GhostNet 解读及代码实验(附代码、超参、日志和预训练模型)
文章首发于 极市平台
文章目录
- 一、前言
- 二、论文阅读
- 摘要
- 问题1: 何为特征图冗余?
- 问题2: Ghost feature maps 和 Intrinsic feature maps 是什么?
- 问题3: Linear transformations 和 Cheap operations 是什么?
- 问题4: Ghost Module长什么样?Ghost Bottlenecks长什么样?Ghost Net长什么样?
- 实验及结果
- 三、代码实验
- 实验1. 训练模型
- 实验2. 计算Weights和FLOPs
- 实验3. 可视化特征图
- 四、Ghost Module下一步工作
- 方案1: 借助baseline的卷积核参数
- 方案2:真正意义的即插即用
- 方案3:定制符合Ghost module的baseline
- 五、结语
本博文实验代码及结果:
code
https://github.com/TingsongYu/ghostnet_cifar10
一、前言
CVPR 2020 最近放榜,其中有一篇论文提出了一种新奇的轻量级卷积神经网络设计,思想非常巧妙,于是对其进行阅读和代码实践,并总结一些可能的下一步工作,供大家参考,共同学习。
本笔记主要分为三个部分,第一部分是论文阅读,对论文中要点进行讲解。第二部分是代码实验部分,对论文中提出的部分实验进行代码实验,包含模型训练,参数量计算,特征图可视化。第三部分是下一步工作,提出一些失败及未实现的想法,来实现不需要训练的即插即用Ghost module。
二、论文阅读
论文题名:《GhostNet: More Features from Cheap Operations》
arxiv: https://arxiv.org/abs/1911.11907
github :https://github.com/huawei-noah/ghostnet
作者翻译:https://zhuanlan.zhihu.com/p/109325275
摘要
在优秀CNN模型中,特征图存在冗余是非常重要的,但是很少有人在模型结构设计上考虑特征图冗余问题(The redundancy in feature maps)。
而本文就从特征图冗余问题出发,提出一个仅通过少量计算(cheap operations)就能生成大量特征图的结构——Ghost Module。
Ghost Module通过怎么样的操作生成特征图呢?这个操作是,一系列线性操作(a series of linear transformations)
在这里,经过线性操作生成的特征图称为ghost feature maps,而被操作的特征图称为intrinsic feature maps。
Ghost Module的操作那么魔幻,那么它有什么作(you)用(dian)?
- 即插即用:Ghost Module是一个即插即用模块,可以无缝衔接现有的CNN中。
- 采用Ghost Module组成的Ghost bottlenecks,设计出Ghost Net,在ILSVRC-2012上top1超过Mobilenet-V3,并且参数更少。
看完摘要,存在一些疑惑
首先,特征图冗余((The redundancy in feature maps))具体是什么意思?
其次,ghost feature maps 和intrinsic feature maps又是什么?
还有,一系列线性操作(a series of linear transformations)是什么?它为什么是cheap operations?
最后,Ghost Module长什么样?Ghost bottlenecks长什么样?Ghost Net长什么样?
这真是吊胃口的摘要,为了回答以上四个问题,接着往下看
问题1: 何为特征图冗余?
先找找关于特征图冗余的解释,Introduction 第四段提到了"For exam- ple, Figure 1 presents some feature maps of an input image generated by ResNet-50, and there exist many similar pairs of feature maps, like a ghost of each another". 对ResNet-50第一个残差块特征图进行可视化,但是,并没有直接说ResNet-50特征图存在冗余,而是用了这样的一句话“there exist many similar pairs of feature maps”。 那么来看看Figure 1吧。
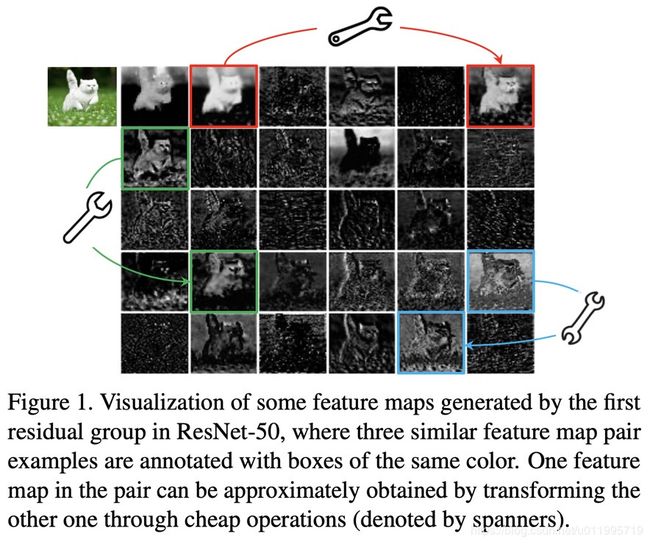
图1 对ResNet-50的特征图进行可视化,并强调了3组特征图,分别用红绿蓝三种颜色圈出来了,说这些特征图,可以近似的通过cheap operations来生成。哈?又出现了cheap operations,到底是啥?这个图并没有给答案,只告诉了大家cheap operations就是那个小扳手(皮…),继续看吧
再次强调特征图冗余就到了3.1 Ghost Module for More Features 第一段,“Given the widely existing redundancy in intermediate feature maps calculated by mainstream CNNs as shown in Figure 1”
这里说图1那样就是冗余了,请大家回到图1去看吧,哈?图1叫我往下看,看到这里又叫我回图1去找特征图冗余?
看到这里懵懵的了吧,接下来就有答案了。
3.1 第三段”the output feature maps of convolutional layers often contain much redundancy, and some of them could be similar with each other“
这里说看着相似的那些就是冗余了,原来如此,图1中,作者用红绿蓝重点给我们标记的那些就是冗余特征图的代表
到这里,可以知道那些相似的特征图被认为是冗余的,但是特征图冗余是什么,是没有定义的,只能意会,第一个问题到此结束。
问题2: Ghost feature maps 和 Intrinsic feature maps 是什么?
作者给那些特征图赋名为Ghost,的确用心良苦,毕竟这两个概念难以言传,请往下意会吧。
Introduction 第5段提到 “Given the intrinsic feature maps from the first part, a series of simple linear operations are then applied for generating more feature maps”。 从这里知道两者的关系,即 intrinsic feature maps 执行 linear operations 得到 ghost feature maps
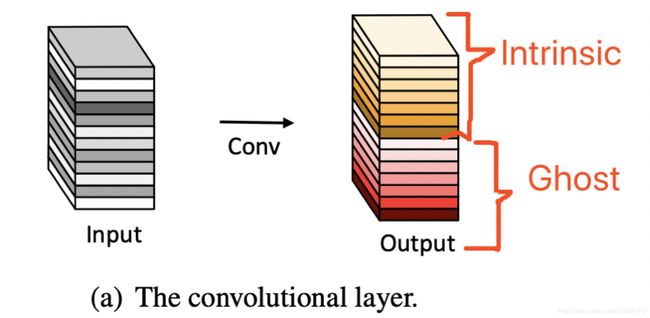
更形象的参见图2,即假设一组特征图中,一部分是Intrinic,而另外一部分是可以由 intrinsic 通过cheap operations来生成的。
cheap operations反复出现多次,但是到底是什么操作,还是不知道,下面看第三个问题。
问题3: Linear transformations 和 Cheap operations 是什么?
其实,从上文就知道 linear operations 等价于 cheap operations,它们是一回事。
文中3.1 终于提到了,linear operations 即是 诸如33的卷积,或者55的卷积。
“Note that the linear operations Φ operate on each channel whose computational cost is much less than the ordinary convolution. In practice, there could be several different linear operations in a Ghost module, e.g. 3 × 3 and 5 × 5 linear kernels, which will be analyzed in the experiment part.”
弄清楚摘要里出现的一系列概念,终于可以进入论文的核心——Ghost Module,Ghost Bottlenecks, Ghost Net
问题4: Ghost Module长什么样?Ghost Bottlenecks长什么样?Ghost Net长什么样?
图2很好的解释了 Ghost Module
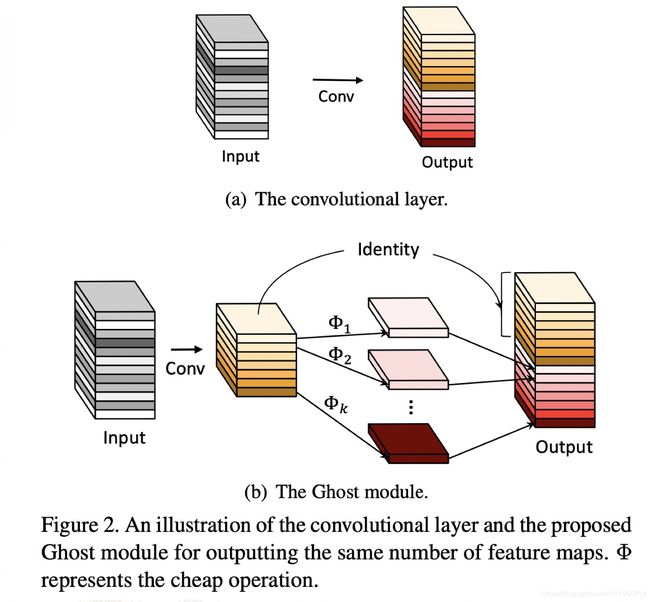
通常的卷积如图2(a)所示,而Ghost Module则分为两步操作来获得与普通卷积一样数量的特征图(这里需要强调,是数量一样)。
第一步:少量卷积(比如正常用32个卷积核,这里就用16个,从而减少一半的计算量)
第二步:cheap operations,如图中的Φ表示,从问题3中可知,Φ是诸如3*3的卷积,并且是逐个特征图的进行卷积(Depth-wise convolutional)。
这里应该是本文最大的创新点和贡献了。
了解了Ghost Module,下面看Ghost Bottlenecks。

论文3.2 介绍Ghost Bottlenecks ,结构与ResNet的是类似的,并且与mobilenet-v2一样在第二个module之后不采用ReLU激活函数。
左边是stride=1的Ghost Bottlenecks,右边是stride=2的Ghost Bottlenecks,目的是为了缩减特征图大小。
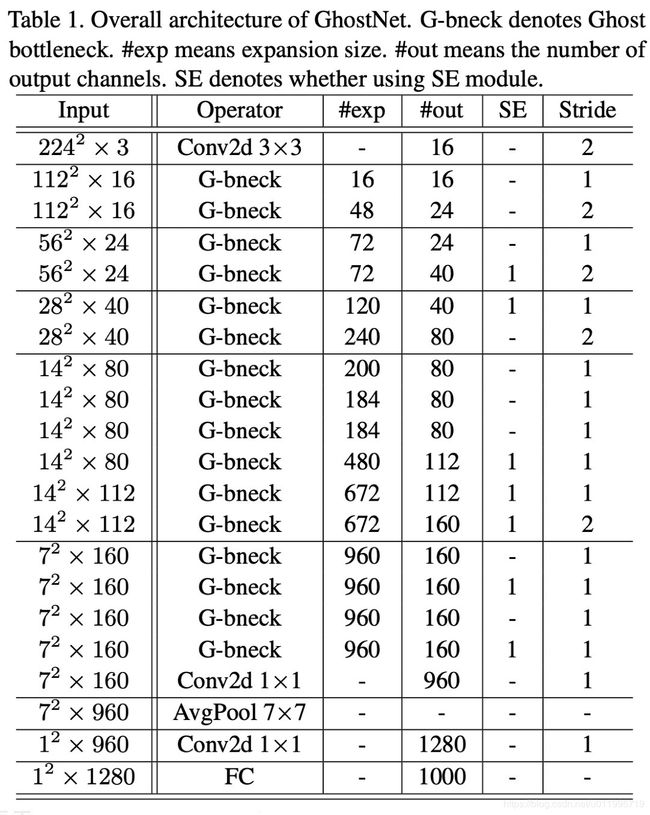
接着来看Ghost Net,Ghost Net结构与MobileNet-V3类似,并且用了SE结构,如下表,其中#exp表示G-bneck的第一个G-Module输出特征图数量
到这里,论文中概念全都清晰了,下面看看实验及效果吧
实验及结果
实验一,Toy Experiments,这个实验结果并不重要,只需要知道结论可以了,即 cheap operations中的卷积核选择3*3最佳
在这里,有探讨 cheap operations为什么用卷积,请看“Besides convolutions used in the above experiments, we can also explore some other low-cost linear operations to construct the Ghost module such as affine transformation and wavelet transformation. However, convolution is an efficient operation already well support by current hardware and it can cover a number of widely used linear operations such as smoothing, blurring, motion, etc. Moreover, although we can also learn the size of each filter w.r.t. the linear operation Φ, the irregular module will reduce the efficiency of computing units (e.g. CPU and GPU).”
简单地说,卷积高效且高质,所以linear transformations和cheap operations就是卷积,没错了。
实验二,在Cifar10上,对VGG-16和ResNet-56进行ghost module的即插即用实验,具体做法是,对于VGG-16和ResNet-56,其中的所有卷积替换为Ghost module,并命名为 Ghost-VGG-16和Ghost-ResNet-56
实验结果如下表,精度不怎么变化的条件下,参数和FLOPs均减少一半左右,效果不赖。

作者还对 vanilla VGG-16 以及 Ghost-VGG-16的第二个卷积特征图进行可视化,大意就是经过 cheap operation,得到的特征图与vanilla的差不多

实验三,在Imagenet 对ResNet-50进行ghost module的即插即用实验
这里s=4,所以参数和FLOPs大约也减小为1/4
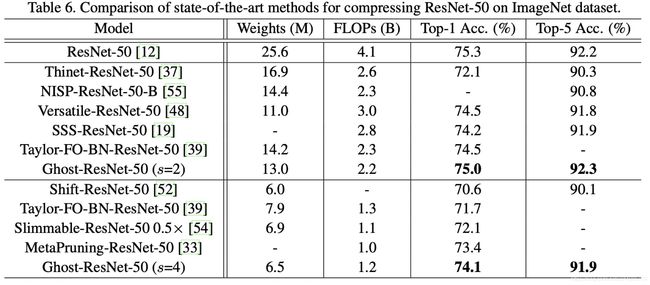
以上实验是对 ghost module 即插即用的实验,而对于摘要中提到的 Ghost Net超越Mobilenet-v3是怎么样的呢?
这里就不告诉大家了,感兴趣的朋友赶紧拜读原文:https://arxiv.org/abs/1911.11907
三、代码实验
读完论文就迫不及待想试试神奇的ghost module的能力。由于没有设备,未能在imagenet上训练ghostnet,这里仅对cifar10进行了复现实验,有机器的话,修改模型和dataloader就可以训练imagenet了。
实验代码主要有三个部分
- 训练模型,训练文中提到的vgg16, ghost-vgg16, resnet56, ghost-resnet56
- 计算Weights和FLOPs, 计算4个模型的Weights和FLOPs
- 可视化特征图,对vgg16,ghost-vgg16所有卷积特征图进行可视化
上述实现代码在:https://github.com/TingsongYu/ghostnet_cifar10 ,感觉有用的话请star
参考github
ghost部分:https://github.com/huawei-noah/ghostnet
vgg部分:https://github.com/kuangliu/pytorch-cifar
resnet部分: https://github.com/akamaster/pytorch_resnet_cifar10
实验1. 训练模型
这部分训练论文中提到的vgg16, ghost-vgg16, resnet56, ghost-resnet56
step1: 数据准备
从http://www.cs.toronto.edu/~kriz/cifar.html 下载python版,得到cifar-10-python.tar.gz,解压得到 cifar-10-batches-py,并放到 ghostnet_cifar10/data下,然后执行 python bin/01_parse_cifar10_to_png.py,可在data/文件夹下获得cifar10_train 和 cifar10_test两个文件夹
step2: 模型训练
训练脚本为 bin/02_main.py
训练resnet56
nohup python 02_main.py -gpu 1 0 -arc resnet56 > resnet56.log 2>&1 &
训练ghost-resnet56
nohup python bin/02_main.py -max_epoch 190 -lr 0.1 -gpu 1 0 -arc resnet56 -replace_conv > ghost-resnet56.log 2>&1 &
训练 vgg16
nohup python bin/02_main.py -max_epoch 190 -lr 0.1 -gpu 1 0 -arc vgg16 > vgg16.log 2>&1 &
训练ghost-vgg16
nohup python bin/02_main.py -max_epoch 190 -lr 0.1 -gpu 1 0 -arc vgg16 -replace_conv > ghost-vgg16.log 2>&1 &
参数解释
-replace_conv, 表示是否将模型中的conv2d层替换为GhostModule
-arc,目前写死了,只支持resnet56, vgg16,可自行修改
-gpu,gpu编号
-pretrain,训练ghost-***时,加载baseline的卷积核参数,这个不属于论文范畴,属于拓展的训练方法,拓展部分讲解
-frozen_primary,冻结primary部分的卷积核,训练ghost-**时,采用baseline的卷积核参数初始化之后对primary部分卷积核进行冻结,只训练cheap conv部分
-low_lr,primary部分卷积核学习率是否小10倍
-point_conv,block中第一个primary是否采用11卷积
代码结构
结构比较清晰,分为5个步骤, 数据–模型–损失函数–优化器–迭代训练
核心在于replace_conv函数进行卷积核替换为GhostModule,实现论文的操作,只需要传入三个参数,分别是model, GhostModule和arc即可
结果输出
实验结果输出均在results/文件夹下,以时间戳为子文件夹,未自动记录log
实验超参
实验超参按Ghostnet论文中提到那样,与Resnet论文中保持一致,lr=0.1, bs=128,2个gpu,epoch通过iteration转换得来的

实验结果
实验日志、曲线、checkpoint均在results里获得,由于vgg模型太大,已存到云盘,可自取,或按上述步骤自行训练即可。
VGG model 链接:https://pan.baidu.com/s/1pnc_Ir5ZwGeSpn9AAx6eZQ 密码:n82n
resnet model: 链接:https://pan.baidu.com/s/10e7CWdHxC18-0pwIr-vXHQ 密码:uz6f
实验结果如下表所示,与原文中提到的精度还是有一点点差距,不知是什么原因,大家也可以尝试一下参照论文中的设置进行实验,欢迎大家贡献自己的训练log和results到github上供大家一起学习
| Accuray | Accuray in paper | |
|---|---|---|
| resnet-56 | 93.4% | 93.0% |
| ghost-resnet-56 | 91.1% | 92.7% |
| vgg-16 | 93.5% | 93.6% |
| ghost-vgg-16 | 92.0% | 93.7% |
实验结果上看,达不到论文提出的精度,两个ghost-baseline模型均差1.7个百分点左右,不知是什么原因呢? 希望作者和大家提供训练参数和代码
所有训练结果均在github中results文件夹下可见,训练日志中有所有超参数的设置。
实验2. 计算Weights和FLOPs
脚本:bin/03_compute_flops.py
前期准备:安装torchstat
Weights和FLOPs的计算采用torchstat工具,必须是python3以上才可安装
安装方法: pip install torchstat
torchstat网站:https://github.com/Swall0w/torchstat
方法:执行03_compute_flops.py 即可得到Weights和FLOPs,得到的结果与论文中有一些误差,具体如下
| Weights | FLOPs | Weights in paper | FLOPs in paper | |
|---|---|---|---|---|
| resnet-56 | 0.85M | 126M | 0.85M | 125M |
| ghost-resnet-56 | 0.44M | 68M | 0.43M | 63M |
| vgg-16 | 14.7M | 314M | 15M | 313M |
| ghost-vgg-16 | 7.4M | 160M | 7.7M | 158M |
实验3. 可视化特征图
脚本:bin/04_fmap_vis.py
方法:运行脚本会在 results/runs下以时间戳为子文件夹记录下events file,然后借助tensorboard就可以查看特征图
与论文一致,对vgg16和ghost-vgg16进行可视化,可视化的图片也与论文一致,是那只可爱的小狗,可是论文没告诉大家那张图片在哪里,所以我人肉把那张可爱的狗狗给人肉出来了,在cifar10_train/5/5_11519.png
来看看VGG16第二个卷积层,是这样的
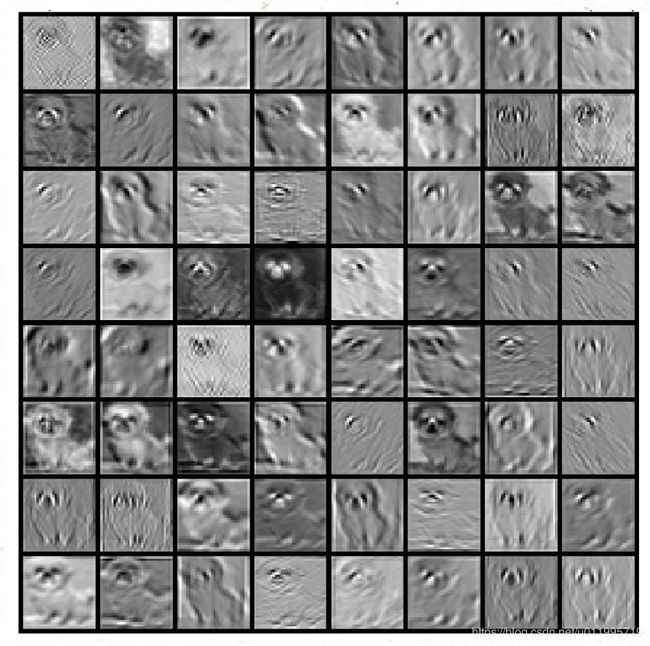
ghost-vgg16的第二个卷积部分的primary和cheap的卷积特征图如下

在这里发现cheap conv中有死神经元,输出是全黑的,不知道是哪个地方出错了,是否是这里导致模型指标达不到论文的水平呢?大家可以关注一下这个问题
四、Ghost Module下一步工作
ghostmodule的思想是很巧妙的,可以说是V1版,它还有很多东西可以改进,可以去做的地方,这里就提几个想到的方案,但是经过代码实践失败的idea。
所有的动机都是基于文中这张图:
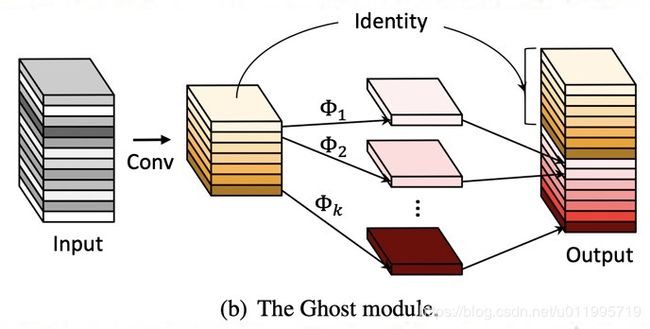
图中可知,Ghost module中的primary conv与原始卷积是一模一样的操作,唯一不同是cheap conv的逐通道卷积会改变一半的特征图,那么能否找到恰当的逐通道卷积核,让这一半特征图尽可能的与原始卷积得到的特征图一模一样,就可以实现不需要训练的即插即用。
思想就是,让Ghost module输出的特征图保持与原始卷积一致,那么就可以实现不需要训练的即插即用。
要想完成上述需求,可分为2步
- 针对primary convolutoin:先从baseline模型中挑选一半的卷积核直接赋值给Ghost module的primary conv,这一步是完全等价的,很好理解。
- 针对cheap convolution:找到恰当卷积核权值使得Ghost module输出的特征图与原始卷积尽可能保持一致
针对第一步,得出方案1
方案1: 借助baseline的卷积核参数
从baseline中挑选卷积核赋值到 ghost-baseline模型的primary convolution
具体操作只需要在 02_main.py 中 添加-pretrain,即可在replace_conv函数中执行baseline卷积核赋值操作。
在这里就会有一个问题,假设baseline的卷积层2K个卷积核,那么如何挑选出K个最有价值的卷积核呢?
这是最头疼的问题,按论文的思想,应该从特征图上去观察,哪些卷积核得到的特征图比较接近,那么就从相近的特征图对应的卷积核中挑选出一个。
这里就采用了卷积核聚类的方法来挑选8个卷积核,然后赋值。这个方案效果不好,多种尝试均存在掉点,于是放弃了,大家也可以尝试不同超参进行训练,看一下效果
在方案1中,还有多种子问题,这里就列举一下
问题1. 如何从baseline中2K个卷积核中挑选K个卷积核?
- 从特征图中选择相近的卷积核;
- 采用聚类方法对卷积核进行聚类,聚类类别为K个类别;
- 对卷积核进行L1排序,挑选L1较大的前K个;
- 对卷积核进行熵的计算,挑选熵较大的前K个;
上述4个方法汇总,1,3,4都可在代码中找到对应函数,但由于效果不好,就没有指出
问题2. ghost-baseline训练中,primary是否需要更新?
按论文的思想,primary 卷积核来自baseline的卷积核,应该是一个已经训练得很好的卷积核了,因此不需要再训练,只要保证cheap convolution的卷积核学习到比较好的线性变换就可以。但实际上,如果冻结primary的卷积核,模型性能大幅下降,这里可以通过参数 -low_lr 和 -frozen_primary分别实现primary采用较小学习率或完全不更新。
问题3. 特征图拼接是否需按顺序
由于primary卷积核来自baseline,特征图拼接部分应该按卷积核顺序拼接,否则下一个primary卷积接收的特征图就乱了。
因此对Ghost Module进行了少少修改,增加fmap_order参数用于记录卷积核顺序,同时在forward中增加特征图排序。
经过不断实验,想通过baseline的训练参数进行即插即用的方案暂时以失败告终。
想从baseline中借用已经训练好的卷积核方案还不成熟,希望大家可针对这个想法进一步改进,按论文中的理论,baseline中的卷积核应该可以拿到ghost-baseline中用一用的。
针对第二步,得出方案2
方案2:真正意义的即插即用
文中提到的即插即用是模型结构的变换,但是还需要重新训练,那么有没有方案实现真正意义的即插即用,不用训练?
要实现不训练的即插即用,就要回顾Ghost Module对原始Conv的改变,这里还要回顾这张图
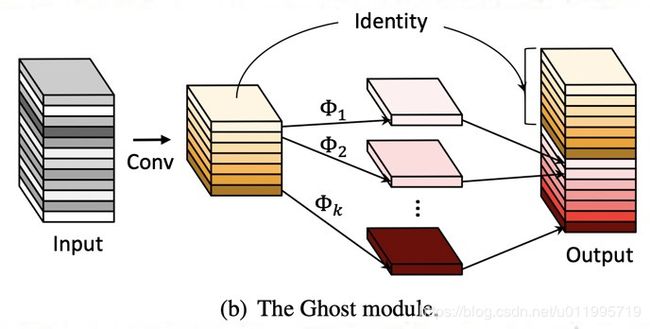
从图中可以发现,唯一变化的地方就是 cheap operation导致一半的特征图变化。
因此,重点关注cheap部分的卷积核,只要这部分的卷积核能实现从intrinsic feature maps中变换得到与baseline卷积核对input进行卷积得到的特征图一致的特征图,那么Ghost Module就实现了不需要训练的即插即用。
上面那句话很是绕口,下面配图解释方案2的想法,如何可以实现不训练的即插即用。
先看下图,上半部分是正常的卷积,下半部分是Ghost module示意图。
为了更好理解intrinsic和ghost,正常卷积的卷积操作拆分为两个部分,分别是W_i,和W_g,分别对应intrinsic和ghost,其中W_i是需要保留的卷积核,它得到的特征图为F_i,这一部分在Ghost Module中是完全被保留的,因此它的特征图不会发生变化,发现变化的是W_g部分卷积核卷积得到的F_g。
再看下半部分的Ghost Module中,特征图被变化的是cheap ops中的生成的F_c。如何找到恰当的权值W_c使得F_c等价于F_g呢?

为了得到W_c的权值,可以从文中的假设出发,intrinsic feature maps和ghost feature maps存在线性变换的话,势必存在公式 F_g = W*F_i, 其中W是权值矩阵。
卷积操作又可以写成矩阵乘法的形式,那么我们可以找到W的权值,请看下图公式

当我们得到W矩阵,那么就得到了W_c矩阵。
这里存在一个问题,W_i是否可逆? 大部分情况都是不可逆的,所以这个方案通过这个思路还是受阻的,当然大家可以尝试求伪逆,得到W矩阵,然后赋值给cheap ops中的卷积核,试一下效果,这里仅提供一个思路,就没有去实现了。
方案3:定制符合Ghost module的baseline
方案2中无法找到合适的线性变换,使得F_g = F_i ,其根本原因是baseline的卷积部分的卷积核之间不存在这种线性关系。
那么,为了实现不训练的即插即用,是否可以从baseline结构出发,设计一个卷积核内部存在线性变换的模型结构,然后再用以上等价方式进行变换到ghost module。
不知道卷积核内部存在线性变换的结构是否已经有论文提出? 如果有,请发邮件([email protected])或评论告诉大家吧。
五、结语
Ghost Module的想法很巧妙,可即插即用的实现轻量级卷积模型,但若能实现不训练的轻量级卷积模型,那就更好了。这也是本笔记中遗憾的部分,未能实现不训练的即插即用,在此希望集思广益,改进上述提出的不成熟方案,说不定GhostNet-V2就诞生了,当然更期待原作者提出GhostNet-V2。