聊一聊关于Glide在面试中的那些事
1.前言
今天填完离职表,帮着公司面试几个帮着填坑的同行,聊着聊着就聊到了Glide,信誓旦旦的和我说,这块很熟悉,之前在掘金社区里,看过一个叫蓝师傅写的这块的文章,基本细节都掌握。(一副胜利在望的表情,好吧,正巧我也看过,咱们就问一问看的仔细情况)
2. 来简单介绍下Glide的缓存
2.1 分析
(这货滔滔不绝的说了一大通,从LruCache说到了LinkedHashMap,巴拉巴拉。。。个人建议这块一定要简述,面试时原理说的太多,第一很多细节会被打断问到,第二点,说这么多,给人的感觉就是在背诵东西,原理概括能力很弱或者感觉根本就没有自己的体会。)
2.2 答案
Glide的缓存机制,主要分为2种缓存,一种是内存缓存,一种是磁盘缓存。
之所以使用内存缓存的原因是:防止应用重复将图片读入到内存,造成内存资源浪费。
之所以使用磁盘缓存的原因是:防止应用重复的从网络或者其他地方下载和读取数据。
正式因为有着这两种缓存的结合,才构成了Glide极佳的缓存效果。
(先告诉人家有哪几种缓存,主要是为了什么目的才用的缓存,然后可以看着面试官,要么等着他继续问,如果他不问,等着你,这个时候你就可以继续的往细节处介绍)
3. 嗯,具体说一说Glide的三级缓存原理
3.1 分析
(记得,如果需要具体谈原理时,要先宏观,后细节)
3.2 答案
读取一张图片的时候,获取顺序:
Lru算法缓存-》弱引用缓存-》磁盘缓存(如果设置了的话)
当我们的APP中想要加载某张图片时,先去LruCache中寻找图片,如果LruCache中有,则直接取出来使用,并将该图片放入WeakReference中,如果LruCache中没有,则去WeakReference中寻找,如果WeakReference中有,则从WeakReference中取出图片使用,如果WeakReference中也没有图片,则从磁盘缓存/网络中加载图片。
注:图片正在使用时存在于 activeResources 弱引用map中
流程如下图
将图片缓存的时候,写入顺序:
弱引用缓存-》Lru算法缓存-》磁盘缓存中
当图片不存在的时候,先从网络下载图片,然后将图片存入弱引用中,glide会采用一个acquired(int)变量用来记录图片被引用的次数,
当acquired变量大于0的时候,说明图片正在使用中,也就是将图片放到弱引用缓存当中;
如果acquired变量等于0了,说明图片已经不再被使用了,那么此时会调用方法来释放资源,首先会将缓存图片从弱引用中移除,然后再将它put到LruResourceCache当中。
这样也就实现了正在使用中的图片使用弱引用来进行缓存,不在使用中的图片使用LruCache来进行缓存的功能。
引深:
关于LruCache
最近最少使用算法,设定一个缓存大小,当缓存达到这个大小之后,会将最老的数据移除,避免图片占用内存过大导致OOM。
LruCache 内部用LinkHashMap存取数据,在双向链表保证数据新旧顺序的前提下,设置一个最大内存,往里面put数据的时候,当数据达到最大内存的时候,将最老的数据移除掉,保证内存不超过设定的最大值。
关于LinkedHashMap
LinkHashMap 继承HashMap,在 HashMap的基础上,新增了双向链表结构,每次访问数据的时候,会更新被访问的数据的链表指针,具体就是先在链表中删除该节点,然后添加到链表头header之前,这样就保证了链表头header节点之前的数据都是最近访问的(从链表中删除并不是真的删除数据,只是移动链表指针,数据本身在map中的位置是不变的)
4. Glide加载一个一兆的图片(100 * 100),是否会压缩后再加载,放到一个300 * 300的view上会怎样,800*800呢,图片会很模糊,怎么处理?
4.1 分析
(因为你缓存机制无论是看博客还是看一些面试宝典,如果只是考原理或者定义,光把上面的文字背诵下来就可以了,但是背诵和真正的理解是两回事,自己没有形成感悟,不理解这个框架,只是一味的迎合面试,这个问题就可以卡住你,另外千万别和面试官嘚瑟,果然,这个面试的哥们,这块就卡住了,支支吾吾的半天没答上来,果然是只看了博客,没真正的阅读过源码)
4.2 答案
当我们调整imageview的大小时,Picasso会不管imageview大小是什么,总是直接缓存整张图片,而Glide就不一样了,它会为每个不同尺寸的Imageview缓存一张图片,也就是说不管你的这张图片有没有加载过,只要imageview的尺寸不一样,那么Glide就会重新加载一次,这时候,它会在加载的imageview之前从网络上重新下载,然后再缓存。
举个例子,如果一个页面的imageview是300 * 300像素,而另一个页面中的imageview是100 * 100像素,这时候想要让两个imageview像是同一张图片,那么Glide需要下载两次图片,并且缓存两张图片。
public <R> LoadStatus load() {
// 根据请求参数得到缓存的键
EngineKey key = keyFactory.buildKey(model, signature, width, height, transformations,
resourceClass, transcodeClass, options);
}
看到了吧,缓存Key的生成条件之一就是控件的长宽。
5. 简单说一下内存泄漏的场景,如果在一个页面中使用Glide加载了一张图片,图片正在获取中,如果突然关闭页面,这个页面会造成内存泄漏吗?
5.1 分析
(注意一定要审题,因为之前问了这个小伙,内存泄漏的原因,无非是长生命周期引用了短生命周期的对象等等,然后突然画风一变,直接问了Glide加载图片会不会引起图片泄漏,这个小伙想也没想,直接回答道会引起内存泄漏,可以用LeakCanary检测,巴拉巴拉。。。)
5.2 答案
因为Glide 在加载资源的时候,如果是在 Activity、Fragment 这一类有生命周期的组件上进行的话,会创建一个透明的 RequestManagerFragment 加入到FragmentManager 之中,感知生命周期,当 Activity、Fragment 等组件进入不可见,或者已经销毁的时候,Glide 会停止加载资源。
但是如果,是在非生命周期的组件上进行时,会采用Application 的生命周期贯穿整个应用,所以 applicationManager 只有在应用程序关闭的时候终止加载。
6.如何设计一个大图加载框架
6.1 分析
(这个孩子,总算是羞愧的低下了头,一脸懵逼的和我说,这个我忘记了)
6.2 答案
概括来说,图片加载包含封装,解析,下载,解码,变换,缓存,显示等操作。
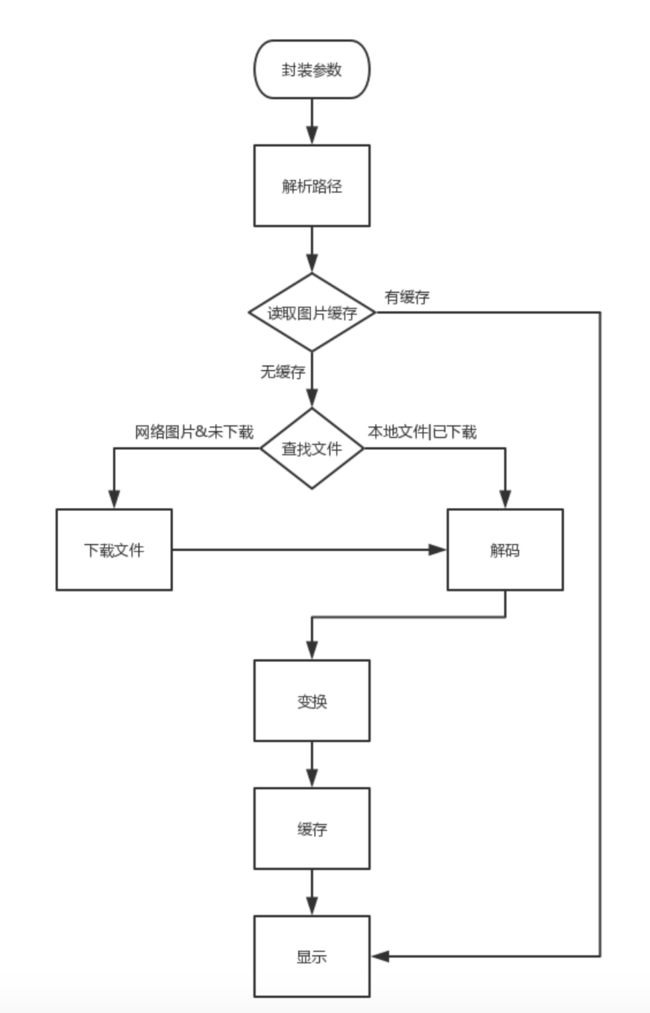
- 封装参数:从指定来源,到输出结果,中间可能经历很多流程,所以第一件事就是封装参数,这些参数会贯穿整个过程;
- 解析路径:图片的来源有多种,格式也不尽相同,需要规范化;
- 读取缓存:为了减少计算,通常都会做缓存;同样的请求,从缓存中取图片(Bitmap)即可;
- 查找文件/下载文件:如果是本地的文件,直接解码即可;如果是网络图片,需要先下载;
- 解码:这一步是整个过程中最复杂的步骤之一,有不少细节,下个博客会说;
- 变换:解码出Bitmap之后,可能还需要做一些变换处理(圆角,滤镜等);
- 缓存:得到最终bitmap之后,可以缓存起来,以便下次请求时直接取结果;
- 显示:显示结果,可能需要做些动画(淡入动画,crossFade等)。
END
先写到这,基本上问的也就这么多了,要是再细扣,感觉有些故意为难了,面试的一般都是在30分钟以内,感觉对方会的,我会跳过,因为你会了,我就没必要问了,浪费时间,感觉不会的,问道你说出不会或者不清楚为止,我也不会再在这方面细扣,原因也是一样,浪费时间。主要是发现每个人的长处,及对待事情的态度。
另外其实吧,不一定都答的上来才会要你,也不是因为答不上来就不要你,主要吧,还是靠感觉,好相处,人又不是太滑,性格nice,给人踏实的感觉的,都会网开一面的。
下期我会仿照着Glide自己仿照一个,将Glide的主流程所涉及的,都会加上,这样方便大家的理解。有兴趣的可以关注我。
还是那句话
虽然更新时间没准,快则半天,慢则半年,但是每一篇文章,我都深入浅出,要么丰富的流程图,一看就懂,要么就是一步一步仿照着写,学习框架原理还是那句话,先搞清楚为什么要这么设计,可不可以不这么写或者不加这个功能,根据情境分析,然后再去解读这块源码逻辑,这样才会记的牢固