里出现了几个角色:
- 你 : 你就相当于一个客户端Client, 负责拿到要上传的数据.
- 秘书 : 上传数据信息管理员NameNode, 负责管理元数据
- 服务器 : 源数据存储节点DataNode, 负责存储源数据.
- 元数据 : 描述数据的数据
- 源数据 : 原始数据
还有两点需要考虑 :
- 一个文件我可不可以存在两台服务器上?
- 如果一台服务器宕机或者坏掉我该怎么办?
这里又引入两个概念 :
- 存储单元block : 单个的文件, 不可拆分存储
- 数据备份(副本)replication : 解决数据的安全性问题, 防止数据丢失.
基本的HDFS写操作
写操作也就是上传文件, 主要分为一下7步:
-
大文件需要切割成block块来上传, 因此client先计算大文件的block块数, 一个block的默认大小为128MB. 所以, 大文件切割成的block块数 = 大文件地址/128M .
-
client会向NameNode节点汇报,汇报内容包括
+ 当前大文件的block块数
+ 当前大文件的属主owership
+ 当前大文件的权限permission
+ 上传时间
for(Block block : blocks){ 根据 block块数循环 3~7
-
client切割出一个block块
-
client请求block块的Id和DataNode地址
-
NameNode返回负载不高的DataNode地址给Client
-
client拿到地址后, 找到DataNode上传数据, 同时做好备份.
-
DataNode将block存储完毕后, 向NameNode汇报当前的存储情况.
}

备份机制
HDFS的备份机制是:
-
如果是集群内提交, 第一个block存储在提交上传请求的服务器上;
如果是集群外提交, 第一个block存储在负载不高的一台服务器上; -
第一个备份的block存储在与第一个block不同机架的随机一台服务器上;
-
第二个备份的block存储在与第一个备份的block相同机架的不同服务器上;
-
默认一个block有两个副本. 更多副本存储在随机节点上.

上述说明的是集群外提交数据, 如果是集群内提交, 即DataNode上传数据, 则第一个block存放在当前节点上, 其余两个相同.
写数据的详细流程
上述流程中备份还存在一定问题 :
客户端在向DN上传文件时, 不能并行存储, 需要等待第一个DN存储完毕之后, 才能继续上传之后的内容, 这无疑使得整个集群的效率变慢. 因此, 在上传时, 客户端会与各个DN节点之间形成管道, 实现并行存储, 从而提高效率.
-
NN返回client一批DN地址之后, client就会和这些DN之间会形成一个Pipeline管道.
-
client将block切割成一个个大小为64K的packet, 然后源源不断地输送packet到Pipeline中来.
-
DN从管道中获取数据并保存到本地.
通过以上三步, 实现上传数据时的并行存储

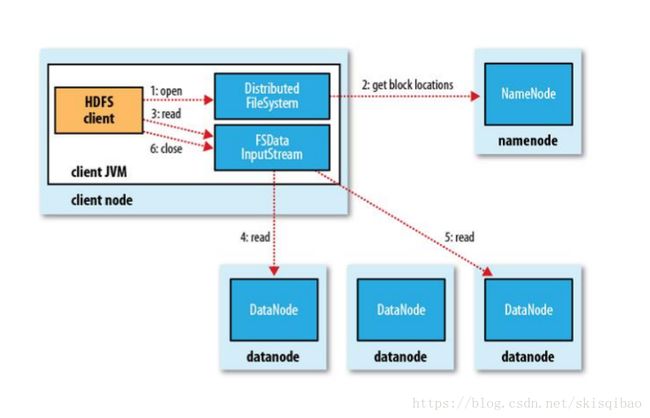
HDFS读操作
-
client向NameNode发送文件名称或内容的请求
-
NN返回文件Block地址给client
-
client根据地址读取block
-
block拼接
元数据持久化
NameNode中的元数据信息都是存储在内存中的, 内存不稳定, 容易造成数据丢失, 因此需要把元数据持久化到磁盘中.
由于NameNode要做的工作已经非常复杂, 再给它持久化的功能会让NN负重更大. 而且如果持久化是由NN来管理, 那么在使用IO操作的过程中, 不允许再有元数据修改, 那我们的服务对外就禁用了, 这当然就不可行了 .
因此, 在这又引入了一个角色SecondaryNameNode, 作为NN的代理对象负责持久化元数据.
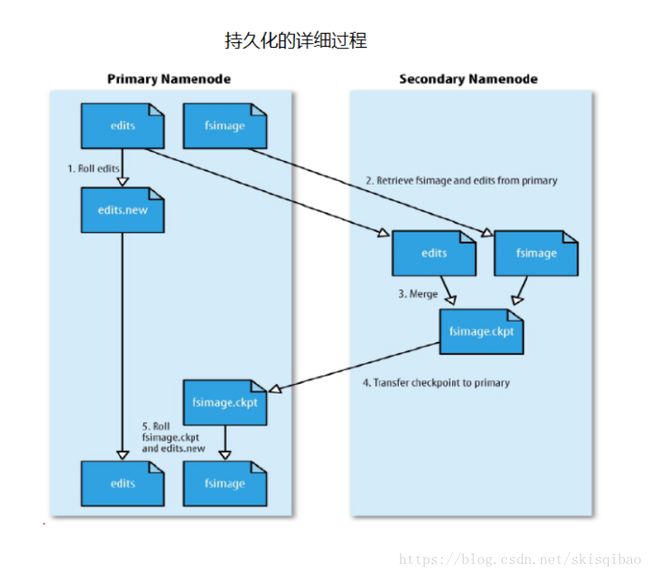
持久化过程:
-
SNN将NN中的edits和fsimage文件(第一次时为空)fetch到自己这边;
-
复制时, NN创建edits.new, 用来存储合并期间对元数据的操作;
-
SNN对edits中修改元数据的操作进行重演;
-
SNN将重演后得到的元数据与fsimage合并;
* 合并触发机制: (1). 超过3600s (2).edits文件超过64MB -
整合后形成checkpoint文件, 并传给NN;
-
NN将edits.new改名edits,用于下一次持久化重演. 将接收的fsimage.ckpt改名fsimage, 用于下一次持久化合并.
注意
并非所有元数据都会持久化. Block的位置信息将不会被持久化.
这就会导致, 当HDFS集群重启时, NN中会缺失block位置信息的元数据, 导致无法对外提供服务.
解决: HDFS集群启动时, 所有的DN都会向NN汇报当前节点的block信息.
安全模式
HDFS文件权限依据linux系统的用户管理系统.
安全模式类似于操作系统启动阶段, 在此期间, client的操作只能是读操作, 写, 删除等修改操作都会失败.
安全模式会做的事情:
-
NN首先将fsimage加载到内存中.
-
然后执行edits的各项操作, 即NN自身重演合并, 关闭或重启服务之前只做这一次.
-
NN收集各个DN的报告, 检查DN的健康情况. 当某个block块达到最小副本数以上时, 系统认定其为安全状态, 在一定数量的block块被确定为安全状态后, 结束安全模式.
-
当监测到副本数不足的block块时, 指挥其他DN做该block块的副本, 直到达到最小副本数.
HDFS总结
HDFS角色
角色在集群中都是通过进程来表现的.
为何node01服务器为NodeName节点?
因为node01节点上启动着一个NameNode进程.
角色:
-
NameNode
掌控全局:
1. 接收客户端请求(读, 写)
2. 管理元数据(元数据存放在内存中)
+ 文件owership
+ 文件permissions
+ 文件大小
+ 上传时间
+ block列表:BlockId
+ Block副本位置
3. 管理DataNode(收集DataNode汇报的Block列表信息) -
SecondaryNameNode
持久化内存中的元数据 -
DataNode
- 以block块的形式存储源数据
- 接受客户端请求
HDFS机制
- 存储单元
- 备份机制
- 权限管理
- 安全模式
HDFS流程
- 读流程
- 写流程
HDFS优缺点
优点

缺点
