基于注意力机制的细腻度图像分类
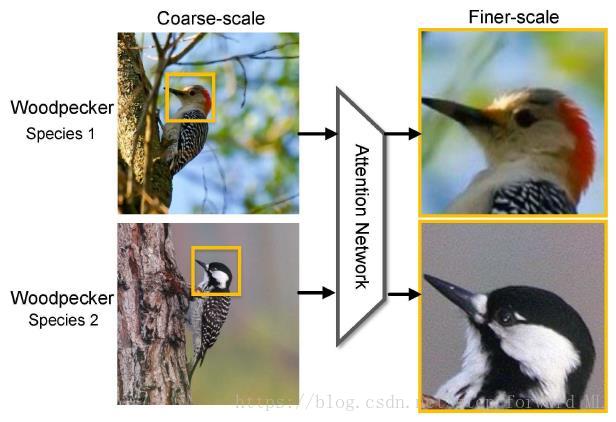
细腻度图像分类相比普通的图像分类具有更大的挑战,因为在细腻度图像类别中类间差异往往只聚焦于很小的一个区域。比如在下图海鸥的3个品种中,差异仅仅体现在喙与脚;而在人类活动识别(human activity recognition)中的弹奏乐器与拿着乐器也仅仅体现在手和嘴上。针对这一类分类任务可采用强监督的学习方式,即根据下图中额外的bounding box信息去学习相应的模型;然而,一方面强监督的学习框架需要额外的标注信息;另一方面人为标定的区域(region)不一定是最适合模型分类的区域。因此基于非监督(注意这里的非监督指不需要bounding box信息,但是在模型学习中仍需要图像的label信息)的细腻度图像分类模型在现实世界中更加通用与有效。在CVPR2017中一篇oral论文Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition,提出了一个很有效的非监督学习模型, 能取得和采用类似bounding box标注的算法效果。

总的来说,该论文基于注意力机制的网络模型不断聚焦到最具辨别性的区域实现图像的分类,如下图,由粗尺度的啄木鸟原始图像聚焦到了更具辨别性的头部区域;如此反复聚焦到更细的尺度,使得模型类似于循环神经网络的流程。因此文中提出的模型叫Recurrent Attention Convolutional Neural Network (RA-CNN)。下面详细阐述模型的网络结构。
RA-CNN结构如下图所示:
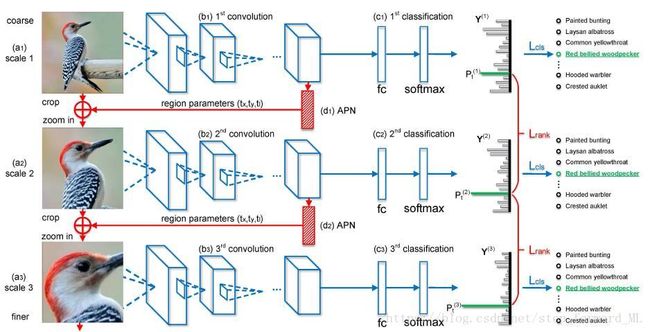
可以看出,RA-CNN由上到下用了3个尺度并且越来越精细,尺度间构成循环,即上层的输出作为当层的输入。RA-CNN主要包含两部分:每一个尺度上的卷积网络和相邻尺度间的注意力提取网络(APN, Attention Proposal Network)。在每一个尺度中,使用了堆叠的卷积层等,最后接上全连接层于softmax层,输出每一个类别的概率;这个是很好理解的,文中采用的网络结构是VGG的网络结构。
APN实质是一个包含2个全连接层的网络,它的输入是卷积网络中的最后一层卷积层,输出是一个正方形区域( tx,ty,tl t x , t y , t l ),其中 tx,ty t x , t y 表示该区域的中心坐标, tl t l 表示该区域边长的一半。那么该辨别的正方形区域的左上坐标(top-left)和右下坐标(bottom-right)就可表示为
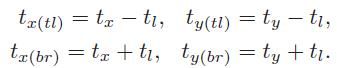
有了APN的区域输出,我们就聚焦了一个辨别区域 [tx,ty,tl] [ t x , t y , t l ] ,那么从上一个尺度的图像中截取此辨别区域 [tx,ty,tl] [ t x , t y , t l ] 的图像数据为:
其中 ⊙ ⊙ 为矩阵的对应元素相乘操作符,而 M(.) M ( . ) 表示一个掩模矩阵(attention
mask)。文中进一步指出,为了进行网络结构的学习,作者针对这里的crop操作采用了近似的连续函数boxcar function,即
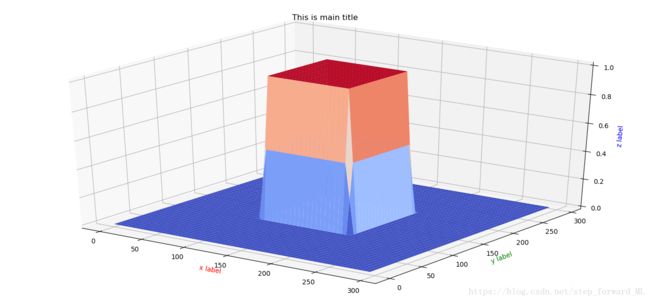
其中 h(x)=1/(1+exp{−kx}) h ( x ) = 1 / ( 1 + exp { − k x } ) 为logistic函数,当 k k 足够大时, h(x) h ( x ) 类似于一个阶跃函数(step fuction);式中的 tx(tl),tx(br),tx(tl),tx(br) t x ( t l ) , t x ( b r ) , t x ( t l ) , t x ( b r ) 为截取区域的左上,右下坐标。例如,假设截取正方形区域中心为 (150,150) ( 150 , 150 ) ,半边长为50, k=1000 k = 1000 ,那么M所产生的三维曲面如下图。从图中可以看出在截取区域内的值为1,边界区域0.5,其它区域为0。那么生成的M掩模矩阵能很好的进行截取区域的近似。并且该boxcar function为连续函数,使得在BP算法中计算梯度成为可能。
这里为了进一步有效的提取区域的特征,作者对截取区域进行了双线性插值放大。然后,再输入到卷积网络中。以上就是APN的实现细节,而其损失函数采用了成对的排序损失(pairwise ranking loss),即使得当前尺度的卷积网络的概率输出大于上一尺度的概率输出。直白的理解就是,通过APN后,获取了图像的辨别区域;那么预测的图像正确类别的输出概率会随着尺度的加深越来越大。最终,总的损失包含卷积网络的各尺度的输出损失和各个APN的成对排序损失,定为:
其中 lcls l c l s 为卷积网络损失,即为常见的交叉熵损失函数; lrank l r a n k 为成对排序损失,具体定义为
这样的损失函数设计使得在训练过程中,以粗尺度的概率输出作为参考,并强制细尺度得到更好的输出以不断的聚焦到最具辨别性的区域。
整个网络的训练采用交替的训练策略,步骤如下:
- 初始化:直接从ImageNet训练的VGG的参数初始化卷积网络;
- 预训练APN:在卷积网络的最后一个卷积层里选取响应最大的区域作为APN的输出区域,其中该输出区域的大小初始化为原始图像的一半。这样有了区域 [tx,ty,tl] [ t x , t y , t l ] ,我们就可以预训练图中的2个APN网络( d1,d2 d 1 , d 2 );
- 交替训练:固定APN的参数,训练卷积网络;固定卷积网络的参数,训练APN;直到两者的 loss 不再变化。注意,在参数 tl t l 的更新中,作者加入了约束,即当前尺度的 tl t l 大小不得小于上一尺度的 1/3 1 / 3 ,以保证截取区域的结构完整性。其中,截取操作采用了具有连续性质的 boxcar 函数,成对排序损失 lrank l r a n k 对参数 [tx,ty,tl] [ t x , t y , t l ] 的求导是很容易的;有了 lrank l r a n k 对参数 [tx,ty,tl] [ t x , t y , t l ] 的梯度,再往回传,即就是更新APN网络中2个全连接层的权重参数。
该论文采用通过尺度内分类损失(intra-scale classification loss)和尺度间排序损失(inter-scale ranking loss)进行优化,以相互学习精准的区域注意力和细粒度表征。最后的实验结果表面RA-CNN 并不需要边界框或边界部分的标注,即可达到和采用类似bounding box标注的算法效果,并且可以进行端到端的训练。