【知识图谱】知识推理
文章目录
- 一、本体知识推理简介
- 1、OWL本体语言
- 2、描述逻辑
- (1)描述逻辑系统
- (2)描述逻辑的语义
- 3、知识推理任务分类
- (1)可满足性(satisfiability)
- (2)分类(classification)
- (3)实例化
- 二、本体推理方法与工具介绍
- 1、基于Tableaux运算的方法
- (1)概述
- (2)示例
- (3)相关工具介绍
- 2、基于逻辑编程改写的方法
- (1)概述
- (2)Datalog语言推理
- (3)相关工具简介
- 3、基于一阶查询重写的方法
- (1)概述
- (2)示例
- (3)Ontop 工具
- 4、基于产生式规则的方法
- (1)产生式系统组成
- (2)产生式系统执行
- (3)相关工具介绍
一、本体知识推理简介
1、OWL本体语言
OWL的特性:
- OWL本体语言是知识图谱中最规范(W3C制定)、最严谨(采用描述逻辑)、表达能力最强(是一阶谓词逻辑的子集)的语言;
- 它基于RDF语法,使表示出来的文档具有语义理解的结构基础。
- 促进了统一词汇表的使用,定义了丰富的语义词汇。
- 允许逻辑推理。
语法:RDF语法,三元组:(subject, property, object)
2、描述逻辑
逻辑基础:描述逻辑
- 描述逻辑(Description Logic):基于对象的知识表示的形式化,也叫概念表示语言或术语逻辑,是一阶谓词逻辑的一个可判定子集。
(1)描述逻辑系统
一个描述逻辑系统由四个基本部分组成:
- 最基本的元素:概念、关系、个体;
- TBox术语集:概念术语的公理集合;
- Abox断言集:个体的断言集合;
- TBox 和 ABox上的推理机制;
不同的描述逻辑系统的表示能力与推理机制由于对这四个组分的不同选择而不同。
下面对四个组成部分进行介绍:
- 最基本的元素:概念、关系、个体。
- 概念:一个领域的子集,如
学生:{x|student(x)} - 关系:该领域上的二元关系(笛卡尔积),如
朋友:{ - 个体:一个领域内的实例,如
小明:{Ming}
- 概念:一个领域的子集,如
- TBox术语集——泛化的知识
- 定义:描述概念和关系的知识,被称之为公理(Axiom)。
- 由于概念之间存在包含关系,TBox 知识形成类似 格(Lattice) 的结构,这种结构是由包含关系决定的,与具体实现无关。
- Tbox语言
(1) 定义:引入概念及关系的名称,如Mother、Person、has_child
(2) 包含:声明包含关系的公理,例如 M o t h e r ⊑ ∃ h a s _ c h i l d . P e r s o n \mathrm{Mother} \sqsubseteq \exists \mathrm{has\_child}.\mathrm{Person} Mother⊑∃has_child.Person
- ABox断言集——具体个体的信息
- 包含:外延知识(又称为断言(Assertion)), 描述论域中的特定个体。
- ABox语言
(1)概念断言:表示一个对象是否属于某个概念,例如Mother(Alice)、Person(Bob)。
(2)关系断言:表示两个对象是否满足特定的关系,例如has_child(Alice, Bob)。
- 描述逻辑的知识库 K : = ⟨ T , A ⟩ K:=\langle{T,A}\rangle K:=⟨T,A⟩, T T T 即 TBOx , A A A即ABOx。
(2)描述逻辑的语义
描述逻辑的语义:
- 解释Ⅰ是知识库 K K K 的模型,当且仅当Ⅰ是 K K K 中每个断言的模型。若一个知识库 K K K 有一个模型,则称 K K K 是可满足的。若断言σ对于 K K K 的每个模型都是满足的,则称 K K K 逻辑蕴含 σ \sigma σ,记为 K ⊨ σ K⊨\sigma K⊨σ。对概念 C C C,若 K K K 有一个模型Ⅰ使得 C Ⅰ ≠ ϕ C^Ⅰ\neq\phi CⅠ̸=ϕ 则称 C C C 是可满足的。
- 描述逻辑依据提供的构造算子,在简单的概念和关系上构造出复杂的概念和关系。描述逻辑至少包含以下 构造算子:交 ( ∩ \cap ∩)、并( ∪ \cup ∪)、非 ( ¬ \neg ¬)、存在量词 ( ∃ \exists ∃)和全称量词 ( ∀ \forall ∀)。
有了语义之后,我们可以进行推理。通过语义来保证推理的正确和完备性。
下图给出描述逻辑的语义表:
| 构造算子 | 语法 | 语义 | 例子 |
|---|---|---|---|
| 原子概念 | A | A Ⅰ ⊆ Δ Ⅰ A^Ⅰ\subseteq\Delta^Ⅰ AⅠ⊆ΔⅠ | Human |
| 原子关系 | R | R Ⅰ ⊆ Δ Ⅰ × Δ Ⅰ R^Ⅰ\subseteq\Delta^Ⅰ\times \Delta^Ⅰ RⅠ⊆ΔⅠ×ΔⅠ | has_child |
| 对概念 C,D和关系(role) R | |||
| 合取 | C ⊓ D C\sqcap{D} C⊓D | C Ⅰ ∩ D Ⅰ C^Ⅰ\cap{D^Ⅰ} CⅠ∩DⅠ | H u m a n ⊓ M a l e \mathrm{Human}\sqcap\mathrm{Male} Human⊓Male |
| 析取 | C ⊔ D C\sqcup{D} C⊔D | C Ⅰ ∪ D Ⅰ C^Ⅰ\cup{D^Ⅰ} CⅠ∪DⅠ | H u m a n ⊔ M a l e \mathrm{Human}\sqcup\mathrm{Male} Human⊔Male |
| 非 | ¬ C \neg C ¬C | Δ Ⅰ ∖ C \Delta^Ⅰ\setminus C ΔⅠ∖C | ¬ M a l e \neg Male ¬Male |
| 存在量词 | ∃ R . C \exists R.C ∃R.C | { x ∣ ∃ y . ⟨ x , y ⟩ ∈ R Ⅰ ∧ y ∈ C Ⅰ } \{x\mid \exists y.\langle {x,y} \rangle\in {R^Ⅰ}\wedge{y\in{C^Ⅰ}}\} {x∣∃y.⟨x,y⟩∈RⅠ∧y∈CⅠ} | ∃ h a s _ c h i l d . M a l e \exists \mathrm{has\_child.Male} ∃has_child.Male |
| 全称量词 | ∀ R . C \forall R.C ∀R.C | { x ∣ ∀ y . ⟨ x , y ⟩ ∈ R Ⅰ ⇒ y ∈ C Ⅰ } \{x\mid \forall y.\langle {x,y} \rangle\in {R^Ⅰ}\Rightarrow{y\in{C^Ⅰ}}\} {x∣∀y.⟨x,y⟩∈RⅠ⇒y∈CⅠ} | ∃ h a s _ c h i l d . M a l e \exists \mathrm{has\_child.Male} ∃has_child.Male |
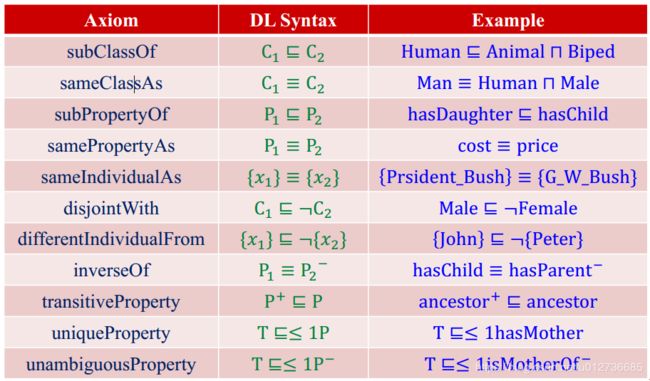
描述逻辑与OWL词汇的对应
3、知识推理任务分类
知识推理:通过各种方法获取新的知识或者结论,这些知识和结论满足语义。
具体任务可分为:
- 可满足性(satisfiability)(针对TBox)
- 分类(classification)(针对TBox)
- 实例化(materialization)(针对ABox)
(1)可满足性(satisfiability)
本体可满足性
- 检查一个本体是否可满足,即检查该本体是否有模型。如果本体不满足,说明存在不一致。
概念可满足性
- 检查某一概念的可满足性,即检查是否具有模型,使得针对该概念的解释不是空集。
示例: 两个不可满足的例子。
- 第一个本体例子:Man 和 Woman 的交集是空集,那么就不存在同一个本体Allen 既是Man 又是Women。
- 第二个概念例子:概念Eternity是一个空集,那么它不具有模型,即不可满足。

(2)分类(classification)
分类:针对 Tbox 的推理,计算新的概念包含关系。
注意:这里的分类与机器学习中分类不同。
示例:
- 若 Mother 是 Women的子集,Women是 Person的子集,那么就可以得出 Mother是 Person 的子集这个新类别关系。

(3)实例化
实例化:计算属于某个概念或关系的所有实例的集合。
示例:
- 计算新的类实例信息:首先已知 Alice 是Mother,Mother 是 Women的子集,那么可知 Alice 是一个Women。即为Women增加了一个新的实例。

- 计算新的二元关系:已知 Alice 和Bob 有儿子,同时 has_son 是 has_child 的子类,那么可知 Alice 和Bob has_child。

二、本体推理方法与工具介绍
基于本体推理的常见方法:
- 基于Tableaux运算的方法:适用于检查某一本体的可满足性,以及实例检测。
- 基于逻辑编程改写的方法:可以根据特定的场景定制规则,以实现用户自定义的推理过程。
- 基于一阶查询重写的方法:可以高效低结合不同数据格式的数据源,重写方法关联起了不同的查询语言。以Datalog语言为中间语言,首先重写SPARQL语言为Datalog,再将Datalog重写为SQL查询;
- 基于产生式规则的方法:可以按照一定机制执行规则从而达到某些目标,与一阶逻辑类似,也有区别;
下面对上面的几种方法做详细介绍。
1、基于Tableaux运算的方法
(1)概述
基本思想:
- 通过一系列规则构建Abox,以检测可满足性,或者检测某一实例是否存在于某概念。
- 这种思想类似于一阶逻辑的归结反驳。
适用性:检查某一本体的可满足性,以及实例检测。
Tableaux运算规则(以主要DL算子举例):
- 以第一个为例进行说明。第一个是说如果 C C C 和 D D D 的 ( x ) (x) (x) 的合取是 ϕ \phi ϕ,且 C ( x ) C(x) C(x) 和 D ( x ) D(x) D(x) 不在 ϕ \phi ϕ 里,则 ϕ \phi ϕ 有可能只包含了部分 C C C,而 C ( x ) C(x) C(x) 不在里面,那么我们就把它们添加到 ϕ \phi ϕ 里。下面我们举个实际的例子:

(2)示例
示例:检测实例 Allen 是否在 Woman中? 即:检测 W o m a n ( A l l e n ) \mathrm{Woman(Allen)} Woman(Allen) ?
M a n ⊓ W o m a n ⊑ ⊥ \mathrm{Man}\sqcap\mathrm{Woman}\sqsubseteq\bot Man⊓Woman⊑⊥
M a n ( A l l e n ) \mathrm{Man(Allen)} Man(Allen)
其解决流程为:

-
首先加入带反驳的结论:
M a n ⊓ W o m a n ⊑ ⊥ \mathrm{Man}\sqcap\mathrm{Woman}\sqsubseteq\bot Man⊓Woman⊑⊥
M a n ( A l l e n ) \mathrm{Man(Allen)} Man(Allen)
W o m a n ( A l l e n ) \mathrm{Woman(Allen)} Woman(Allen) -
初始Abox,记为 ϕ \phi ϕ,其内包含 M a n ( A l l e n ) \mathrm{Man(Allen)} Man(Allen)、 W o m a n ( A l l e n ) \mathrm{Woman(Allen)} Woman(Allen)。
-
运用 ⊓ − \sqcap^- ⊓− 规则,得到 M a n ⊓ W o m e n ( A l l e n ) \mathrm{Man}\sqcap \mathrm{Women(Allen)} Man⊓Women(Allen)。将其加入到 ϕ \phi ϕ 中,
现在的 ϕ \phi ϕ 为 M a n ( A l l e n ) W o m a n ( A l l e n ) M a n ⊓ W o m e n ( A l l e n ) \mathrm{Man(Allen)} \ \ \ \mathrm{Woman(Allen)} \ \ \ \ \mathrm{Man}\sqcap \mathrm{Women(Allen)} Man(Allen) Woman(Allen) Man⊓Women(Allen)。 -
运用 ⊑ \sqsubseteq ⊑ 规则到 M a n ⊓ W o m e n ( A l l e n ) \mathrm{Man}\sqcap \mathrm{Women(Allen)} Man⊓Women(Allen) 与 M a n ⊓ W o m e n ⊑ ⊥ \mathrm{Man}\sqcap \mathrm{Women}\sqsubseteq\bot Man⊓Women⊑⊥ 上,得到 ⊥ A l l e n \bot\mathrm{Allen} ⊥Allen。
此时的 ϕ \phi ϕ 包含 M a n ( A l l e n ) W o m a n ( A l l e n ) M a n ⊓ W o m e n ( A l l e n ) ⊥ A l l e n \mathrm{Man(Allen)} \ \ \ \mathrm{Woman(Allen)} \ \ \ \ \mathrm{Man}\sqcap \mathrm{Women(Allen)}\ \ \ \ \bot\mathrm{Allen} Man(Allen) Woman(Allen) Man⊓Women(Allen) ⊥Allen。 -
运用 ⊥ \bot ⊥ 规则,拒绝现在的 ϕ \phi ϕ 。
-
得出 Allen 不在 Woman 的结论。如果 W o m a n ( A l l e n ) \mathrm{Woman(Allen)} Woman(Allen) 在初始情况已存在于原始本体,那么推导出该本体不可满足!
正确性:基于Herbrand模型,Herbrand模型可以把它简单的理解为所有可满足模型的最小模型,具体的可以参考逻辑方面的书籍。
(3)相关工具介绍
| 工具名称 | 支持本体语言 | 编程语言 | 算法 |
|---|---|---|---|
| FaCT++ | OWL DL | C++ | tableau-based |
| Racer | OWL DL | Common Lisp | tableau-based |
| Pellet | OWL DL | Java | tableau-based |
| HermiT | OWL 2 Profiles | Java | tableau-based |
2、基于逻辑编程改写的方法
(1)概述
本体推理的局限性:
- 仅支持预定义的本体公理上的推理,无法针对自定义的词汇支持灵活推理;
- 用户无法定义自己的推理过程。
解决方法:引入规则推理
- 它可以根据特定的场景定制规则,以实现用户自定义的推理过程。
- Datalog语言可以结合本体推理和规则推理
(2)Datalog语言推理
Datalog语言
- 面向知识库和数据库设计的逻辑语言,表达能力与OWL相当,支持递归;
- 便于撰写规则,实现推理。
Datalog的语法:
- 原子(Atom)
- 形式: p ( t 1 , t 2 , . . . , t n ) p(t_1,t_2,...,t_n) p(t1,t2,...,tn),其中 p p p 是谓词, n n n 是目数, t i t_i ti 是项 (变量或常量),
- 例如: h a s _ c h i l d ( X , Y ) \mathrm{has\_child(X, Y)} has_child(X,Y);
- 规则(Rule)
- 形式: H : − B 1 , B 2 , … , B m . H:−B_1,B_2,…,B_m. H:−B1,B2,…,Bm.,由原子构建,其中 H H H 是头部原子, B 1 , B 2 , … , B m B_1,B_2,…,B_m B1,B2,…,Bm 是体部原子。
- 例如: h a s _ c h i l d ( X , Y ) : − h a s _ s o n ( X , Y ) . \mathrm{has\_child(X,Y):−has\_son(X, Y).} has_child(X,Y):−has_son(X,Y).
- 事实(Fact):
- 形式: F ( c 1 , c 2 , … , c n ) : − F ( c 1 , c 2 , … , c n ) : − F(c_1,c_2,…,c_n):−F(c_1,c_2,…,c_n):− F(c1,c2,…,cn):−F(c1,c2,…,cn):−,它是没有体部且没有变量的规则,
- 例如: h a s _ c h i l d ( A l i c e , B o b ) : − \mathrm{has\_child(Alice,Bob):−} has_child(Alice,Bob):−
- Datalog程序是规则的集合
- 示例:
h a s _ c h i l d ( X , Y ) : − h a s _ s o n ( X , Y ) . h a s _ c h i l d ( A l i c e , B o b ) : − \mathrm{has\_child(X,Y):−has\_son(X, Y).} \\ \mathrm{has\_child(Alice,Bob):−} has_child(X,Y):−has_son(X,Y).has_child(Alice,Bob):−
- 示例:
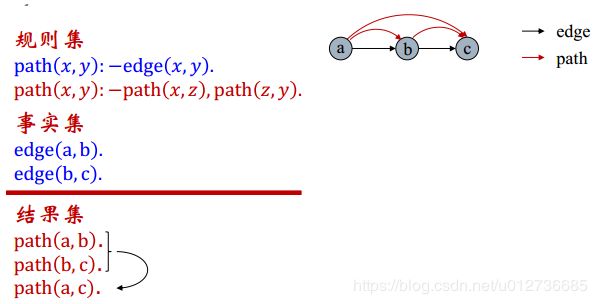
Datalog 推理的示例:
(3)相关工具简介
| 工具名称 | 支持本体语言 | 实现编程语言 | 支持编程语言 |
|---|---|---|---|
| KAON2 | OWL DL/SWRL | Java | Java |
| RDFox | OWL 2 RL | C++ | Java/C++/Python |
3、基于一阶查询重写的方法
(1)概述
查询重写的目的:
- 高效地结合不同数据格式的数据源;
- 重写方法关联起了不同的查询语言。
一阶查询:具有一阶逻辑形式的语言
- 原因:Datalog是数据库的一种查询语言,同时具有一阶逻辑形式。
==》针对本体基于一阶查询进行重写 - 可以以 Datalog 为中间语言,首先重写 SPARQL 语言为 Datalog ,再将 Datalog 重写为 SQL。
S P A R Q L → D a t a l o g → S Q L \mathrm{SPARQL→Datalog→SQL} SPARQL→Datalog→SQL
基本流程:

(2)示例
Q: 给定如下本体,查询所有研究人员及其所从事的项目?
用 SPARQL 表示为:
SELECT ?r ?p
WHERE {
?r exp:worksFor ?p .
?p rdf:type exp:Project
}
给定Datalog 规则如下:
C o o r d i n a t o r ⊑ R e s e a r c h e r ∃ w o r k F o r ⊑ R e s e a r c h e r ∃ w o r k F o r − ⊑ P r o j e c t R e s e a r c h e r ⊑ ∃ w o r k F o r P r o j e c t ⊑ ∃ w o r k F o r − ∃ n a m e − ⊑ x s d : S t r i n g R e s e a r c h e r ⊑ ∃ n a m e P r o j e c t ⊑ ∃ n a m e \begin{aligned} \mathrm{Coordinator} \sqsubseteq & \mathrm{Researcher} \\ \exists\mathrm{workFor} \sqsubseteq & \mathrm{Researcher} \\ \exists\mathrm{workFor-} \sqsubseteq & \mathrm{Project} \\ \mathrm{Researcher} \sqsubseteq & \exists\mathrm{workFor} \\ \mathrm{Project} \sqsubseteq & \exists\mathrm{workFor-} \\ \exists\mathrm{name-} \sqsubseteq &\mathrm{xsd:String} \\ \mathrm{Researcher} \sqsubseteq & \exists\mathrm{name} \\ \mathrm{Project} \sqsubseteq & \exists\mathrm{name} \end{aligned} Coordinator⊑∃workFor⊑∃workFor−⊑Researcher⊑Project⊑∃name−⊑Researcher⊑Project⊑ResearcherResearcherProject∃workFor∃workFor−xsd:String∃name∃name
底层数据具体为某数据库中为下图中的两张表:

步骤一: 重写为 Datalog 查询
- 过滤不需要的公理 (通过语法层过滤)

- 生成所有相关的 Datalog 查询
q ( x ) ← w o r k s F o r ( x , y ) , P r o j e c t ( y ) q ( x ) ← w o r k s F o r ( x , y ) , w o r k s F o r ( , y ) q ( x ) ← w o r k s F o r ( x , _ ) q ( x ) ← R e s e a r c h e r ( x ) q ( x ) ← C o o r d i n a t o r ( x ) \begin{aligned} \mathrm{q(x)} \leftarrow & \mathrm{worksFor(x,y),Project(y)} \\ \mathrm{q(x)} \leftarrow & \mathrm{worksFor(x,y),worksFor(_,y)} \\ \mathrm{q(x)} \leftarrow & \mathrm{worksFor(x,\_)} \\ \mathrm{q(x)} \leftarrow & \mathrm{Researcher(x)} \\ \mathrm{q(x)} \leftarrow & \mathrm{Coordinator(x)} \end{aligned} q(x)←q(x)←q(x)←q(x)←q(x)←worksFor(x,y),Project(y)worksFor(x,y),worksFor(,y)worksFor(x,_)Researcher(x)Coordinator(x)
步骤二: 将数据库关系表达式映射成 Datalog 原子

- 步骤三:将从SPARQL以及数据库重写过来的 Datalog 规则整合进行查询


(3)Ontop 工具
Ontop 工具
- 最先进的OBDA 系统,兼容RDFs、OWL 2 QL、R2RML、SPARQL标准
- 支持主流关系数据库: Oracle、MySQL、SQL Server、Postgres
4、基于产生式规则的方法
(1)产生式系统组成
产生式系统
- 定义:一种前向推理系统,可以按照一定机制执行规则从而达到某些目标,与一阶逻辑类似,但也有区别。
- 应用:自动规划、专家系统上。
产生式系统的 组成:
- 事实集合(Working Memory)
- 产生式/规则集合
- 推理引擎组成:
1. 事实集/运行内存(Working Memory, WM)
- 定义:事实(WME)的集合,用于存储当前系统中所有事实。
- 事实(Working Memory Element, WME):包含描述对象和描述关系。
- 描述对象:
- 形如: ( t y p e a t t r 1 : v a l 1 a t t r 2 : v a l 2 . . . a t t r n : v a l n ) \mathrm{(type\ attr_1:val_1\ attr_2:val_2...attr_n:val_n)} (type attr1:val1 attr2:val2...attrn:valn),其中 t y p e a t t r i v a l i \mathrm{type\ attr_i\ val_i} type attri vali 均为原子 (常量);
- 示例:
(student name:Alice age:24)。
- 描述关系(Refication):
- 例如: ( b a s i c F a c t r e l a t i o n : o l d e r T h a n f i r s t A r g : J o h n s e c o n d A r g : A l i c e ) \mathrm{(basicFact\ relation:olderThan\ firstArg:John\ secondArg:Alice)} (basicFact relation:olderThan firstArg:John secondArg:Alice) 简记为 ( o l d e r T h a n J o h n A l i c e ) \mathrm{(olderThan John Alice)} (olderThanJohnAlice)。
- 描述对象:
2. 产生式集合(Production Memory, PM)
- 定义:产生式的集合。
- 产生式:
- I F c o n d i t i o n s T H E N a c t i o n s \mathrm{IF} \ \ \color{red}{conditions} \ \ \color{black}{\mathrm{THEN}} \ \ \color{red}{actions} IF conditions THEN actions
conditions是由条件组成的集合,又称为 LHS。actions是由动作组成的序列,称为 RHS 。
- LHS
- 定义:条件(condition)的集合,各条件之间是 且 的关系,当 LHS 中所有条件均被满足,则该规则触发。
- 条件的形式为: ( t y p e a t t r 1 : s p e c 1 a t t r 2 : s p e c 2 . . . a t t r n : s p e c n ) \mathrm{(type\ \ attr_1:spec_1\ \ attr_2:spec_2...attr_n:spec_n)} (type attr1:spec1 attr2:spec2...attrn:specn)
- 其中 s p e c i \mathrm{spec_i} speci 表示对 a t t r i \mathrm{attr_i} attri 的约束,形式可取如下的一种:
- 原子,如:Alice ( p e r s o n n a m e : A l i c e ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (\mathrm{person\ name:Alice}) (person name:Alice)
- 变量,如: x x x ( p e r s o n n a m e : x ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ (\mathrm{person\ name:}x) (person name:x)
- 表达式,如: [ n + 4 ] [n+4] [n+4] ( p e r s o n a g e : [ n + 4 ] ) \ \ \ \ \ \ \ \ \ \ \ (\mathrm{person\ age:}[n+4]) (person age:[n+4])
- 布尔测试,如: { > 10 } \{>10\} {>10} ( p e r s o n a g e : [ > 10 ] ) \ \ \ \ \ \ \ \ (\mathrm{person\ age:}[>10]) (person age:[>10])
- 约束的 与、或、非 操作
- 其中 s p e c i \mathrm{spec_i} speci 表示对 a t t r i \mathrm{attr_i} attri 的约束,形式可取如下的一种:
- RHS
- 定义:动作序列,即执行时的顺序,是依次执行的;
- 动作的种类包含:
- A D D p a t t e r n \mathrm{ADD}\ \ pattern ADD pattern:向WM中加入形如pattern的WME。
- R E M O V E i \mathrm{REMOVE}\ \ i REMOVE i:从WM中移除当前规则第 i i i 个条件匹配的 WME。
- M O D I F Y i ( a t t r s p e c ) \mathrm{MODIFY }\ \ i\ \ (attr\ spec) MODIFY i (attr spec):对于当前规则第 i i i 个条件匹配的 WME,将其对应于 a t t r attr attr 属性的值改为 s p e c spec spec。
- 示例:若有一个学生名为 ? x ?x ?x,则向事实集中加入一个事实,表示有一个名为 ? x ?x ?x 的人。
- I F ( S t u d e n t n a m e : x ) T h e n A D D ( P e r s o n n a m e : x ) \mathrm{IF\ (Student\ name:}x) \mathrm{\ Then\ ADD\ (Person\ name:}x) IF (Student name:x) Then ADD (Person name:x) 也可写作 ( S t u d e n t n a m e : x ) ⇒ A D D ( P e r s o n n a m e : x ) \mathrm{(Student\ name:}x) \Rightarrow \mathrm{ADD\ (Person\ name:}x) (Student name:x)⇒ADD (Person name:x)
3. 推理引擎(核心步骤):
- 作用:可以控制系统的执行;
- 包含(下节重点说明):
- 模式匹配:用规则的条件部分匹配事实集中的事实,整个LHS都被满足的规则被触发,并被加入议程(agenda);
- 解决冲突:按一定的策略从被触发的多条规则中选择一条;
- 执行动作:执行被选择出来的规则的RHS,从而对WM进行一定的操作。
(2)产生式系统执行
产生式系统的执行流程:
- 下图的 WM 和产生式集合是我们定义的数据,相当于ABox 和 TBox,中间部分是推理引擎。其实大部分推理系统都是由这三部分组成。

模式匹配:用每条规则的条件部分匹配当前WM。
-
RETE算法——高效的模式匹配算法(空间换时间)
- 1979年由Charles Forgy (CMU)提出;
- 思路:将产生式的LHS组织成判别网络形式;
- 流程:

-
冲突解决:从被触发的多条规则中选择一条
- 常见策略:
-
随机选择:从被触发的规则中随机选择一条执行;
- 注意:在推理场景下,被触发的多条规则可全被执行;
-
具体性(specificity):选择最具体的规则;
-
示例:
( S t u d e n t n a m e : x ) ⇒ . . . (\mathrm{Student\ name:}x) \Rightarrow ... (Student name:x)⇒...
( S t u d e n t n a m e : x a g e : 20 ) ⇒ . . . (\mathrm{Student\ name:}x\ \mathrm{age}:20) \Rightarrow ... (Student name:x age:20)⇒...
存在上述两条规则时,若根据具体性,则选择第二条
-
-
新近程度(recency):选择最近没有被触发的规则执行动作;
-
- 常见策略:
(3)相关工具介绍
Drools
- 商用规则管理系统,其中提供了一个规则推理引擎;
- 核心算法是基于RETE算法的改进。
- 提供规则定义语言 ,支持嵌入Java代码。
Jena
- Jena 用于构建语义网应用 Java 框架,
- 提供了处理 RDF、RDFs、OWL 数据的接口,还提供了一个规则引擎。
- 提供了三元组的内存存储于查询。
RDF4J
- RDF4J 是一个处理 RDF 数据的开源框架,
- 支持语义数据的解析、存储、推理和查询。
- 能够关联几乎所有RDF存储系统,能够用于访问远程RDF存储。
GraphDB(原OWLIM)
- 一个可扩展的语义数据存储系统;
- 包含:三元组存储、推理引擎、查询引擎
- 支持 RDFS、OWL DLP、OWL Horst、OWL 2 RL 推理
对比
