深度学习训练中为什么要将图片随机剪裁(random crop)
图像分类中,在深度学习的训练时将图片的随机剪裁(random crop)已经成为很普遍的数据扩充(data augmentation)方法,随机剪裁(缩写为:IRC)不但提高了模型精度,也增强了模型稳定性,但是IRC如此有效的核心原因是什么呢?仅仅是因为数据扩充吗?这个是下面我们需要研究的问题。
神经网络的学习(参数估计)本质就是建立输入X与输出Y的统计关系,神经网络的学习问题仍然是统计机器学习问题,而神经网络学习往往需要大量的数据,但是我们用大量的数据学习到的模型是否是稳定的呢?因为神经网络广为诟病的黑箱问题,我们很难用数学原理来推断模型的稳定性(目前模型测试主要还是黑盒测试,顺便,目前业界很不关心模型测试问题,测试太随意,模型的多场景跨分布测试,边界测试,极端条件测试对尤其是自动驾驶等行业的重要性毋庸置疑)。模型是否学到了我们希望的特征呢?比如在人脸识别中,人识别相似但不同的人的方法往往是关注几个重要的脸部器官的差异,脸部轮廓的差异,以及明显的特征点(如:痣、胎记等)。但是在训练神经网络的时候很难告诉他我们关注的特征,让他用我们的方法来学习,神经网络不像人那样,你告诉他某个人脸上的胎记可以很好的辨别这个人,他就知道胎记是关键特征,往往只能给他足够多的数据以便于在统计意义上获得我们希望他关注的特征。但是问题来了,比如
「俄罗斯坦克问题」
这个故事说,美国军方试图训练一台电脑来区分俄罗斯和美国坦克的照片。 它们的分类准确度非常高,但俄罗斯坦克的所有照片都模糊不清,而美国坦克是高清晰度的。该算法不是识别坦克,而是学习区分模糊和清晰的照片。
因子特征分布问题
所以模型训练时会存在这样的问题,即:目的和数据不符合(我们给了模型错误的数据)。 「俄罗斯坦克问题」本质上是一个集合中的概率问题,可以假设训练图片(这里假设每类训练图片数量基本相同)包含因子特征:
俄罗斯坦克 ,美国坦克
,美国坦克
模糊 ,清晰
,清晰
而类别标签,俄罗斯坦克为![]() ,美国坦克为
,美国坦克为![]()
所以俄罗斯坦克的图片为![]() ,美国坦克的图片为
,美国坦克的图片为![]() ;
;
这里存在多映射关系即
![]()
![]()
我们的目的是给定图片 学习![]() 及
及![]() 的映射关系,但是如果模型建立了
的映射关系,但是如果模型建立了![]() ,
,![]() 的映射关系,用以上数据测试仍然显示为正确,但用数据
的映射关系,用以上数据测试仍然显示为正确,但用数据![]() 或
或![]() 测试会发现模型建立了错误的关系。
测试会发现模型建立了错误的关系。
所以为了避免数据与目的不符,需要在数据中加入因子或,即数据变为
俄罗斯坦克的图片为: ![]() ,
,![]() ,
,
美国坦克的图片为: ![]() ,
,![]() ;
;
这个时候当和在每类均匀分布的时候,和被学习器视作为了噪音,即
![]()
所以 ,对分类的信息增益为0,即 ,无预测能力,这时才正确建立了与我们目的相符的映射关系。
因子特征的难易问题
俄罗斯坦克问题还存在另一个问题,即特征难易问题。
这里简单定义特征的难易:以 (其中
(其中 ![]() )的误差正确分类该特征的最小模型容量或函数复杂度(这里特征是高维的,所以分类包含了特征降维过程(特征提取),所以这里的模型容量包含了降维函数的容量,其他可参考VC维及模型容量的概念)
)的误差正确分类该特征的最小模型容量或函数复杂度(这里特征是高维的,所以分类包含了特征降维过程(特征提取),所以这里的模型容量包含了降维函数的容量,其他可参考VC维及模型容量的概念)

所以如上,虽然概率上各特征相同
![]()
![]()
但是模型对特征的偏好不同,模型越简单(在保证分类误差最小的情况下)该模型会更倾向于选择更简单特征(更简单特征的最优模型容量与该模型容量的距离更小)。这里假设区分模糊比区分坦克类型更简单,那么模型将更容易学习到区分模糊和清晰。所以在作训练的时候,目的分类特征越难,越需要保证其他无关特征的分布在类间的均匀。
深度学习训练中为什么要将图片随机剪裁?
这个裁剪并不仅仅是增加数据,而如上文也是一个弱化数据噪声与增加模型稳定性的方法。比如假设:
二类分类问题(如区分人脸与猫脸),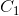 类别主要特征为
类别主要特征为![]() ,
,![]() 为
为![]() ,这里的特征可能是非离散的,如人脸的局部patch(眼睛及周围区域,嘴巴及周围区域,为了容易书写用离散的方式)
,这里的特征可能是非离散的,如人脸的局部patch(眼睛及周围区域,嘴巴及周围区域,为了容易书写用离散的方式)
增加背景数据噪音:,![]() 随机加入
随机加入![]() ,这里同上可以表示为非人(猫)脸背景区域
,这里同上可以表示为非人(猫)脸背景区域
这个时候随机剪裁可以得到图片(这里为了方便,未考虑组合特征对类别的相关关系,即多个局部特征可以组合为全局特征,这时全局特征有关于类别的关联关系,这个关系和其包含的局部特征不同):如
![]() ,
,
![]() ,
,
![]() ,
,
![]()
...
因为 ![]() 为随机的而
为随机的而 ![]() 总是能高概率产生
总是能高概率产生 ![]() 的映射,这时
的映射,这时 ![]() 中任意因子相对于
中任意因子相对于![]() 有更高的信息增益或者权重。即:
有更高的信息增益或者权重。即:
![]()
如果 ![]() 在类别
在类别 ![]() 也有相应的分布,那么
也有相应的分布,那么![]() 对分类的信息增益接近于零。
对分类的信息增益接近于零。
假设模型未见过数据![]() ,那么模型如何预测该数据?通过上式我们可以看到
,那么模型如何预测该数据?通过上式我们可以看到![]() 的权重远高于其他特征,即使其他未见过的噪声加入,
的权重远高于其他特征,即使其他未见过的噪声加入,![]() 因子的权重仍然起主要作用,而个别的因子特征缺失并不会大幅影响模型的预测结果,这个和深度学习中的dropout原理相同,区别是两者的使用方式及dropout更加随机,所以综上模型有更高的稳定性。
因子的权重仍然起主要作用,而个别的因子特征缺失并不会大幅影响模型的预测结果,这个和深度学习中的dropout原理相同,区别是两者的使用方式及dropout更加随机,所以综上模型有更高的稳定性。
随机裁剪相当于建立每个因子特征与相应类别的权重关系,减弱背景(或噪音)因子的权重,且使模型面对缺失值不敏感,也就可以产生更好的学习效果,增加模型稳定性。
2019年3月补充
最近看了 Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet 和本篇文章思想很相似,喜欢的同学可以细读一下。
其他参考:Why do deep convolutional networks generalize so poorly to small image transformations
2019年5月补充
在图片分类任务中,训练获取的特征往往非常多,像神经网络这种黑盒我们无法明确的知道每个因子特征的权重,如在猫、狗分类的任务中,如果存在人眼不敏感的非稳健因子特征 F,假设在训练时类间分布并不均衡,那么特征 F就有大于0的权重,假设 P(Cat|F) > P(Dog|F),如果在部署时我们不断增加Dog类的这个特征F,那么分类器很可能出现对抗攻击问题(Cat的概率变高,将Dog预测为了Cat),这就是下面这篇文章的研究 Adversarial Examples Are Not Bugs, They Are Features
2019年6月补充
Imagenet-Trained Cnns Are Biased Towards Texture Increasing Shape Bias Improves Accuracy And Robustness
这篇文章对比了CNN对shape和texture的偏好问题,描述了使用ImageNet训练CNN会使其具有texture bias,即更喜欢使用纹理特征预测物体类别(或纹理特征有更高的权重); 而Stylized-ImageNet的训练则使CNN有shape bias,即形状偏好,也证明了形状比纹理有更高的预测稳定性,侧面证明人类预测物体的形状偏好是有原因的。使用BagNet的小窗口训练方式会削弱模型对全局形状(特征)的集成能力,即全局形状的预测权重变弱。
如上,ImageNet其实充满了shape和texture的特征,两个特征都有很好的预测能力,而在这个数据上训练的大多数模型都具有texture bias,而更换到Stylized-ImageNet则使CNN有shape bias,充分说明数据的特征分布深刻的影响模型对特征的偏好,这个问题和俄罗斯坦克问题如出一辙。