大数据(一)数据采集 3
数据采集3:
关于pandas的函数都在官方API有写,哪个参数不会用首先应该去查这个
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.interpolate.html
-------------------------------------------------------------0---------------------------------------------------------------------
1.df.interpolate() 插值函数(即填充空白值更平滑的方法,因为某些数据需要平滑过渡,比如温度不能骤降或者骤升)
在数据采集2里面我们详解了fillna的用法,但是尽管它可以用前一个值或后一个值来填补相邻位置的空白值,
df.fillna()这种填充往往是不合理的,比如说温度不能骤升骤降,的空白值显然是用两个点的平均值更合理。
(1) df.interpolate() 插值函数 取平均数
关于interpolate插值的用法,英文的值得参考:
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.interpolate.html
它有很多参数,这里不一一列举,method 默认的话是线性插值,大家可能忘了线性插值了,就是用两点间的直线去近似原函数。所以两个相邻的点之间如果有NaN的话,这个NaN会被填补为两点的平均数。
method : {‘linear’, ‘time’, ‘index’, ‘values’, ‘nearest’, ‘zero’,‘slinear’, ‘quadratic’, ‘cubic’, ‘barycentric’, ‘krogh’, ‘polynomial’, ‘spline’, ‘piecewise_polynomial’, ‘from_derivatives’, ‘pchip’, ‘akima’}
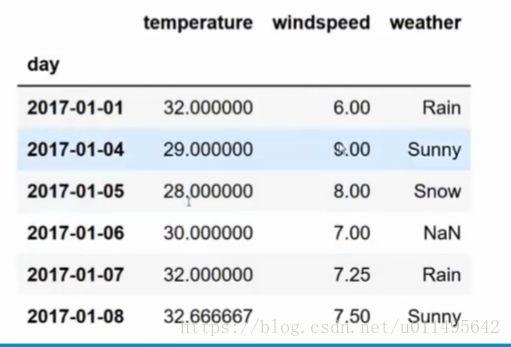
(2)df.interpolate(method = 'time' ) 根据时间间隔来计算 使数值更平滑
df的index索引一定得是时间格式的,df它会查你的索引,这样就能计算出来时间差。
例如: 这样温度它也会按时间计算线性插值
-------------------------------------------------------------------- 1 ----------------------------------------------------------------------------------------
2.如何处理 不可能出现的值(df.replace()或数据校验方法-->转化为NaN---> fillna()或interpolate() )
现在是有值,只是值不能用,那就需要先转化为空白值,再填充它。
(1)df.replace()
有时候数据库里会用特别极端的值代替不可能出现的数据,我们需要通过df.replace() 来替换为NaN。
以下例子有5种用法,第1种替换单个值为NaN,第2种一次替换多个值为NaN,第3种按列替换为NaN
第4种 我可以对每一列用正则表达式(对整个表直接用regex很容易刷掉有效数据),比如说天气就不适合出现数字,年龄不适合出现字母。有这些内容的我都给它替换成NaN。
第5种,我不替换为NaN了,我替换成一个list,都给比较合理的值。
import numpy as np
import pandas as pd
df = pd.read_csv("~/weather_data.csv")
# 1. Replace special values for the entire dataframe
new_df = df.replace('-99999', np.NaN)
new_df
# 2. Replace multiple special values at one time for the entire dataframe
new_df = df.replace(['-99999','-99991'], np.NaN)
new_df
# 3. columns
new_df = df.replace({'temperature':'-9999','weather':'0'}, np.NaN)
new_df
# 4. regular expression (regex)
new_df = df.replace({'temperature':'[A-Za-z]'},'weather':'[0-9]',regex = True)
new_df
# 5. Replace Values with a list of Values
new_df = df.replace(['-99999','-99991'], ['35','7'])
new_df
(2)通过数据校验方法转化为NaN,这种方式更通用,覆盖面积更大。
总结:
处理步骤:
(1)通过【df.replace()或者数据校验】方法,将不符合要求的无效值标记为NaN。
(2)有了NaN值,就可以通过fillna()和interpolate()两种方法来填充NaN的值
-------------------------------------------------------------------- 2----------------------------------------------------------------------------------------
3.如何处理Outliers(极端值)
极端值对数据整体的影响很大。
首先我们怎么认定一个数据是极端值呢,有几种办法:
(1)计算标准化值 z-value
公式:z=(x-μ)/σ,z就是standardized value,也叫z-value。
μ是指服从正态分布的随机变量的平均值,σ是标准差。
然后还有一个T作为阈值,如果和标准化值的距离 大于这个阈值的话,就是极端值。
(2)percentile 百分线:
我们划一条百分线,高于百分之多少我们就算它是极端值。
这种方式叫做percentile.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
其次我们怎么替换(修正)极端值:
(1)T*标准差+平均值
这意味着所有的outliers(翻译为野点或极端值)都是同一个值来替代
(2)选一个不超过percentile线的,但最接近percentile线的值。
意味着边界内最大值来替换边界外的值
(3)删除所有极端值
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
再说如何发现极端值的方法(其实和如何认定极端值是差不多的,只是加了个绝对中位差的方法):
(1)MAD(Median Absolute Deviation) :绝对中位差。
简单来说,绝对中位差较标准差而言对“野”点(outlier)更加的鲁棒(更加抗异常)。在标准差的计算中,数据点到其均值的距离要求平方,因此对偏离较为严重的点偏离的影响得以加重,也就是说“野”点严重影响着标准差的求解,而少量的“野”点对绝对中位差的影响不大。
计算方法:![]()
解释下这个公式的计算步骤,其实非常简单:
给一组原始数据,先计算所有数据的中位数 A,然后用原始数据的每个值和A做差,对差取绝对值之后再取一次中位数即可。
通过和绝对中位差比较,差的比较多的就是极端值,具体怎么规定的我还没有做过例子。
(2)Percentile
为了加深理解,现在实际动手做一下:
(1)percentile方式发现极端值的方法(注意percentile是numpy的方法,因为涉及到数值计算了)
def percentile_based_outlier(data, threshold=95):
diff = (100 - threshold) / 2.0
minval, maxval = np.percentile(data, [diff, 100-diff])
return (data < minval) | (data > maxval)np.percentile(data,[x1,x2]) 意思是,这条线我划在 2.5%和97.5%,意思是在data这个list里 求2.5%和97.5%分别对应的数据,最后返回小于min和大于max的outlier。
运行结果:True的都是极端值

(2)MAD 绝对中位差方式
解释下这个函数,如果是一维数组(它用的len=1 所以是一维),points就给每个元素都加括号来提升维度。比如原来是一维8列,现在就变成8个一维数组,每个一维数组只有一列,实际上就是8行一列。shape[0]为8,shape[1]为1。
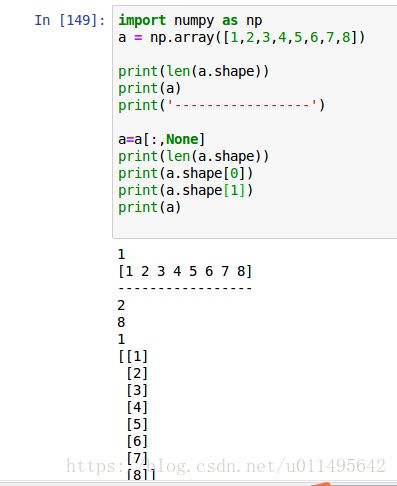
换成二维数组,我们就可以开始算中位数,0表示按列来算中位数。
中位数我们按列来算,因为要照顾一维数组转成二维数组的情况。每列都算出中位数之后,放到一个median数组里。
然后用points减去中位数的差,我们要求的是绝对值,所以他按照行来取平方再开方,就是绝对值了。这个绝对值再取中位数就可以得到绝对中位差。
然后我们用 T=0.6745*diff /绝对中位差 会获得一个值叫做Z-Score。Z分数还有另外一个计算公式,0.6745这个我反而没听说过,如果谁知道请告诉我一下,先不记了如果以后用会提到的。
def mad_based_outlier(points, thresh=3.5):
if len(points.shape) == 1:
points = points[:,None]
median = np.median(points,axis=0)
diff = np.sqrt(np.sum((points - median)**2,axis = -1))
med_abs_deviation = np.median(diff)
modified_z_score = 0.6745 * diff / med_abs_deviation
retrun modified_z_score > thresh
v = mad_based_outlier(users['Age'])
v = mad_based_outlier(np.array([34,345,1231,1245,43656,3434]))z分数(z-score):也叫标准分数(standard score),是一个分数与平均数的差再除以标准差的过程。
公式: z=(x-μ)/σ。其中x为某一具体分数, μ为平均数,σ为标准差。

~~~~~~~~~··~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~·
插播:a是8行一列的二维数组。
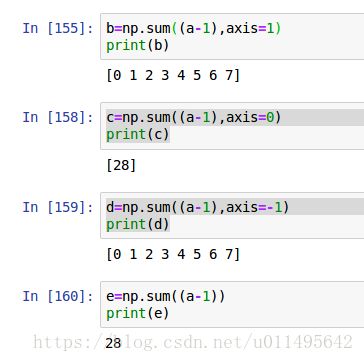
axis=-1的作用,和axis=1并无区别,都是按照行来算的,这样的话相当于按行计算每一行的和,分别是0-7。所以最后输出的是一维数组。而axis=0则是按照列,所以最后加成了一个元素。而如果毫无方向的话,就是直接取元素了,加完也就没有维度了,直接是28。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
这里必须插播一下shape(维度)属性的解释:
shape属性是numpy.array特有的,只有通过np创建的数组才有shape属性。
在一维数组里,shape就代表一维数组的列数。
假如是一个包含3个二行三列的二维数组,shape的值就是[3,2,3] 其中shape[0]是二维数组个数,
shape[1]是二维数组行数,shape[2]是二维数组列数。
可以看到,shape[0]表示最外围的数组的维数,shape[1]表示次外围的数组的维数,数字不断增大,维数由外到内。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~··
再插播:
从list, tuple对象中创建 - array()
array() - 创建多维数组。
np.array(object, dtype=None, copy=True, order='K', subok=False, ndmin=0)
object — list或tuple对象。强制参数。
dtype — 数据类型。可选参数。
copy — 默认为True,对象被复制。可选参数。
order — 数组按一定的顺序排列。C - 按行;F - 按列;A - 如果输入为F则按列排列,否则按行排列;K - 保留按行和列排列。默认值为K。可选参数。
subok — 默认为False,返回的数组被强制为基类数组。如果为True,则返回子类。可选参数。
ndmin — 最小维数。可选参数。
注:array函数的参数必须是由方括号括起来的列表,而不能使用多个数值作为参数调用array。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
我再插播:
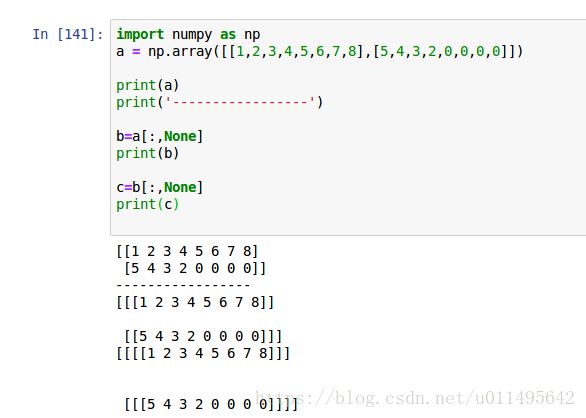
没看懂 这一步,于是我就在jupyter上试了一下
if len(points.shape) == 1:
points = points[:,None]看起来是升数组维度的方法,但是没有None就达不到效果,和使用np.newaxis效果确一模一样,都起到了升维的作用。
·
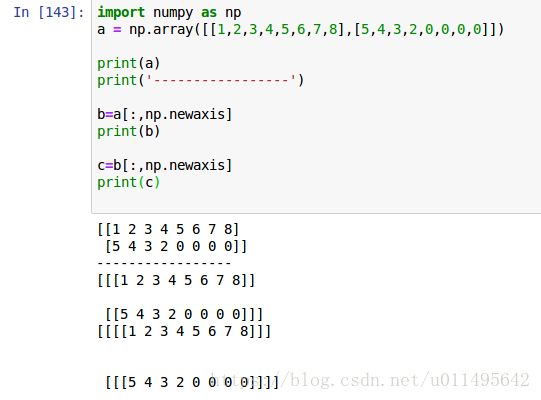
a[:, np.newaxis] # 给a最外层中括号中的每一个元素加[]
a[np.newaxis, :] # 给a最外层中括号中所有元素加[]
我发现None放在前面和后面,效果都和np.newaxis完全一样。·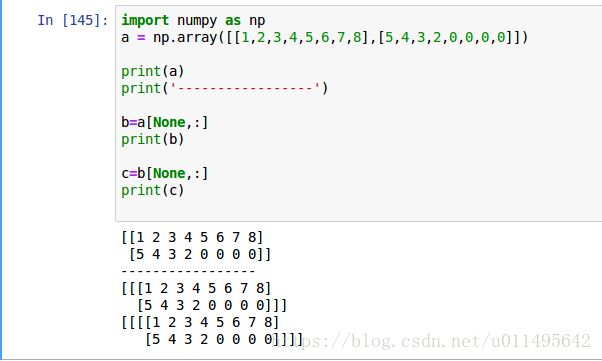
但是,如果不加这个None的话,就不会升维度。
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~·
关于:dtype
https://blog.csdn.net/starter_____/article/details/79173303
属性dtype
In [49]: arr=np.arange(5)
In [50]: arr
Out[50]: array([0, 1, 2, 3, 4])
In [51]: arr.dtype
Out[51]: dtype('int32')函数dtype( )
作用:结构化数组类型并加以使用
语法:numpy.dtype(object, align, copy)
| 参数 | 含义 |
|---|---|
| Object | 被转换为数据类型的对象。 |
| Align | 如果为true,则向字段添加间隔,使其类似 C 的结构体。 |
| Copy | 是否生成dtype对象的新副本,如果为flase,结果是内建数据类型对象的引用。 |
In [53]: np.dtype(np.int32)
Out[53]: dtype('int32')结构化数据类型
In [54]: student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
In [55]: print student
[('name', 'S20'), ('age', 'i1'), ('marks', '将其应用于 ndarray 对象
In [56]: a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
In [57]: print a
[('abc', 21, 50.) ('xyz', 18, 75.)]文件名称可用于访问 name,age,marks 列的内容
In [60]: print a['name']
['abc' 'xyz']
In [61]: print a['marks']
[ 50. 75.]
In [62]: print a['age']
[21 18]astype( )函数
作用:转换数据类型dtype
In [66]: arr=np.arange(5)
In [67]: arr.dtype
Out[67]: dtype('int32')
In [68]: float_arr=arr.astype(np.float64)
In [69]: float_arr.dtype
Out[69]: dtype('float64')
In [70]: float_arr
Out[70]: array([ 0., 1., 2., 3., 4.])
---------------------------------------------------------------------------------------------------------------------------------------------------------
回来了 ...把数据采集3补充完
——————————————————————————————-——————————————
4. 元数据
元数据就是描述数据的数据,非结构化的数据结构化的过程,需要定义一些元数据,你得知道一个数据的格式,你才知道怎么用它。
元数据分类:
(1)技术元数据 Technical Metadata /Schema
一个数据有几个字段,每个字段叫什么,格式是什么,每个值的范围和限定。这些都是硬性的。
(2)业务元数据 Business Metadata
除了数据的描述,还包含数据的归类、用法、业务上如何去用。(实际开发用的不多,但是数据搜索时有用,PB级大数据环境下 我根本不知道我的数据在哪个表里,如果可以基于业务元数据去搜索就容易很多。比如说找某个公司某个业务的数据)
我觉得这块听太多没意义,以后做项目都会用到的,大概了解即可。
——————————————————————————————————————