训练CNN你需要知道的tricks/tips
Introduction
本文假设阅读者有基本的NN基础,涉及的tips有一下几点:
- data augmentation
- pre-process on images
- initializations of Networks
- some tips during training
- selections of activation functions
- diverse regularizations
- some insights found from figures and finally
- methods of ensemble multiple deep networks.
Data Augmentation
在数据量少的情况下,需要对图片做Augmentation.当然,在训练dnn时这一步是必不可少的。
data augmentation的基本方法有:
- translation
- rotation
- stretching
- shearing
- lens distortions,…
(一般对图片见减个均值或者scaling到【0-1】);
2. 对图片做fancy PCA,即对图片先做pca然后将特征值乘上一个正态分布 N(0,0.1) 的随机数;具体步骤如下:
- 计算所有RGB通道的PCA
- Sample some color offset along the principal components at each forward pass;
- Add the offset to all pixels in a training image.
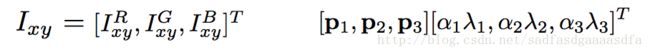
这种方法在imagenet 2012中top 1 精确度获得1%的提升。
github上的大神已经对Augmentation的操作有比较完整的实现:
Pre-Processing
- 在进行Aumentation后还可以做zero-center 或 normalize
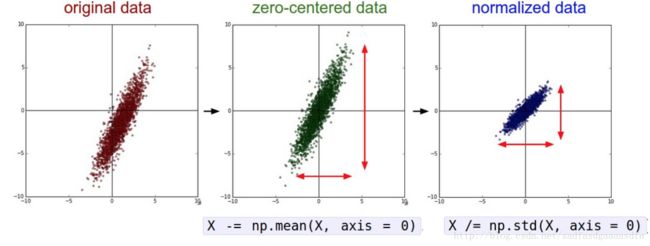
>>> X -= np.mean(X, axis = 0) # zero-center
>>> X /= np.std(X, axis = 0) # normalize- PCA Whitening 白化
在centered后,可以再进行pca whitening
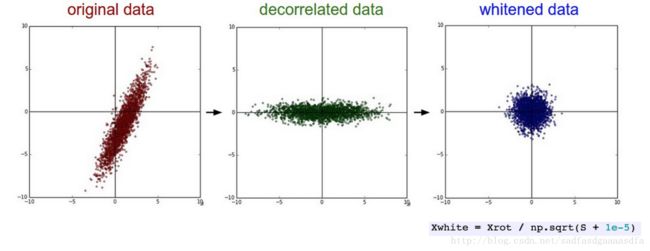
>>> U,S,V = np.linalg.svd(cov) # compute the SVD factorization of the data covariance matrix
>>> Xrot = np.dot(X, U) # decorrelate the data
>>> Xwhite = Xrot / np.sqrt(S + 1e-5) # divide by the eigenvalues (which are square roots of the singular values)最后一个操作是,将矩阵处以特征值进行白化,白化这种处理方法过分夸大了噪声。
(p.s. zero-center是必须的,在vgg中图片就是直接减去RGB固定的均值;但是尝试[0,1]化发现反而效果变差)像这些方法要根据自己的实际情况斟酌使用,并不是必须的!
初始化
初始化为0值
在理想状态下,对于正太分布的数据,把假设为权重一半为正一般为负是合理的。所以,将权重全部初始化为0看上去是合理的。但是,同样的权重会导致每个神经元的输出都是一样的输出,那么他们计算出的梯度相同,结果就是反馈更新后的权重都相同,这显然不合理。
用小的随机数初始化
即
![]()
这里使用均匀分布初始化也可以,但是会有一些影响。
方差校准(Calibrating the Variances)
上一个初始化方式随机初始化的方差会随着输入数据的增加而增加。可以用以下方式初始化
>>> w = np.random.randn(n) / sqrt(n)
# calibrating the variances with 1/sqrt(n)n 是输入数据的数量。这种方法在初始时可以近似地保证输出的分布是相同的,并且可以提高收敛速度;
在经过激活函数之前保证输出是同分布,不受到输入数据量的影响:

推荐的方法
上一种方法并没有考虑激活层(relus)的影响,在文献 中使用以下公式取得了良好的效果:
>>> w = np.random.randn(n) * sqrt(2.0/n) # current recommendation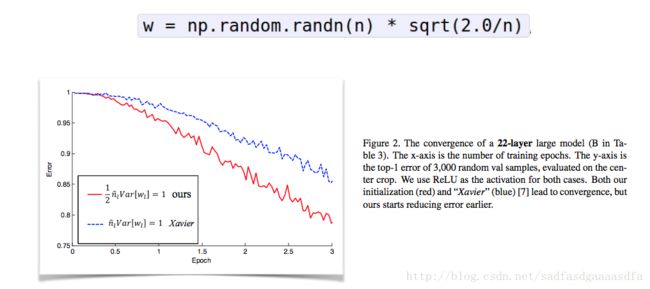
上图红线是 sqrt(2.0/n) 的结果,收敛速度比 sqrt(1.0/n) 的要快。
训练过程中的tricks
卷积和池化
- 使用2的指数次幂的图片作为输入,如32*32(cifar-10),224*224(imagenet)
- 卷积层使用3*3并且做zero padding,small strides既可以减少参数数量并且能够提高dnn的精度
- 池化层一般用2*2 (越大的效果越差)
Gradient normalization
把梯度除以minibatch的大小,这样就不用在采用不同batch大小时候大幅度改变learning rate的值。
learning rate
- LR 常用 0.1
- 使用交叉验证集
- 实际应用的建议:如果在validation set中不能精度不能提升了,可以尝试将少lr为原来的2倍(5倍)继续训练。
fine tuning
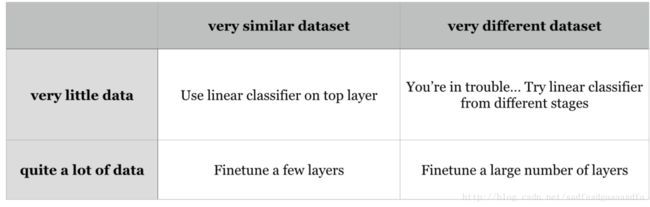
还要注意的是:
- 小数据集:对于finetuning的层建议随机初始化
- 大数据集:用更小的lr
- 对于不同的数据集而且数据少,可以尝试用靠前的某一层特征的权重或特征训练SVM。
激活函数
- sigmoid
- tanh
- ReLU(Rectified Linear Unit)
- Leaky ReLU
- Rarametric ReLU
- Randomized ReLU
sigmoid
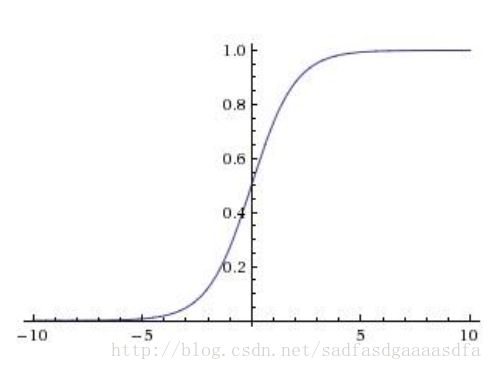
优点:
- 将数值“压缩到”[0,1]
- 饱和
缺点:
- 梯度消失
- 不是zero-centered
tanh
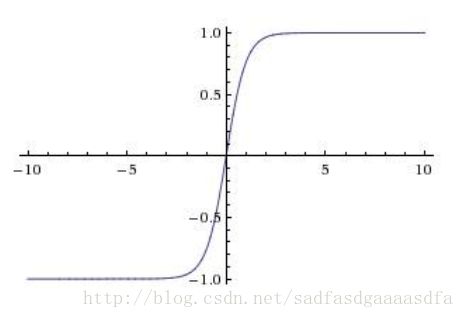
优点:
- 将数值“压缩到”[-1,1]
- zero-centered
缺点:
- 梯度消失
ReLU(Rectified Linear Unit)
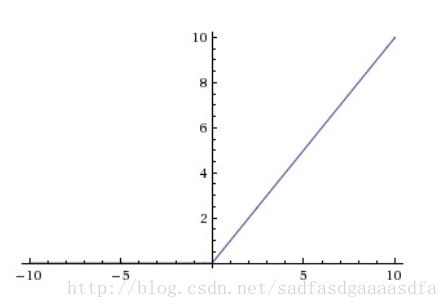
优点:
- 计算效率高
- 收敛速度快
其他各种ReLU变种
不详细介绍参见原文。
正则化
L2 regularization
L1 regularization
通常情况下,如果不做显式的特征选取,L2效果比L1好
L1 && L2
max norm constraints
对权重做L2的上限控制: ||w||2<c
Dropout
来自于
Dropout: A Simple Way to Prevent Neural Networks from Overfitting.
这个方法十分有效,即让每层的节点不工作,不更新。一般dropoutratio为 p=0.5
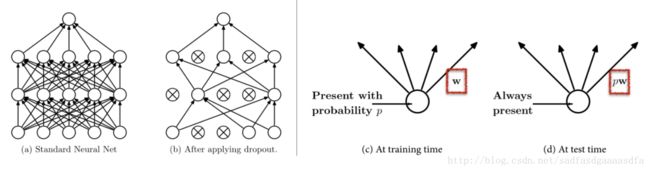
几种方法的比较

观察图表
通过观察目标函数(如交叉熵)或者精确度在每次的变化可以看出数据的学习率设置的是否合,是否有过拟合的情况。
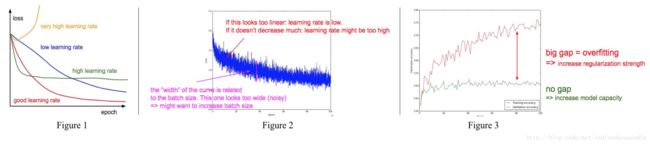
ensemble
最最最后,通过模型融合优化。有以下几种方式:
同模型,不同初始化参数
利用cv找出最佳超参,然后初始化不同的参数进行训练多个模型。这种方法的风险是各个模型的不同取决于初始化的情况。
不同模型
通过cv找出较好的几个不同模型进行融合
Different checkpoints of a single model
一个模型多个checkpoint 做融合。
一些经验
better ensemble method is to employ multiple deep models trained on different data sources to extract different and complementary deep representations相当于将好多不同的nn stack在一起。
可以看这两篇文献:
1. Deep Spatial Pyramid Ensemble for Cultural Event Recognition
2. S-NN: Stacked Neural Networks
本文原文来自:Must Know Tips/Tricks in Deep Neural Networks