Join操作的总结以及在Presto中的使用
介绍
在对多表进行查询时,不可避免的会涉及到JOIN操作,但是由于存在多种类型的JOIN,有时会令人困惑。
本文首先会对常见的JOIN进行描述,由于分布式系统使用Presto对外提供查询接口,接着会介绍Presto中关于JOIN的一些独有的特性。最后列出了几个通用的JOIN的优化策略
常见的JOIN操作
为了方便演示,通过下面两张表进行演示
TableA
| id | name |
|---|---|
| 1 | Pirate |
| 2 | Monkey |
| 3 | Ninja |
| 4 | Spaghetti |
TableB
| id | name |
|---|---|
| 1 | Rutabaga |
| 2 | Pirate |
| 3 | Darth Vader |
| 4 | Ninja |
Inter Join
Inter Join产生的结果是A和B的以On交集。
语句:
SELECT * FROM TableA
INNER JOIN TableB
ON TableA.name = TableB.nameInter Join 包含两种:
- 显示(explicit) :就是上面这种方式
- 隐式(implicit):语句形式为SELECT * FROM TableA,TableB where TableA.name = TableB.name
多数情况下上面两种方式没有差别,但是建议使用第一种
结果:
| id | name | id | name |
|---|---|---|---|
| 1 | Pirate | 2 | Pirate |
| 3 | Ninja | 4 | Ninja |
图例:

Left Join(left outer join)
Left outer join产生表A的完全集,而B表中匹配的则有值,没有匹配的则以null值取代。
语句:
SELECT * FROM TableA
LEFT OUTER JOIN TableB
ON TableA.name = TableB.name结果:
| id | name | id | name |
|---|---|---|---|
| 1 | Pirate | 2 | Pirate |
| 2 | Monkey | null | null |
| 3 | Ninja | 4 | Ninja |
| 4 | Spaghetti | null | null |
图例:

Right Join(Right outer join)
right join 的效果和left join 的效果真好相反,这里不再描述
Full Join(FULL OUTER JOIN)
Full outer join 产生A和B的并集。但是需要注意的是,对于没有匹配的记录,则会以null做为值。
语句:
SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name结果:
| id | name | id | name |
|---|---|---|---|
| 1 | Pirate | 2 | Pirate |
| 2 | Monkey | null | null |
| 3 | Ninja | 4 | Ninja |
| 4 | Spaghetti | null | null |
| null | null | 1 | Rutabaga |
| null | null | 3 | Darth Vader |
图例:
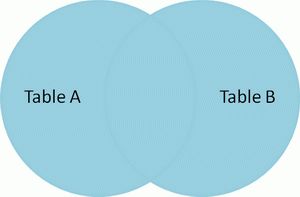
Cross Join
还需要注册的是我们还有一个是“交差集” cross join, 这种Join没有办法用文式图表示,因为其就是把表A和表B的数据进行一个N*M的组合,即笛卡尔积。
语句:
SELECT * FROM TableA
CROSS JOIN TableB 这个笛卡尔乘积会产生 4 x 4 = 16 条记录,一般来说,我们很少用到这个语法。但是我们得小心,如果不是使用嵌套的select语句,一般系统都会产生笛卡尔乘积然再做过滤。这是对于性能来说是非常危险的,尤其是表很大的时候。
其他
产生A表和B表都没有出现的数据集
语句:
SELECT * FROM TableA
FULL OUTER JOIN TableB
ON TableA.name = TableB.name
WHERE TableA.id IS null
OR TableB.id IS null结果:
| id | name | id | name |
|---|---|---|---|
| 2 | Monkey | null | null |
| 4 | Spaghetti | null | null |
| null | null | 1 | Rutabaga |
| null | null | 3 | Darth |
图例:

Presto的特有特性
多数据源Join
Presto 不仅提供了对上述几种JOIN类型的支持,而且还支持对不同的类型的数据表进行JOIN.这个特性对于数据放在不同的数据源中,又需要进行关联的场景很有帮助
例如,在Hive中有一个task_ip表,在mysql中有一个task表,两个表通过task_id进行关联,可以通过下面的Sql进行进行JOIN操作
select presto_table.task_id,presto_table.target_ip,mysql_table.risk_value
from hive.default.task_ip as presto_table
join mysql.test.task as mysql_table
on presto_table.task_id=mysql_table.id
where presto_table.log_time='2016101312'; Presto除了支持Hive,Mysql外还支持Redis,MongoDB以及PostgreSQL 等常用的数据库,关于各种类型数据源的配置以及Join支持情况,请参考官方文档:
https://prestodb.io/docs/current/connector.html
Join优化的建议
下面的JOIN优化建议来源于网络以及个人总结,适用于大多数的场景,仅供参考
1:多表Join时,数据越多的表越往后放
2:Left join时,条件过滤尽量在ON阶段完成,而少用WHERE
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据,在匹配阶段 WHERE 子句的条件都不会被使用。仅在匹配阶段完成以后,WHERE 子句条件才会被使用。它将从匹配阶段产生的数据中检索过滤。
不建议的方式:
select * from A
inner join B on B.name = A.name
left join C on C.name = B.name
left join D on D.id = C.id
where C.status>1 and D.status=1;建议的方式:
select * from A
inner join B on B.name = A.name
left join C on C.name = B.name and C.status>1
left join D on D.id = C.id and D.status=13:使用join取代子查询
在数据量比较大时,使用inner join取代exists与 使用left join取代 not exists性能上可以得到较大的提升
不建议的方式:
insert into t1(a1) select b1 from t2 where not exists(select 1 from t1 where t1.id = t2.r_id); select * from t1 where exists(select 1 from t2 where t1.id=t2.r_id);
建议的方式:
insert into t1(a1)
select b1 from t2
left join (select distinct t1.id from t1 ) t1 on t1.id = t2.r_id
where t1.id is null; select t1.* from t1
inner join (select distinct r_id from t2) t2 on t1.id= t2.r_id