【ICCV2015】Holistically-Nested Edge Detection论文阅读笔记
一、作者

二、方法概括
本文提出一种新的边缘检测算法HED(holistically-nested edge detection),有两个特点:
1整图进行训练和预测;
2多尺度多层次特征学习。
利用全卷积网络(FCN)和deeply-supervised nets(DSN),自动学习丰富的层次化表达。在BSD500(0.782)和NYU Depth(0.746)数据集达到state-of-the-art,速度达到每幅图400ms。
github源码:https://github.com/s9xie/hed,公开训练好的模型,已经train/test code,可在caffe上使用。
三、创新点和贡献
holistic表示边缘预测的结果是基于image-to-image(端到端)的过程,neted表示在生成的输出过程中不断地继承和学习,从而得到边缘预测图(edge maps)的过程,这里使用多尺度的方法学习特征。(其意义是能够产生不同scale的轮廓线。该网络基于VGG,有五层不同level的轮廓线输出。)
因为希望显示每个预测的路径对于每个edge maps是通用的,可使连续边缘maps更加简洁,不像canny有很多不连续边缘。
本算法有两个贡献:
1.整体图像的训练和预测,使用FCN网络,输入原图,直接输出edge map图像;
2.嵌套多尺度特征学习,通过deeply-supervised nets[34],执行深层监督去指引早期分类结果;

四、相关方法
边缘检测关键点:
- 提取的特征;
- 多尺度融合;
- 不同level视觉感知的运用;
- 合并结构信息(输入与输出的内在联系)和内容;
- 实现整体图像的预测;
- 开拓3D几何学;
- 寻找封闭的边界;
一些基于CNN的方法,掌握1-3的关键点,但是缺乏deep supervision,隐藏层产生多尺度响应,缺少有意义的语义信息。而且patch-to-pixel或者patch-to-path策略导致准确性下降。
本系统是端到端的,使用FCN网络,还在修正的VGG网络顶端中增加deep supervision。如果缺少deep supervision和side outputs,FCN输出结果不佳。因为边缘检测要求非常准确的像素级定位。本系统的高准确度得益于:
- 基于FCN的image-to-image训练允许同时训练大量样本[table4];
- deep supervision指导学习更多易懂的特征[table2];
- 端到端学习的side outputs的插值鼓励每层进行相互耦合的贡献[table3];
作者通过几种不同的多尺度深度学习下的结构进行对比说明。在多尺度方面,有内部网络形成的多尺度,和外部网络形成的多尺度。前者是神经网络里不同层由于降采样的不同得到的不同尺度特征,结合形成多尺度,后者是通过对输入图像的尺度处理时的多尺度,获得不同尺度信息。作者将具体多尺度下的深度学习分为四种,如下图。

- Multi-stream learning:不同的参数个数和感受野尺寸,输入同时进入多流,然后concatenate特征,进入全局输出层。
- Skip-layer network learning:以基本流为中心,不同level去incorporate特征,结合进入共享输出层。
这里(a)和(b)都是使用一个输出的loss函数进行单一的回归预测,而边缘检测可能通过多个回归预测得到结合的边缘图效果更好。
- Single model on multiple inputs:单一网络,多尺度输入,图像resize得到多尺度输入,该方法在train和test过程均可加入。
- Training independent networks:从a)演化而来,通过多个独立网络分别对不同深度和输出loss进行多尺度预测,不同输出loss层。训练需很多资源,训练样本量很大。
- Holistically-nested networks:本文提出的算法结构,从d)演化而来,类似一个相互独立的多网络多尺度预测系统,但是将multiple side outputs组合成一个单一深度网络。包含单一流网络,多面输出。集成deeply-supervised net工作,其隐藏层监督可以改善图像分类性能和鲁棒性。多面输出使增加额外融合层更加灵活。
五、公式说明
- 训练阶段:
groundtruth是输入图像的二值边缘图,取值0或1。X是输入图像,Y是gt。定义所有标准网络层参数集合为W,假设网络有M个side-output层,每个side-output层关联一个分类器,对应权重:![]() 目标函数为:
目标函数为:

定义ℓside为图像层级的side-output层的loss方程。在我们的图像端到端的训练中,使用训练图像X的所有像素和二值图gt计算loss方程。
对于一个标准的场景图像,一般90%都是非边缘像素。【19】提出一个对cost敏感的loss方程。本文使用一个简单的策略自动平衡正负样本之间的loss,在逐像素上引入类间平衡权重β。索引j是图像X的空间维度,然后使用类间平衡权重去简单的抵消边缘/非边缘之间的不平衡。特别地,定义如下类间平衡的cross-entropy loss方程:

(参考https://blog.csdn.net/majinlei121/article/details/78884531进行理解)
其中,β = |Y−|/|Y | , 1 − β = |Y+|/|Y |。|Y−|和|Y+|表示边缘和非边缘的gt标注集合。
![]() 是像素j的sigmoid响应值。在每个side output层,然后获取边缘预测图edge map预测
是像素j的sigmoid响应值。在每个side output层,然后获取边缘预测图edge map预测![]() ,
,![]()
![]()
![]() 是m层side-output的响应。
是m层side-output的响应。
为了直接利用side-output预测,我们在网络中添加权重融合层,同时在训练时学习融合权重。我们的融合层Lfuse的loss方程为:
![]()
其中![]() ,其中
,其中![]()
![]() 是融合权重。Dist(·, ·)是融合预测值和gt label map的距离,我们将这个设为cross-entropy的loss。
是融合权重。Dist(·, ·)是融合预测值和gt label map的距离,我们将这个设为cross-entropy的loss。
通过以上计算,我们可以通过标准(反馈传播)随机梯度下降方法来最小化目标方程:

实验部分有超参数和实验设置的细节说明。
- 测试阶段:
通过测试,制定X图像,我们可以通过side output layers和weighted-fusion layer获得边缘预测图edge map predictions:
![]()
CNN(·)表示我们的网络生成的edge maps。最终标准输出集合了这些edge maps。详细细节在实验结果章节说明。
![]()
六、网络结构

本文的网络结构如上图所示,误差反向传播路径高亮显示。Side-output层跟在卷积层后。Deep supervision应用在每个side-output层,指导side-outputs获取特征进行边缘预测。HED的输出是多尺度和多层次的,side-output平面尺寸逐渐变小,感受野尺寸逐渐变大。并加入了一个权重融合层去自动学习多尺度输出的结合,即训练一个权重融合函数得到最终的边缘输出。整个网络在训练时用多种误差反馈路径(点线)。
这个图非常形象,在卷积层后面侧边插入一个输出层 side-output 层,在side-output层上进行deep supervision,使得结果向着边缘检测方向进行。同时随着side-output层越向后大小的变小,将receptive field变大,最后通过一个weighted-fusion layer得到多尺度下的输出。
本文目标是创建深度网络去高效的获得多level的特征,并在不同步长的各阶段获取edge map的内在尺度。VGGNet在ImageNet获得state-of-the-art性能,有16卷积层,较大密度(步长1的卷积核)。[2]也证明在通用图像分类任务上fine-tuning预训练的DNN有益于low-level的边缘检测任务。因此我们使用VGGNet结构,并做了改进:
- 在每个阶段最后的卷积层连接我们的side output层,分别为conv1_2, conv2_2, conv3_3, conv4_3,conv5_3,每个卷积层的感受野与对应的side output层相同;
- 切去了VGGNet的最后一个阶段,包括第5个pooling层和所有全连接层。因为第5个pooling层后输出尺寸太小,而全连接层计算量太大,太耗时。
HED网络有5个阶段,stride分别为1,2,4,8,16,具有不同感受野尺寸,所有都内嵌在VGGNet。

使用weighted-fusion输出层连接每个side-output层,输出层参数可以通过 weighted-fusion层error传播路径的反向传播来更新。deep supervision对于获取期望的edge maps非常重要。本文网络的典型关键点在于,每个网络层都作为一个单独的网络在特定尺度生产edge map。本文观察到,配合deep supervision,nested side-outputs能够使edge map预测逐渐coarse-to-fine,local-to-global。
七、实现细节
使用caffe库,建立在公开平台FCN[26]和DSN[23]基础上,因此工程量较小。整个网络在预训练的VGG-16模型上fine-tune。
- 模型参数:
相比将CNN用于图像分类或语义分割,低层次的边缘检测需要更加留意。数据分布、gt分布,loss方程均造成网络收敛的困难,即使模型是有预训练的。
首先,使用验证集和[6]的评价策略来微调该深度模型的超参数。超参数包括:
- mini-batch size:10
- learning rate:1e-6
- 每个side-output层的loss-weight
 :1
:1 - momentum:0.9
- nested filters的初始化:0
- 融合层权重的初始化:1/5
- weight decay:0.0002
- 训练迭代数:10000(divide learning rate by 10 after 5,000)
我们观察到不论训练是否收敛,验证集的F值偏差都很小。为了调查是否包含额外非线性的帮助,我们也考虑到在每个side-output层前添加一个额外的层,包含50个滤波器和一个ReLU,但这使性能变差。另外,发现nested多尺度框架对输入图像尺度不敏感。在训练过程,我们将所有图像缩放到400*400,以便降低GPU的内存和高效并行处理。
- 共识抽样:
本方法在每个side-output层复制gt,并resize side output到原始尺度。因此,high-level的side-output有mismatch,预测的边缘是粗略的和全局的,同时gt仍然包含很多弱边缘,甚至可被看做噪声。即使模型经过预训练,这也会造成不收敛和梯度爆炸。因此,在BSDS数据集,我们将ground truth的弱边缘移除(少于三人标记)。
- 数据扩增:
data augmentation在深度网络中被证明非常关键。我们旋转图像到16个不同角度,切割最大矩形,并进行左右翻转,得到增大32倍的训练集。测试时,原图保持原有尺寸,因为实验显示将test image进行旋转和翻转,并将预测值取平均,并不能改善性能。
- 不同的池化方程:
发现替换成average pooling会降低性能到ODS=.741。
- 反向网络双线性插值:
side-output预测上采样使用in-network反卷积层,类似于文献[26]。我们将所有反卷积层改为运行线性插值。虽然文献[26]说能够学会任意插值方程,但我们发现学习的反卷积并不能明显改善性能。
- 运行时间:
在单卡K40的GPU上训练需要7小时。对于320*480图像,耗费400ms。明显快于基于CNN的方法。
BSDS500数据集包括200训练集、100验证集、200测试集。评价三准则:fixed contour threshold (ODS), per-image best threshold(OIS), and average precision (AP)。
八、BSDS500数据库实验结果
BSDS500:the Berkeley Segmentation Dataset and Benchmark (BSDS 500) [1]。
训练集200幅图像,验证集100幅图像,测试集200幅图像。每幅都手动标注了gt轮廓。
准确性评价使用三个标准:fixed contour threshold (ODS), per-image best threshold
(OIS), and average precision (AP)。
为了优化评价结果,我们使用在edge maps上使用标准的非极大值抑制方法来获取thinned edges。实验结果见Figure5和table4。如Figure5所示,本方法获得最佳结果,ODS=.782。


- Side outputs:
为了更明确的验证side outputs,table 3显示不同尺度上每个side outputs的结果,包括多尺度edge maps的不同结合。融合输出得到最佳F值,5层平均得到最佳平均准确性,合并二者得到最佳性能。注意所有side-output预测值都是one pass得到的。
HED比其他深度学习方法有更高的召回率是因为deep supervision能考虑到low level predictions。
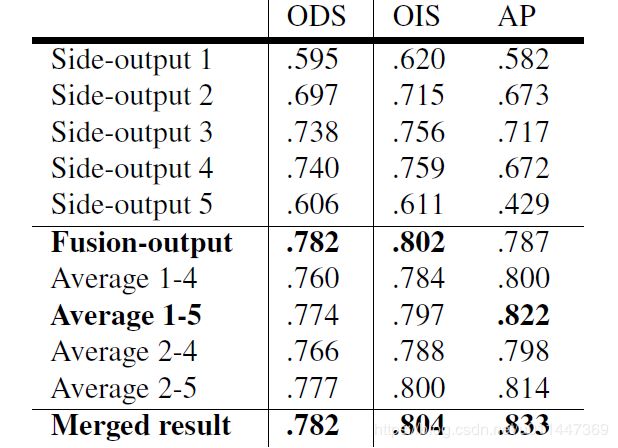
根据作者提供的开源代码,out = (out1 + out2 + out3 + out4 + out5 + fuse) / 6,根据测试,fuse最干净,out次之,ave细小噪声最多。
- Late merging to boost average precision:
融合层的权重学习更关注global物体边缘。因此将融合层输出和平均输出进行结合。
- 更多训练数据:
从测试集采样100张图作为训练集,在剩下的100张测试图进行测试,性能更高,从0.782涨到0.797,接近人类水平。
九、NYUDv2 数据库实验结果
NYU Depth (NYUD) 数据库(文献[35])有1449幅RGB-D深度图像。381幅训练集,414幅验证集,654幅测试集。所有图像是相同尺寸,我们训练时不缩放。(深度图像忽略)
十、总结与收获
GPU上400ms,CPU上12秒。
受FCN和DSN的启发,使用VGG进行预训练。
训练使用端到端,提取multi-scale和multi-level特征。
十一、深入理解
- 与FCN-网络对比:
网络类型类似于FCN-2S。
直接替换FCN-8S中的loss为交叉熵的性能不好,FCN-2s network that adds additional links from the pool1 and pool2 layers)
- 什么是deep supervision:
在这里指的是来自side-output 的结果
The “fusion-output without deep supervision” result is learned w.r.t Eqn. 3. The “fusion-output with deep supervision” result is learned w.r.t. to Eqn. 4
关于The role of deep supervision:
deep supervision terms (specifically, ℓside(W,w(m)):
每一层都看做是一个独立的network的输出(在不同的尺度上)
实验表明,仅仅用weighted-fusion supervision训练,在高层的side output上很多关键的边缘信息都丢失了。
- Loss:
对轮廓的输出其实可以类比成FCN像素级分割对于轮廓线与非轮廓线两种分类。所以非轮廓线的像素点会远远大于轮廓线的像素点。如果使用正常的loss进行训练很容易会训练不出来,因为网络在计算的过程中会认为全都不是轮廓线会产生更小更稳定的loss。所以我们放大轮廓线部分的Loss。
在训练中对不同层的结果进行综合的过程中,作者提出了另一种结合每一层的输出计算Loss的办法。
- 利用HED进行文档定位:
1)知乎专栏
阅读腾讯《基于 TensorFlow 在手机端实现文档检测》
https://zhuanlan.zhihu.com/p/27191354
2)博文《基于 TensorFlow 和 OpenCV 实现文档检测功能》
http://fengjian0106.github.io/2017/05/08/Document-Scanning-With-TensorFlow-And-OpenCV/
代码已开源在github