Xxl Job Helloworld
刚到新公司不久,新公司使用分布式任务调度平台是 xxl-job。其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。当然它的特性在 它的官网 描述得非常清楚,我就不需要赘述了。对于 xxl-job 只是了解过,并没有在真实的环境使用过。为了更好的使用这个框架,准备分析一下它的实现过程。使用的 xxl-job 是最新版本 2.2.0-SNAPSHOT,下面从 hello world 开始。
1、设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
2、系统组成
2.1 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
2.2 执行模块(执行器):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
3、架构图
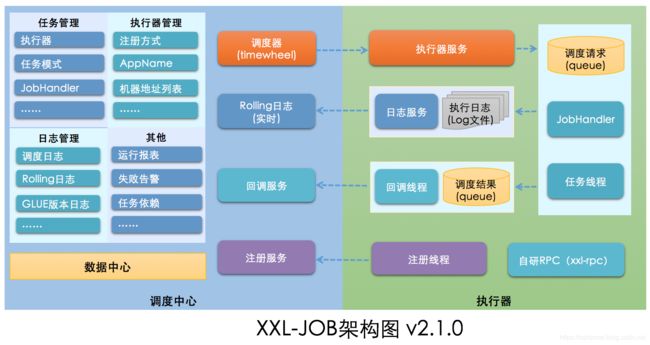
4、调度模块
xxl-job 早期实现是通过 Quartz 来实现的。Quartz作为开源作业调度中的佼佼者,是作业调度的首选。但是集群环境中Quartz采用API的方式对任务进行管理,从而可以避免上述问题,但是同样存在以下问题:
问题一:调用API的的方式操作任务,不人性化;
问题二:需要持久化业务QuartzJobBean到底层数据表中,系统侵入性相当严重。
问题三:调度逻辑和QuartzJobBean耦合在同一个项目中,这将导致一个问题,在调度任务数量逐渐增多,同时调度任务逻辑逐渐加重的情况下,此时调度系统的性能将大大受限于业务;
问题四:quartz底层以“抢占式”获取DB锁并由抢占成功节点负责运行任务,会导致节点负载悬殊非常大;而XXL-JOB通过执行器实现“协同分配式”运行任务,充分发挥集群优势,负载各节点均衡。
XXL-JOB弥补了quartz的上述不足之处。采用了自研调度模块。
XXL-JOB最终选择自研调度组件(早期调度组件基于Quartz);一方面是为了精简系统降低冗余依赖,另一方面是为了提供系统的可控度与稳定性;
XXL-JOB中“调度模块”和“任务模块”完全解耦,调度模块进行任务调度时,将会解析不同的任务参数发起远程调用,调用各自的远程执行器服务。这种调用模型类似RPC调用,调度中心提供调用代理的功能,而执行器提供远程服务的功能。
5、hello world
我们首先从 xxl-job github 地址 把项目源代码拉取下来。

- xxl-admin:就是调度中心。
- xxl-job-executor-samples:是提供的不同使用的简单 demo,可以理解成执行器。
- xxl-job-core:是基础模块,为调用中心以及执行器提供服务。
下面就来说说如何使用 xxl-job。
5.1 初始化调度数据库
调度数据库初始化SQL脚本位置为,下载项目目录的:
/xxl-job/doc/db/tables_xxl_job.sql
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
5.2 启动调度中心
启动调度中心需要以下几个步骤:
首先个性调度中心的配置文件,调度中心配置文件地址:
/xxl-job/xxl-job-admin/src/main/resources/application.properties
调度中心配置内容说明:
### 调度中心JDBC链接:链接地址请保持和 2.1章节 所创建的调度数据库的地址一致
spring.datasource.url=jdbc:mysql://127.0.0.1:3306/xxl_job?Unicode=true&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=root_pwd
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
[email protected]
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 调度中心国际化配置 [选填]: 默认为空,表示中文; "en" 表示英文;
xxl.job.i18n=
## 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
调度中心访问地址:http://localhost:8080/xxl-job-admin (该地址执行器将会使用到,作为回调地址)
默认登录账号 “admin/123456”, 登录后运行界面如下图所示。

5.3 配置部署执行器项目
“执行器”项目:xxl-job-executor-sample-springboot (提供多种版本执行器供选择,现以 springboot 版本为例,可直接使用,也可以参考其并将现有项目改造成执行器)
作用:负责接收“调度中心”的调度并执行;可直接部署执行器,也可以将执行器集成到现有业务项目中。
对于真实的项目需要启动执行器需要执行以下几个步骤:
步骤一:maven依赖
确认pom文件中引入了 “xxl-job-core” 的maven依赖;
步骤二:执行器配置
执行器配置,配置文件地址:
/xxl-job/xxl-job-executor-samples/xxl-job-executor-sample-springboot/src/main/resources/application.properties
执行器配置,配置内容说明:
### 调度中心部署跟地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-sample
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
注意:如果配置执行端口号那么它不需要与执行器所在的服务端口不同冲突。
步骤三:执行器组件配置
执行器组件,配置文件地址:
/xxl-job/xxl-job-executor-samples/xxl-job-executor-sample-springboot/src/main/java/com/xxl/job/executor/core/config/XxlJobConfig.java
执行器组件,配置内容说明:它主要的作用就是把当前任务注册到调度中心,用于调度中心控制执行器的执行。
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppName(appName);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
步骤四:启动 xxl-job-executor-sample-springboot
com.xxl.job.executor.XxlJobExecutorApplication.main() 启动。
5.4 调度中心配置并启动任务
首先 执行器管理 模块添加执行器,它其实就是作业分组。点击进入”执行器管理”界面, 如下图:

图中的执行器是初始化 SQL 添加进去的。在没有执行器注册成功的时候 Online 机器地址 这栏是空的。
1、"调度中心OnLine:"右侧显示在线的"调度中心"列表, 任务执行结束后, 将会以failover的模式进行回调调度中心通知执行结果, 避免回调的单点风险;
2、"执行器列表" 中显示在线的执行器列表, 可通过"OnLine 机器"查看对应执行器的集群机器。
点击按钮 “+新增执行器” 弹框如下图, 可新增执行器配置:
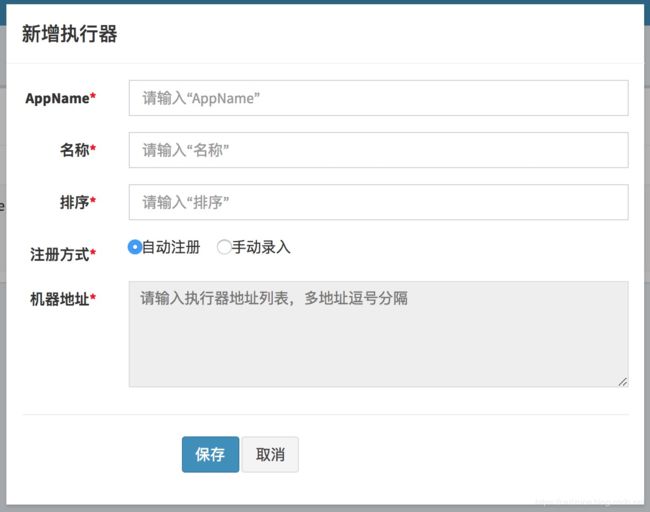
执行器属性说明:
AppName: 是每个执行器集群的唯一标示AppName, 执行器会周期性以AppName为对象进行自动注册。可通过该配置自动发现注册成功的执行器, 供任务调度时使用;
名称: 执行器的名称, 因为AppName限制字母数字等组成,可读性不强, 名称为了提高执行器的可读性;
排序: 执行器的排序, 系统中需要执行器的地方,如任务新增, 将会按照该排序读取可用的执行器列表;
注册方式:调度中心获取执行器地址的方式;
自动注册:执行器自动进行执行器注册,调度中心通过底层注册表可以动态发现执行器机器地址;
手动录入:人工手动录入执行器的地址信息,多地址逗号分隔,供调度中心使用;
机器地址:"注册方式"为"手动录入"时有效,支持人工维护执行器的地址信息;
其实在初始化的 sql 中已经添加了执行器。也就是 xxl-job-executor-sample 这个示例执行器。

在执行器启动成功之后 Online 机器地址 就会显示注册的机器,在没有启动执行器的时候,这一拦是空的。可以查看执行器管理中的图片。
下一个步骤就是在任务管理模块中在已有执行器添加任务:
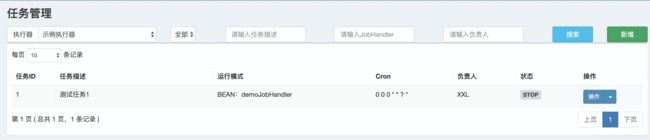
初始化 SQL 已经添加了 bean 模式的任务。我们直接执行就可以了。下面是新建任务的界面

配置属性详细说明:
执行器:任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 "执行器管理" 进行设置;
- 任务描述:任务的描述信息,便于任务管理;
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久为使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- Cron:触发任务执行的Cron表达式;
- 运行模式:
BEAN模式:任务以JobHandler方式维护在执行器端;需要结合 "JobHandler" 属性匹配执行器中任务;
GLUE模式(Java):任务以源码方式维护在调度中心;该模式的任务实际上是一段继承自IJobHandler的Java类代码并 "groovy" 源码方式维护,它在执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服务;
GLUE模式(Shell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "shell" 脚本;
GLUE模式(Python):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "python" 脚本;
GLUE模式(PHP):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "php" 脚本;
GLUE模式(NodeJS):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "nodejs" 脚本;
GLUE模式(PowerShell):任务以源码方式维护在调度中心;该模式的任务实际上是一段 "PowerShell" 脚本;
- JobHandler:运行模式为 "BEAN模式" 时生效,对应执行器中新开发的JobHandler类“@JobHandler”注解自定义的value值;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
- 报警邮件:任务调度失败时邮件通知的邮箱地址,支持配置多邮箱地址,配置多个邮箱地址时用逗号分隔;
- 负责人:任务的负责人;
- 执行参数:任务执行所需的参数;
下面我们就在初始化的任务操作栏,执行一次启动任务。
可以通过调度日志查看任务执行情况:

以及查看运行报表查看任务的相关信息:

参考文章:分布式任务调度平台XXL-JOB 官方文档