Elasticsearch面试题
1,什么是ElasticSearch?
Elasticsearch是一个基于Lucene的搜索引擎。它提供了具有HTTP Web界面和无架构JSON文档的分布式,多租户能力的全文搜索引擎。Elasticsearch是用Java开发的,根据Apache许可条款作为开源发布。
Lucene工作原理
1)、Lucene 是一个 JAVA 搜索类库,它本身并不是一个完整的解决方案,需要额外的开发工作。
2)、Document文档存储、文本搜索。
3)、Index索引,聚合检索。
4)、Analyzer分词器,如IKAnalyzer、word分词、Ansj、Stanford等
5)、大数据搜索引擎解决方案原理
6)、NoSQL的兴起(Redis、MongoDB、Memecache)
Lucene工作原理

关系型数据库和ES操作姿势对比
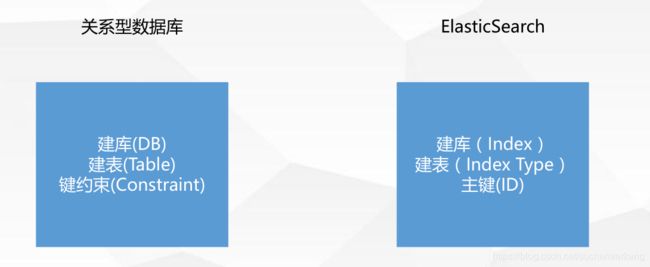

2,您可以在文档上执行哪些基本操作?
可以在文档中进行以下操作:
a.使用ELASTICSEARCH索引文档内容。
b.使用ELASTICSEARCH抓取文档内容。
C.使用ELASTICSEARCH更新文档内容。
d.使用ELASTICSEARCH删除文档内容。
3,Elasticsearch中的倒排索引是什么?
- 正排索引:文档id到单词的关联关系
- 倒排索引:单词到文档id的关联关系
示例:
对以下三个文档去除停用词后构造倒排索引
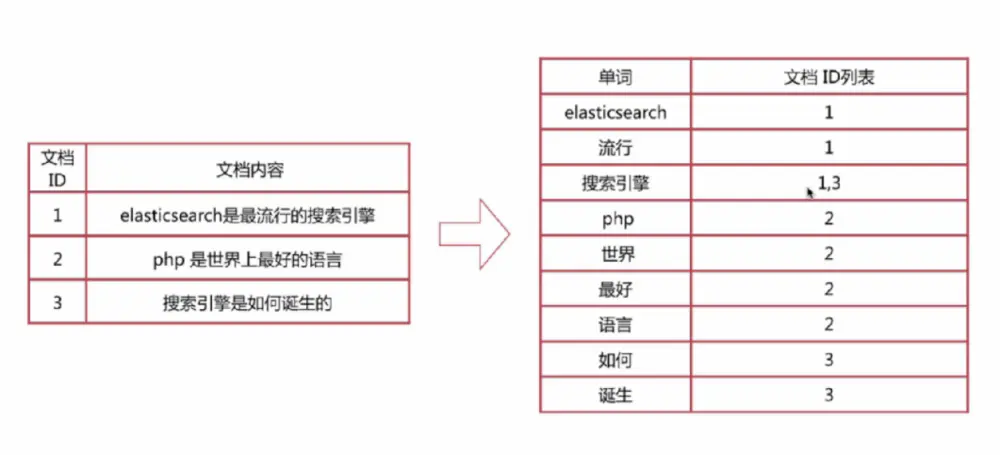
倒排索引-查询过程
查询包含“搜索引擎”的文档
- 通过倒排索引获得“搜索引擎”对应的文档id列表,有1,3
- 通过正排索引查询1和3的完整内容
- 返回最终结果
倒排索引-组成
- 单词词典(Term Dictionary)
- 倒排列表(Posting List)
单词词典(Term Dictionary)
单词词典的实现一般用B+树,B+树构造的可视化过程网址: B+ Tree Visualization
关于B树和B+树
维基百科-B树
维基百科-B+树
B树和B+树的插入、删除图文详解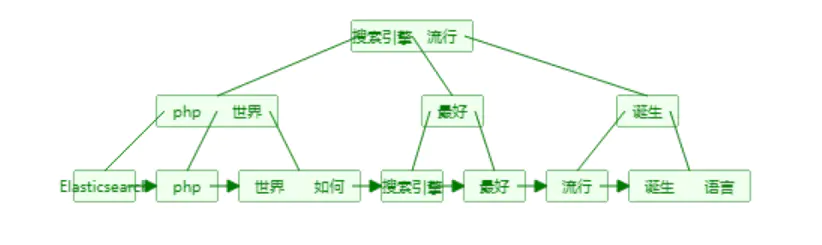
倒排列表(Posting List)
倒排列表记录了单词对应的文档集合,有倒排索引项(Posting)组成
倒排索引项主要包含如下信息:
1)文档id用于获取原始信息
2)单词频率(TF,Term Frequency),记录该单词在该文档中出现的次数,用于后续相关性算分
3)位置(Posting),记录单词在文档中的分词位置(多个),用于做词语搜索(Phrase Query)
4)偏移(Offset),记录单词在文档的开始和结束位置,用于高亮显示
B+树内部结点存索引,叶子结点存数据,这里的 单词词典就是B+树索引,倒排列表就是数据,整合在一起后如下所示
note:
B+树索引中文和英文怎么比较大小呢?unicode比较还是拼音呢?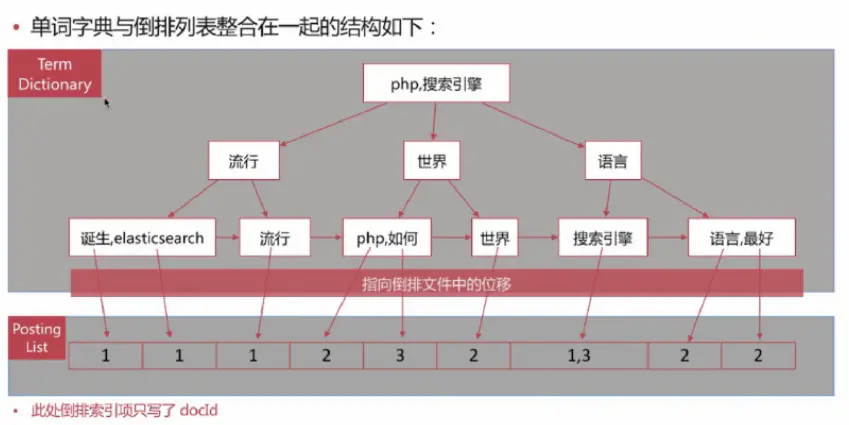
ES存储的是一个JSON格式的文档,其中包含多个字段,每个字段会有自己的倒排索引
4,分词器
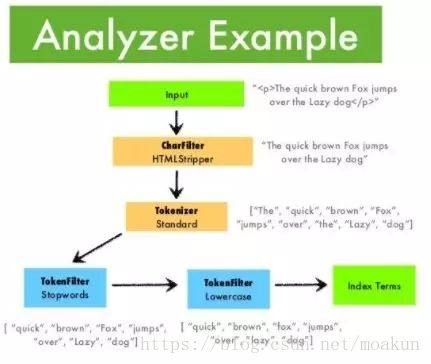
分词是将文本转换成一系列单词(Term or Token)的过程,也可以叫文本分析,在ES里面称为Analysis

分词器是ES中专门处理分词的组件,英文为Analyzer,它的组成如下:
Character Filters:针对原始文本进行处理,比如去除html标签
Tokenizer:将原始文本按照一定规则切分为单词
Token Filters:针对Tokenizer处理的单词进行再加工,比如转小写、删除或增新等处理
分词器调用顺序
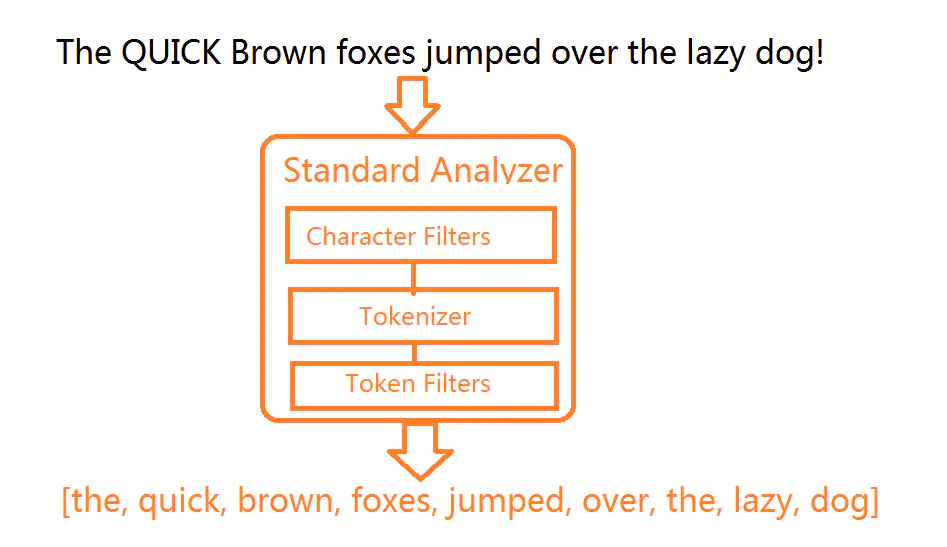
ES提供了一个可以测试分词的API接口,方便验证分词效果,endpoint是_analyze
- 可以直接指定analyzer进行测试

- 可以直接指定索引中的字段进行测试
POST test_index/doc
{
"username": "whirly",
"age":22
}
POST test_index/_analyze
{
"field": "username",
"text": ["hello world"]
}
- 可以自定义分词器进行测试
POST _analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": ["Hello World"]
}
预定义的分词器
ES自带的分词器有如下:
- Standard Analyzer
- 默认分词器
- 按词切分,支持多语言
- 小写处理
- Simple Analyzer
- 按照非字母切分
- 小写处理
- Whitespace Analyzer
- 空白字符作为分隔符
- Stop Analyzer
- 相比Simple Analyzer多了去除请用词处理
- 停用词指语气助词等修饰性词语,如the, an, 的, 这等
- Keyword Analyzer
- 不分词,直接将输入作为一个单词输出
- Pattern Analyzer
- 通过正则表达式自定义分隔符
- 默认是\W+,即非字词的符号作为分隔符
- Language Analyzer
- 提供了30+种常见语言的分词器
示例:停用词分词器
POST _analyze
{
"analyzer": "stop",
"text": ["The 2 QUICK Brown Foxes jumped over the lazy dog's bone."]
}
{
"tokens": [
{
"token": "quick",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "word",
"position": 2
},
{
"token": "foxes",
"start_offset": 18,
"end_offset": 23,
"type": "word",
"position": 3
},
{
"token": "jumped",
"start_offset": 24,
"end_offset": 30,
"type": "word",
"position": 4
},
{
"token": "over",
"start_offset": 31,
"end_offset": 35,
"type": "word",
"position": 5
},
{
"token": "lazy",
"start_offset": 40,
"end_offset": 44,
"type": "word",
"position": 7
},
{
"token": "dog",
"start_offset": 45,
"end_offset": 48,
"type": "word",
"position": 8
},
{
"token": "s",
"start_offset": 49,
"end_offset": 50,
"type": "word",
"position": 9
},
{
"token": "bone",
"start_offset": 51,
"end_offset": 55,
"type": "word",
"position": 10
}
]
}
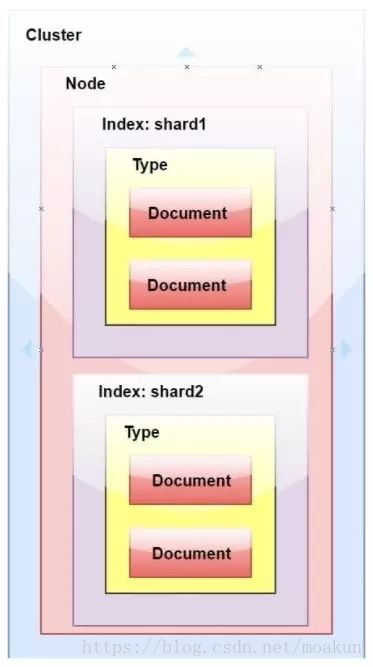
5,ElasticSearch中的集群、节点、索引、文档、类型是什么?
-
群集是一个或多个节点(服务器)的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。群集由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为如果节点设置为按名称加入群集,则该节点只能是群集的一部分。
-
节点是属于集群一部分的单个服务器。它存储数据并参与群集索引和搜索功能。
-
索引就像关系数据库中的“数据库”。它有一个定义多种类型的映射。索引是逻辑名称空间,映射到一个或多个主分片,并且可以有零个或多个副本分片。 MySQL =>数据库 ElasticSearch =>索引
-
文档类似于关系数据库中的一行。不同之处在于索引中的每个文档可以具有不同的结构(字段),但是对于通用字段应该具有相同的数据类型。 MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有属性的文档
-
类型是索引的逻辑类别/分区,其语义完全取决于用户。
6,ElasticSearch中的分片是什么?
在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。
-
索引 - 在Elasticsearch中,索引是文档的集合。
-
分片 -因为Elasticsearch是一个分布式搜索引擎,所以索引通常被分割成分布在多个节点上的被称为分片的元素。
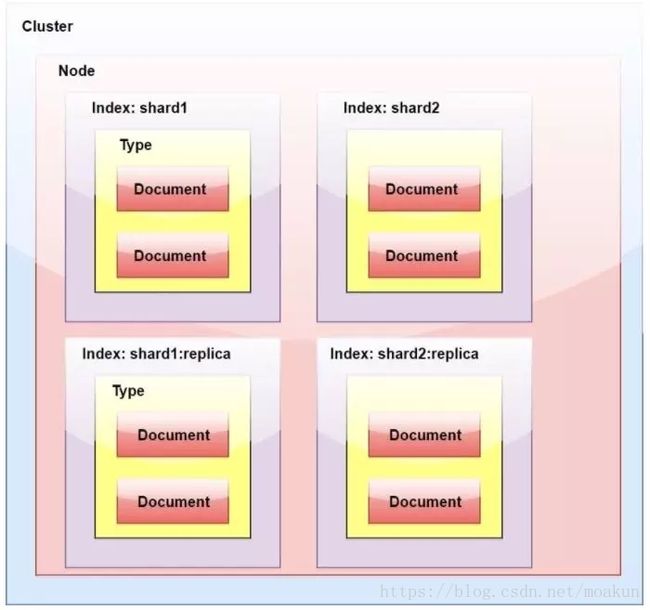
7,ElasticSearch中的副本是什么?
一个索引被分解成碎片以便于分发和扩展。副本是分片的副本。一个节点是一个属于一个集群的ElasticSearch的运行实例。一个集群由一个或多个共享相同集群名称的节点组成。
8,ElasticSearch中的分析器是什么?
在ElasticSearch中索引数据时,数据由为索引定义的Analyzer在内部进行转换。 分析器由一个Tokenizer和零个或多个TokenFilter组成。编译器可以在一个或多个CharFilter之前。分析模块允许您在逻辑名称下注册分析器,然后可以在映射定义或某些API中引用它们。
Elasticsearch附带了许多可以随时使用的预建分析器。或者,您可以组合内置的字符过滤器,编译器和过滤器器来创建自定义分析器。
9,什么是ElasticSearch中的编译器?
编译器用于将字符串分解为术语或标记流。一个简单的编译器可能会将字符串拆分为任何遇到空格或标点的地方。Elasticsearch有许多内置标记器,可用于构建自定义分析器。
10,什么是ElasticSearch中的过滤器?
数据由Tokenizer处理后,在编制索引之前,过滤器会对其进行处理。
11,启用属性,索引和存储的用途是什么?
enabled属性适用于各类ElasticSearch特定/创建领域,如index和size。用户提供的字段没有“已启用”属性。 存储意味着数据由Lucene存储,如果询问,将返回这些数据。
存储字段不一定是可搜索的。默认情况下,字段不存储,但源文件是完整的。因为您希望使用默认值(这是有意义的),所以不要设置store属性 该指数属性用于搜索。
索引属性只能用于搜索。只有索引域可以进行搜索。差异的原因是在分析期间对索引字段进行了转换,因此如果需要的话,您不能检索原始数据。