Python课程学习笔记 下
笔记目录
- Python 学习笔记 上
- 面向对象和异常
- 面向对象
- 基本理论
- 定义类
- 根据类实例化对象
- 属性相关
- 方法相关
- 类的补充
- 属性补充
- 方法相关补充
- 描述器
- python对象的生命周期
- 内存管理机制
- 面向对象的三大特性
- 面向对象应当遵循的原则
- 错误和异常
- 错误和异常的概念
- 常见的系统异常和系统异常类继承树
- 异常的解决方式
- 手动抛出异常
- 自定义异常
- 包和虚拟环境
- 包和模块
- 包和模块的概念
- 包和模块的作用
- 包和模块的分类
- 包和模块的一般操作
- 第三方包和模块的安装和升级
- 包和模块的发布
- 虚拟环境
- 虚拟环境的补充
Python 学习笔记 上
Python 学习笔记 上
面向对象和异常
面向对象
基本理论
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 基本理论
# 什么是对象:万物皆对象
# 对象是具体的物体:拥有属性,拥有行为,把很多零散的东西封装成一个整体
# 比如张三:
# 属性:姓名、身高、年龄、体重
# 行为:走、跑、跳
# 在python中的体现:python是一门彻底的面向对象编程(oop)语言
# 面向对象和面向过程:都是解决问题的思路
# 面向过程:在解决问题的时候,关注的是解决问题的每一个步骤
# 面向对象:在解决问题的时候,关注的是解决问题所需要的对象
# 对比:
# 面向过程和面向对象都是解决问题的一种思想:面向对象是面向过程的封装
# 面向过程编程最重要的是:按步骤划分,将一个任务划分成具体的步骤
# 面向对象编程最重要的是:按功能对象划分,找到对象,确定对象的属性和行为
# 如何从面相过程编程过渡到面向对象编程:
# 1.列举出一个任务具体的步骤
# 2.分离这些实现步骤中的功能代码块
# 3.将这些功能代码块划分到一个对象中
# 4.根据这些对象及行为,抽象出对应的类(设计类)
# 什么是类:某一个具体对象特征的抽象
# 例如
# 张三这个具体的人:
# 属性:年龄:18 身高:180 体重:150···
# 行为:吃:抽烟 喝:白酒 赌 嫖 打架···
# 由张三抽象出来的类:不良青年:
# 属性:年龄 身高 体重···
# 行为:吃 喝 嫖 赌···
# 类的作用:根据抽象出来的类生产具体的对象
# 例如:
# 类:不良青年:
# 属性:年龄 身高 体重···
# 行为:吃 喝 嫖 赌···
# 形成对象:
# 张三:不同的属性和不同的行为
# 李四:不同的属性和不同的行为
# 王二麻子:不同的属性和不同的行为
# 类的组成:
# 名称
# 属性
# 方法
# 注意:以上的属性和方法都是抽象的概念(不良青年而不是具体的张三李四);在产生对象之后,对象才具有具体的属性值和方法实现
# 生活中的类:
# 钱:1毛,1元,5元,10元···
# 汽车品牌:大众,奥拓,马自达···
# 树:桃树、李子树、杏子书···
# 对象和类的关系:对象==>抽象==>类==>实例化==>对象
定义类
# 定义类
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 语法:
# class ClassName[()]:
# pass
# 注意:
# python中的类分为经典类和新式类
# 类的命名需要坚持大驼峰标识,单词首字母大写
# '()'可以选择加或者不加,加'()'是继承
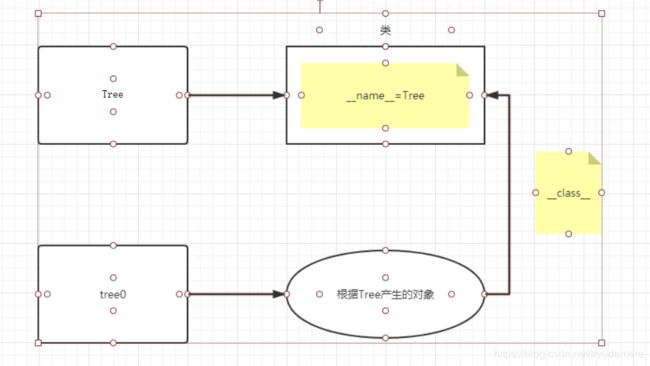
根据类实例化对象
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 根据一个类实例化一个对象
class Tree:
pass
# ClassName不仅是类名,也是变量名
tree = Tree() # tree就是通过类创建的一个对象
# 在pycharm下使用ClassName + .pri + TAB键 == print(ClassName)
print(tree)
Tree = 666
print(type(Tree), Tree)
print(tree.__class__)
print(tree)
# <__main__.Tree object at 0x00000265C9A8A400>
# 666
# 
属性相关
属性的含义以及和变量的区别
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 属性相关:
# 属性和变量的区别及判定依据:
# 区别:
# 概念:
# 变量是'可以改变的量值'
# 属性是'属于某个对象的特性'
# 访问权限:
# 变量:根据不同的位置,具有不同的访问权限(局部变量、全局变量···)
# 属性:只能通过对象来进行访问:
# 所以必须先找到对象
# 对象也是通过变量名来引用;因为是变量,也存在访问权限
# 判定依据:是否存在宿主(根据宿主的不同划分为类属性和对象属性)
对象属性的增删改查
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 对象属性:
# 增加对象属性:
# 语法:
# 方式一:ClassName.object = value
# 方式一:通过类的初始化方法(构造方法):__init__方法(python对象的生命周期)
class ProvincialCapital:
pass
captial = ProvincialCapital()
captial.Sichuan = '成都'
captial.HuNan = '长沙'
captial.HuBei = '武汉'
captial.Hei_Long_Jiang_city = ['哈尔滨', '齐齐哈尔', '牡丹江', '绥芬河', '佳木斯', '同江', '大庆']
# 查询对象属性:
# 语法:object.attributeName / object.__dict__ / object.attribute.属性可使用的查询方法
# 返回值:object.attributeName返回的是单个属性的值,object.__dict__以键值对的形式返回对象内所有属性和值,object.attribute.属性可使用的查询方法的返回值由具体的方法决定
# 注意:如果访问不存在的值会报错:AttributeError
print(captial.Sichuan)
print(captial.__dict__) # object.__dict__以键值对的形式返回对象内所有的属性
print(captial.Hei_Long_Jiang_city[1: 5])
# 成都
# {'Sichuan': '成都', 'HuNan': '长沙', 'HuBei': '武汉', 'Hei_Long_Jiang_city': ['哈尔滨', '齐齐哈尔', '牡丹江', '绥芬河', '佳木斯', '同江', '大庆']}
# ['齐齐哈尔', '牡丹江', '绥芬河', '佳木斯']
# 修改对象属性:
# 直接修改:object.attribute = newValue # 会修改属性的储存地址
# 访问修改:object.attribute.属性可使用的修改方式 # 根据属性的数据类型决定是否会修改储存地址
captial.Si_Chuan_city = ['成都', '绵阳', '攀枝花', '德阳', '巴中']
ID0 = id(captial.Si_Chuan_city)
captial.Si_Chuan_city = ['成都', '绵阳', '攀枝花', '德阳', '巴中', '自贡', '遂宁']
ID1 = id(captial.Si_Chuan_city)
print(ID0 == ID1)
captial.Si_Chuan_city.append('眉山')
ID2 = id(captial.Si_Chuan_city)
print(ID1 == ID2)
# False
# True
# 删除对象属性:
# 语法:
# del语句:直接删除整个属性或者属性内的多个值
# object.attributeName.属性可使用的删除方法 # 具体删除多少根据使用的方法而定
captial.Si_Chuan_city.remove('巴中')
print(captial.Si_Chuan_city)
# ['成都', '绵阳', '攀枝花', '德阳', '自贡', '遂宁', '眉山']
del captial.Hei_Long_Jiang_city
del captial.Si_Chuan_city[:5]
print(captial.__dict__)
# {'Sichuan': '成都', 'HuNan': '长沙', 'HuBei': '武汉', 'Si_Chuan_city': ['遂宁', '眉山']}
# 注意:不同的对象之间不能互相访问属性,否则会报错:AttributeError
类属性的增删改查
# 类属性:万物皆对象,类也是一种特殊的对象
# 增加类的属性:
# 方式一:ClassName.attribute = value
# 方式二:
# class ClassName:
# attribute0 = value0
# attribute1 = value1
# ···
# attribute = value
class ProvincialCity:
SiChuan = '成都'
HuNan = '长沙'
HuBei = '武汉'
ProvincialCity.HeBei = '石家庄'
# 查找类的属性:
# 方式一:通过类访问:ClassName.attribute
# 方式二:通过类创建的对象访问:object.attribute
# 注意:
# python查找对象的机制:
# 优先到对象自身查找属性,如果找到了就结束
# 如果没找到,则根据__class__找到创建对象的类,到这个类里面去查找
# 如果更改对象所属的类,不能查询原类的内容,否则会报错:AttributeError
class Chinese:
compulsoryOne = '离骚'
compulsoryTwo = '赤壁赋'
compulsoryThree = '过秦论'
class Math:
ElectiveOne = '逻辑、圆锥曲线、导数'
ElectiveFour = '不等式'
Title = Chinese()
Title.compulsoryOne = '沁园春·长沙'
print(Chinese.compulsoryOne, Title.compulsoryTwo)
print(Title.compulsoryOne, Chinese.compulsoryOne)
# 离骚 赤壁赋
# 沁园春·长沙 离骚
# 修改对象属性:
# 语法:ClassName.attribute = newValue
# 注意:不能使用object.attribute = newValue,这种做法只能修改对象的属性,如果这个属性不存在,那么将新建
Math.ElectiveFour = '不等式、柯西不等式'
print(Math.ElectiveFour)
Title.__class__ = Math # object.__class__ = ClassName修改对象的类
Title.ElectiveFour = '不等式和绝对值不等式、证明不等式的方法、柯西不等式、排序不等式、数学归纳法证明不等式'
print(Math.ElectiveFour) # 如果Math.ElectiveFour的值改变,那么object.attribute = newValue方法有效
print(Title.__dict__)
# 不等式、柯西不等式
# 不等式、柯西不等式
# {'compulsoryOne': '沁园春·长沙', 'ElectiveFour': '不等式和绝对值不等式、证明不等式的方法、柯西不等式、排序不等式、数学归纳法证明不等式'}
# 删除对象属性:
# 语法:del ClassName.attribute
# 注意:不能通过del object.attribute删除,该方法只能删除object自己的属性
del Math.ElectiveOne
print(Math.__dict__)
# {'__module__': '__main__', 'ElectiveFour': '不等式、柯西不等式', '__dict__': , '__weakref__': , '__doc__': None}
# 注意
# 注意:类属性的储存:
# 一般情况下属性存储在__dict__的字典中(但有些内置对象没有__dict__属性)
# 由类创建的对象可以直接修改__dict__属性
# 但类对象的__dict__只能读:一般无法修改,否则会报错:AttributeError: attribute '__dict__' of 'type'
# objects is not writable,可以通过setatttr方法修改,
class UserInformation:
name = 'David'
age = 19
print(UserInformation.__dict__)
# {'__module__': '__main__', 'name': 'David', 'age': 19, '__dict__': , '__weakref__': , '__doc__': None}
address = UserInformation()
address.__dict__ = {'address': '40N, 10E'}
print(address.address)
# 40N, 40N10E10E
# 类属性被各个对象共享
限制对象属性
```python
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 限制对象属性
# 语法:
# class ClassName:
# __slots__ = [attributeName0, attributeName1, ···]
# 注意:后续添加的属性必须是__slots__列表里面必须有的,否则会报错:ValueError: xxx in __slots__ conflicts with class variable
方法相关
概念及划分
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 方法的概念:
# 描述一个目标的行为动作,和函数非常相似:
# 都封装了一系列动作,被调用了之后执行这些动作;主要的区别在于调用的方式
# 方法的划分:
# 实例方法:默认第一个参数接收一个实例
# 类方法:默认第一个参数接收一个类
# 静态方法:第一个参数没有限制
# 注意事项:
# 划分的依据:方法的第一个参数必须要接收的数据类型
# 不管是哪种方法,都储存在类的__dict__属性中,没有储存在实例中
# 不同类型的方法调用方式也不同:
# 但都坚持一个原则:无论是我们传递还是解释器自动处理;最重要保证方法接收到的
# 第一个参数的类型是自己想要的类型
实例方法
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 实例方法
# 语法:
# class ClassName:
# def function(self, ···):
# pass
# 调用:
# 标准调用:object.function()
# 使用实例调用实例方法,不用手动传递,解释器会自动将调用对象本身传递过去
# 其他调用:本质都是直接找到函数本身来调用
# 使用类调用:ClassName.function()
# 其他调用:
# func = ClassName.function
# func()
# 注意:如果实例方法没有接受任何参数会报错:TypeError: unary_function() takes 0 positional arguments but 4 were given
# 解释器自动传递了参数,但是实例方法不需要接受参数
class MathCompulsoryOne:
def unary_function(self, k, x, b):
print('一元一次函数公式是f(x) = {0}x+{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
# 标准调用
func = MathCompulsoryOne()
func.unary_function(6, 2, 10)
# 使用类调用:
MathCompulsoryOne.unary_function(MathCompulsoryOne, 6, 2, 10)
# 其他调用:
Func = func.unary_function
Func(6, 2, 10)
# 一元一次函数公式是f(x) = 6x+10,当x = 2,f(x) = 22
# 一元一次函数公式是f(x) = 6x+10,当x = 2,f(x) = 22
# 一元一次函数公式是f(x) = 6x+10,当x = 2,f(x) = 22
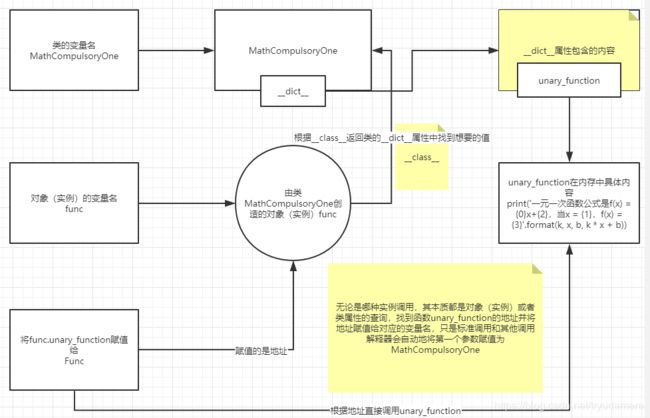
类方法
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 类方法
# 语法:
# class ClassName:
# @classmethod
# def function(self, ···)
# pass
# 调用:
# 标准方法:
# 方式一:ClassName.function()
# 方式二:
# func = ClassName()
# func.function()
# 间接调用:
# func = ClassName.function
# func()
class MathCompulsoryOne:
@classmethod
def unary_function(cls, k, x, b):
if b < 0:
print('一元一次函数公式是f(x) = {0}x{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
else:
print('一元一次函数公式是f(x) = {0}x+{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
func = MathCompulsoryOne()
# 方式一:
MathCompulsoryOne.unary_function(4, 10, -30)
# 一元一次函数公式是f(x) = 4x-30,当x = 10,f(x) = 10
# 方式二
func.unary_function(2, 5, 7)
# 一元一次函数公式是f(x) = 2x+7,当x = 5,f(x) = 17
# 间接调用:
func = MathCompulsoryOne.unary_function
func(4, 5, 6)
# 一元一次函数公式是f(x) = 4x+6,当x = 5,f(x) = 26
静态方法
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 静态方法
# 语法:
# class ClassName:
# @staticmethod
# def function(···):
# pass
# 调用:
# 标准方式:
# 方式一:ClassName.function()
# 方式二:
# func = ClassName()
# func.function()
# 其他调用:
# 方式三:
# func = ClassName.function
# func()
class MathCompulsoryOne:
@staticmethod
def unary_function(k, x, b):
if b < 0:
print('一元一次函数公式是f(x) = {0}x{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
else:
print('一元一次函数公式是f(x) = {0}x+{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
# 方式一:
MathCompulsoryOne.unary_function(4, 5, 6)
# 一元一次函数公式是f(x) = 4x+6,当x = 5,f(x) = 26
# 方式二:
func = MathCompulsoryOne()
func.unary_function(7, 8, 8)
# 一元一次函数公式是f(x) = 7x+8,当x = 8,f(x) = 64
# 方式三:
func = MathCompulsoryOne.unary_function
func(1, 2, 3)
# 一元一次函数公式是f(x) = 1x+3,当x = 2,f(x) = 5
注意事项
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 注意事项:不同类型的方法对不同类型属性的访问权限(一般情况下)
# 实例方法:类和实例(对象)的属性都能访问
# 类方法:只能访问类的属性
# 静态方法:类和实例(对象)的属性都不能访问
# 此处和类和实例(对象)的查询有关,类方法和实例方法会将类和实例(对象)当作参数传递进去,访问权限自然取决于类和实例(对象)的
# 访问方式,而静态方法不会讲类和实例(对象)传递进去,因而谁都不能访问
# 如果调用了不能调用的属性会报错:AttributeError
class ProvinceCity:
Si_Chuan = '成都市、自贡市、攀枝花市、泸州市、德阳市、绵阳市、广元市、遂宁市、内江市、乐山市、南充市···'
Hu_Nan = '长沙、株洲、湘潭、怀化···'
def si_chuan(self):
print(self.Si_Chuan)
print(self.Si_Chuan_Other)
@classmethod
def hu_nan(cls):
print(cls.Hu_Nan)
@staticmethod
def blank():
print(ProvinceCity.Hu_Nan)
print(Province_city.Si_Chuan_Other)
# 实例方法调用类和实例属性
Province_city = ProvinceCity()
Province_city.Si_Chuan_Other = '眉山市、宜宾市、广安市、达州市、雅安市、巴中市、资阳市、阿坝藏族羌族自治州、甘孜藏族自治州、凉山彝族自治州'
Province_city.si_chuan()
# 成都市、自贡市、攀枝花市、泸州市、德阳市、绵阳市、广元市、遂宁市、内江市、乐山市、南充市···
# 眉山市、宜宾市、广安市、达州市、雅安市、巴中市、资阳市、阿坝藏族羌族自治州、甘孜藏族自治州、凉山彝族自治州
# 类方法调用类属性
ProvinceCity.hu_nan()
# 长沙、株洲、湘潭、怀化···
# 静态方法调用类或者实例属性必须先查找
ProvinceCity.blank()
# 长沙、株洲、湘潭、怀化···
# 眉山市、宜宾市、广安市、达州市、雅安市、巴中市、资阳市、阿坝藏族羌族自治州、甘孜藏族自治州、凉山彝族自治州
类的补充
元类
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 元类:type
# 概念:创建类对象的类:类也是对象,是有另一个类创建出来的
num = 1
print(num.__class__)
print(num.__class__.__class__)
class Class:
pass
print(Class.__class__)
# 创建类的方法
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 创建类对象:
# 语法:
# 方式一:
# class ClassName:
# pass
# 方式二:
# ClassName = type(name, tuple, dict)
# 参数:name:类的名称, tuple:,dict:类包含的属性
# 方式二:
def address(self):
print(self.Address)
@classmethod
def age(cls):
print(cls.Age)
@staticmethod
def sex():
print('male')
PersonInformation = type('Jack', (), {'Name': 'Jack', 'sex': sex, 'address': address, 'Age': 17, 'age': age})
print(PersonInformation.__dict__)
# {'Name': 'Jack', 'sex': , 'address': , 'Age': 17, 'age': , '__module__': '__main__', '__dict__': , '__weakref__': , '__doc__': None}
PersonAddress = PersonInformation()
PersonAddress.Address = '100E, 40N'
PersonAddress.address()
# 100E, 40N
PersonInformation.age()
PersonAddress.age()
# 17
# 17
PersonInformation.sex()
PersonAddress.sex()
# male
# male
类的创建流程
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 类的创建流程:
# 1.检测类中是否有明确的__metaclass__属性
# 2.检测父类中是否有存在__metaclass__属性
# 3.检测模块中是否有存在__metaclass__属性
# 4.如果以上都没有则通过内置的type元类来创建这个类对象
# 元类的运用场景:
# 1.拦截类的创建
# 2.修改类
# 3.返回修改之后的类
# 明确类的__metaclass__属性
# type是内置元类(最大)
# __metaclass__ = 'xxx' # 模块级别的__metaclass__属性
#
#
# class Animal(metaclass='xxx'): # 类中明确方式一
# __metaclass__ = 'xxx' # 类中明确方式二
# pass
#
#
# class Dog(Animal): # 继承Animal的__metaclass__属性
# pass
类的描述
# 类的描述
# 语法:
# class ClassName:
# """
# 类的描述、作用、类的构造函数、类的属性
# """
# def function(self):
# """
# 这个方法的作用效果,参数以及参数的含义、类型、默认值,返回值的含义以及类型
# """
# 调用类的描述文档的方法:help(ClassName)
class MathCompulsoryOne:
"""
这个类的主要作用是获取用户输入的方程的参数并计算给定x时的f(x)值
"""
@classmethod
def unary_function(cls, k, x, b):
"""
这个方法主要是计算给定的一元一次方程的值
:param k:斜率,float类型
:param x:x的取值,float类型
:param b:截距,float类型
:return:没有返回值
"""
if b < 0:
print('一元一次函数公式是f(x) = {0}x{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
else:
print('一元一次函数公式是f(x) = {0}x+{2},当x = {1},f(x) = {3}'.format(k, x, b, k * x + b))
help(MathCompulsoryOne)
# Help on class MathCompulsoryOne in module __main__:
#
# class MathCompulsoryOne(builtins.object)
# | 这个类的主要作用是获取用户输入的方程的参数并计算给定x时的f(x)值
# |
# | Class methods defined here:
# |
# | unary_function(k, x, b) from builtins.type
# | 这个方法主要是计算给定的一元一次方程的值
# | :param k:斜率,float类型
# | :param x:x的取值,float类型
# | :param b:截距,float类型
# | :return:没有返回值
# |
# | ----------------------------------------------------------------------
# | Data descriptors defined here:
# |
# | __dict__
# | dictionary for instance variables (if defined)
# |
# | __weakref__
# | list of weak references to the object (if defined)
注释文档的生成
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 生成项目文档
# 方式一:cmd中使用内置模块pydoc
# 查看文档描述:python3 -m pydoc 模块名称(不需要后缀)
# 启动本地服务,浏览文档:python3 -m pydoc -p 端口地址
# 生成指定模块html文档:python3 -m pydoc -w 模块名称
# 方式二:使用第三方库:Sphinx, epydoc, doxygen
属性补充
私有化属性概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 私有化属性
# 概念:使得属性只能在某个固定的范围内访问
# 意义:保护数据安全
# 形式:
# attribute
# _attribute
# __attribute
# 注意:python并没有真正的私有化支持,当时可以通过下划线完成伪私有的效果;类属性和实例属性遵循相同的原则
公有属性的访问权限
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 公有属性的访问权限
# 能够访问的方式:
# 类内部
# 子类内部
# 模块内其他位置:
# 类访问:父类和派生类
# 实例访问:父类实例和派生实例
# 跨模块访问:使用import 模块名 / from 模块名 import *访问
class Currency:
Rmb = "¥"
Dollar = "$"
@classmethod
def output_rmb(cls):
print(cls.Rmb)
def output_dollar(self):
print(self.Dollar)
# 类的内部访问
Currency.output_rmb()
# ¥
# 子类内部访问
class Money(Currency):
def output_currency(self):
print(self.__Rmb)
print(self.__Dollar)
Money.output_currency()
# ¥
# $
# 实例访问
dollar = Currency()
dollar.output_dollar()
# $
# 派生实例访问
rmb = Money()
rmb.output_rmb()
# ¥
# 模块内其他位置访问
print(Currency.Rmb)
print(Money.Dollar)
# ¥
# $
# 跨模块访问
# Definition_Class.py
# num = 10
#
#
# class UserInformation:
# name = 'David'
# age = 19
import Definition_Class
print(Definition_Class.num)
print(Definition_Class.UserInformation.name)
# 10
# David
受保护的属性(_attribute)访问权限
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 受保护的属性(_attribute)访问权限
# 访问方式:
# 类内部 可以
# 子类内部 可以
# 模块内其他位置:
# 类访问:父类和派生类 可以,但pycharm有警告
# 实例访问:父类实例和派生实例 可以,但pycharm有警告
# 跨模块访问:
# 使用import 模块名 可以,但pycharm有警告
# from 模块名 import *访问 直接访问会报错:AttributeError: module 'Definition_Class' has no
# attribute '_num',如果一定要使用该方法访问,需在原模块首添加__all__ = [attribute]
class Currency:
_Rmb = "¥"
_Dollar = "$"
@classmethod
def output_rmb(cls):
print(cls._Rmb)
def output_dollar(self):
print(self._Dollar)
# 类的内部访问
Currency.output_rmb()
# ¥
# 子类内部访问
class Money(Currency):
def output_currency(self):
print(self.__Rmb)
print(self.__Dollar)
Money.output_currency()
# ¥
# $
# 实例访问
dollar = Currency()
dollar.output_dollar()
# $
# 派生实例访问
rmb = Money()
rmb.output_rmb()
# ¥
# 模块内其他位置访问
print(Currency._Rmb)
print(Money._Dollar)
# ¥
# $
# 跨模块访问
# __all__ = ['_num', 'UserInformation']
# Definition_Class.py
# _num = 10
#
#
# class UserInformation:
# _name = 'David'
# _age = 19
from Definition_Class import *
print(_num)
print(UserInformation._name)
# 10
# David
私有属性(__attribute)访问权限
# 私有属性(__attribute)访问权限
# 访问方式:
# 类内部 可以
# 子类内部 不可以
# 模块内其他位置:
# 类访问:父类 可以
# 派生类 不可以
# 实例访问:
# 父类实例 可以
# 派生实例 不可以
# 跨模块访问:
# 使用import 模块名 可以,但pycharm有警告
# from 模块名 import *访问 直接访问会报错:AttributeError: module 'Definition_Class' has no
# attribute 'num',如果一定要使用该方法访问,需在原模块首添加__all__ = [__attribute]
class Currency:
__Rmb = "¥"
__Dollar = "$"
@classmethod
def output_rmb(cls):
print(cls.__Rmb)
def output_dollar(self):
print(self.__Dollar)
# 类的内部访问
Currency.output_rmb()
# ¥
# 实例访问
dollar = Currency()
dollar.output_dollar()
# $
from Definition_Class import *
print(__num)
# 10
私有属性的实现机制
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 私有属性的实现机制
# 名字重整:解释器自动将__attribute改成另一个名字_ClassName__attribute
# 访问类外私有属性的方式:将想要访问的属性名称改为_ClassName__attribute
# 设置私有属性的目的:
# 防止外界直接访问
# 防止被子类同名称属性覆盖
class Currency:
__Rmb = "¥"
__Dollar = "$"
class Money(Currency):
@classmethod
def output_currency(cls):
print(cls.__dict__)
print(cls._Currency__Rmb)
print(cls._Currency__Dollar)
Money.output_currency()
# {'__module__': '__main__', 'output_currency': , '__doc__': None}
# ¥
# $
私有属性的应用场景
# 私有数据的应用场景:保护数据和过滤数据
class PersonInformation:
def __init__(self): # 该方法是给每个有这个类创建的实例(对象)添加默认的属性以及对应的值
self.__age = 18 # 保护数据
def get_age(self, value):
if isinstance(value, int) and 0 < value < 150: # 过滤数据
self.__age = value
else:
print('你输入的数据有误,将使用默认数据18岁')
def output_age(self):
return self.__age
Jack = PersonInformation()
Mike = PersonInformation()
Jack.get_age(20)
print(Jack.output_age())
print(Mike.output_age())
# 20
# 18
变量名称加下划线规范
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 变量添加下划线的规范
# xx_:与系统内置关键字做区分
# __xx__:系统内置的名称,例如:__dict__
只读属性
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 只读属性
# 应用场景:有些属性,只限在内部根据不同场景修改,对外界而言只能读取,不能修改
# 方式一:使用property方法简化操作(需要区分新式类和经典类)
# 属性全部隐藏:即属性的私有化,既不能读,也不能写
# 部分公开,公开读的操作
# python经典类和新式类的区别
# 经典类(python2.x中):定义类的时候不会继承任何属性,如果要在python2.x中定义新式类需要使用class ClassName(object)定义方法
# 新式类(python3.x中):定义类隐性继承object属性,默认为新式类,但是建议还是明确继承object属性,即使用class ClassName(object)
# 语法,方便在两个版本的解释器中使用。
# @property在新式类中的使用方法(property在经典类中只能使用读取的方法,其他方法不会报错但也不会运行)
# 使用方式一:
# 语法:
# class ClassName(object):
# __attribute_name = value
#
# @property
# def method_name(self): # 查询(也是最基础的,使用其他两个方法必须先设置该方法)
# return self.__attribute
#
# @method_name.setter # 更改
# def method_name(self, value):
# self.attribute_name = value
#
# @method_name.deleter # 删除
# def method_name(self):
# def self.__attribute
#
#
# object_name = ClassName()
# 使用方式二:
# 语法:
# class ClassName(object):
# __attribute_name = value
#
# def inquire_attribute(self): # 查询
# return self.__attribute
#
# def change_attribute(self, value): # 更改
# self.attribute_name = value
#
# def delete_attribute(self): # 删除
# def self.__attribute
#
# method_name = property(self[, inquire_attribute][, change_attribute][, delete_attribute])
# 调用:
# 查:object_name.method_name
# 改:object_name.method_name = new_value
# 删:del object_name.method_name
# 方式一:
class UserInformation(object):
def __init__(self):
self.__age = 18
self.__height = 170
self.__weight = 60
@property # 以属性的操作方式来操作方法
def output_information(self):
return self.__age, self.__height, self.__weight
@property
def age(self):
return self.__age
@age.setter
def age(self, value):
self.__age = value
@age.deleter
def age(self):
del self.__age
Jack = UserInformation()
age, height, weight = Jack.output_information
print('Jack的年龄是{},身高是{}cm,体重是{}kg'.format(age, height, weight))
Jack.age = 9 # 改
print(Jack.age) # 查
del Jack.age # 删
print(Jack.__dict__)
# Jack的年龄是18,身高是170cm,体重是60kg
# 9
# {'_UserInformation__height': 170, '_UserInformation__weight': 60}
# 方式二:
class UserInformation(object):
def __init__(self):
self.__age = 18
self.__height = 170
self.__weight = 60
def inquire_age(self):
return self.__age
def change_age(self, value):
self.__age = value
def delete_weight(self):
del self.__weight
age = property(inquire_age, change_age, delete_weight)
Jack = UserInformation()
print(Jack.age)
Jack.age = 12
print(Jack.age)
del Jack.age
print(Jack.__dict__)
# 18
# 12
# {'_UserInformation__age': 12, '_UserInformation__height': 170}
只读属性的补充
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 只读属性的补充
# python通过设置私有属性__attribute_name方法来实现只读属性可以通过object_name._ClassName__attribute_name或者
# object_name.__dict__[__attribute_name] = value来修改
# 此时可以通过使用__setattr__来避免第一种修改方式
# __setattr__的作用:当我们通过'object_name.attribute_name = value'来给一个实例增加或者修改属性的时候,都会调用这个方法
# 在这个方法内部只能通过object_name.__dict__[attribute_name] = value将属性储存到__dict__属性中(使用
# object_name.attribute_name = value会陷入死循环
# 语法:
# class ClassName(object):
# def __setattr__(self, key, value):
# if key == '__attribute_name' and key in self.__dict__.keys(): # 判断key是否是只读属性,以及是否在__dict__字典中
# pass
# else:
# self.__dict__[key] = value
class UserInformation(object):
def __setattr__(self, key, value):
print('属性名是{},值是{}'.format(key, value))
if key == 'age' and key in self.__dict__.keys():
pass
else:
self.__dict__[key] = value
Jack = UserInformation()
Jack.age = 19
print(Jack.__dict__)
Jack.age = 20
print(Jack.__dict__)
# 属性名是age,值是19
# {'age': 19}
# 属性名是age,值是20
# {'age': 19}
系统内置的特殊属性
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 系统内置的特殊属性
# 语法及作用:
# 类属性:
# ClassName.__dict__:查看类的所有属性
# ClassName.__bases__:查看类的所有父类,返回的是一个元组
# ClassName.__doc__:查看类的描述文档字符串
# ClassName.__name__:查看类的类名
# ClassName.__module__:查看类定义所在的模块
# 实例属性:
# object_name.__dict__:查看实例所有的属性
# object_name.__class__:实例对应的类
class UserInformation(object):
"""
这是类的描述
"""
age = 19
def __init__(self):
self.weight = 60
Jack = UserInformation()
print(UserInformation.__dict__)
print(UserInformation.__bases__)
print(UserInformation.__doc__)
print(UserInformation.__name__)
print(UserInformation.__module__)
print(Jack.__dict__)
print(Jack.__class__)
# {'__module__': '__main__', '__doc__': '\n 这是类的描述\n ', 'age': 19, '__init__': , '__dict__': , '__weakref__': }
# (,)
#
# 这是类的描述
#
# UserInformation
# __main__
# {'weight': 60}
# 方法相关补充
私有化方法
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 私有化方法
# 私有化方法的名字重整机制和私有化属性的一致:__method_name ==> _ClassName__method_name
# 使用方式和私有化属性一致,最好在类内部调用
内置特殊方法
信息格式化__str__
# _*_ coding:utf-8 _*_
# !/usr/bin/env python3
# 信息格式化:
# __str__(面向开发人员):将return后的字符串赋值给object,并可以直接通过object调用
# __repr__(面向解释器,可以通过eval()转化为__str__输出):将return后的语句赋值给object,并可以通过object直接调用
# 调用方式:
# 方式一:object
# 方式二:variable_name = str(object) / variable_name = repr(object)
# 注意:
# 在交互模式下可以直接使用object会输出__repr__对应的return语句
# 标准的__repr__可以通过eval(variable)将其转换为__str__输出格式
# 如果没有使用__str__,__repr__方法,那么使用object会输出object的类型和对应的内存地址
# 如果__str__,__repr__其中一个存在,使用方式一调用会返回其对应的return后的语句
# 如果__str__,__repr__同时存在,使用方式一调用只会返回__str__的return后的语句,__repr__需要使用第二种方式调用
def output(self):
print(self.age)
class UserInformation(object):
def __init__(self, n, a, h):
self.name = n
self.age = a
self.height = h
@staticmethod
def output(person):
return "这个人的名字是{},年龄是{}岁。身高是{}cm".format(person.name, person.age, person.height)
def __str__(self):
return "这个人的名字是{},年龄是{}岁。身高是{}cm".format(self.name, self.age, self.height)
def __repr__(self):
return 'Jack.output(Jack)'
Jack = UserInformation('Jack', 16, 180)
print(Jack.__repr__())
# print(Jack)
print(eval(Jack.__repr__()))
person_one = UserInformation('Jack', 36, 182)
print(person_one)
Jack_information_str = str(person_one)
print(Jack_information_str)
print(person_one) # 如果__str__,__repr__同时存在,使用方式一调用只会返回__str__的return后的语句,__repr__需要使用第二种方式调用
Jack_information_repr = repr(person_one)
print(Jack_information_repr)
print(eval(Jack_information_repr))
# Jack.output(Jack)
# 这个人的名字是Jack,年龄是16岁。身高是180cm
# 这个人的名字是Jack,年龄是36岁。身高是182cm
# 这个人的名字是Jack,年龄是36岁。身高是182cm
# 这个人的名字是Jack,年龄是36岁。身高是182cm
# Jack.output(Jack)
# 这个人的名字是Jack,年龄是16岁。身高是180cm
import datetime # __repr__(面向解释器,可以通过eval()转化为__str__输出)
now = datetime.datetime.now()
print(str(now))
new = repr(now)
print(new)
new = eval(new)
print(new)
# 2020-03-19 22:17:42.421954
# datetime.datetime(2020, 3, 19, 22, 17, 42, 421954)
# 2020-03-19 22:17:42.421954
调用操作
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 调用操作
# __call__方法
# 作用:使得对象具备当作函数,有调用的作用
# 应用场景:方法需要接收多个参数,但其中一个参数不会频繁改动
class Pen(object):
def __init__(self, pen_type):
self.pen_type = pen_type
def __call__(self, pen_color):
print('这支笔是{},是{}颜色'.format(self.pen_type, pen_color))
pencil = Pen('铅笔')
pencil('黑')
pencil('橘')
# 这支笔是铅笔,是黑颜色
# 这支笔是铅笔,是橘颜色
索引操作
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 索引操作
# 作用:可以对实例对象进行索引操作
# 语法:
# class ClassName(object):
# def __init__(self):
# self.Dict = {}
#
# def __setitem__(self, key, value):
# self.Dict[key] = value
#
# def __getitem__(self, item):
# return self.Dict[item]
#
# def __delitem__(self, item):
# del self.Dict[item]
class UserInformation(object):
def __init__(self):
self.Dict = {}
def __setitem__(self, key, value):
self.Dict[key] = value
def __getitem__(self, item):
return self.Dict[item]
def __delitem__(self, key):
del self.Dict[key]
Jack = UserInformation()
Jack['age'] = 16
print(Jack['age'])
del Jack['age']
print(Jack.Dict)
# 16
# {}
切片操作
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 切片操作
# 作用:可以对实例对象的属性进行索引操作
# 语法:
# class ClassName(object):
# def __init__(self):
# self.List = [] # 此处列表不能为空
#
# def __setitem__(self, key, value): # 改
# self.List[key] = value
#
# def __getitem__(self, item): # 查
# return self. List[item]
#
# def __delitem__(self, item): # 删
# del self.List[item]
class UserInformation(object):
def __init__(self):
self.List = [1, 2, 3, 4, 5, 6, 7, 8]
def __setitem__(self, key, value):
self.List[key] = value
def __getitem__(self, item):
return self.List[item]
def __delitem__(self, key):
del self.List[key]
Jack = UserInformation()
Jack[1: 5] = ['b', 'c', 'd', 'e']
print(Jack[2])
del Jack[1: 3]
print(Jack.List)
# c
# [1, 'd', 'e', 6, 7, 8]
比较操作(自定义比较的属性)
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 比较操作
# 作用:比较两个实例的某个属性值
# 语法:
# class ClassName(object):
# def __eq__(self, other): # 等于
# return
# def __ne__(self, other): # 不等于
# return
# def __gt__(self, other): # 大于
# return
# def __ge__(self, other): # 大于等于
# return
# def __lt__(self, other): # 小于
# return
# def __le__(self, other): # 小于等于
# return
# 调用:与普通的比较调用方式一样
# 注意:
# 如果设置一个比较方法,那么它对应的相对的方法也可以直接调用(实现机制:调换self和other的值)
# 不支持叠加操作,即设置了等于和大于的方法,来计算一个值是否大于另一个值
# 等于 <==> 不等于 小于 <==> 大于 小于等于 <==> 大于等于
class UserInformation(object):
def __init__(self, name, level):
self.name = name
self.level = level
def __eq__(self, other):
if self.level == other.level:
return '两人等级相等'
else:
return '两人等级不相等'
def __ge__(self, other):
print(self.level, other.level)
return self.level >= other.level
User_One = UserInformation('Jack', 141)
User_Two = UserInformation('Bob', 140)
print(User_One == User_Two)
print(User_One <= User_Two)
# 两人等级不相等
# 140 141
# False
# 比较操作的补充
# @functools.total_ordering装饰器
# 根据已有的比较方法补全对印的比较方法,同时可以叠加补充
# 语法:
# import functions
#
#
# @functools.total_ordering
# class ClassName(object):
# def __eq__(self, other):
# pass
#
# def __lt__(self, other):
# pass
import functools
@functools.total_ordering
class UserInformation(object):
def __init__(self, name, level):
self.name = name
self.level = level
def __eq__(self, other):
if self.level == other.level:
return '两人等级相等'
else:
return '两人等级不相等'
def __gt__(self, other):
print(self.level, other.level)
return self.level >= other.level
print(UserInformation.__dict__)
User_One = UserInformation('Jack', 141)
User_Two = UserInformation('Bob', 140)
print(User_One == User_Two)
print(User_One <= User_Two)
# {'__module__': '__main__', '__init__': , '__eq__': , '__gt__': , '__dict__': , '__weakref__': , '__doc__': None, '__hash__': None, '__lt__': , '__ge__': , '__le__': }
# 两人等级不相等
# 141 140
# False
# 控制实例在上下代码中的bool值
# __bool__方法
class IsTrue(object):
def __init__(self, num):
self.num = num
def __bool__(self):
return self.num > 20
a = IsTrue(15)
if a:
print('数值大于20')
else:
print('数值小于或者等于20')
# 数值小于或者等于20
遍历操作
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 遍历操作
# 语法:
# 方式一:使用for循环进行遍历:
# __getitem__方法 # 会一直遍历到抛出异常或者满足结束条件,不设置抛出异常的语句会陷入死循环
# __iter__方法,使用该方法遍历实例本身需要和__next__方法联合使用
# 方式二:使用__next__进行遍历:需要结合__next__方法
# 注意:__iter__的优先级高于__getitem__,即两个方法同时存在时,使用for循环遍历优先使用__iter__的返回值
# 如果要将实例变成一个迭代器,必须要实现__iter__,__next__两个方法,如果只是实现__iter__那么实例只是一个可迭代对象
# 检测方法:
# import collections
# isinstance(object_name, Iterator) # 查看实例是否是迭代器,返回值为bool值
# isinstance(object_name, Iterable) # 查看实例是否为可迭代对象,返回值为bool值
# for循环遍历
# __getitem__方法:
class Count(object):
def __init__(self):
self.count = 0
def __getitem__(self, item):
self.count += 1
if self.count >= 5:
raise StopIteration('越界了') # raise是抛出异常的语句
return self.count
a = Count()
for a in a:
print(a)
# 1
# 2
# 3
# 4
# __iter__方法:
class Count(object):
def __init__(self):
self.count = 0
def __iter__(self):
return self
def __next__(self):
self.count += 1
if self.count >= 5:
raise StopIteration('越界了') # raise是抛出异常的语句
return self.count
a = Count()
for a in a:
print(a)
# 1
# 2
# 3
# 4
# 注意:如果__iter__返回的是一个可迭代对象则不需要结合__next__使用
class Count(object):
def __init__(self):
self.count = 0
def __iter__(self):
return iter([1, 2, 3, 4, 5, 6])
a = Count()
for a in a:
print(a)
# 1
# 2
# 3
# 4
# 5
# 6
# 使用next函数遍历
# 结合__next__方法使用
class Count(object):
def __init__(self):
self.count = 0
def __next__(self):
self.count += 1
if self.count >= 5:
raise StopIteration('越界了') # raise是抛出异常的语句
return self.count
a = Count()
print(next(a))
print(next(a))
print(next(a))
print(next(a))
# 1
# 2
# 3
# 4
# iter()函数补充:增加停止条件
# iter(source, sentinel)
# 注意:sentinel取不到
class Count(object):
def __init__(self):
self.count = 0
def __iter__(self):
self.count = 0
return self
def __call__(self, *args, **kwargs):
self.count += 1
if self.count >= 5:
raise StopIteration('越界了') # raise是抛出异常的语句
return self.count
a = Count()
pt = iter(a, 4)
for i in pt:
print(i)
# 1
# 2
# 3
描述器
概念及定义方式
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 概念:描述一个属性操作的对象(描述器本身也是一个对象,可以对属性进行增删改查操作,还有描述属性)
# 作用:操作私有属性不需要以调用方法的方式进行
# 定义方式一:
# property
# 方式一:
# 语法:
# class ClassName(object):
# def __init__(self):
# __attribute = value
#
# @property
# def attribute(self):
# return self.__attribute
#
# @attribute.setattr
# def attribute(self, value):
# self.__attribute = value
#
# @attribute.deleter
# def attribute(self):
# del self.attribute
#
#
# object_name = ClassName()
# 调用:
# 增、改:object_name.attribute = value
# 查:print(object_name.attribute)
# 删:del object_name
#
# 方式二:
# 语法:
# class ClassName(object):
# def __init__(self):
# __attribute = value
#
# def get_attribute(self):
# return self.__attribute
#
# def set_attribute(self, value):
# self.__attribute = value
#
# def del_attribute(self):
# del self.attribute
#
# attribute = property(gat_attribute, set_attribute, del_attribute)
#
# object_name = ClassName()
# 调用:
# 增、改:object_name.attribute = value
# 查:print(object_name.attribute)
# 删:del object_name
# 定义方式二:
# 语法:
# class Descriptor(object):
# def __get__(self, instance, owner):
# return self.instance
#
# def __set__(self, instance, value):
# self.instance = value
#
# def __delete__(self, instance):
# del self.instance
#
#
# class ClassName(object):
# attribute = Descriptor()
#
#
# 调用:
# object = ClassName()
# print(object.attribute) # 调用Descriptor的__get__方法,获取属性值
# object.attribute = value # 调用Descriptor的__set__方法,更改属性值
# del object.attribute # 调用Descriptor的__delete__方法,删除属性
#
# 参数:self:描述器,instance:被描述的实例,owner:被描述的实例的父类
# 注意:
# 一般通过实例来修改属性,而不是通过类
# 定义方式一更加适合单个属性,定义方式二更加适合多个属性
# 描述器只在新式类中有效,即在python2.x中必须要两个类都要继承自object
# 定义方式一:
class RoleInformation(object):
def __init__(self, name, sex):
self.__name = name
self.__sex = sex
self.__level = 0
@property
def creating_role(self):
return self.__name, self.__sex
@creating_role.setter
def creating_role(self, args):
re_name, re_sex = args
self.__name = re_name
self.__sex = re_sex
@creating_role.deleter
def creating_role(self):
del self.__name
del self.__level
del self.__sex
user = RoleInformation('Jack', 'male')
print(user.creating_role)
user.creating_role = tuple(input('请输入名字和性别').split(','))
print(user.creating_role)
del user.creating_role
print(user.__dict__)
# ('Jack', 'male')
# 请输入名字和性别Mike, male
# ('Mike', ' male')
# {}
class RoleInformation(object):
def __init__(self, name, sex):
self.__name = name
self.__sex = sex
self.__level = 0
def get_creating_role(self):
return self.__name, self.__sex
def set_creating_role(self, args):
re_name, re_sex = args
self.__name = re_name
self.__sex = re_sex
def del_creating_role(self):
del self.__name, self.__sex, self.__level
creating_role = property(fget=get_creating_role, fset=set_creating_role, fdel=del_creating_role)
user = RoleInformation('Jack', 'male')
print(user.creating_role)
user.creating_role = tuple(input('请输入名字和性别').split(','))
print(user.__dict__)
del user.creating_role
print(user.__dict__)
# ('Jack', 'male')
# 请输入名字和性别Alice, female
# {'_RoleInformation__name': 'Alice', '_RoleInformation__sex': ' female', '_RoleInformation__level': 0}
# {}
# 定义方式二
class Descriptor(object):
def __get__(self, instance, owner):
return self.instance
def __set__(self, instance, value):
self.instance = value
def __delete__(self, instance):
del self.instance
class RoleInformation(object):
def __init__(self):
self.name = Descriptor()
self.sex = Descriptor()
user = RoleInformation()
user.name = 'Jack'
print(user.name)
user.sex = 'male'
print(user.sex)
del user.sex
print(user.__dict__)
# Jack
# male
# {'name': 'Jack'}
描述器的实现机制以及和属性同名时的优先级问题
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 描述器实现机制:
# 正常实例属性查询机制:
# 首先到实例对象本身的字典__dict__中查找
# 然后到对应的类对象的__dict__字典中查找
# 如果有父类,则前往父类的__dict__字典中查找
# 如果没找到,同时又定义了__getattr__方法,则会调用这个方法
# 带有描述器时的查询机制:__getattribute__
# 如果实现了__get__就会直接调用
# 如果没有则按照上述的正常机制运行
#
# 注意:如果已经定义了__get__方法,又实现了__getattribute__方法,那么__getattribute__会覆盖__get__方法(主要是针对描述器
# 定义方式二)
#
# 描述器分类:
# 资料描述器:实现了__get__, __set__方法
# 非资料描述器:仅仅实现了__get__一个方法
# 描述器的调用优先级(主要是针对描述器和属性同名):资料描述器 > 实例属性 > 非资料描述器
# 资料描述器与实例属性同名时:
class Descriptor(object):
def __get__(self, instance, owner):
return '执行了资料描述器'
def __set__(self, instance, value):
self.instance = value
def __delete__(self, instance):
del self.instance
class Information(object):
Descriptor = Descriptor()
def __init__(self):
self.Descriptor = '执行了实例属性'
I = Information()
print(I.Descriptor)
print(I.__dict__)
# 执行了资料描述器
# {}
# 实例属性与非资料描述器同名时:
class Descriptor(object):
def __get__(self, instance, owner):
print('执行了非资料描述器')
class Information(object):
Descriptor = Descriptor()
def __init__(self):
self.Descriptor = '执行了实例属性'
I = Information()
print(I.Descriptor)
print(I.__dict__)
# 执行了实例属性
# {'Descriptor': '执行了实例属性'}
描述器的值的储存问题
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 描述器值的储存
# 如果在__set__方法中设置为self.attribute_name = value,那么值的标识会被储存在实例的父类的__dict__字典中并将具体的值储存在描述器的__dict__字典,如果设置了多个实例,那么修改其中一个实例的值的时候,其他实例的值也会发生变化
# 如果在__set__方法中设置为instance.attribute_name = value,那么值的标识会被储存在实例的父类__dict__字典中并将具体的值储存在实例的__dict__字典,修改一个实例的值的时候其他实例的值不会发生变化
# 验证__set__方法设置为self.attribute_name = value
class Descriptor(object):
def __get__(self, instance, owner):
return self.v
def __set__(self, instance, value):
self.v = value
def __delete__(self, instance):
del self.v
class UserInformation(object):
name = Descriptor()
User0 = UserInformation()
User1 = UserInformation()
User0.name = 'Jack'
print(User0.name)
User1.name = 'Mike'
print(User0.name)
print(User1.name)
print(Descriptor.__dict__)
print(UserInformation.__dict__)
print(User0.__dict__)
print(User1.__dict__)
# Jack
# Mike
# Mike
# {'__module__': '__main__', '__get__': , '__set__': , '__delete__': , '__dict__': , '__weakref__': , '__doc__': None}
# {'__module__': '__main__', 'name': <__main__.Descriptor object at 0x00000234E535A400>, '__dict__': , '__weakref__': , '__doc__': None}
# {}
# {}
# 验证__set__方法设置为instance.attribute_name = value
class Descriptor(object):
def __get__(self, instance, owner):
return instance.v
def __set__(self, instance, value):
instance.v = value
def __delete__(self, instance):
del instance.v
class UserInformation(object):
name = Descriptor()
User0 = UserInformation()
User1 = UserInformation()
User0.name = 'Jack'
print(User0.name)
User1.name = 'Mike'
print(User0.name)
print(User1.name)
print(Descriptor.__dict__)
print(UserInformation.__dict__)
print(User0.__dict__)
print(User1.__dict__)
# Jack
# Jack
# Mike
# {'__module__': '__main__', '__get__': , '__set__': , '__delete__': , '__dict__': , '__weakref__': , '__doc__': None}
# {'__module__': '__main__', 'name': <__main__.Descriptor object at 0x000002A43E17A400>, '__dict__': , '__weakref__': , '__doc__': None}
# {'v': 'Jack'}
# {'v': 'Mike'}
使用类来装饰函数
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 使用类来装饰函数
# 语法:
# 方式一:
# class ClassName(object):
# def __init__(self, value):
# self.attribute_name = value
#
# def __call__(self, *args, *kwargs):
# 需要额外执行的代码
# self.attribute_name(*args)
#
#
# @ClassName
# def function_name(parameter):
# pass
#
#
# 调用:function_name(parameter)
#
# 方式二:
# class ClassName(object):
# def __init__(self, value):
# self.attribute_name = value
#
# def __call__(self, *args, *kwargs):
# 需要额外执行的代码
# self.attribute_name(*args)
#
#
# def function_name(parameter):
# pass
#
#
# function_name = ClassName(function_name)
#
# 调用:function_name(parameter)
class ChickInformation(object):
def __init__(self, func):
self.chick = func
def __call__(self, *args):
print('请输入身份信息')
self.chick(*args)
# @ChickInformation
def creating_role(choice):
if choice == 'Yes':
print('创建角色成功')
creating_role = ChickInformation(creating_role)
creating_role('Yes')
# 请输入身份信息
# 创建角色成功
python对象的生命周期
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# python对象的生命周期
# 概念:
# 指的是一个对象从诞生到消亡的过程
# 当一个对象被创建的时候会在内存中分配相应的内存空间进行存储
# 当这个对象不再使用的时候,系统为了节省内存,就会把这个对象释放掉
# python监听对象生命周期的方法:
# __new__方法:
# 这个是我们创建一个对象的时候给对象分配空间的方法
# 通过这个方法可以拦截对象的创建过程
# __init__方法:初始化方法,用来给对象附加东西的,一旦创建会自动地将__new__中的对象传递过来
# __del__方法:释放内存
# 统计类创建的对象总数
class Information(object):
__object_count = 0
def __init__(self):
Information.__object_count += 1
def __del__(self):
self.__class__.__object_count -= 1
@classmethod
def get_count(cls):
print('当前共有%d个类' % cls.__object_count)
I0 = Information()
I1 = Information()
I2 = Information()
I3 = Information()
Information.get_count()
del I0
Information.get_count()
# 当前共有4个类
# 当前共有3个类
内存管理机制
储存和回收
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# python内存管理机制
# 存储方面:
# 在python中万物皆对象,不存在基本数据类型
# 所有对象都会在内存中开辟一块空间进行储存:
# 会根据不同的类型以及内容,开辟不同的空间大小进行存储
# 会返回改空间的地址给外界接受(称为“引用”)用于后续对这个对象进行操作:可以通过id()函数获取内存地址
# 对于较短的字符和整数,python会进行缓存,而不会开辟多个相同的对象
# 容器对象(列表、字典、__dict__字典)中储存的其他兑现,仅仅是其他对象的“引用”,而不是其他对象本身
num0 = 1
num1 = 1
print(id(num0) == id(num1))
# True
# 垃圾回收:
# 引用计数器:
# 概念:
# 每一个对象会记录自己被引用的个数
# 每增加一次引用,这个对象的引用计数就会+1
# 每减少一次引用,这个对象的引用计数就会—1
# 查看引用计数的方式:
# import sys
# sys.getrefcount(arg)
# 注意:因为调用getrefcount()也会引用对象,所以计数增加1,多次引用不会叠加
# 引用计数+1的场景:
# 对象被创建:object = ClassName()
# 对象被引用:object1 = object0
# 对象作为一个参数,被传入到一个函数中==>此时是+2
# 对象作为一个元素,储存在容器中:List = [object]
# 引用计数-1的场景:
# 对象的别名被显式销毁
# 对象的别名被赋予新的对象
# 对象离开了他的作用域:一个函数执行完毕时,内部的局部变量关联的对象的引用被销毁
# 对象所在的容器被销毁或者从容器中删除了对象
import sys
def get_ref_count(name):
print('引用函数后的计数%d' % sys.getrefcount(name))
class ClassName(object):
pass
# 引用增加
C0 = ClassName()
print('创建时的计数%d' % sys.getrefcount(C0))
C1 = C0
C2 = C0
print('引用函数前的计数%d' % sys.getrefcount(C0))
get_ref_count(C0) # 此处函数调用结束后被视为引用销毁而减少了2
List = [C0]
print('储存到容器后的计数%d' % sys.getrefcount(C0))
# 引用减少
del C1
print('别名被销毁后的计数%d' % sys.getrefcount(C0))
C2 = 112
print('别名被赋予给其他的对象%d' % sys.getrefcount(C0))
List.remove(C0)
print('别名从容器中移除%d' % sys.getrefcount(C0))
# 创建时的计数2
# 引用函数前的计数4
# 引用函数后的计数6
# 储存到容器后的计数5
# 别名被销毁后的计数4
# 别名被赋予给其他的对象3
# 别名从容器中移除2
循环引用问题以及解决方式
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 引用计数器:循环引用问题
# 循环引用产生的问题:两个对象互相引用,删除对象后引用数仍为1,不能释放内存
# python内存管理机制:引用计数机制 + 垃圾回收机制
# 使用objgraph模块可以查看跟踪对象的个数
# 语法:首先需要安装objgraph模块,在cmd中使用pip install objgraph语句或者在idle中安装
# import objgraph
# objgraph.count()
import objgraph
class Person(object):
pass
class Pet(object):
pass
P = Person()
D = Pet()
print(objgraph.count('Person'))
print(objgraph.count('Pet'))
P.dog = D
D.master = P
del P
del D
# 查看删除P, D之后内存是否被释放掉
print(objgraph.count('Person'))
print(objgraph.count('Pet'))
# 1
# 1
# 1
# 1
# 循环引用的解决方式:垃圾回收机制
# 垃圾回收机制的作用:从经历“引用计数器机制”仍未被释放的对象中,找到“循环引用”并释放掉
# 实现机制:
# 怎样找到循环引用:
# 1.收集所有的“容器对象”,通过一个双向链表进行引用(容器对象是可以引用其他对象的对象,如列表、元组、字典、自定义的对象)
# 2.针对每一个容器对象,通过一个变量“gc_refs”来记录当前对应的引用计数
# 3.对于每个“容器对象”,找到它引用的“容器对象”,并将这个“容器对象”的引用计数 -1
# 4.经过步骤三之后,如果一个“容器对象”的引用计数为0,那么它就可以被回收,可能是循环引用导致其留存到了现在
# 如何提升垃圾回收机制的性能:分代回收
# 1.默认一个对象被创建出来的时候属于0代
# 2.如果经历这一代“垃圾回收”后,依然存活,则被划分到下一代
# 3.“垃圾回收”的循环周期:0代检测到一定次数后会触发0代和1代检测,并将通过一代检测的对象改为2代
# 1代检测达到一定次数会触发0代、1代、2代检测
# 什么时候会触发垃圾回收机制:在垃圾回收器中,当新增个数 - 消亡对象的个数达到一定的阈值才会触发垃圾检测机制
# 如何获取和更改当前垃圾检测阈值
# 语法:gc库
# import gc
# gc.get_threshold() # 获取当前垃圾回收阈值,返回值为元组,第一个数是触发值,后两个分别是是1代和2代检测值
# gc.set_threshold(value0, value1, value2) # 输入阈值,参数同get_threshold()的返回值
#
# 垃圾回收开启时机:
# 自动开启:开启垃圾回收机制并达到检测的阈值
# 相关语法:
# gc.enable() # 开启垃圾回收机制(默认开启)
# gc.disable() # 关闭垃圾回收机制
# gc.isenabled() # 判断是否开启垃圾回收机制
# 手动回收:gc.collect(n) # n代表需要回收的最高代数,即0只回收0代,1回收0代和1代,默认全回收,同时该方法的运行与垃圾回收机制是否开启不挂钩
# 注意:
# 在python2.x中在类中实现了__del__方法即使手动释放循环引用也不会生效,需要借助其他方法结束循环引用
# 1.在删除引用前破坏引用,使其中一个对象 = None
# 2.使用weakref模块创建弱引用(弱引用不会增加引用计数,所以不会形成循环引用),weakref.ref() / weakref.WeakValueDictionary()···
import gc
import objgraph
class Person(object):
pass
class Animal(object):
pass
# 建立对象
Jack = Person()
Dog = Animal()
# 创建循环引用
Jack.pet = Dog
Dog.master = Jack
# 删除引用
del Jack, Dog
print('当前两个对象的引用数Person:{},Animal:{}'.format(objgraph.count('Person'), objgraph.count('Animal')))
# 关闭垃圾回收机制,测试是否collect()方法是否与垃圾回收机制开启挂钩
gc.disable()
print(gc.isenabled())
gc.collect()
print('当前两个对象的引用数Person:{},Animal:{}'.format(objgraph.count('Person'), objgraph.count('Animal')))
# 当前两个对象的引用数Person:1,Animal:1
# False
# 当前两个对象的引用数Person:0,Animal:0
面向对象的三大特性
封装
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 面向对象的三大特性————封装
# 概念:将一些属性和相关的方法封装到一个对象中,对外隐藏具体的细节
# 好处:
# 1.使用更加方便
# 2.保护数据安全
# 3.利于代码维护
from Case_Calculator import Calculator
cal = Calculator()
cal.plus(3).multiply(4)
print(cal.get_res)
# 12
继承
# 面向对象的三大特性————继承
# 概念:一个类拥有另一个类资源(主要是非私有的属性和方法)的使用权的一种形式
# 目的:方便代码复用
# 分类:
# 单继承:
# 概念:仅仅继承了一个父类
# 语法:class ClassName1(ClassName0)
# 多继承:
# 概念:继承了多个父类
# 语法:class ClassNameN(ClassName0, ClassName1, ···)
# 查看一个对象继承自何处的方法:object_name.__base__
# 查看一个对象是由谁实例化的方式:object_name.__class__
# type(元类)和object(新式类)的关系:
# object是type的实例化对象
# type继承自object
# type是由自己实例化出来的
# 一般内置方法都是继承自object,由type实例化
# bool由int实例化
# Python3.x创建类时隐性继承object
# 注意:父类又称超类、基类 子类又称派生类
print('type来自%s的实例化,继承自%s' % (type.__class__, type.__base__))
print('object来自%s的实例化' % object.__class__)
print('内置对象float来自%s的实例化,继承自%s' % (float.__class__, float.__base__))
print('内置对象int来自%s的实例化,继承自%s' % (int.__class__, int.__base__))
# type来自的实例化,继承自
# object来自的实例化
# 内置对象float来自的实例化,继承自
# 内置对象int来自的实例化,继承自
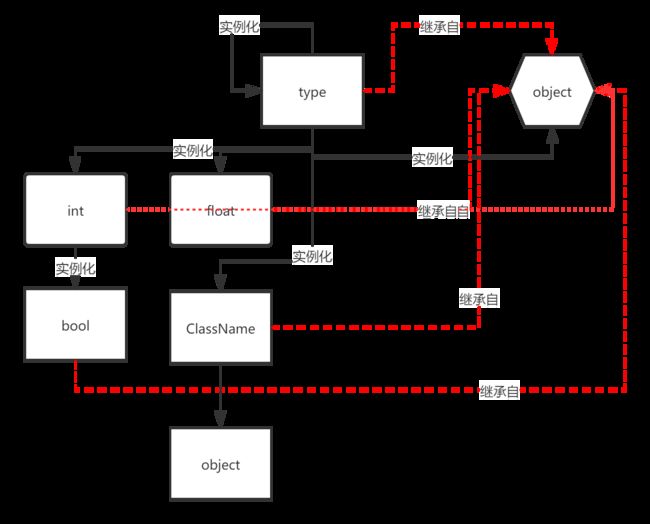
继承的影响
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 继承的影响:资源主要指的是父类的属性和方法
# 资源的继承:
# 主要是继承资源的使用权限而不是复制一份资源
# 除去私有方法和属性不能继承,其他的公有的和受保护的属性和方法都可以继承
# 子类不能修改父类的属性,修改操作会被识别为新增操作,会在子类中新增该属性
# 资源的使用:
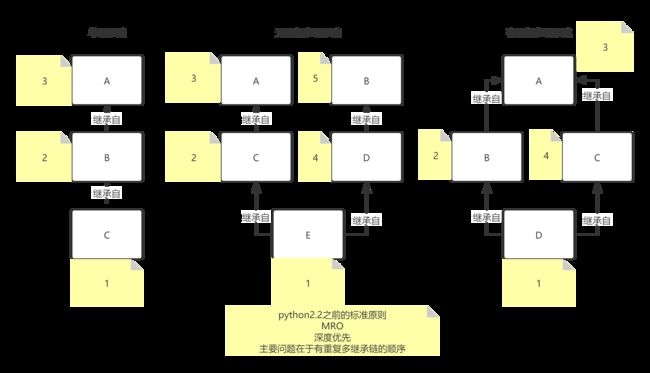
# 继承的三种形态:单链继承、无重复多链继承、有重复多链继承(具体见下图)
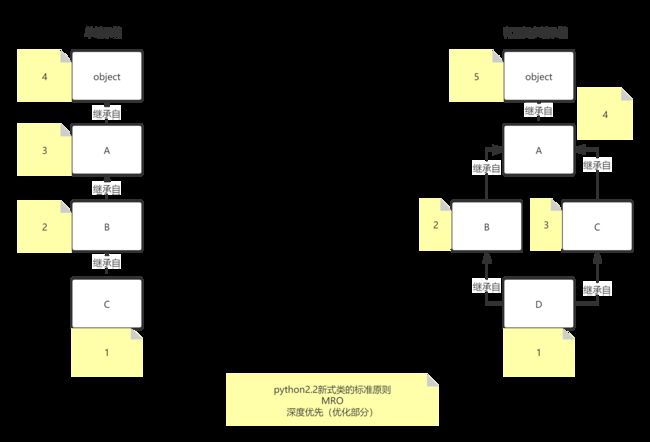
# 几种形态应当遵循的标准原则:见继承的三种形态中的图
# 针对几种标准原则的方案演化:
# python2.2之前:
# 仅仅存在经典类
# MRO原则:Method Resolution Order,方法解析顺序 从左至右
# 深度优先:沿着一个继承链,尽可能往深层找
# 具体步骤:
# 1.把根节点压入栈中
# 2.每次从栈中弹出一个元素,搜索所有在它下一级的元素并把这些元素压入栈中(发现元素已经被处理过则略过)
# 3.重复步骤二直到结束
# 存在的问题:在有重叠的继承链中违背“重写可用原则”
# python2.2:产生了新式类
# MRO原则:
# 经典类:深度优先 从左至右
# 新式类:在深度优先的基础上进行了优化(如果出现了重复的元素,会保留最后一个,更尊重基类出现的先后顺序)具体见下图
# 注意:此时的方法并不是广度优先,仍然是广度优先
# 广度优先:沿着继承链尽可能往宽找
# 1.把根节点放在队列的末尾
# 2.每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,并把它们放到队列的末尾(发现已经处理过的元素则略过)
# 3.重复上面的步骤
# 新算法可能产生的问题:
# 无法检测有问题的继承
# 有可能违背“局部优先”的原则
# 有问题的继承:
# class A(object):
# pass
#
# class B(A):
# pass
#
# class C(B):
# pass
#
# class D(B, C):
# pass
# 存在的问题:上述继承的计算顺序D -> C -> B -> A -> object
# D已经从C继承到了A、B、object的资源,但又通过B继承了object和A的资源
# 正常情况先应当优先计算B,然而上述继承优先计算了C
# python2.3-2.7:新式经典两个类并存
# MRO原则:
# 经典类:深度优先(从左至右)
# 新式类:C3算法
# C3算法步骤:
# 1.两个公式:L(object) = [object]
# 2.L(子类(父类1, 父类2)) = [子类] + merge(L(父类1), L(父类2), [父类1, 父类2])
# + 代表合并列表
# merge算法:
# 1.判断第一个列表的第一个元素是否是后续列表的第一个元素或者后续列表中是否没有出现
# 2.如果满足上述两个条件之一,则将这个元素合并到最终的解析列表中并从当前操作的所有列表中删除这个元素
# 3.如果不符合,则跳过这个元素,查找下一个列表的第一个元素,重复1的判断规则
# 4.如果最终无法将所有的元素归并到解析列表,则报错
# 注意:C3算法并不是拓扑排序
# 拓扑排序:
# 1.根据代码的继承关系绘制一张继承图
# 2.找到入度为0的节点
# 3.把这个节点输出并删除,同时删除该节点的出边
# 4.重复2、3步骤直到输出所有节点
# python3.x版本:只存在新式类,同时MRO采用的是C3算法
# 注意:查看类的资源查找顺序的方法
# 方式一:
# import inspect
# print(inspect.getmro(cls) # 返回值是tuple类型
# 方式二:
# print(cls.__mro__) # 返回值是tuple类型
# 方式三:
# print(cls.mro()) # 返回值是list类型
# 资源的覆盖:包括属性的覆盖和方法的重写
# 原理:
# 在MRO的资源检索链中,优先级比较高的类写了一个和优先级比较低的类的一样的资源(属性或者方法)
# 到时候再去获取相关的资源,就会优先选择优先级比较高的资源,而摒弃优先级比较低的资源,造成“覆盖”的假象
# 注意事项:调用优先级比较高的资源时,注意self和cls的变化
# 谁调用就传递谁
# 资源的累加:概念:在一个类的基础上,增加一些额外的资源
# 子类相比于父类,多一些自己特有的资源
# 在被覆盖的方法基础上,新增内容
# 注意事项:
# 多个类连续继承时:如果有一个以上的类实现了初始化方法__init__,最后调用__init__中的属性时,优先级低的方法会被优先级高的方法覆盖,即优先级低的方法中的属性不会被增加到实例中,需要手动新增
# 方式一:在优先级高的类中使用类名调用的方式调用优先级低的类的__init__方法
# 方式二:在类方法中,通过“super”调用高优先级类的方法:
# 概念:是一个类,只能在新式类中起作用
# 作用:沿着MRO链条,找到下一级节点,去调用对应的方法
# 需要解决的问题:沿着谁的MRO链条?找谁的下一级节点?如何处理类方法、实例方法、静态方法传参的问题?
# 语法原理:super(参数1[, 参数2]) # 参数二只能是参数1的子类或者实例
# 工作原理:
# def super(cls, inst):
# mro = inst.__class__.mro()
# return mro[mro.index(cls) + 1]
# 问题解决:
# 沿着谁的MRO链条 ——> inst
# 找的谁的下个一节点 ——> cls
# 解决传参问题 ——> 使用inst进行传参
# 具体的语法形式:
# python2.2 -> 2.7:
# super(type,obj) -> bound super object;
# super(type1, type2) -> bound super object;
# python3.x:super() == super(__class__, ) # 会根据行文自动传参
# 即静态方法直接使用super()可能会报错,缺少第二个参数
# 注意事项:
# 第一个参数不能使用self.__class__动态获取,容易陷入死循环
# 方式一和方式二不能混合使用,容易产生重复调用
# 继承的影响
class Father(object):
Attribute = 0
public_attribute = '公有属性'
_protected_attribute = '受保护的属性'
__private_attribute = '私有属性'
def public_method(self):
print('这是公开的方法')
def _protected_method(self):
print('这是受保护的方法')
def __private_method(self):
print('这是私有的方法')
def __init__(self):
print('这是初始化方法')
class DerivedClass(Father):
def chick(self):
print(self.public_attribute)
print(self._protected_attribute)
# print(self.__private_attribute)
self.public_method()
self._protected_method()
# self.__private_method()
self.__init__()
D = DerivedClass()
D.chick()
print(DerivedClass.Attribute) # 调用父类属性值
DerivedClass.Attribute = 1 # 尝试修改父类属性值
print(Father.Attribute) # 查看父类属性值是否被修改
print(DerivedClass.__dict__) # 查看子类是否增加该属性
# 这是初始化方法
# 公有属性
# 受保护的属性
# 这是公开的方法
# 这是受保护的方法
# 这是初始化方法
# 0
# 0
# {'__module__': '__main__', 'chick': , '__doc__': None, 'Attribute': 1}
# C3算法演示
# 此时python版本应当为2.3 - 2.7
import inspect
class A(object):
pass
# L(A) = A
# L(object) = object
# L(A(object)) = [A] + merge(L(object))
# = [A] + merge(object)
# = [A, object]
class B(A):
pass
# L[B] = B
# L[B(A)] = [B] + merge(L(A), [A])
# = [B] + merge([A, object], [A]) # 此处merge()中[A, object]的A满足1中的第一个条件,取出A放入解析列表并从所有操作的列表中删除A
# = [B, A] + merge([object], []) # 此处的merge()中的[object]满足1中的第二个条件,取出object放入解析列表并从所有操作的列表中删除object
# = [B, A, object] + merge([])
# = [B, A, object]
class C(A):
pass
# L(C) = C
# L(C[A]) = [C] + merge(L[A], [A])
# = [C] + merge([A, object], [A])
# = [C, A] + merge([object], [])
# = [C, A, object] + merge([])
# = [C, A, object]
class D(B, C):
pass
# L(D) = D
# L(D[B, C]) = [D] + merge(L[B], L[C], [B, C])
# = [D] + merge([B, A, object], [C, A, object], [B, C])
# = [D, B] + merge([A, object], [C, A, object], [C]) # 此处的merge()中的[B, A, object]中的B满足1中的第一个条件,取出B放入解析列表并从所有操作的列表中删除B
# = [D, B, C] + merge([A, object], [A, object], []) # 此处的merge()中的[A, object]不满足1中的任何条件,因而使用[C, A, object]执行1的条件,发现C满足条件,取出C放入解析列表并从所有操作的列表删除C
# = [D, B, C, A] + merge([object], [object]) # 此处的merge()中的第一个[A, object]满足1中的条件1,取出A放到解析列表中并从所有操作的列表中删除A
# = [D, B, C, A, object] + merge([], []) # 此处的merge()中的第一个[object]满足1中的条件1,取出object放入解析列表并从所有操作的列表中删除object
# = [D, B, C, A, object]
# 查看D的MRO顺序
print('D的资源查找顺序是:%s' % str(inspect.getmro(D)))
print('inspect.getmro()的返回值的类型是:%s' % str(type(inspect.getmro(D))))
print('D的资源查找顺序是:%s' % str(D.__mro__))
print('cls.__mro__的返回值的类型是:%s' % str(type(D.__mro__)))
print('D的资源查找顺序是:%s' % str(D.mro()))
print('cls.mro()的返回值的类型是:%s' % str(type(D.mro())))
# D的资源查找顺序是:(, , , , )
# inspect.getmro()的返回值的类型是:, , , , )
# cls.__mro__的返回值的类型是:, , , , ]
# cls.mro()的返回值的类型是:, , , , ]

多态
# _*_coding:utf-8_*_
# !/bin/usr/env python3
# 面向对象的三大特性————多态
# 概念:
# 一个类所延伸的多种形态
# 调用时的多种形态——在继承的前提下,使用不同的子类,调用父类的同一种方法产生不同的功能
# 多态在python中的体现:
# 鸭子类型:
# 动态语言的一种类型
# 关注点在于对象的“行为和属性”,而非对象的“类型”
# 在python中并没有真正意义上的多态,也不需要多态
# 多态演示
class Animal(object):
@staticmethod
def howl():
print('xxx')
class Dog(Animal):
@staticmethod
def howl():
print('汪汪汪')
class Cat(Animal):
@staticmethod
def howl():
print('喵喵喵')
def howl(Object):
Object.howl()
howl(Dog)
补充
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 面向对象三大特性————补充
# 抽象类:
# 一个抽象出来的类,并不是一个具化的类
# 不能直接创建实例的类 —— 创建会报错
# 抽象方法:
# 一个抽象出来的方法
# 不能具体实现,但是好像可以调用(当前版本python3.8) —— 子类不实现会报错
# 在python中的实现:
# 无法直接是实现,需要借助abc模块 —— import abc
# 设置类的元类为 —— abc.ABCMeta
# 使用装饰器修饰抽象方法 —— @abc.abstractmethod
# 注意:一旦在抽象类中设置了抽象方法就必须要在子类中实现
import abc
class Animal(object, metaclass=abc.ABCMeta):
@abc.abstractmethod
def run(self):
pass
@abc.abstractclassmethod
def jump(cls):
pass
@abc.abstractstaticmethod
def howl():
pass
@abc.abstractproperty
def name(self):
pass
class Dog(Animal):
def run(self):
print('跑')
@classmethod
def jump(cls):
print('跳')
@staticmethod
def howl():
print('汪汪汪')
@property
def name(self):
return '狗'
# a = Animal() # TypeError: Can't instantiate abstract class Animal with abstract methods howl
print(Animal.name)
d = Dog()
d.run()
Dog.jump()
d.howl()
print(d.name)
# 面向对象应当遵循的原则
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 面向对象遵循的的设计原则
# SOLID
# S(Single Responsibility Principle):单一职责,即一个类只负责一项职责
# 好处:
# 易于维护,写出高质量的代码
# 已于代码复用
# 案例:计算机案例:只包括加减乘除以及返回结果
# O(Open Closed Principle):开放封闭原则,即对扩展开放,对修改关闭
# 易于维护,保证代码的安全性和扩展性
# 案例:学生、组长、教师案例,通过基类、抽象类等方法统一(将工作方法统一为work)
# L(Liskov Substitution Principle):里氏替换原则,即使用基类引继的地方必须能使用继承类的对象
# 防止代码出现不可预知的错误
# 方便针对基类的测试代码可以用在子类上
# 案例:
# class birds(object):
#
# def fly(self):
# pass
#
#
# class ostrich(birds):
# pass
#
#
# 此处子类ostrich()(鸵鸟)不具有飞的功能,所以不适用里氏替换原则
# I(Interface Segregation Principle):接口分离原则,即一个类包含了过多的接口方法,而这些方法在使用的过程中并非“不可分割”,那么应当将他们分离
# 所谓接口,在python中可理解为“抽象方法”
# 好处:提高接口的重用价值
# 案例:
# 鸟类:吃、叫、飞
# 而这一接口在由鸵鸟的前提下设计的不合理,应当将吃、叫与飞分离
# D(Dependency Inversion Principle):依赖倒置原则,即高层模块不应当直接依赖底层模块,他们应该依赖抽象类或者接口
# 好处:有利于代码的维护
# 案例:电脑类:依赖的不是具体的鼠标类,而是鼠标的抽象类(能单击、双击、右击、移动鼠标指针)
错误和异常
错误和异常的概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 错误和异常的概念
# 错误:没法通过其他代码进行处理的问题
# 语法错误:
# dfe function_name():
# 这种错误可以根据IDE或者解释器给出的提示修改
# 逻辑错误:
# age = input()
# if age < 18:
# print('你已经成年了')
# 这种错误IDE和解释器无法发现,需要我们通过代码测试排查
# 异常:多指程序执行的过程中,出现未知的错误,语法和逻辑都是正确的,可以通过其他代码进行修复
# age = input('请输入你的年龄')
# if age > 18:
# print('你已经成年')
# 语法和逻辑都没有错误,但是用户输入字符串时无法处理
常见的系统异常和系统异常类继承树
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 常见的系统异常
# 除零异常:zeroDivisionError
# print(12 / 0)
# ZeroDivisionError
# 名称异常:NameError
# print(name)
# NameError
# 类型异常:TypeError
# print('1' + 2)
# TypeError
# 索引异常:IndexError
List = range(2)
# print(List[3])
# IndexError
# 键异常:KeyError
# Dict = {'name': 'LY', 'age': 18}
# print(Dict['address'])
# KeyError
# 值异常:ValueError
# Str = 'abc'
# print(int(Str)) # 如果Str = '123'之类的是可以转换的,不会报错
# ValueError
# 属性异常:AttributeError
# class Person(object):
# name = 'LY'
#
#
# print(Person.age)
# AttributeError
# 迭代器异常:StopIteration
# List = iter(List)
# while True:
# next(List)
#
# StopIteration
# 这些类都继承自BaseException
print('StopIteration --> {} --> {} --> {}'.format(StopIteration.__base__, StopIteration.__base__.__base__, StopIteration.__base__.__base__.__base__))
print(StopIteration.mro())
# StopIteration --> --> -->
# [, , , ]
# 系统异常类继承树:
# BaseException所有内建的异常的基类:
# SystemExit:由sys.exit()函数引发,当它不处理时,python解释器退出
# KeyboardInterrupt:用户点击中止键(通常是Ctrl + C)引起的
# GeneratorExit:当调用一种generator的close()方法时引起的
# Exception:所有内置的、非系统退出的异常是从该类派生出的。用户自定义的异常也应当由该类派生出
异常的解决方式
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 异常的解决:
# 系统内置了一些特定的场景,当我们的代码在运行的过程中触发了这个场景,系统内部就会自动向外部抛出这个问题;这就是所谓的异常;如果一场不被解决,程序就会终止运行
# 解决方式:
# 预防:添加容错代码
# 弊端:容错代码过多会造成代码混乱,主要业务逻辑不清晰
# 解决:
# 语法:
# 方案一:
# try:
# 需要解决异常的代码块 # 这儿无论存在多少个异常,只要检测出一个异常就会执行后面的代码不会处理其他的异常
# except ErrorName as Formal_parameter(接收异常解释的形参): # 该段可多次使用,如同elif语句,python2.x中可以使用 , 来代替as
# 需要执行的解决方案代码
# else:
# 没出现异常时需要做的处理 # 该段必须放在上一块except结束后,也可以省略
# finally:
# 不管有没有出现异常,都会执行的代码 # 这一段必须放在最后,可以省略
# 方案二:适用于执行一段代码前A,进行预处理,执行代码A结束后,进行清理。该方法并不会处理错误,只是会关闭打开的文件
# 语法:
# with content_expression [as target(s)]: # target接受的是__enter__的返回值
# with-body
# 图解见下
# 补充:
# 自定义上下文管理器:
# class ContextManagerName(object):
# def __enter__(self):
# pass # 需要执行的操作
#
# return 需要返回给target的值
#
# def __exit__(self, exc_type, exc_val, exc_tb): # 参数:exc_type:异常类型,exc_val:异常值,exc_tb:异常追踪信息
# pass # 需要执行的操作
#
# return bool # 如果此处返回的bool值是True,那么外界不会报错
#
# contextlib模块:
# @contextlib.contextmanager # 使用装饰器将一个生成器变成一个上下文管理器
# 语法:
# import contextlib
# @contextlib.contextmanager
# def context_manager():
# 充当__enter__的代码块
#
# yield[ 需要当作target返回值的代码]
#
# 充当__exit__的代码块
# with context_manager()[ as target]:
# with-body
#
# contextlib.closing # 可以让一个拥有closing方法但不是上下文管理器的对象变成“上下文管理器”
# 语法:
# import contextlib
#
#
# class ClassName(object):
# 需要当作__enter__方法和with-body的方法
#
# def close(self): # 这个方法必须要具有,被用来当作“上下文管理器”的__exit__方法并自动执行
# pass
#
# with contextlib.closing(ClassName()) as target: # target相当于ClassName的实例,由contextlib模块的closing()函数自动实现的
# target.method() # 通过实例.方法的方式来实现__enter__和with-body的运行
#
# 这段代码相当于:
# class ClassName(object):
# 需要和with-body互动的方法
#
# def close(self):
# print('释放资源')
#
# def __enter__(self):
# return self
#
# def __exit__(self, exc_type, exc_val, exc_tb):
# self.closing()
#
#
# with ClassName() as target:
# target.method()
#
# nested()函数:在python2.7之前用作上下文管理器的嵌套
# 语法:
# python2.7(包括2.7)可以使用该方法:
# import contextlib
# with contextlib.nested(open('File_name0', 'r'), open('File_name1', 'w')) as (File0, File2):
# context = File0.read()
# File1.write(content)
#
# python2.7(包括2.7)之后的方法:
# with open('File_name0, 'r') as File0, open('File.name1', 'w') as File1:
# content = File0.read()
# File.write(content)
#
# 这两种方式等价于:
# with open('File_name0', 'r') as File0:
# with open('File_name1', 'w') as File1:
# content = File0.read()
# File1.write(content)
#
# 查看错误追踪信息:traceback库
# import traceback
# print(traceback.extract_tb(traceback_information))
# 注意:
# 1.如果try语句没有捕获到异常,执行顺序是首先try语句中的代码,然后执行else中的语句,最后执行finally语句中的代码
# 2.如果try语句捕获到了异常,执行顺序是首先执行对应的except语句中的代码,然后执行finally语句中的代码
# 3.如果一场名称不确定,而又想捕捉,可直接写Exception
# 预防:
age = 'abc'
if isinstance(age, int) or isinstance(age, float):
if age >= 18:
print('你已经成年了')
else:
print('你还没有成年')
else:
print('你输入的年龄有误,应当输入数字')
# 你输入的年龄有误,应当输入数字
# 解决
# 方式一
try:
if age >= 18:
print('你已经成年了')
print(name)
else:
print('你还没有成年')
print(name)
except Exception as Error: # 适合于不知道错误类型,并且错误的处理方式都是一样的时候
print('存在错误,错误的类型是是%s' % Error)
else:
print('这段代码没有错误没有错误')
finally:
print('怎样都会执行的语句')
# 存在错误,错误的类型是是'>=' not supported between instances of 'str' and 'int'
# 怎样都会执行的语句
# 方式二
# with open('with语句的图解.png', 'r') as File:
# content = File.readlines()
# print(content)
# Traceback (most recent call last):
# File "Errors_And_Exceptions.py", line , in division by zero
# [>]
# 执行结束
# contextlib模块
import contextlib
# @contextlib.contextmanager装饰器
@contextlib.contextmanager
def context_manager():
print('这是__enter__语句的位置')
yield '这是target接受的返回值'
print('这是__exit__语句的位置')
with context_manager() as val:
print('这是with-body的位置', val)
# 这是__enter__语句的位置
# 这是with-body的位置 这是target接受的返回值
# 这是__exit__语句的位置
# contextlib.closing()
class ContextManager(object):
def method(self):
print('这是需要互动的方法的位置')
def close(self):
print('这是实现__exit__方法得位置')
with contextlib.closing(ContextManager()) as CM:
CM.method()
# 这是需要互动的方法的位置
# 这是实现__exit__方法得位置

手动抛出异常
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 手动抛出异常
# 语法:raise ErrorName('想要传递的信息')
import contextlib
def age(num):
if num < 0 or num > 120:
raise ValueError("年龄过大或者过小")
else:
print('你的年龄设置为%s岁' % num)
@contextlib.contextmanager
def age_chick():
try:
yield
except Exception as exc:
print('Error', exc)
with age_chick():
age(-19)
with age_chick():
age(19)
# Error 年龄过大或者过小
# 你的年龄设置为19岁
自定义异常
# _*_coding:utf-8_*_
# !usr/bin/env python3
# 自定义异常
# 用户自定义的异常必须继承自Exception
import contextlib
class NumError(Exception):
def __init__(self, msg, tb):
self.msg = msg
self.tb = tb
def __str__(self):
return self.msg + str(self.tb)
def age(num):
if num < 0:
raise NumError("年龄过小", '你设置的年龄是:%d,小于0岁' % num)
elif num > 120:
raise NumError('年龄过大', '你设置的年龄是:%d,大于120岁' % num)
else:
print('你的年龄设置为%s岁' % num)
@contextlib.contextmanager
def age_chick():
try:
yield
except NumError as exc:
print('NumError', exc)
with age_chick():
age(-19)
with age_chick():
age(19)
with age_chick():
age(180)
# NumError 年龄过小你设置的年龄是:-19,小于0岁
# 你的年龄设置为19岁
# NumError 年龄过大你设置的年龄是:180,大于120岁
包和虚拟环境
目前 https://pypi.org 可在页面底部选择中文
包和模块
包和模块的概念
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 概念:
# 模块:
# 为了代码更容易维护,提高代码的复用价值;可以将一组相关的代码写入一个单独的 .py 文件中
# 提供给别人导入使用,这个 .py 文件就被称为一个模块
# 包:包是一个有层次的文件目录结构,包含多个模块和自包
# 具体表现形式,:一定包含有__init__.py文件的目录,在这个目录下一定能得到__init__.py这个文件或者其他模块和子包
# 库:
# 参照其他编程语言的一种称呼
# 完成一定功能代码的合集
# 具体表现可以是一个包、也可以是一个模块
# 框架:
# 一个架构层面的概念:
# 从库的功能角度来看:解决一个开放性的问题而设计的具有一定约束性的支撑结构
# 通过一个框架,可以快速实现一个问题解决的骨架;到时按框架角色去填充、交互就可以完成一个质量高、维护性好的项目
包和模块的作用
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 作用:
# 1.编写好一些“工具”代码,供其他模块使用 —— 有效的对程序进行分解,方便代码的维护和管理
# 2.可以防止同一模块内命名重复的问题(两个模块的命名空间是平行的,即使名称一样但是调用时返回的值是不一样的)
包和模块的分类
# _*_coding:utf_*_
# !/usr/bin/env python3
# 包和模块的分类
# 标准包和模块:
# 安装python后,自动帮我们安装好的一些模块,可以直接导入使用
# 每个安装python的用户电脑上都有这些模块 —— 自己写的代码中使用到了某个系统模块的代码,到了其他人的电脑上也能运行
# 满足基本的功能需求
# 特殊:内建的包和模块:
# 在我们编码的过程中,python会自动帮我们导入这些模块 —— builtins
# 当我们用到这个模块中的相关功能时不需要导入就能直接使用
# 第三方的包和模块:
# 有些功能,系统模块没有实现,或者实现了使用时比较复杂
# 有其他开发人员,开发了一些使用更加简便的模块,供其他开发人员使用
# 其他开发人员需要下载、安装、 导入才能使用 —— 如果自己写的代码使用了某个第三方包或者模块;将代码拷贝给别人后需要别人安装同样的第三方包或模块才能使用
# 自定义包和模块:我们自己写的一些包和模块,发布出去后就变成了第三方包和模块
包和模块的一般操作
包和模块的创建
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 包和模块的创建
# 创建模块:直接创建一个 .py 文件即可
# 创建包:创建一个文件夹,文件夹内必须包含 __init__.py 这个模块 —— python3.3之后可以不用创建该文件,但是为了版本之间的兼容,建议创建(pycharm中右键选择python package,会自动创建__init__.py文件)
# 创建多层级包:在包内直接创建另一个包即可,可以无限嵌套
包和模块的基本信息
# _*_coding:utf-8_*_
# !usr/bin/env python3
# 包和模块的基本信息
# 查看包和模块的名称:xxx.py 的 xxx 即是模块的名称,不需要后缀,包就是包的名称
# 查看包和模块的存放位置:print(module / package .__file__) # 使用pycharm该方法没有提示,用该方法查看包的位置时显示的是__init__文件的位置
# 查看包和模块的内容:print(dir(module / package))
import os
import json
print('模块os的位置是%s,包json的存放位置是%s' % (os.__file__, json.__file__))
print('模块os的内容是%s \n 包json的内容是%s' % (dir(os), dir(json)))
# 模块os的位置是C:\Program Files\Python38\lib\os.py,包json的存放位置是C:\Program Files\Python38\lib\json\__init__.py
# 模块os的内容是['DirEntry', 'F_OK', 'MutableMapping', 'O_APPEND', 'O_BINARY', 'O_CREAT', 'O_EXCL', 'O_NOINHERIT', 'O_RANDOM', 'O_RDONLY', 'O_RDWR', 'O_SEQUENTIAL', 'O_SHORT_LIVED',
# 'O_TEMPORARY', 'O_TEXT', 'O_TRUNC', 'O_WRONLY', 'P_DETACH', 'P_NOWAIT', 'P_NOWAITO', 'P_OVERLAY', 'P_WAIT', 'PathLike', 'R_OK', 'SEEK_CUR', 'SEEK_END', 'SEEK_SET', 'TMP_MAX','W_OK',
# 'X_OK', '_AddedDllDirectory', '_Environ', '__all__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', '_check_methods',
# '_execvpe', '_exists', '_exit', '_fspath', '_get_exports_list', '_putenv', '_unsetenv', '_wrap_close', 'abc', 'abort', 'access', 'add_dll_directory', 'altsep', 'chdir', 'chmod',
# 'close', 'closerange', 'cpu_count', 'curdir', 'defpath', 'device_encoding', 'devnull', 'dup', 'dup2', 'environ', 'error', 'execl', 'execle', 'execlp', 'execlpe', 'execv', 'execve',
# 'execvp', 'execvpe', 'extsep', 'fdopen', 'fsdecode', 'fsencode', 'fspath', 'fstat', 'fsync', 'ftruncate', 'get_exec_path', 'get_handle_inheritable', 'get_inheritable',
# 'get_terminal_size', 'getcwd', 'getcwdb', 'getenv', 'getlogin', 'getpid', 'getppid', 'isatty', 'kill', 'linesep', 'link', 'listdir', 'lseek', 'lstat', 'makedirs', 'mkdir', 'name',
# 'open', 'pardir', 'path', 'pathsep', 'pipe', 'popen', 'putenv', 'read', 'readlink', 'remove', 'removedirs', 'rename', 'renames', 'replace', 'rmdir', 'scandir', 'sep',
# 'set_handle_inheritable', 'set_inheritable', 'spawnl', 'spawnle', 'spawnv', 'spawnve', 'st', 'startfile', 'stat', 'stat_result', 'statvfs_result', 'strerror',
# 'supports_bytes_environ', 'supports_dir_fd', 'supports_effective_ids', 'supports_fd', 'supports_follow_symlinks', 'symlink', 'sys', 'system', 'terminal_size', 'times',
# 'times_result',
# 'truncate', 'umask', 'uname_result', 'unlink', 'urandom', 'utime', 'waitpid', 'walk', 'write']
# 包json的内容是['JSONDecodeError', 'JSONDecoder', 'JSONEncoder', '__all__', '__author__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__',
# '__path__', '__spec__', '__version__', '_default_decoder', '_default_encoder', 'codecs', 'decoder', 'detect_encoding', 'dump', 'dumps', 'encoder', 'load', 'loads', 'scanner']
导入包和模块
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 导入包和模块
# 常规导入:
# 导入单个模块:语法:import [package_name0.package_name1.···]module_name # package_name仅在有包的时候使用,重叠使用是在多个包嵌套的前提下
# 导入多个模块:语法:import [package_name0.package_name1.···]module_name0, [package_name0.package_name1.···]module_name1, [package_name0.package_name1.···]module_name2···
# 增加别名简化代码:语法:import [package_name0.package_name1.···]module_name as another_name
#
# 注意:
# 使用导入的模块中的资源时需要注明模块名称:another_name.object_name / [package_name0.package_name1.···]module_name.object_name
# 导入模块时不需要写模块的 .py 后缀
# 导入包和模块时会执行包内部的__init__.py文件
# 补充:
# 如果只导入一个包,仅仅执行包中的__init__.py文件
# 解决方式:
# 1.在__init__.py文件中添加相关模块的导入(需要注意模块路径检索问题,需要使用绝对路径)
# 2.使用from ··· import ··· 的方式导入
# 导入单个模块
import time
print(time.strftime("%Y - %m - %d %H : %M : %S"))
print(time.strftime("%Y年%m月%d日 %H时%M分%S秒"))
# 导入多个模块
import time, datetime
print(time.strftime("%Y年%m月%d日 %H时%M分%S秒"))
print(datetime.datetime.now())
# 增加别称
import time as T
print(T.strftime("%Y - %m - %d %H : %M : %S"))
# 2020 - 04 - 02 22 : 18 : 31
# 2020年04月02日 22时18分31秒
# 2020年04月02日 22时18分31秒
# 2020-04-02 22:18:31.968829
# 2020 - 04 - 02 22 : 18 : 31
# from语句导入:
# 基础语法:from package import module / from module import object as another_name
# 各种导入的语法:
# 从包中导入模块:
# 导入单个模块:from package import module_name[ as another_name]
# 导入多个模块:from package import module_name0, module_name1··· # 被导入的模块必须在package这一包中
# 导入多个模块并起别名:from package import module_name0 as another_name0, module_name as another_name1 # 必须是是这个写法而不是:from package import module_name0, module_name as another_name0, another_name1 # 违背了面向关系
# 包有多个层级时需要将路径写在 from 语句后面 from package0.package1··· import module_name # 也是面向关系的原因,即import后面的语句只能是单个包、模块或者功能的名称
# 从模块中导入模块的资源:同从包中导入模块
# 作用:导入包和模块中的某一部分资源
# 理论基础:只能从范围大的地方中找范围小的地方
# 范围排序:包 > 模块 > 模块中的资源
# 注意面向关系:
# 包里面只能找模块,而不能找模块中的资源
# 模块里面只能找模块中的资源,不能找包中的资源
# 补充:
# from package import *
# from module import *
# 该方法导入的是package的 __init__.py 文件中的或者module中的 __all__ = ['object_name0', object_name1···] 全局变量列表中的添加的对象
# 如果上述文件中没有 __all__ 这个全局变量,那么就会导入 package 或者 module 中的全部资源
# 该方法仅仅只能导入非下划线资源
# 注意:该方法慎用,如果 module 的资源和自己写的代码中重名,会产生覆盖
# 注意事项:
# 1.导入模块后具体做了什么事:
# 1.在被导入模块的命名空间下运行所有代码
# 2.创建一个模块对象(与被导入模块同名),并将被导入模块内的所有顶级变量(全局变量)以属性的方式绑定在模块对象上
# 3.在 import 位置,引入 import 后面的变量名称到当前变量命名空间
# 后续再次导入该模块时:直接执行第三步
# 结论:import ··· / from ··· import ··· 两种导入方式都会执行这三个步骤
# 1.在同一模块内多次导入该模块并不会多次执行该模块
# 2.两种导入模式不存在谁更省内存 —— 仅仅存在是否是拿部分资源到当前空间来使用
# 2.在那个位置找到需要导入的模块:
# 第一次导入时:按照模块检索路径查找
# 第一级:内置模块(builtin)
# 第二级:
# sys.path:
# 查看方式:
# cmd 中运行 python3
# import sys
# print(sys.path) # sys.path 的返回值是一个列表
# 构成:
# 当前目录
# 环境变量 PYTHONPATH 中指定的路径列表
# python 安装路径
# python 安装路径下的 .pth 文件
# python 安装路径中的 lib 库
# python 安装路径中的 lib 库中的 .pth 文件
# 追加路径的方式:
# 方式一:添加的路径仅在使用的这个模块有效
# import sys
# sys.append(r'文件路径') # 优先级最低,添加在列表的末尾,列表有序!
# 方式二:修改环境变量
# 仅在 shell 中有效:
# 打开 编辑系统环境变量 这个设置
# 高级 ——> 环境变量 ——> 用户变量 / 系统变量 ——> 点击 新建 ——> 在变量名中输入 PYTHONPATH 在变量值中输入 对应的文件位置
# 用户变量仅对该用户有效,系统变量对所有用户有效
# pycharm:File ——> Settings ——> Project Interpreter ——> 点击齿轮图标 ——> Show All Show paths for selected interpreter(最右侧那排图标最下面的那一个) ——> 点击 + ——> 选择目标文件夹
# 想要删除点击 -
# 方式三:创建 .pth文件
# 获取创建 .pat 文件的位置:
# import site
# print(site.getsitepackages()) # 返回值是一个列表,由可创建 .pth 路径字符串组成
# 添加路径:
# 转到给出的路径创建一个后缀为 .pth 的文件
# 打开该文件写入想要添加的路径
# 注意:该方法对 shell 和 pycharm 都有效
# 第二次导入时:
# 从已加载的模块去查找
# 查看已加载模块的方式:
# import sys
# print(sys.modules)
# 3.导入模块的常见场景:
# 局部导入:在局部范围内(函数、类、方法)导入一个模块,该模块在其他范围无效
# 覆盖导入:
# 场景一:
# 自定义模块与非内置的标准模块重名:根据前者的储存位置,可能会覆盖非内置的标准模块
# 自定义命名的模块尽量不要与非内置的标准模块重名
# 场景二:
# 自定义模块与内置模块重名:内置模块会覆盖自定义模块
# 又想使用重名的自定义模块:使用 from package import module 使用绝对路径导入
# 循环导入:两个模块互相导入,A模块导入B模块,B模块导入A模块
# 可能产生问题,详解见下图
# 优先导入:
# 两个模块功能接近并且api相同,根据需要优先选择一个导入
# 语法:
# try:
# import module_name0 as another_name # 此处导入的模块是优先级较高的
# except ModuleNotFoundError:
# import module_name1 as another_name # 此处设置的别名和 try 语句中的相同,方便后面调用
# 包内导入:分为绝对导入和相对导入
# 概念:python导入分为绝对导入和相对导入,包内导入就是包内的模块带入包内部的模块
# 绝对导入:
# 参照 sys.path 进行检索
# 例如:指明包名或者模块名:import package_name/module_name / from package import module
# 注意:以上结论基于python3.x
# 相对导入:
# 使用 . 来指代相对路径:
# from . import module_name
# from .. import module_name
# . 根据模块名称所获取的当前目录
# .. 根据模块名称所获取的上层目录
# 查看当前模块名称的方式:
# print(__name__) 输出为:[package.]module_name 如果是以脚本运行的文件而不是导入的文件,返回值为 __main__,所以在主要模块中使用相对导入会报错,无顶级名称对应的目录
# 注意:
# 最左侧的是顶级名称
# 执行 .py 文件时会将当前文件的路径传递到 sys.path 中作为当前文件的值,而且一旦确定就不会更改:
# 主要针对:
# package:
# x.py # 该文件使用 import xx 导入sub_package 中的 xx.py 模块
# sub_package:
# xx.py # 该文件中使用 import xxx 导入同级目录下的 xxx.py 文件
# xxx.py
# 这种导入会报错:执行 x.py 时向 sys.path 添加的路径是package,导入 xx.py 时也执行的该路径,根据面向对象关系无法找到 xx.py 这个文件,报错信息为ModuleNotFoundError
# 修正方式:
# 将 x.py 中的导入方式改为 from sub_package import xx.py # xx.py 的导入修正也是同理
# 存在的问题:如果 sub_package 中多个模块都是这样,如果 sub_package 名称修改,那么每个文件的名称都要修改,较为麻烦
# 优化:使用 . / .. 来代替路径:使用 __name__ 获取的名称有几个 . ,就使用几个点,否则会报错:Value Error: attempted relative import beyond top-level package
# package:
# x.py from sub_package import xx.py # 该文件只能使用该方式导入, x.py 以脚本形式运行,__name__ 的值是 __main__ 不能根据模块名找到路径
# sub_package:
# xx.py from . import xxx # 该文件可通过 print(__name__) 并运行 x.py 来获取模块名称
# xxx.py
# 补充:python3.x之前,直接使用 import module
# 原因:
# 优先从本地目录查找而非 sys.path
# 解决方式:在以前的版本中添加 from __future__ import absolute_import 改变import 行为
# 结论:
# 包内导入:使用相对导入
# 包外导入:使用绝对导入
import datetime
print(type(datetime))
# , 'MINYEAR': 1, 'MAXYEAR': 9999, 'timedelta': , 'date': ,
# 'tzinfo': , 'time': , 'datetime': , 'timezone': , 'datetime_CAPI':
# "datetime.datetime_CAPI" at 0x000001E35EE88A20>}
ID0 = id(datetime)
import datetime
ID1 = id(datetime)
print(ID0 == ID1)
# True
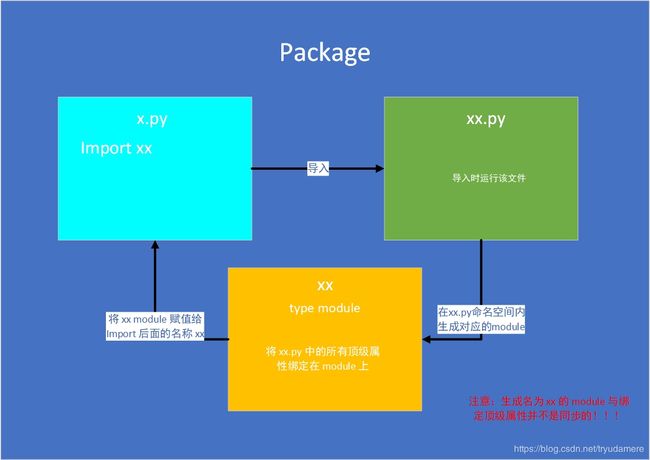
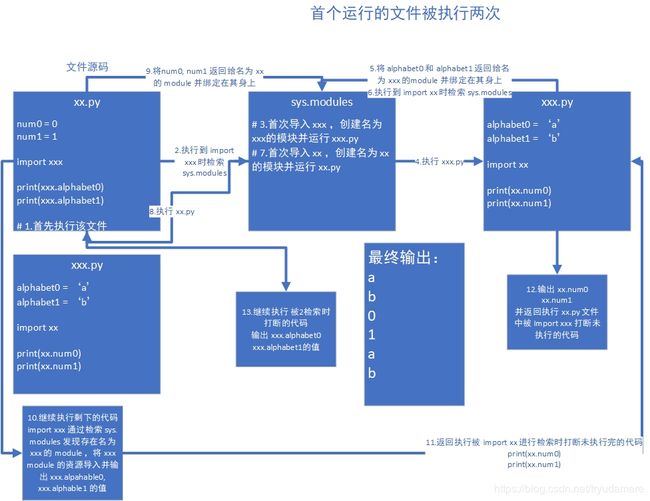
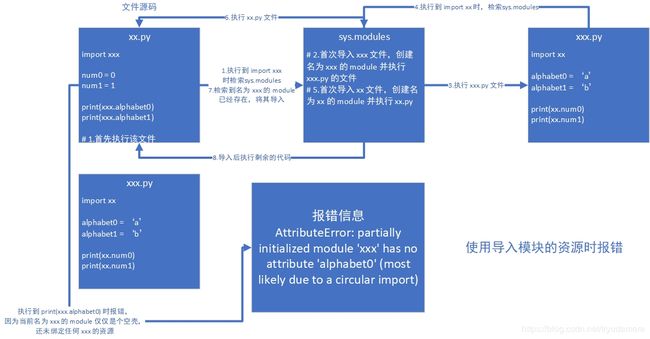
第三方包和模块的安装和升级
一般基础
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 一般基础
# 第三方包和模块与标准包和模块的区别和联系:
# 都是为了完成某个功能
# 标准模块:由官方发布;使用可靠几乎没有bug,即使有也修复很快;有健全的使用文档说明
# 第三方包和模块:文档不健全;更新不及时甚至不更新;功能可能有bug
# 安装的方式:
# 源码安装:手动下载源码并安装到本地
# 包管理器安装:更加简单自动化地为用户管理本地包和模块
# 包和模块的安装简史:
# distutils:
# 标准库地一部分
# 能够进行简单的安装
# 通过 setup.py 进行安装
# setuptools:
# 基于 distutils 产生的
# 现在的包安装标准
# 自带一个 easy-install 安装脚本 # 后续出现了 pip 安装脚本来代替这个脚本
# 引入了 .egg 的格式 # 后续出现了 .whl 格式来代替这个格式
# 属于第三方库
# setuptools是当前最好的选择
# 常见的第三方包和模块的格式:
# 源码:
# 单文件模式 —— .py
# 多文件模式:由包管理工具发布的项目
# 无论是 distutils 还是 setuptools 发布的项目都包括 setup.py 文件
# .egg:
# 由 setuptools 引入的一种格式,setuptools 可以识别和安装,本质上属于压缩包
# .whl:
# 本质是 .zip ,为了代替 .egg 而引入的
# 安装方式:
# 本地安装:手动下载包和模块并安装
# 对于单文件:直接拷贝到相关文件夹即可
# 对于带 setup.py 的文件:使用 setup.py 脚本安装
# .egg 文件:通过 setuptools 自带的安装脚本 easy_install 进行安装
# .whl 使用 pip 进行安装
# 远程安装:通过命令自动下载包和模块进行安装
# 平台:
# easy_install
# pip
# pycharm
安装源:
python官方源码托管平台
豆瓣pypi镜像
阿里云pypi镜像
清华大学pypi镜像
具体安装操作
# 具体操作步骤:
# 本地安装:
# 单文件:将文件拷贝到 Python38\\lib\\site-packages
# 对于带 setup.py 的文件:
# 1.解压下载好的模块压缩包
# 2.打开 cmd 命令行(最好是以管理员模式打开)
# 3.切换到 setup.py 文件的路径(cd 文件路径)
# 4.python2.x:执行 python[2] setup.py install
# python3.x:执行 python[3] setup.py install
# 注意:
# 如果项目是 distutils 打包的,那么上述命令可以直接执行
# 如果项目是 setuptools 打包的,那么本地没有 setuptools 时会报错
# 如果安装的包有依赖的第三方包,如果处于离线状态,那么安装会失败
# .egg 文件的安装:使用 setuptools 自带的 easy_install 安装
# easy_install xxx.egg
# .whl 文件的安装:
# 使用 easy_install 安装
# 使用 pip 安装:
# 语法:pip install 文件路径 + 文件名
# 注意:pip 在安装 python 时勾选安装,如果没有安装可以使用 easy_install 手动或者远程安装(cmd 输入 easy_install pip)
# 远程安装:自动从网络上检索 > 下载 > 安装模块
# 安装方式:cmd 下运行
# easy_install package_name
# pip install package_name
# 注意:
# 默认包的来源:https://pypi.org
# 默认储存位置:Lib \ site-packages
其他操作
# 包和模块的其他操作:
# easy_install:easy_install 官方介绍文档:http://peak.telecommunity.com/DevCenter/EasyInstall?action=highlight&value=easy_install
# 在多个 python 版本中选择安装:如果直接输入 easy_install package_name / pip install package_name 会根据系统环境变量中的 python 版本顺序安装在优先级较高的 python 版本中
# 语法:easy_install-X.x package_name # X.x 指的是 python 版本
# 安装指定版本:
# 语法:easy_install "库名 限定符 版本 [, 版本 限定符]"
# 限定符:
# <:安装小于指定版本的最新指定库
# >:安装大于指定版本的最新指定库
# <=:安装小于等于指定版本的最新指定库
# >=:安装大于等于指定版本的最新指定库
# ==:安装指定版本的指定库
# >, <[<=, >=]:安装指定版本之间的指定库
# 注意:如果指定版本已经安装,那么只是将 easy_install.pth 文件中的路径改为指定版本
# 升级第三方库:语法:easy_install --upgrade[-U] package_module
# 卸载第三方库:
# 方式一:手动卸载
# 步骤:
# 删除第三方库的文件
# 删除 easy_install.pth 中的第三方库的路径
# 方式二:easy_install -m package_name
# 注意:
# easy_install.pth 的作用:记录当前通过 easy_install 安装的第三方模块(安装多个版本时只记录最后安装的版本);用于导入模块时的检索路径
# easy_install -m package_name :该方法并不会删除第三方库的源文件,只是将第三方库的路径从 easy_install.pth 中移除
# 目的是为了动态的使用指定库的版本
# 使用方式:语法:
# import pkg_resources
#
# pkg_resources.require("package_name == 指定版本(必须写全)")
#
# import package_name
# 切换第三方安装源:Lib\site-packages\setuptools.egg(解压缩,改完再压缩回去)\command\easy_install.py --> ctrl + f --> www.pypi.org --> 更换为任意安装源
# pip:官方介绍文档:https://pip.pypa.io/en/stable/
# 修改安装源:
# 单次修改:
# 指定路径检索:pip install --index-url 网址
# 扩展检索:pip install --extra-index-url 网址 # 首先到官网检索,没找到再到给定的网址检索
# 永久修改:
# 在 C盘/用户/用户名 下建立名为 pip 的文件夹
# 在文件夹中创建一个记事本,在内部写入:
# [global]
# index-url = 安装源网址
# [install]
# trusted-host=安装源网址的主站
# 将文件名改为:pip.ini(注意将 .txt 后缀删除)
# 安装到不同版本的解释器中:
# python2 / 3 -m pip install package_name
# py-2 / -3 -m pip install package_name
# 补充:
# python在安装时在系统中安装了启动器 py.exe 位于 C:\Windows\py.exe
# 启动器可以调用不同版本的 python 去执行某些脚本
#
# 查看包:cmd 模式下
# 所有已安装的包:pip list
# 不被依赖的包: pip list --not-required
# 非最新的包:pip list --outdated
# 查看某个包的最新的信息:pip show package_name
# 搜索包:
# pip search package_information # 默认检索网址为:https://pypi.org
# pip search -i 指定网址 package_information
# 安装指定版本的库:与 easy_install 的安装方式相同,只是将 easy_install 更替为 pip
# 注意:pip 与 easy_install 不同在于:pip 在安装指定版本的包时会卸载已有的非指定版本的同名包,在安装指定版本的包,如果存在指定版本的包不会重新安装
# 升级包:
# pip install --upgrade package_name
# 注意:不能使用 pip install package_name 来安装最新的包,该方式只适用于指定的包不存在时才会安装最新的包
# 卸载包:
# pip uninstall package_name
# 注意:
# 如果指定的包是通过 easy_install 安装的,那么使用该命令会删除 easy_install.pth 中包的路径和 对应的 .egg 文件
# 如果指定的包是通过 pip 安装的,那么使用该命令会删除对应的包的文件
# 生成冻结文本和使用冻结文本来安装包:
# 冻结文本:当前安装的包的名字及版本
# 生成冻结文本:首先要转到想要保存的位置
# pip freeze [> 指定文件目录/requirements.txt] # 文件名为 requirements.txt 为一般命名方式 # 如果不写可选部分,那么只是在 cmd 控制台中输出包名及版本
# 使用冻结文本来安装指定的包:
# pip install -r requirements.txt
# 补充:
# 版本变动规则:N1.N2.N3
# N1:修改了之前的功能、添加了一个功能或者修改了 api # N1 + 1,同时清零 N2, N3
# N2:新增了一个小功能 # N2 + 1,同时 N3 清零
# N3:修复了当前版本的 bug # N3 + 1
包和模块的发布
前期准备
# _*_coding:itf-8_*_
# !/usr/bin/env python3
from __future__ import absolute_import
# 包和模块的发布
# 官方文档地址:https://python-packaging.readthedocs.io/en/latest/minimal.html
# 账号操作:
# 注册账号:https://pypi.python.org/pypi
# 验证邮箱:https://pypi.org/manage/account/
# 环境准备:安装 setuptools, pip, wheel, twine
# 发布前的准备:
# 创建一个项目:
# 项目结构:
# 项目名称:
# 包名称: # 真正的包和模块
# __init__.py # 真正的包和模块
# 模块 # 真正的包和模块
# 模块 # 真正的包和模块
# setup.py: 该文件必须有
# 作用:项目信息的配置文件,在这个文件中执行 setup() 函数,通过函数来指明信息
# 示例:
# from distutils.core import setup
# setup(形参0=实参0, 形参1=实参1···)
#
# from setuptools import setup
# setup(形参0=实参0, 形参1=实参1)
# 参数说明:
# name: name="package_name"
# version: version="1.0.1"
# description: description="There is used to writing package information"
# packages: packages=["need to deal with other packages"]
# py_modules: py_modules=["need to deal with single modules"]
# author: author="author_name"
# author_email: author_email="[email protected]"
# long_description: long_description="This description will display on PyPi project introduction and read in from readme.rst"
# install_requires: install_requires=[required_package_name operation version]
# python_requires: python_requires operation version
# url: url="Your project home page"
# license: license="Your project supported protocols"
# setup.py 说明文档:
# https://docs.python.org/2/distutils/setupscript.html
# https://packaging.python.org/tutorials/distributing-packages/
# README.rst: # 可选
# 概念:
# rst:reStructuredText —— 重新构建文本
# 作用:
# 使用特定的字符来描述文本的格式
# PyPi 平台能够识别 long_description 字段中所写的这种格式的字符串
# 但是将所有的字符串都写在 setup() 函数中会比较混乱,所以一般将内容写在一个
# 名为 README.rst 文件中,然后在 setup.py 这个文件中读取并赋值给 long_description
# 文件内容的编写:
# rst 文件介绍文档:http://zh-sphinx-doc.readthedocs.io/en/latest/contents.html
# pycharm 内置 rst 文件格式编辑支持,显示识别后的 rst 文本 # 好像教育版不支持安装该插件,需要下载 Intellij IDEA 里面下载 ReStr 插件,查看渲染后的界面也需要在这里面
# 检测编写内容是否能在 PyPi 上完整渲染:
# 产生原因:
# pycharm 使用的渲染工具是 sphinx ,而 PyPi 不是使用的该工具,两个渲染工具存在一定的语法差异
# 示例:requests 2.18.4
# 方式:使用 readme_renderer 库
# cmd 模式下进入想要检测的文件路径
# 输入 python[3] setup.py check -r -s
# 注意:如果最后输出的 running check 则是不存在语法问题
# LICENSE.txt: # 可选
# 作用:
# 声明库的一些使用责任
# 所有权归属、是否可对代码进行任何操作、是否可用于商业用途
# 文件内容获取:https://choosealicense.com/
# MANIFEST.in: # 可选
# 官方文档:https://docs.python.org/3/distutils/sourcedist.html#specifying-the-files-to-distribute
# 指定需要打包的其他文件
# 语法:在文件内写
# include xxx.xx # 该方式只能指定一个文件
# recursive-include examples *.txt *.py # 打包所有 .xx 格式的文件
# prune examples/sample?/build # 打包除去该文件以外的其他文件
# 注意:
# 命名全部小写
# 多个单词以 - 划分,不能使用_
# 不能与 PyPi 中已有的文件重名
# 打包形成的名字是由 name-version 组成的
# 编译生成安装包:在 cmd 执行
# 进入 setup.py 的同级目录
# 执行:
# python[3] setup.py sdist [--formats=zip, tar ···] # 生成源码的压缩包,可在任何平台上重新编译所有内容
# python[3] setup.py bdist # 生成二进制包,不包含 setup.py 文件,只能在与打包相同的平台上使用 windows + python3
# python[3] setup.py sdist_egg # 生成 .egg 格式的包,需要 setuptools 库,其他的同 bdist
# python[3] setup.py sdist_wheel # 生成 .wheel 格式的包,需要 wheel 库,其他的同 bdist
# python[3] setup.py sdist_wininst # 生成可在 windows 下直接安装的包
# 查看其它的命令及解释:python[3] setup.py --help -commands
# 安装方式:
# 带 setup.py 的源码压缩包:
# 解压压缩包 ——> cmd 模式下进入 setup.py 所在的位置 ——> 执行 python[3] setup.py install
# cmd 模式下进入压缩包所在的位置 ——> 执行 easy_install 包名 / pip install 压缩包名
# 二进制发行包:
# 解压压缩包 —— 复制解压后的文件 site-packages 里的除了 __pycache__ 的文件到 python/xx/Lib/site-packages 即可
# windows 发行包:直接双击运行即可
# .egg: cmd 模式下进入文件所在路径 ——> easy_install 包名
# .whl: cmd 模式下进入文件所在路径 ——> easy_install / pip install 包名
发布和升级
# _*_coding:utf-8_*_
# !/usr/bin/env python3
from __future__ import absoulte_import
# 上传打包好的包:
# 安装 twine 库
# cmd 模式下进入 打包好的包所在的路径
# 输入 twine upload 包名全称
# 输入 PyPi 注册的名称和密码
# 版本迭代:根据迭代规则更改 setup.py 中的 setup() 函数中的 version 的参数,再按照发布规则发布即可
包和模块的补充
# _*_coding:utf-8_*_
# !/usr/bin/env python3
# 包和模块的补充
from __future__ import absolute_import
# 区分模块测试与发布状态:
# 写代码时存在测试代码,查看代码是否出错,如果在发布时不解决测试代码,那么其他使用者下载了代码后在导入时会直接执行顶级代码,可能会执行测试代码,引起不必要的麻烦
# 处理方式:
# 1.发布前将所有测试代码删除或者注释掉
# 2.将测试代码写在 if __name__ == main: 范围内
# 原因:
# 如果模块以脚本的形式运行,那么 __name__ = __main__
# 如果模块以导入的形式运行,那么 __name__ = package_name.module_name
# 这样其他使用者使用时就不会运行测试代码了
# 在 pycharm 中安装包和模块:
# File -- Settings -- Project -- ProjectInterpreter
# 安装新模块:点 + -- 在上部的搜索框输入包或者模块的名称 -- 点击左下角 install Package -- 安装完成后有 “Packages Installed Successfully”
# 升级:点击想要升级的包或者模块再点击 ▲
# 删除:点击想要删除的包或者模块再点击 —
# 更改安装源(永久):搜索模块的界面左下角点击 Manage Repositories +:添加, —:删除, 铅笔:修改
虚拟环境
虚拟环境的概念和安装
# _*_coding:itf-8_*_
# !/usr/bin/env python3
from __future__ import absolute_import
# 虚拟环境:
# 概念:独立的、局部的 Python 环境
# 实现方式:
# 方式一:首先安装 virtualenv(pip install virtualenv)
# 官方文档说明:https://virtualenv.pypa.io/en/latest/user_guide.html
# 具体步骤:
# 1.创建一个虚拟环境:
# 首先创建项目文件夹 ——> cmd 模式下切换到项目文件 ——> 运行 virtualenv virtualenv_name
# 可选参数:
# -p:virtualenv -p 指定 python 版本的路径 虚拟环境名称 # 用于指定 python 的版本,如果不写,默认继承自 virtualenv 所在的 python 版本
# --sys-site-packages 虚拟环境名称 # 写了就关联系统的第三方库,如果不写只会在虚拟环境自身的三方库中查找。注意不是复制,只是获得系统第三方库的使用权(如同类的继承)
# 2.激活虚拟环境:
# cmd 模式下进入虚拟环境 python 所在的文件夹的 scripts 中,运行 activate[.bat] 文件
# 在虚拟环境下做的所有操作只对虚拟环境有效,不会对全局 python 产生影响
# 3.退出虚拟环境:cmd 模式下进入虚拟环境 python 所在的文件夹中的 scripts 文件夹中,运行 deactivate.bat 文件。后续的操作就会作用于全局 python
# 5.删除虚拟环境:删除整个虚拟环境文件夹即可
# 补充:
# 虚拟环境项目交接:
# 方式一:将整个虚拟环境文件夹拷贝给别人
# 方式二:在虚拟环境中生成冻结依赖需求文本,将冻结依赖需求文本交给别人,别人根据冻结依赖需求文本来创建虚拟环境
# 使用 pycharm 生成虚拟环境:
# File --> New Project --> 项目名称根据需要填 --> 展开 Project Interpreter --> 在 Base Interpreter 选择作为引子的解释器(相当于 virtualenv 中的 -p 命令)
# 注意:
# Inherit global site packages 相当于 virtualenv 中的 --sys-site-packages 命令
# Make available to all projects 是指该虚拟环境能运行所有项目,而不是局部的
# 此时包和模块的管理还是和之前一样,同时解释器也可在 Settings --> Project Interpreter(即管理包、模块和解释器的地方)更改
虚拟环境的补充
# _*_coding:utf-8_*_
# !/usr/bin/env python3
from __future__ import absolute_import
# 集中式的虚拟环境管理:
# 使用库:virtualenvwrapper-win
# 官方文档说明:https://pypi.org/pypi/virtualenvwrapper-win
# 作用:将分散在各个路径的虚拟机集中到统一的路径下进行管理,更加方便虚拟环境的切换和 virtualenv 的使用
# 具体使用:所有命令的执行与虚拟式状态(是否激活)无关 # 在 cmd 模式下运行
# 创建虚拟环境:
# 语法:mkvirtualenv 虚拟环境名称
# 注意:
# windows 下会将虚拟环境默认建立在用户的 Envs 文件中,同时激活虚拟环境
# 注意:在虚拟环境下也可以执行该命令,效果同没有激活虚拟环境
# 查看所有的虚拟环境:
# 语法:listvirtualenv
# 切换虚拟环境:
# 语法:workon [虚拟环境名称]
# 注意:如果不添加虚拟环境名称,那么会提示你添加虚拟环境并列出所有虚拟环境
# 关闭虚拟环境:deactivate
# 删除虚拟环境:rmvirtualenv 虚拟环境名称,并退出激活状态(如果该虚拟环境已经激活)
# 基于项目的虚拟环境管理:
# 库名称:Pipenv
# 功能:pip + virtualenv
# 会自动创建虚拟环境和安装第三方库,使用 Pipfile 和 Pipfile.lock 取代 requirements.txt ,自动记录项目依赖的第三方库
# 官方文档:https://pipenv.pypa.io/en/latest/ # 可通过输入 pipenv 查看简略操作方式
# 具体使用: # 在 cmd 模式下运行
# 创建虚拟环境:
# 命令:cmd 模式下进入项目位置 --> pipenv --two / --three [--site-packages] # 可选参数为是否继承系统第三方包
# 查看其他信息:
# 查看项目位置:pipenv --where
# 查看虚拟环境位置:pipenv --venv
# 查看解释器信息:pipenv --py
# 注意:该库生成的虚拟环境(pipfile.lock)和解释器的位置不一致
# 激活项目:在 cmd 模式下进入项目的目录 --> 输入 pipenv shell # 此时 cmd 的名称会变成 “命令提示符 - pipenv shell”
# 在虚拟环境中的操作:
# 首先需要进入项目文件并激活虚拟环境
# 运行代码:python[2 / 3] 文件名称.py
# 安装包:不能使用 “pip” 命令
# 使用 pipenv install 包的名称
# 作用:
# 首先在当前环境监测是否存在这个第三方库,
# 如果不存在就安装这个第三方库(如果存在就跳过这一步)
# 在项目目录下,通过 pipfile 和 pipfile.lock 记录安装的包和依赖关系
# 注意:使用 pip install 包名 安装,虽然会安装第三方库,但是不会在 pipenv 和 pipenv.lock 中记录安装的包和依赖关系
# 查看包以及依赖关系:cmd 模式下进入项目文件并激活虚拟环境,输入 pipenv graph
# 卸载包:
# cmd 模式下进入项目文件并激活虚拟环境,输入 pipenv uninstall 包名
# 注意:不能使用 pip uninstall 包名 来卸载包,道理同 pip install 包名
# 退出虚拟环境:输入 exit 或者直接关闭 cmd 窗口
# 删除虚拟环境:cmd 模式下进入项目的目录,输入 pipenv --rm
# 补充:
# 上传项目应当传的内容:自己写的包或者模块,pipenv 和 pipenvfile
# 拿到有pipenv写的项目应当如何使用:
# 首先将包和模块的源码拷到项目文件
# cmd 模式下进入项目目录
# 创建虚拟环境 使用 pipenv install 会自动识别项目需要的 python 版本并安装依赖的包和模块