环境
安装环境
| 环境 | 配置 |
|---|---|
| Linux | Centos6.5 |
| Java | JDK1.8 |
| Hadoop | Hadoop 2.7.3 |
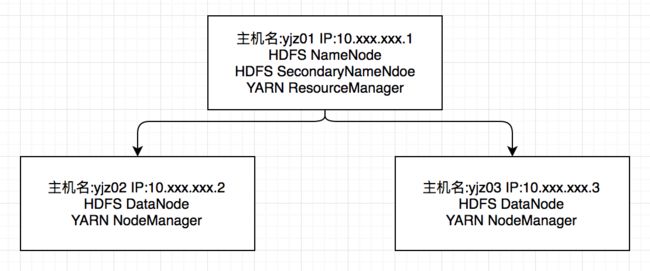
节点配置
创建用户组
groupadd hadoop
useradd hadoop -g hadoop
JDK安装
需要提前安装好jdk,jdk版本参考:
https://wiki.apache.org/hadoop/HadoopJavaVersions
ssh免密码登陆
分别在三台机器生成ssh公钥和私钥
ssh-keygen -t rsa
将三台机器的公钥放到authorized_keys
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
ssh [email protected] ~/.ssh/id_rsa.pub >> authorized_keys
ssh [email protected] ~/.ssh/id_rsa.pub >> authorized_keys
这两步需要输入对应机器的hadoop账户密码,因为此时还没有无密码免登录。
将authorized_keys拷贝到另外两台机器:
scp authorized_keys [email protected]:~/.ssh/
scp authorized_keys [email protected]:~/.ssh/
这样可以直接登录另外两台机器,而不需要密码了。
注意:如果这时仍然需要输入密码,那有可能是authorized_keys权限问题,将其改为600即可。
chmod 600 authorized_keys
Hadoop安装
下载hadoop镜像文件
http://hadoop.apache.org/releases.html
解压缩
tar -zxvf hadoop-2.7.3.tar.gz
配置hadoop配置文件
hadoop的配置文件都在${HADOOP_HOME}/etc/hadoop/下面。
配置hadoop-env.sh
修改JDK安装目录
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/opt/xxx/java/jdk1.8.0_111/
配置slaves文件
在slaves文件中添加所有从节点的IP
10.xxx.xxx.2
10.xxx.xxx.3
配置core-site.xml
fs.defaultFS
hdfs://10.xxx.xxx.1:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/home/hadoop/hadoop/tmp
配置hdfs-site.xml
dfs.namenode.secondary.http-address
http://10.xxx.xxx.1:50090
dfs.replication
2
dfs.namenode.name.dir
file:/home/hadoop/hadoop/hdfs/name
dfs.datanode.name.dir
file:/home/hadoop/hadoop/hdfs/data
dfs.bocksize
134217728
配置mapred-site.xml
mapred-site.xml没有提供,而是提供了其模版mapred-siter.xml.template,我们需要复制一个
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
http://10.xxx.xxx.1:10020
mapreduce.jobhistory.webapp.address
http://10.xxx.xxx.1:19888
配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
http://10.xxx.xxx.1:8032
yarn.resourcemanager.scheduler.address
http://10.xxx.xxx.1:8030
yarn.resourcemanager.resource-tracker.address
http://10.xxx.xxx.1:8031
yarn.resourcemanager.admin.address
http://10.xxx.xxx.1:8033
需要注意的是不能有以下配置:
yarn.resourcemanager.webapp.address
http://10.xxx.xxx.1:8088
否则ResourceManeger启动不起来,之后看下为什么?
分发节点
将配置配置好的hadoop复制到其它节点:
scp -r hadoop-2.7.3 [email protected]:/home/hadoop/
scp -r hadoop-2.7.3 [email protected]:/home/hadoop/
格式化NameNode
bin/hdfs namenode -format
....
17/03/27 18:11:29 INFO common.Storage: Storage directory /home/hadoop/hadoop/hdfs/name has been successfully formatted.
......
启动hdfs和yarn
sbin/start-hdfs.sh
sbin/start-yarn.sh
web查看NameNode
http://10.xxx.xxx.1:50070
web查看ResourceManager
http://10.xxx.xxx.1:8080/cluster
注意:如果报了下面这个问题,应该是你的/etc/hosts下面并没有slave 的ip地址,将slave的地址填上即可。
2017-05-31 04:08:54,915 INFO org.apache.hadoop.hdfs.server.datanode.DataNode: Block pool BP-1212305280-172.26.3.61-1496217355761 (Datanode Uuid null) service to /10.5.234.238:9000 beginning handshake with NN
2017-05-31 04:08:54,929 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool BP-1212305280-172.26.3.61-1496217355761 (Datanode Uuid null) service to /10.5.234.238:9000 Datanode denied communication with namenode because hostname cannot be resolved (ip=10.5.237.131, hostname=10.5.237.131): DatanodeRegistration(0.0.0.0:50010, datanodeUuid=62026f56-a10d-4ddc-962c-48eaff24a8a2, infoPort=50075, infoSecurePort=0, ipcPort=50020, storageInfo=lv=-56;cid=CID-d7717928-6909-4dc8-bbfd-dea4d6d509db;nsid=1819736668;c=0)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:873)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:4529)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:1286)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:96)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:28752)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:616)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:982)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2049)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2045)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2043)
这里只是集群的基础配置,后续会跟进各种配置。
关注我
欢迎关注我的公众号,会定期推送优质技术文章,让我们一起进步、一起成长!
公众号搜索:data_tc
或直接扫码:

欢迎关注我