scrapy框架爬取建设行业数据实例(思路整理)
最近挤了点时间,写了个爬虫,可能以后工作中能用得上。关于scrapy框架的一些基础知识这里就不再赘述,这里主要记录下开发思路。
关于项目背景:
http://jst.sc.gov.cn/xxgx/Enterprise/eList.aspx从这个网站中查询建筑企业,并且爬取每个企业的基本信息,资质证书和注册人员信息。
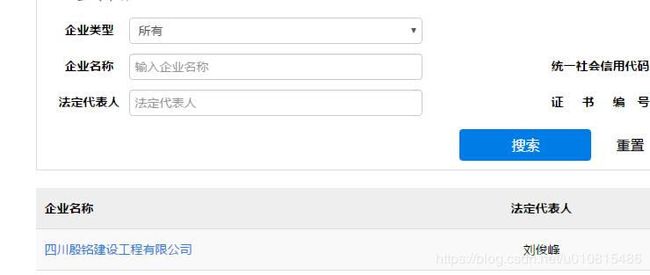
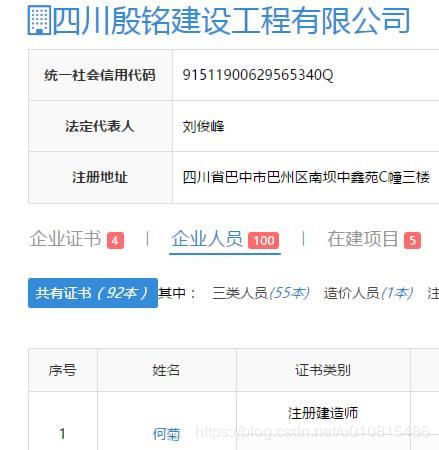
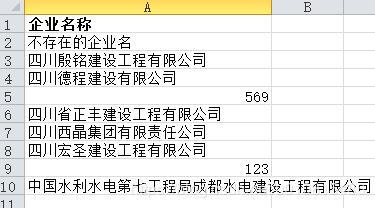
首先分析目标网站,要查询到每个企业的详细信息,需要获取到企业id,先写个爬虫获取企业id并导出到id表格中:
class ElistSpider(scrapy.Spider):
name = 'eList'
allowed_domains = ['http://jst.sc.gov.cn/xxgx/Enterprise/eList.aspx']
f_1Sheet1 = None
f_1_count = None
# 设置浏览器用户代理
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'}
def start_requests(self):
# 读取企业名称excel
f_1 = xlrd.open_workbook(r'企业名称.xlsx')
self.f_1Sheet1 = f_1.sheet_by_index(0)
# 表里的数据量(数据行数)
self.f_1_count = self.f_1Sheet1.nrows
# 第一次请求页面,设置开启cookie使其得到cookie,设置回调函数
return [Request('http://jst.sc.gov.cn/xxgx/Enterprise/eList.aspx', meta={'cookiejar': 1}, callback=self.parse)]
def parse(self, response):
__VIEWSTATE = response.css('#__VIEWSTATE::attr(value)').extract()[0]
__VIEWSTATEGENERATOR = response.css(
'#__VIEWSTATEGENERATOR::attr(value)').extract()[0]
__EVENTVALIDATION = response.css(
'#__EVENTVALIDATION::attr(value)').extract()[0]
# print(__VIEWSTATE)
# print(__VIEWSTATEGENERATOR)
# print(__EVENTVALIDATION)
# 设置提交表单信息,对应抓包得到字段
for i in range(1, self.f_1_count):
rows = self.f_1Sheet1.row_values(i) # 获取行内容
form_data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'__EVENTVALIDATION': __EVENTVALIDATION,
'qylx': '',
'mc': str(rows[0]),
'xydm': '',
'fr': '',
'zsbh': '',
'ctl00$MainContent$Button1': '搜索'
}
# 第二次用表单post请求,携带Cookie、浏览器代理等信息给Cookie授权
yield FormRequest(response.url, meta={'cookiejar': response.meta['cookiejar']}, headers=self.header, formdata=form_data, callback=self.next, dont_filter=True)
def next(self, response):
items = ElistItem()
name_id = response.css('.search-result tr td a::attr(href)')
if name_id:
items['name_id'] = name_id.extract()[0]
yield items从企业名单表中读取企业名称,事先抓包一下请求地址和字段,模拟表单提交,爬取企业id。需要注意的是,网站是用asp.net框架开发的,表单提交的一些字段需要从页面获取:

有了企业id,就可以为所欲为了~接下来写个爬虫,爬取企业的基本信息:
class EzsxxSpider(scrapy.Spider):
name = 'eZsxx'
f_1Sheet1 = None
f_1_count = None
url = []
# 设置浏览器用户代理
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'}
def start_requests(self):
# 读取企业id
try:
f_1 = xlrd.open_workbook(r'name_id.xls')
self.f_1Sheet1 = f_1.sheet_by_index(0)
# 表里的数据量(数据行数)
self.f_1_count = self.f_1Sheet1.nrows
link = 'http://jst.sc.gov.cn/xxgx/Enterprise/eZsxx.aspx?'
for i in range(0, self.f_1_count):
name_id = self.f_1Sheet1.row_values(i)[0]
name_url = link + name_id.split('?')[1]
self.url.append(name_url)
except IOError:
print('name_id.xls文件不存在')
return False
# 第一次请求页面,设置开启cookie使其得到cookie,设置回调函数
return [Request(self.url[0], meta={'cookiejar': 1}, callback=self.parse)]
def parse(self, response):
items = EzsxxItem()
company_name = response.css('.user_info b::text').extract()[0]
company_content = response.css('.datas_table tr')
_company_code = company_content[0].css('th+td::text').extract()
if len(_company_code) >= 1:
company_code = _company_code[0]
else:
company_code = ''
_area = company_content[0].css('th+td::text').extract()
if len(_area) == 2:
area = _area[1]
else:
area = ''
_boss_name = company_content[1].css('th+td::text').extract()
if len(_boss_name) >= 1:
boss_name = _boss_name[0]
else:
boss_name = ''
_company_type = company_content[1].css('th+td::text').extract()
if len(_company_type) == 2:
company_type = _company_type[1]
else:
company_type = ''
_address = company_content[2].css('th+td::text').extract()
if len(_address) >= 1:
address = _address[0]
else:
address = ''
items['company_name'] = company_name
items['company_code'] = company_code
items['area'] = area
items['boss_name'] = boss_name
items['company_type'] = company_type
items['address'] = address
yield items
self.url.pop(0)
if self.url:
yield Request(self.url[0], meta={'cookiejar': 1}, callback=self.parse)把企业id存入数组,递归调用爬虫parse方法,爬取数据:

爬取企业注册人员有点麻烦,涉及到一个翻页提交;先抓包一下请求字段,然后递归调用爬虫parse方法:
class EryxxSpider(scrapy.Spider):
name = 'eRyxx'
f_1Sheet1 = None
f_1_count = None
url = []
# 设置浏览器用户代理
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'}
def start_requests(self):
# 读取企业id
try:
f_1 = xlrd.open_workbook(r'name_id.xls')
self.f_1Sheet1 = f_1.sheet_by_index(0)
# 表里的数据量(数据行数)
self.f_1_count = self.f_1Sheet1.nrows
link = 'http://jst.sc.gov.cn/xxgx/Enterprise/eRyxx.aspx?isRc=0&'
for i in range(0, self.f_1_count):
name_id = self.f_1Sheet1.row_values(i)[0]
name_url = link + name_id.split('?')[1]
self.url.append(name_url)
except IOError:
print('name_id.xls文件不存在')
return False
# 第一次请求页面,设置开启cookie使其得到cookie,设置回调函数
return [Request(self.url[0], meta={'cookiejar': 1}, callback=self.parse)]
def parse(self, response):
items = EryxxItem()
company_name = response.css('.user_info b::text').extract()[0]
# print(company_name)
man_data = response.css('#catabled tr')
man_data.pop(0)
for i in man_data:
man_name = i.css('#tb__1_6 a::text').extract()
category = i.css('#tb__1_1::text').extract()
certificate_num = i.css('#tb__1_2::text').extract()
start_date = i.css('#tb__1_3::text').extract()
end_date = i.css('#tb__1_4 span::text').extract()
agencies = i.css('#tb__1_5::text').extract()
items['company_name'] = company_name
items['man_name'] = man_name
items['category'] = category
items['certificate_num'] = certificate_num
items['start_date'] = start_date
items['end_date'] = end_date
items['agencies'] = agencies
yield items
pnum = response.css(
'#MainContent_gvPager td a:nth-last-of-type(2)::attr(href)')
if pnum:
next_page = pnum.extract()[0]
page = next_page.split(',')[1].replace("'", "").replace(")", "")
else:
page = ''
__VIEWSTATE = response.css('#__VIEWSTATE::attr(value)').extract()[0]
__VIEWSTATEGENERATOR = response.css(
'#__VIEWSTATEGENERATOR::attr(value)').extract()[0]
__EVENTVALIDATION = response.css(
'#__EVENTVALIDATION::attr(value)').extract()[0]
form_data = {
'__VIEWSTATE': __VIEWSTATE,
'__VIEWSTATEGENERATOR': __VIEWSTATEGENERATOR,
'__EVENTTARGET': 'ctl00$MainContent$gvPager',
'__EVENTARGUMENT': str(page),
'__EVENTVALIDATION': __EVENTVALIDATION,
'ctl00$MainContent$hidZSLX': '',
'ctl00$MainContent$ryname': '',
'ctl00$MainContent$ryzsh': '',
'ctl00$MainContent$cxtj': ''
}
if page is not None and page != '':
print(response.url)
yield FormRequest(response.url, formdata=form_data, meta={'cookiejar': response.meta['cookiejar']}, headers=self.header, callback=self.parse, dont_filter=True)
else:
self.url.pop(0)
if self.url:
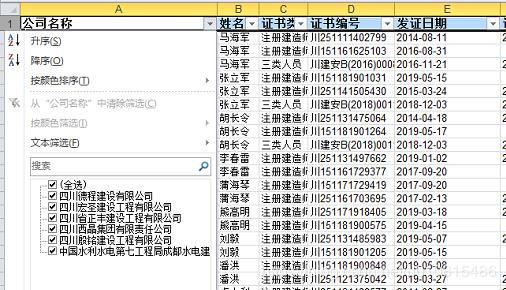
yield Request(self.url[0], meta={'cookiejar': 1}, callback=self.parse)6家测试企业的全部注册人员爬取结果:
继续爬取企业的资质证书,这个情况有点特殊,数据不在页面上:

抓一下请求的接口,直接获取json数据对象:
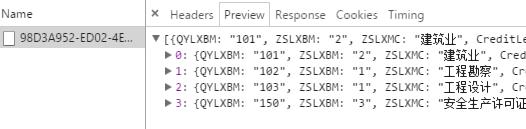
class ZslistSpider(scrapy.Spider):
name = 'ZsList'
f_1Sheet1 = None
f_1_count = None
zz_url = []
# 设置浏览器用户代理
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'}
def start_requests(self):
# 读取企业id
try:
f_1 = xlrd.open_workbook(r'name_id.xls')
self.f_1Sheet1 = f_1.sheet_by_index(0)
# 表里的数据量(数据行数)
self.f_1_count = self.f_1Sheet1.nrows
zz_link = 'http://jst.sc.gov.cn/xxgx/api/getdata/GetEnteZsList/'
for i in range(0, self.f_1_count):
name_id = self.f_1Sheet1.row_values(i)[0]
zz = zz_link + name_id.split('?')[1].replace("id=", "")
self.zz_url.append(zz)
except IOError:
print('name_id.xls文件不存在')
return False
# 第一次请求页面,设置开启cookie使其得到cookie,设置回调函数
return [Request(self.zz_url[0], meta={'cookiejar': 1}, callback=self.parse)]
def parse(self, response):
items = ZsListItem()
js_data = json.loads(response.body)
for i in js_data:
for zsDetial in i['zsDetial']:
items['company_name'] = zsDetial['QYMC']
items['zz_class'] = zsDetial['ZSLXMC']
items['zz_num'] = zsDetial['ZSBH']
items['zz_date'] = zsDetial['YXJSRQ']
items['agencies'] = zsDetial['BFBM']
items['zz_name'] = zsDetial['ZZX']
yield items
self.zz_url.pop(0)
if self.zz_url:
yield Request(self.zz_url[0], meta={'cookiejar': 1}, callback=self.parse)爬取结果:
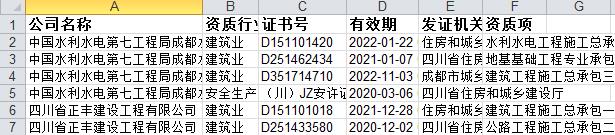
最后贴一下4个爬虫的Pipeline:
class NameIdPipeline(object):
def open_spider(self, spider):
if spider.name == 'eList':
self.f = xlwt.Workbook()
self.sheet1 = self.f.add_sheet(u'sheet1', cell_overwrite_ok=True)
self.f.save('name_id.xls')
print("开始输出企业id")
def process_item(self, item, spider):
if spider.name == 'eList':
data = xlrd.open_workbook('name_id.xls') # 打开Excel文件
table = data.sheets()[0] # 通过索引顺序获取table,因为初始化时只创建了一个table,因此索引值为0
rowCount = table.nrows # 获取行数,下次从这一行开始
self.sheet1.write(rowCount, 0, item['name_id']) # 写入数据到execl中
self.f.save('name_id.xls')
return item
def close_spider(self, spider):
if spider.name == 'eList':
self.f.save('name_id.xls')
print("结束输出企业id")
class ManDataPipeline(object):
def open_spider(self, spider):
if spider.name == 'eRyxx':
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
self.f = xlwt.Workbook()
self.sheet1 = self.f.add_sheet(u'sheet1', cell_overwrite_ok=True)
row0 = [u'公司名称 ', u'姓名', u'证书类别',
u'证书编号', u'发证日期', u'证书有效期', u'发证机关']
for i in range(0, len(row0)):
self.sheet1.write(0, i, row0[i], set_style(
'Times New Roman', 220, True))
self.f.save('man_data.xls')
print("开始输出企业人员")
def process_item(self, item, spider):
if spider.name == 'eRyxx':
data = xlrd.open_workbook('man_data.xls') # 打开Excel文件
table = data.sheets()[0] # 通过索引顺序获取table,因为初始化时只创建了一个table,因此索引值为0
rowCount = table.nrows # 获取行数,下次从这一行开始
self.sheet1.write(rowCount, 0, item['company_name']) # 写入数据到execl中
self.sheet1.write(rowCount, 1, item['man_name'])
self.sheet1.write(rowCount, 2, item['category'])
self.sheet1.write(rowCount, 3, item['certificate_num'])
self.sheet1.write(rowCount, 4, item['start_date'])
if item['end_date'][0] == '2250-12-31':
self.sheet1.write(rowCount, 5, '')
else:
self.sheet1.write(rowCount, 5, item['end_date'])
self.sheet1.write(rowCount, 6, item['agencies'])
self.f.save('man_data.xls')
return item
def close_spider(self, spider):
if spider.name == 'eRyxx':
self.f.save('man_data.xls')
print("结束输出企业人员")
class CompanyDataPipeline(object):
def open_spider(self, spider):
if spider.name == 'eZsxx':
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
self.f = xlwt.Workbook()
self.sheet1 = self.f.add_sheet(u'sheet1', cell_overwrite_ok=True)
row0 = [u'公司名称 ', u'社会信用代码', u'所属地区', u'法定代表人', u'登记注册类型', u'注册地址']
for i in range(0, len(row0)):
self.sheet1.write(0, i, row0[i], set_style(
'Times New Roman', 220, True))
self.f.save('company_data.xls')
print("开始输出企业信息")
def process_item(self, item, spider):
if spider.name == 'eZsxx':
data = xlrd.open_workbook('company_data.xls') # 打开Excel文件
table = data.sheets()[0] # 通过索引顺序获取table,因为初始化时只创建了一个table,因此索引值为0
rowCount = table.nrows # 获取行数,下次从这一行开始
self.sheet1.write(rowCount, 0, item['company_name']) # 写入数据到execl中
self.sheet1.write(rowCount, 1, item['company_code'])
self.sheet1.write(rowCount, 2, item['area'])
self.sheet1.write(rowCount, 3, item['boss_name'])
self.sheet1.write(rowCount, 4, item['company_type'])
self.sheet1.write(rowCount, 5, item['address'])
self.f.save('company_data.xls')
return item
def close_spider(self, spider):
if spider.name == 'eZsxx':
self.f.save('company_data.xls')
print("结束输出企业信息")
class CompanyZzPipeline(object):
def open_spider(self, spider):
if spider.name == 'ZsList':
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style
self.f = xlwt.Workbook()
self.sheet1 = self.f.add_sheet(u'sheet1', cell_overwrite_ok=True)
row0 = [u'公司名称 ', u'资质行业', u'证书号', u'有效期', u'发证机关', u'资质项']
for i in range(0, len(row0)):
self.sheet1.write(0, i, row0[i], set_style(
'Times New Roman', 220, True))
self.f.save('company_zz.xls')
print("开始输出企业资质")
def process_item(self, item, spider):
if spider.name == 'ZsList':
data = xlrd.open_workbook('company_zz.xls') # 打开Excel文件
table = data.sheets()[0] # 通过索引顺序获取table,因为初始化时只创建了一个table,因此索引值为0
rowCount = table.nrows # 获取行数,下次从这一行开始
self.sheet1.write(rowCount, 0, item['company_name'])
self.sheet1.write(rowCount, 1, item['zz_class'])
self.sheet1.write(rowCount, 2, item['zz_num'])
self.sheet1.write(rowCount, 3, item['zz_date'])
self.sheet1.write(rowCount, 4, item['agencies'])
self.sheet1.write(rowCount, 5, item['zz_name'])
self.f.save('company_zz.xls')
return item
def close_spider(self, spider):
if spider.name == 'ZsList':
self.f.save('company_zz.xls')
print("结束输出企业资质")