#####好好好#######干货满满的深度强化学习综述(中文)
0.来源说明
引用:深度强化学习综述
作者:刘全,翟建伟,章宗长,钟珊,周 倩,章 鹏,徐 进
单位:苏州大学计算机科学与技术学院 、软件新技术与产业化协同创新中心
出处:计算机学报,2017年第40卷
整理&排版:九三山人
1.内容提要
九三智给大家推荐一篇苏州大学刘全老师等人综述的深度强化学习方向发展情况,虽然是在2017年发表,没有覆盖到DeepMind打星际,OpenAI打DOTA等方面最新的进展,但也把DRL这个方向的主要发展脉络梳理的蛮清晰的,而且是中文版哟,28页的综述奉上~
“
全文PDF下载,公众号回复:20181115
”
深度强化学习是人工智能领域的一个新的研究热点. 它以一种通用的形式将深度学习的感知能力与强化学习的决策能力相结合,并能够通过端对端的学习方式实现从原始输入到输出的直接控制。自提出以来, 在许多需要感知高维度原始输入数据和决策控制的任务中,深度强化学习方法已经取得了实质性的突破.
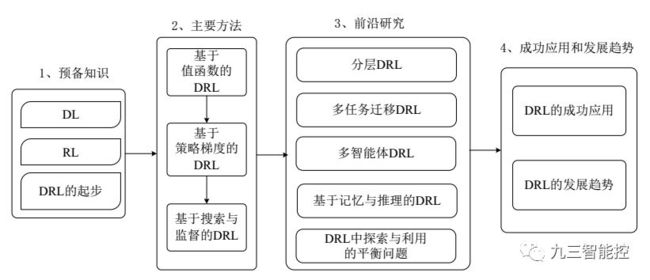
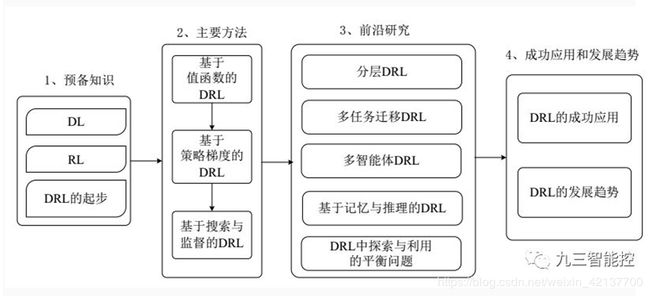
该文首先阐述了 3 类主要的深度强化学习方法,包括基于值函数的深度强化学习、基于策略梯度的深度强化学习和基于搜索与监督的深度强化学习;其次对深度强化学习领域的一些前沿研究方向进行了综述,包括分层深度强化学习、多任务迁移深度强化学习、多智能体深度强化学习、基于记忆与推理的深度强化学习等. 最后总结了深度强化学习在若干领域的成功应用和未来发展趋势。
2.强化学习的基本概念
强 化 学 习 (Reinforcement Learning, RL) 作为机器学习领域另一个研究热点,已经广泛应用于工业制造、仿真模拟、机器人控制、优化与调度、游戏博弈等领域.RL的基本思想是通过最大化智能体(agent) 从环境中获得的累计奖赏值,以学习到完成目标的最优策略。因此 RL 方法更加侧重于学习解决问题的策略,被认为是迈向通用人工智能(Artificial General Intelligence, AGI)的重要途径。
3.深度强化学习的应用
在 DRL 发展的最初阶段, DQN 算法主要被应用于 Atari 2600 平台中的各类 2D 视频游戏中. 随后,研究人员分别从算法和模型两方面对 DQN 进行了改进,使得 agent 在 Atari 2600 游戏中的平均得分提高了 300%,并在模型中加入记忆和推理模块,成功地将 DRL 应用场景拓宽到 3D 场景下的复杂任务中. AlphaGo 围棋算法结合深度神经网络和MCTS,成功地击败了围棋世界冠军. 此外, DRL在机器人控制、计算机视觉、自然语言处理和医疗等领域的应用也都取得了一定的成功。
深度强化学习在机器人控制领域的应用:在 2D 和 3D 的模拟环境中, 基于策略梯度的DRL 方法(TRPO、 GAE、 SVG、 A3C 等) 实现了对机器人的行为控制. 另外, 在现实场景下的机器人控制任务中,DRL也取得了若干研究成果。
深度强化学习在计算机视觉领域的应用:基于视觉感知的 DRL 模型可以在只输入原始图像的情况下,输出当前状态下所有可能动作的预测回报. 因此可以将 DRL 模型应用到基于动作条件的视频预测(action-conditional video prediction)任务中。
深度强化学习在自然语言处理领域的应用:利用 DRL 中的策略梯度方法训练对话模型,最终使模型生成更具连贯性、交互性和持续响应的一系列对话。
深度强化学习在参数优化中的应用:通过某种DRL学习机制,根据具体问题自动确定相应的学习率,将极大地提升模型的训练效率,暂时还处于初步阶段,例如谷歌利用 DRL 算法来优化数据中心服务器群的参数设置,并节省了 40%的电力能源.
深度强化学习在博弈论领域的应用:DRL 的不断发展为求解博弈论问题开辟了一条新的道路. 深度卷积网络具有自动学习高维输入数据抽象表达的功能, 可以有效解决复杂任务中领域知识表示和获取的难题. 目前,利用 DRL 技术来发展博弈论已经取得了不错的研究成果。
4.DRL基本原理
DRL 是一种端对端(end-to-end) 的感知与控制系统,具有很强的通用性. 其学习过程可以描述为:
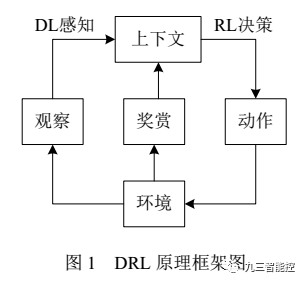
(1) 在每个时刻 agent与环境交互得到一个高维度的观察,并利用 DL 方法来感知观察, 以得到抽象、具体的状态特征表示;
(2) 基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作.
(3)环境对此动作做出反应,并得到下一个观察. 通过不断循环以上过程,最终可以得到实现目标的最优策略.
5.主要方法
-
基于值函数的深度强化学习
深度 Q 网络:Mnih等人将卷积神经网络与传统 RL中的Q 学习算法相结合, 提出了深度 Q 网络(Deep Q-Network, DQN)模型. 该模型用于处理基于视觉感知的控制任务,是 DRL 领域的开创性工作。

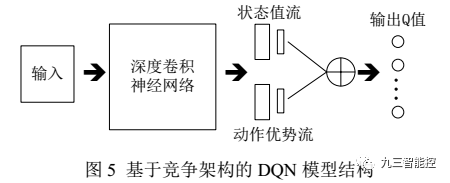
DQN 模型结构的改进:对 DQN 模型的改进一般是通过向原有网络中添加新的功能模块来实现的. 例如,可以向 DQN模型中加入循环神经网络结构,使得模型拥有时间轴上的记忆能力,比如基于竞争架构的 DQN 和深度循环 Q 网络(Deep Recurrent Q-Network,DRQN) .
竞争网络结构的模型则将 CNN 提取的抽象特征分流到两个支路中,其中一路代表状态值函数,另一路代 表 依 赖 状 态 的 动 作 优 势 函 数 (advantagefunction) . 通过该种竞争网络结构, agent 可以在策略评估过程中更快地识别出正确的行为。
Hausknecht 等人利用循环神经网络结构来记忆时间轴上连续的历史状态信息,提出了 DRQN 模型。在部分状态可观察的情况下, DRQN 表现出比 DQN 更好的性能. 因此 DRQN 模型适用于普遍存在部分状态可观察问题的复杂任务.
-
基于策略梯度的深度强化学习
在求解 DRL 问题时,往往第一选择是采取基于策略梯度的算法. 原因是它能够直接优化策略的期望总奖赏,并以端对端的方式直接在策略空间中搜索最优策略,省去了繁琐的中间环节. 因此与 DQN 及其改进模型相比, 基于策略梯度的 DRL 方法适用范围更广,策略优化的效果也更好。
策略梯度方法是一种直接使用逼近器来近似表示和优化策略,最终得到最优策略的方法. 该方法优化的是策略的期望总奖赏。
![]()
深度策略梯度方法的另一个研究方向是通过增加额外的人工监督来促进策略搜索. 例如著名的 AlphaGo 围棋机器人,先使用监督学习从人类专家的棋局中预测人类的走子行为, 再用策略梯度方法针对赢得围棋比赛的真实目标进行精细的策略参数调整。然而在某些任务中是缺乏监督数据的,比如现实场景下的机器人控制, 可以通过引导式策略搜索( guided policy search)方法来监督策略搜索的过程. 在只接受原始输入信号的真实场景中,引导式策略搜索实现了对机器人的操控。
Actor-Critic方法:在许多复杂的现实场景中,很难在线获得大量训练数据. 例如在真实场景下机器人的操控任务中,在线收集并利用大量训练数据会产生十分昂贵的代价, 并且动作连续的特性使得在线抽取批量轨迹的方式无法达到令人满意的覆盖面. 以上问题会导致局部最优解的出现. 针对此问题,可以将传统 RL中的行动者评论家(Actor-Critic, AC) 框架拓展到深度策略梯度方法中.
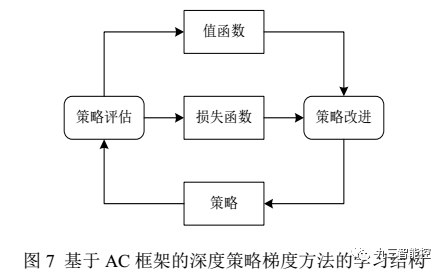
异步的优势Actor-Critic算法:Mnih 等人根据异步强化学习(Asynchronous Reinforcement Learning, ARL) 的思想,提出了一种轻量级的 DRL 框架,该框架可以使用异步的梯度下降法来优化网络控制器的参数,并可以结合多种 RL 算法. 其中,异步的优势行动者评论家算法(Asynchronous Advantage Actor-Critic, A3C) 在各类连续动作空间的控制任务上表现的最好。

-
基于搜索与监督的深度强化学习
通过增加额外的人工监督来促进策略搜索的过程,即为基于搜索与监督的 DRL 的
核心思想. 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)作为一种经典的启发式策略搜索方法,被广泛用于游戏博弈问题中的行动规划. 因此在基于搜索与监督的 DRL 方法中, 策略搜索一般是通过 MCTS 来完成的。AlphaGo围棋算法将深度神经网络和 MCTS 相结合,并取得了卓越的成就。
结合深度神经网络和 MCTS:AlphaGo 的主要思想有两点:
(1)使用 MCTS 来近似估计每个状态的值函数;
(2)使用基于值函数的 CNN 来评估棋盘的当前布局和走子.
AlphaGo 完整的学习系统主要由以下 4 个部分组成:
(1)策略网络(policy network) . 又分为监督学习的策略网络和 RL 的策略网络. 策略网络的作用是根据当前的局面来预测和采样下一步走棋.
(2)滚轮策略(rollout policy) .目标也是预测下一步走子,但是预测的速度是策略网络的 1000倍.
(3)估值网络(value network) . 根据当前局面,估计双方获胜的概率.
(4) MCTS. 将策略网络、滚轮策略和估值网络融合进策略搜索的过程中,以形成一个完整的系统
6.研究前沿
分层深度强化学习:利用分层强化学习(Hierarchical Reinforcement Learning,HRL)将最终目标分解为多个子任务来学习层次化的策略,并通过组合多个子任务的策略形成有效的全局策略。
多任务迁移深度强化学习:在传统 DRL 方法中, 每个训练完成后的 agent只能解决单一任务. 然而在一些复杂的现实场景中,需要 agent 能够同时处理多个任务,此时多任务学习和迁移学习就显得异常重要.Wang 等人总结出 RL 中的迁移分为两大类:行为上的迁移和知识上的迁移,这两大类迁移也被广泛应用于多任务 DRL 算法中。
多 agent 深度强化学习:在面对一些真实场景下的复杂决策问题时,单agent 系统的决策能力是远远不够的.例如在拥有多玩家的 Atari 2600 游戏中, 要求多个决策者之间存在相互合作或竞争的关系. 因此在特定的情形下,需要将 DRL 模型扩展为多个 agent 之间相互合作、通信及竞争的多 agent 系统。
基于记忆与推理的深度强化学习:在解决一些高层次的 DRL 任务时, agent 不仅需要很强的感知能力,也需要具备一定的记忆与推理能力,才能学习到有效的决策. 因此赋予现有 DRL 模型主动记忆与推理的能力就显得十分重要。
|引用文章:
刘全,翟建伟,章宗长,钟珊,周倩,章鹏,徐进,深度强化学习综述,2017, Vol.40,在线出版号 No.1
LIU Quan, ZHAI Jian-Wei, ZHANG Zong-Zhang, ZHONG Shan, ZHOU Qian, ZHANG Peng, XU Jin, A Survey on Deep Reinforcement
Learning, 2017,Vol.40,Online Publishing No.1
干货满满的深度强化学习综述(中文)
https://mp.weixin.qq.com/s/HQStW2AW3UIZR1R-hvJ8AQ
0.来源说明
引用:深度强化学习综述
作者:刘全,翟建伟,章宗长,钟珊,周 倩,章 鹏,徐 进
单位:苏州大学计算机科学与技术学院 、软件新技术与产业化协同创新中心
出处:计算机学报,2017年第40卷
整理&排版:九三山人
1.内容提要
九三智给大家推荐一篇苏州大学刘全老师等人综述的深度强化学习方向发展情况,虽然是在2017年发表,没有覆盖到DeepMind打星际,OpenAI打DOTA等方面最新的进展,但也把DRL这个方向的主要发展脉络梳理的蛮清晰的,而且是中文版哟,28页的综述奉上~
深度强化学习是人工智能领域的一个新的研究热点. 它以一种通用的形式将深度学习的感知能力与强化学习的决策能力相结合,并能够通过端对端的学习方式实现从原始输入到输出的直接控制。自提出以来, 在许多需要感知高维度原始输入数据和决策控制的任务中,深度强化学习方法已经取得了实质性的突破.
该文首先阐述了 3 类主要的深度强化学习方法,包括基于值函数的深度强化学习、基于策略梯度的深度强化学习和基于搜索与监督的深度强化学习;其次对深度强化学习领域的一些前沿研究方向进行了综述,包括分层深度强化学习、多任务迁移深度强化学习、多智能体深度强化学习、基于记忆与推理的深度强化学习等. 最后总结了深度强化学习在若干领域的成功应用和未来发展趋势。
2.强化学习的基本概念
强 化 学 习 (Reinforcement Learning, RL) 作为机器学习领域另一个研究热点,已经广泛应用于工业制造、仿真模拟、机器人控制、优化与调度、游戏博弈等领域.RL的基本思想是通过最大化智能体(agent) 从环境中获得的累计奖赏值,以学习到完成目标的最优策略。因此 RL 方法更加侧重于学习解决问题的策略,被认为是迈向通用人工智能(Artificial General Intelligence, AGI)的重要途径。
3.深度强化学习的应用
在 DRL 发展的最初阶段, DQN 算法主要被应用于 Atari 2600 平台中的各类 2D 视频游戏中. 随后,研究人员分别从算法和模型两方面对 DQN 进行了改进,使得 agent 在 Atari 2600 游戏中的平均得分提高了 300%,并在模型中加入记忆和推理模块,成功地将 DRL 应用场景拓宽到 3D 场景下的复杂任务中. AlphaGo 围棋算法结合深度神经网络和MCTS,成功地击败了围棋世界冠军. 此外, DRL在机器人控制、计算机视觉、自然语言处理和医疗等领域的应用也都取得了一定的成功。
深度强化学习在机器人控制领域的应用:在 2D 和 3D 的模拟环境中, 基于策略梯度的DRL 方法(TRPO、 GAE、 SVG、 A3C 等) 实现了对机器人的行为控制. 另外, 在现实场景下的机器人控制任务中,DRL也取得了若干研究成果。
深度强化学习在计算机视觉领域的应用:基于视觉感知的 DRL 模型可以在只输入原始图像的情况下,输出当前状态下所有可能动作的预测回报. 因此可以将 DRL 模型应用到基于动作条件的视频预测(action-conditional video prediction)任务中。
深度强化学习在自然语言处理领域的应用:利用 DRL 中的策略梯度方法训练对话模型,最终使模型生成更具连贯性、交互性和持续响应的一系列对话。
深度强化学习在参数优化中的应用:通过某种DRL学习机制,根据具体问题自动确定相应的学习率,将极大地提升模型的训练效率,暂时还处于初步阶段,例如谷歌利用 DRL 算法来优化数据中心服务器群的参数设置,并节省了 40%的电力能源.
深度强化学习在博弈论领域的应用:DRL 的不断发展为求解博弈论问题开辟了一条新的道路. 深度卷积网络具有自动学习高维输入数据抽象表达的功能, 可以有效解决复杂任务中领域知识表示和获取的难题. 目前,利用 DRL 技术来发展博弈论已经取得了不错的研究成果。
4.DRL基本原理
DRL 是一种端对端(end-to-end) 的感知与控制系统,具有很强的通用性. 其学习过程可以描述为:

(1) 在每个时刻 agent与环境交互得到一个高维度的观察,并利用 DL 方法来感知观察, 以得到抽象、具体的状态特征表示;
(2) 基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作.
(3)环境对此动作做出反应,并得到下一个观察. 通过不断循环以上过程,最终可以得到实现目标的最优策略.
5.主要方法
- 基于值函数的深度强化学习
深度 Q 网络:Mnih等人将卷积神经网络与传统 RL中的Q 学习算法相结合, 提出了深度 Q 网络(Deep Q-Network, DQN)模型. 该模型用于处理基于视觉感知的控制任务,是 DRL 领域的开创性工作。

DQN 模型结构的改进:对 DQN 模型的改进一般是通过向原有网络中添加新的功能模块来实现的. 例如,可以向 DQN模型中加入循环神经网络结构,使得模型拥有时间轴上的记忆能力,比如基于竞争架构的 DQN 和深度循环 Q 网络(Deep Recurrent Q-Network,DRQN) .
竞争网络结构的模型则将 CNN 提取的抽象特征分流到两个支路中,其中一路代表状态值函数,另一路代 表 依 赖 状 态 的 动 作 优 势 函 数 (advantagefunction) . 通过该种竞争网络结构, agent 可以在策略评估过程中更快地识别出正确的行为。

Hausknecht 等人利用循环神经网络结构来记忆时间轴上连续的历史状态信息,提出了 DRQN 模型。在部分状态可观察的情况下, DRQN 表现出比 DQN 更好的性能. 因此 DRQN 模型适用于普遍存在部分状态可观察问题的复杂任务.
- 基于策略梯度的深度强化学习
在求解 DRL 问题时,往往第一选择是采取基于策略梯度的算法. 原因是它能够直接优化策略的期望总奖赏,并以端对端的方式直接在策略空间中搜索最优策略,省去了繁琐的中间环节. 因此与 DQN 及其改进模型相比, 基于策略梯度的 DRL 方法适用范围更广,策略优化的效果也更好。
策略梯度方法是一种直接使用逼近器来近似表示和优化策略,最终得到最优策略的方法. 该方法优化的是策略的期望总奖赏。

深度策略梯度方法的另一个研究方向是通过增加额外的人工监督来促进策略搜索. 例如著名的 AlphaGo 围棋机器人,先使用监督学习从人类专家的棋局中预测人类的走子行为, 再用策略梯度方法针对赢得围棋比赛的真实目标进行精细的策略参数调整。然而在某些任务中是缺乏监督数据的,比如现实场景下的机器人控制, 可以通过引导式策略搜索( guided policy search)方法来监督策略搜索的过程. 在只接受原始输入信号的真实场景中,引导式策略搜索实现了对机器人的操控。
Actor-Critic方法:在许多复杂的现实场景中,很难在线获得大量训练数据. 例如在真实场景下机器人的操控任务中,在线收集并利用大量训练数据会产生十分昂贵的代价, 并且动作连续的特性使得在线抽取批量轨迹的方式无法达到令人满意的覆盖面. 以上问题会导致局部最优解的出现. 针对此问题,可以将传统 RL中的行动者评论家(Actor-Critic, AC) 框架拓展到深度策略梯度方法中.
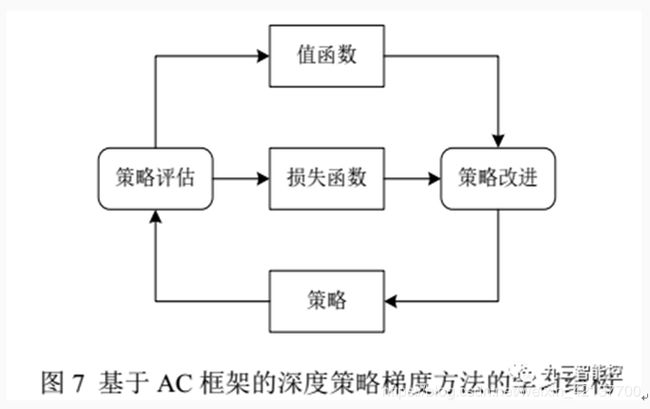
异步的优势Actor-Critic算法:Mnih 等人根据异步强化学习(Asynchronous Reinforcement Learning, ARL) 的思想,提出了一种轻量级的 DRL 框架,该框架可以使用异步的梯度下降法来优化网络控制器的参数,并可以结合多种 RL 算法. 其中,异步的优势行动者评论家算法(Asynchronous Advantage Actor-Critic, A3C) 在各类连续动作空间的控制任务上表现的最好。

- 基于搜索与监督的深度强化学习
通过增加额外的人工监督来促进策略搜索的过程,即为基于搜索与监督的 DRL 的
核心思想. 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)作为一种经典的启发式策略搜索方法,被广泛用于游戏博弈问题中的行动规划. 因此在基于搜索与监督的 DRL 方法中, 策略搜索一般是通过 MCTS 来完成的。AlphaGo围棋算法将深度神经网络和 MCTS 相结合,并取得了卓越的成就。
结合深度神经网络和 MCTS:AlphaGo 的主要思想有两点:
(1)使用 MCTS 来近似估计每个状态的值函数;
(2)使用基于值函数的 CNN 来评估棋盘的当前布局和走子.
AlphaGo 完整的学习系统主要由以下 4 个部分组成:
(1)策略网络(policy network) . 又分为监督学习的策略网络和 RL 的策略网络. 策略网络的作用是根据当前的局面来预测和采样下一步走棋.
(2)滚轮策略(rollout policy) .目标也是预测下一步走子,但是预测的速度是策略网络的 1000倍.
(3)估值网络(value network) . 根据当前局面,估计双方获胜的概率.
(4) MCTS. 将策略网络、滚轮策略和估值网络融合进策略搜索的过程中,以形成一个完整的系统
6.研究前沿
分层深度强化学习:利用分层强化学习(Hierarchical Reinforcement Learning,HRL)将最终目标分解为多个子任务来学习层次化的策略,并通过组合多个子任务的策略形成有效的全局策略。
多任务迁移深度强化学习:在传统 DRL 方法中, 每个训练完成后的 agent只能解决单一任务. 然而在一些复杂的现实场景中,需要 agent 能够同时处理多个任务,此时多任务学习和迁移学习就显得异常重要.Wang 等人总结出 RL 中的迁移分为两大类:行为上的迁移和知识上的迁移,这两大类迁移也被广泛应用于多任务 DRL 算法中。
多 agent 深度强化学习:在面对一些真实场景下的复杂决策问题时,单agent 系统的决策能力是远远不够的.例如在拥有多玩家的 Atari 2600 游戏中, 要求多个决策者之间存在相互合作或竞争的关系. 因此在特定的情形下,需要将 DRL 模型扩展为多个 agent 之间相互合作、通信及竞争的多 agent 系统。
基于记忆与推理的深度强化学习:在解决一些高层次的 DRL 任务时, agent 不仅需要很强的感知能力,也需要具备一定的记忆与推理能力,才能学习到有效的决策. 因此赋予现有 DRL 模型主动记忆与推理的能力就显得十分重要。
|引用文章:
刘全,翟建伟,章宗长,钟珊,周倩,章鹏,徐进,深度强化学习综述,2017, Vol.40,在线出版号 No.1
LIU Quan, ZHAI Jian-Wei, ZHANG Zong-Zhang, ZHONG Shan, ZHOU Qian, ZHANG Peng, XU Jin, A Survey on Deep Reinforcement
Learning, 2017,Vol.40,Online Publishing No.1