评价一个好的算法有以下几个标准
① 正确性(Correctness )
② 可读性(Readability)
③ 健壮性(Robustness)
④ 通用性(Generality)
⑤ 效率与存储量需求:
对于效率指的是算法执行的时间,存储量需求指算法执行过程中所需要的最大存储空间。一般地,这两者与问题的规模有关,其实就是时间复杂度和空间复杂度。
时间复杂度
基本操作重复执行的次数是问题规模n的某个函数,其时间量度记作 T(n)=O(f(n)),称作算法的渐近时间复杂度(Asymptotic Time complexity),简称时间复杂度。
"O"的定义: 若f(n)是正整数n的一个函数,则 O(f(n))表示 M≥0 ,使得当n ≥ n0时,| f(n) | ≤ M | f(n0) | 。
表示时间复杂度的阶有:
O(1) :常量时间阶
O (n):线性时间阶
O(㏒n) :对数时间阶
O(n㏒n) :线性对数时间阶
O (n^k): k≥2 ,k次方时间阶
下面看个例子:
for(i=1,i<=n; ++i) {
for(j=1; j<=n; ++j) {
c[i][j]=0 ;
for(k=1; k<=n; ++k) {
c[i][j]+=a[i][k]*b[k][j] ;
}
}
}
由于是一个三重循环,每个循环从1到n,则总次数为: n×n×n=n3 时间复杂度为T(n)=O(n3)
空间复杂度
空间复杂度(Space complexity) :是指算法编写成程序后,在计算机中运行时所需存储空间大小的度量。记作: S(n)=O(f(n))
其中: n为问题的规模(或大小)
该存储空间一般包括三个方面:
- 指令常数变量所占用的存储空间;
- 输入数据所占用的存储空间;
- 辅助(存储)空间。
- 一般地,算法的空间复杂度指的是辅助空间。
- 一维数组a[n]: 空间复杂度 O(n)
- 二维数组a[n][m]: 空间复杂度 O(n*m)
冒泡排序
排序思想
依次比较相邻的两个记录的关键字,若两个记录是反序的(即前一个记录的关键字大于后前一个记录的关键字),则进行交换,直到没有反序的记录为止。
① 首先将L->R[1]与L->R[2]的关键字进行比较,若为反序(L->R[1]的关键字大于L->R[2]的关键字),则交换两个记录;然后比较L->R[2]与L->R[3]的关键字,依此类推,直到L->R[n-1]与L->R[n]的关键字比较后为止,称为一趟冒泡排序,L->R[n]为关键字最大的记录。
② 然后进行第二趟冒泡排序,对前n-1个记录进行同样的操作。
排序示例
设有9个待排序的记录,关键字分别为23, 38, 22, 45, 23, 67, 31, 15, 41,冒泡排序的过程如下图所示

算法实现:
/**
* 冒泡排序
*
* @param data
*/
public static void bubbleSort(int[] data) {
for (int i = 0; i < data.length - 1; i++) {
for (int j = 0; j < data.length - 1 - i; j++) {
if (data[j] > data[j + 1]) {
int temp = data[j];
data[j] = data[j + 1];
data[j + 1] = temp;
}
}
}
}
快速排序
排序思想
通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,再分别对这两部分记录进行下一趟排序,以达到整个序列有序。
排序过程
设待排序的记录序列是R[s…t] ,在记录序列中任取一个记录(一般取R[s])作为参照(又称为基准或枢轴),以R[s].key为基准重新排列其余的所有记录,方法是:
- 所有关键字比基准小的放R[s]之前;
- 所有关键字比基准大的放R[s]之后。
以R[s].key最后所在位置i作为分界,将序列R[s…t]分割成两个子序列,称为一趟快速排序。
一趟快速排序方法
从序列的两端交替扫描各个记录,将关键字小于基准关键字的记录依次放置到序列的前边;而将关键字大于基准关键字的记录从序列的最后端起,依次放置到序列的后边,直到扫描完所有的记录。
设置指针low,high,初值为第1个和最后一个记录的位置。
设两个变量i,j,初始时令i=low,j=high,以R[low].key作基准(将R[low]保存在R[0]中) 。
① 从j所指位置向前搜索:将R[0].key与R[j].key进行比较:
- 若R[0].key≤R[j].key :令j=j-1,然后继续进行比较, 直到i=j或R[0].key>R[j].key为止;
- 若R[0].key>R[j].key :R[j]R[i],腾空R[j]的位置, 且令i=i+1;
② 从i所指位置起向后搜索:将R[0].key与R[i].key进行比较: - 若R[0].key≥R[i].key :令i=i+1,然后继续进行比较, 直到i=j或R[0].key
- 若R[0].key
- 若R[0].key
一趟排序示例
设有6个待排序的记录,关键字分别为29, 38, 22, 45, 23, 67,一趟快速排序的过程如图下图所示。

算法实现:
/**
* 查找中轴所在位置
*
* @param data
* @param low
* @param high
* @return
*/
public static int getMiddle(int[] data, int low, int high) {
//取第一个元素作为基准点
int key = data[low];
while (low < high) {
//从后半部分向前扫描
while (data[high] >= key && high > low) {
high--;
}
//比中轴小的记录移到低端
data[low] = data[high];
//从前半部分向后扫描
while (data[low] <= key && high > low) {
low++;
}
//比中轴大的记录移到高端
data[high] = data[low];
}
data[low] = key;
// 返回中轴的位置
return low;
}
/**
* 递归形式的分治排序算法
*
* @param data
* @param low
* @param high
*/
public static void quickSort(int[] data, int low, int high) {
if (low < high) {
//将数组一分为二
int index = getMiddle(array, low, high);
quickSort(array, low, index - 1);
quickSort(array, index + 1, high);
}
}
选择排序
选择排序(Selection Sort)的基本思想是:每次从当前待排序的记录中选取关键字最小的记录表,然后与待排序的记录序列中的第一个记录进行交换,直到整个记录序列有序为止。
简单选择排序(Simple Selection Sort ,又称为直接选择排序)的基本操作是:通过n-i次关键字间的比较,从n-i+1个记录中选取关键字最小的记录,然后和第i个记录进行交换,i=1, 2, … n-1 。
设有关键字序列为:7, 4, -2, 19, 13, 6,直接选择排序的过程如下图所示。

算法实现:
/**
* @param data
*/
public static void selectSort(int[] data) {
for (int i = 0; i < data.length; i++) {
//待确定的位置
int k = i;
// 选最小的记录
for (int j = k + 1; j < data.length; j++) {
if (data[j] < data[k]) {
k = j;
}
}
//交换a[i]和a[k]
if (i != k) {
int temp = data[i];
data[i] = data[k];
data[k] = temp;
}
}
}
插入排序
采用的是以 “玩桥牌者”的方法为基础的。即在考察记录Ri之前,设以前的所有记录R1, R2 ,…., Ri-1已排好序,然后将Ri插入到已排好序的诸记录的适当位置。
最基本的插入排序是直接插入排序(Straight Insertion Sort) 。
排序思想
将待排序的记录Ri,插入到已排好序的记录表R1, R2 ,…., Ri-1中,得到一个新的、记录数增加1的有序表。 直到所有的记录都插入完为止。
设待排序的记录顺序存放在数组R[1…n]中,在排序的某一时刻,将记录序列分成两部分:
- R[1…i-1]:已排好序的有序部分;
- R[i…n]:未排好序的无序部分。
显然,在刚开始排序时,R[1]是已经排好序的。
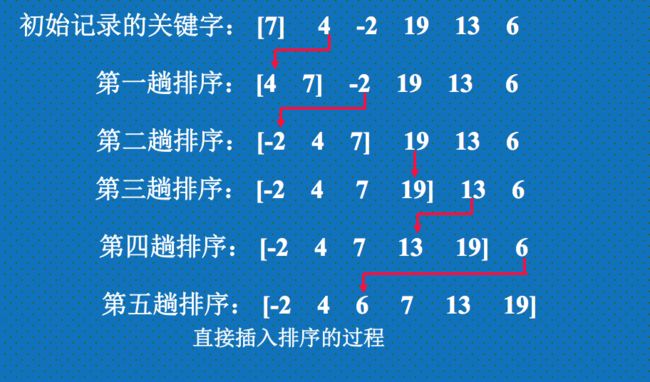
设有关键字序列为:7, 4, -2, 19, 13, 6,直接插入排序的过程如下图所示:
算法实现:
/**
*
* @param data
*/
public static void insertionSorts(int[] data) {
for (int i = 1; i < data.length; i++) {
int temp = data[i];
int j = i - 1;
// 从右到左扫描有序区
while (j >= 0 && temp < data[j]) {
// 将左侧有序区中元素比array[i]大的array[j+1]后移
data[j + 1] = data[j];
j--;
}
// 将右侧无序区第一个元素tmp = array[i]放到正确的位置上
data[j + 1] = temp;
}
}