你确定不来了解一下Redis跳跃表的原理吗
为什么选择跳跃表
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树出来吗?很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,还要参考网上的代码,相当麻烦。用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList。
有序表的搜索
考虑一个有序表
 从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉搜索树,我们把一些节点提取出来,作为索引。得到如下结构:
从该有序表中搜索元素 < 23, 43, 59 > ,需要比较的次数分别为 < 2, 4, 6 >,总共比较的次数为 2 + 4 + 6 = 12 次。有没有优化的算法吗? 链表是有序的,但不能使用二分查找。类似二叉搜索树,我们把一些节点提取出来,作为索引。得到如下结构:

这里我们把 < 14, 34, 50, 72 > 提取出来作为一级索引,这样搜索的时候就可以减少比较次数了。我们还可以再从一级索引提取一些元素出来,作为二级索引,变成如下结构:
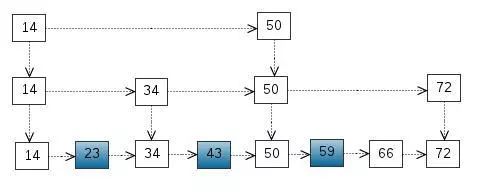
这里元素不多,体现不出优势,如果元素足够多,这种索引结构就能体现出优势来了。
跳跃表
下面的结构是就是跳表:
其中 -1 表示 INT_MIN, 链表的最小值,1 表示 INT_MAX,链表的最大值。

跳表具有如下性质:
(1) 由很多层结构组成
(2) 每一层都是一个有序的链表
(3) 最底层(Level 1)的链表包含所有元素
(4) 如果一个元素出现在 Level i 的链表中,则它在 Level i 之下的链表也都会出现。
(5) 每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
跳表的搜索
 例子:查找元素 117
例子:查找元素 117
(1) 比较 21, 比 21 大,往后面找
(2) 比较 37, 比 37大,比链表最大值小,从 37 的下面一层开始找
(3) 比较 71, 比 71 大,比链表最大值小,从 71 的下面一层开始找
(4) 比较 85, 比 85 大,从后面找
(5) 比较 117, 等于 117, 找到了节点。
跳表的插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)
然后在 Level 1 ... Level K 各个层的链表都插入元素。
例子:插入 119, K = 2

如果 K 大于链表的层数,则要添加新的层。
例子:插入 119, K = 4

跳表的高度
n 个元素的跳表,每个元素插入的时候都要做一次实验,用来决定元素占据的层数 K,跳表的高度等于这 n 次实验中产生的最大 K,待续。。。
跳表的空间复杂度分析
根据上面的分析,每个元素的期望高度为 2, 一个大小为 n 的跳表,其节点数目的期望值是 2n。
跳表的删除
在各个层中找到包含 x 的节点,使用标准的 delete from list 方法删除该节点。
例子:删除 71

好啦,上面我们跳跃表就介绍完了,接下来我们看看 Redis中是如何实现跳跃表的把。我们知道 Redis 中 zset 有序集合底层就使用了跳跃表来存储数据,那么我们就来看看 zset 结构把。老规矩,我看redis 源码都是从命令入手的,那么我们就来看看 zadd 这个命令做了哪些事情把。
在讲 Redis 实现的跳跃表之前我们先讲讲 Redis 有序集合的组成成分吧!
/** * ZSETs use a specialized version of Skiplists * 跳跃表中的数据节点 */typedef struct zskiplistNode { sds ele; double score; // 后退指针 struct zskiplistNode *backward; // 层 struct zskiplistLevel { // 前进指针 struct zskiplistNode *forward; /** * 跨度实际上是用来计算元素排名(rank)的, * 在查找某个节点的过程中,将沿途访过的所有层的跨度累积起来, * 得到的结果就是目标节点在跳跃表中的排位 */ unsigned long span; } level[];} zskiplistNode;/** * 跳跃表结构体 */typedef struct zskiplist { struct zskiplistNode *header, *tail; unsigned long length; int level;} zskiplist;/** * 有序集合结构体 */typedef struct zset { /* * Redis 会将跳跃表中所有的元素和分值组成 * key-value 的形式保存在字典中 * todo:注意:该字典并不是 Redis DB 中的字典,只属于有序集合 */ dict *dict; /* * 底层指向的跳跃表的指针 */ zskiplist *zsl;} zset;zadd 命令(添加元素)
之所以从 zadd 入手,是因为我们一开始使用 zadd 添加有序集合的时候,该有序集合是不存在的,redis 需要先创建一个有序集合,这样我们才能从源头开始看起,那么我们就来看看 zaddCommand 方法的实现把。
/** * 往有序集合中添加元素 * * @param c 客户端数据 */void zaddCommand(client *c) { zaddGenericCommand(c, ZADD_NONE);}由上可知,底层还是调用的 zaddGenericCommand() 这个方法,我们继续往下看
void zaddGenericCommand(client *c, int flags) { // 先忽略一些干扰代码 ... /* 从字典中查找该有序集合是否存在,如果不存在则创建 */ zobj = lookupKeyWrite(c->db, key); if (zobj == NULL) { if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */ // 如果配置文件中关闭了 ziplist 结构存储,则直接创建用跳跃表存储的有序集合 if (server.zset_max_ziplist_entries == 0 || server.zset_max_ziplist_value < sdslen(c->argv[scoreidx + 1]->ptr)) { zobj = createZsetObject(); } else { // 从这里我们可以看出底层有序集合一开始是使用 ziplist 存储元素的,ziplist 下次再说 zobj = createZsetZiplistObject(); } // 往字典里面保存我们新创建的 有序集合 dbAdd(c->db, key, zobj); } else { // 不是有序集合的结构报错 ... } for (j = 0; j < elements; j++) { double newscore; score = scores[j]; int retflags = flags; ele = c->argv[scoreidx + 1 + j * 2]->ptr; // 在这里我们终于看到了往 zset 里面添加元素的代码了 int retval = zsetAdd(zobj, score, ele, &retflags, &newscore); ... } ...}调用链很长,还是要大家耐着性子继续往下看!
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) { // 忽略干扰代码 ... /* 编码格式是 ziplist */ if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { // 往 ziplist压缩列表中添加元素 ... } else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) { // 往跳跃表中添加元素 zset *zs = zobj->ptr; zskiplistNode *znode; dictEntry *de; // todo: 在字典中查找指定元素的,注意这个字典是 zset 结构体中的字典结构 de = dictFind(zs->dict, ele); if (de != NULL) { // 如果开启了 NX 模式,且元素已经在有序集合中存在,则直接返回 /* NX? Return, same element already exists. */ if (nx) { *flags |= ZADD_NOP; return 1; } // 获取字典中的有序集合中元素的分值 curscore = *(double *) dictGetVal(de); /* 如果需要,准备增量的分数。*/ if (incr) { // 增量分值 score += curscore; if (isnan(score)) { *flags |= ZADD_NAN; return 0; } if (newscore) *newscore = score; } /* 分数变化时删除并重新插入。*/ if (score != curscore) { ... // 将元素和分值重新插入到跳跃表中 znode = zslInsert(zs->zsl, score, node->ele); // 释放 node 节点,因为我们可以重用 zslInsert 返回的 znode 节点,节省内存空间 node->ele = NULL; zslFreeNode(node); // 删除干扰代码 ... } return 1; } else if (!xx) {// 非 仅在元素已存在时才执行操作 // 将有序集合中的元素复制一遍 ele = sdsdup(ele); // 直接插入元素 znode = zslInsert(zs->zsl, score, ele); // 将有序集合中的元素和 score 组成 key-value 存储在 zset 结构体中的字典当中 serverAssert(dictAdd(zs->dict, ele, &znode->score) == DICT_OK); ... } else { ... } } else { serverPanic("Unknown sorted set encoding"); } return 0; /* Never reached. */}大家耐着性子看到这里有没有点小激动,因为我们马上就要看到跳跃表是如何添加元素了,废话少说,撸代码。
zrem 命令(删除元素)
看完添加元素的方法,我们再来看看 redis 是如何删除元素的。
void zremCommand(client *c) { // 有序集合不存在则直接返回 ... // 我们知道 zrem 可以一次性删除多个元素,这里我们看到 redis 是循环删除元素的 for (j = 2; j < c->argc; j++) { // 删除指定元素 if (zsetDel(zobj, c->argv[j]->ptr)) deleted++; // 如果集合中没有元素了,则直接将该有序集合从字典中移除 if (zsetLength(zobj) == 0) { dbDelete(c->db, key); keyremoved = 1; break; } } // 删除干扰代码 ...}和刚刚添加方法一样,又调用了其他的删除方法,继续往下看。
int zsetDel(robj *zobj, sds ele) { // 如果编码格式是 ziplist 则从 ziplist 中删除元素 if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { ... } else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {// 编码格式是跳跃表 zset *zs = zobj->ptr; dictEntry *de; double score; // 在字典中解除该元素节点,但是并没有释放该节点的内存,会在下面的 skiplist 释放 de = dictUnlink(zs->dict, ele); if (de != NULL) { /* Get the score in order to delete from the skiplist later. */ score = *(double *) dictGetVal(de); /* 我们知道有序集合中会将 元素和分值构造成 entry 存储在 字典中,所以要释放 entry */ dictFreeUnlinkedEntry(zs->dict, de); /* 在跳跃表中释放元素 */ int retval = zslDelete(zs->zsl, score, ele, NULL); serverAssert(retval); if (htNeedsResize(zs->dict)) dictResize(zs->dict); return 1; } } else { serverPanic("Unknown sorted set encoding"); } return 0; /* No such element found. */}代码进行到这里,我们应该也能猜到 zslDelete 方法里面到底做了哪些操作吧!来,我们来猜一猜。
首先要在跳跃表中定位到要删除的元素吧
我们知道该节点每一层都有前驱、后继指针,那么我们删除这个节点的时候,自然也要改变该节点的每一层节点指针的指向啦。
我们知道 redis 跳跃表中还有跨度的概念,该节点没了,那么肯定要改变相关节点的跨度
我们还知道跳跃表是有序的,有个 rank 排名的概念,删除了一个节点,后面的节点排名肯定也要做相应的改变咯。
节点删除了,最后肯定就是释放该节点空间呗。
上面我们分析完了,实际是不是和我们预估的一样呢,我们看看代码吧
/* * Internal function used by zslDelete, zslDeleteByScore and zslDeleteByRank * 该方法会修改跳跃表中的跨度 * * zslDelete,zslDeleteByScore和zslDeleteByRank 使用的内部函数 */void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) { int i; for (i = 0; i < zsl->level; i++) { if (update[i]->level[i].forward == x) { update[i]->level[i].span += x->level[i].span - 1; update[i]->level[i].forward = x->level[i].forward; } else { // 计算跨度 update[i]->level[i].span -= 1; } } if (x->level[0].forward) { x->level[0].forward->backward = x->backward; } else { zsl->tail = x->backward; } while (zsl->level > 1 && zsl->header->level[zsl->level - 1].forward == NULL) zsl->level--; zsl->length--;}zscore 命令(获取元素分值)
我们可以想想获取某个值的分值,在跳跃表中我们是不是要先在跳跃表中找到指定节点然后再获取该节点的分值吗?带着这个疑问我们看看源码吧!
/** * zscore 获取分值 * @param c */void zscoreCommand(client *c) { robj *key = c->argv[1]; robj *zobj; double score; // 如果在字典中找不到该有序集合或者元素类型不是 OBJ_ZSET,直接返回 if ((zobj = lookupKeyReadOrReply(c, key, shared.nullbulk)) == NULL || checkType(c, zobj, OBJ_ZSET)) return; // 获取分值 if (zsetScore(zobj, c->argv[2]->ptr, &score) == C_ERR) { addReply(c, shared.nullbulk); } else { addReplyDouble(c, score); }}从上面我们可以看到,分值的获取实际是通过 zsetScore 方法获取的。
int zsetScore(robj *zobj, sds member, double *score) { if (!zobj || !member) return C_ERR; // 如果编码格式压缩链表 if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { if (zzlFind(zobj->ptr, member, score) == NULL) return C_ERR; } else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {// 编码格式是跳跃表 zset *zs = zobj->ptr; // 直接从 zset 中的字典获取指定的 dictEntry dictEntry *de = dictFind(zs->dict, member); if (de == NULL) return C_ERR; // 从 dictEntry 中获取 score *score = *(double *) dictGetVal(de); } else { serverPanic("Unknown sorted set encoding"); } return C_OK;}zrank 命令(获取某个元素的排名)
当我们想获取有序集合中某个元素的排名时,zrank 命令是我们很好的选择,zrank 命令返回有序集 key 中成员 member 的排名。其中有序集成员按 score 值递增(从小到大)顺序排列。排名以 0 为底,也就是说, score 值最小的成员排名为 0 。下面我们看看他里面具体实现吧!
long zsetRank(robj *zobj, sds ele, int reverse) { unsigned long llen; unsigned long rank; llen = zsetLength(zobj); if (zobj->encoding == OBJ_ENCODING_ZIPLIST) { // 压缩链表 rank 计算方式 ... } else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) { zset *zs = zobj->ptr; zskiplist *zsl = zs->zsl; dictEntry *de; double score; // 从 zset 中的字典中直接拿到指定元素 dictEntry de = dictFind(zs->dict, ele); if (de != NULL) { score = *(double *) dictGetVal(de); rank = zslGetRank(zsl, score, ele); /* Existing elements always have a rank. */ serverAssert(rank != 0); if (reverse) return llen - rank; else return rank - 1; } else { return -1; } } else { serverPanic("Unknown sorted set encoding"); }}接下来就是真正 rank 计算的方法咯,不要分心,专心看。
unsigned long zslGetRank(zskiplist *zsl, double score, sds ele) { zskiplistNode *x; unsigned long rank = 0; int i; x = zsl->header; // 这里从最上层开始查找节点元素的排名 for (i = zsl->level - 1; i >= 0; i--) { while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && sdscmp(x->level[i].forward->ele, ele) <= 0))) { rank += x->level[i].span; x = x->level[i].forward; } /* x might be equal to zsl->header, so test if obj is non-NULL */ if (x->ele && sdscmp(x->ele, ele) == 0) { return rank; } } return 0;}好啦,到这里 Redis 中跳跃表的实现大概讲完了。
— THE END —

猜你喜欢:
◤半年文章精选系列◥
Flink从入门到放弃之源码解析系列
《Flink组件和逻辑计划》
《Flink执行计划生成》
《JobManager中的基本组件(1)》
《JobManager中的基本组件(2)》
《JobManager中的基本组件(3)》
《TaskManager》
《算子》
《网络》
《水印WaterMark》
《CheckPoint》
《任务调度及负载均衡》
《异常处理》
大数据成神之路-基础篇
《HashSet》
《HashMap》
《LinkedList》
《ArrayList/Vector》
《ConcurrentSkipListMap》
《ConcurrentHashMap1.7》
《ConcurrentHashMap1.8 Part1》
《ConcurrentHashMap1.8 Part2》
《CopyOnWriteArrayList》
《CopyOnWriteArraySet》
《ConcurrentLinkedQueue》
《LinkedBlockingDeque》
《LinkedBlockingQueue》
《ArrayBlockingQueue》
《ConcurrentSkipListSet》
大数据成神之路-进阶篇
《JVM&NIO基础入门》
《分布式理论基础和原理》
《分布式中的常见问题解决方案(分布式锁/事务/ID)》
《Zookeeper》
《RPC》
《Netty入门篇》
《Netty源码篇》
《Linux基础》
Flink入门系列
《Flink入门》
《Flink DataSet&DataSteam API》
《Flink集群部署》
《Flink重启策略》
《Flink分布式缓存》
《Flink广播变量》
《Flink中的Time》
《Flink中的窗口》
《时间戳和水印》
《Broadcast广播变量》
《Flink-Kafka-Connector》
《Flink之Table-&-SQL》
《Flink实战项目之实时热销排行》
《Flink-Redis-Sink》
《Flink消费Kafka写入Mysql》
Flink高级进阶
《FaultTolerance》
《流表对偶(duality)性》
《持续查询(ContinuousQueries)》
《DataStream-Connectors之Kafka》
《SQL概览》
《JOIN 算子》
《TableAPI》
《JOIN-LATERAL》
《JOIN-LATERAL-Time Interval(Time-windowed)》
《Temporal-Table-JOIN》
《State》
《FlinkSQL中的回退更新-Retraction》
《Apache Flink结合Apache Kafka实现端到端的一致性语义》
《Flink1.8.0发布!新功能抢先看》
《Flink1.8.0重大更新-Flink中State的自动清除详解》
《Flink在滴滴出行的应用与实践》
《批流统一计算引擎的动力源泉—Flink Shuffle机制的重构与优化》
《HBase分享 | Flink+HBase场景化解决方案》
《腾讯基于Flink的实时流计算平台演进之路》
《Flink进阶-Flink CEP(复杂事件处理)》
《Flink基于EventTime和WaterMark处理乱序事件和晚到的数据》
《Flink 最锋利的武器:Flink SQL 入门和实战》
《Flink Back Pressure》
《使用Flink读取Kafka中的消息》
《Flink on YARN部署快速入门指南》
《Apache Flink状态管理和容错机制介绍》
Hadoop生态圈系列
《Hadoop极简入门》
《MapReduce编程模型和计算框架架构原理》
《分布式文件系统-HDFS》
《YARN》
《Hadoop机架感知》
《HDFS的一个重要知识点-HDFS的数据流》
《Hadoop分布式缓存(DistributedCache)》
《如何从根源上解决 HDFS 小文件问题》(https://dwz.cn/FqDPpRUc)
《Hadoop解决小文件存储思路》(https://dwz.cn/2oCdmCkw)
《Hadoop所支持的几种压缩格式》
《MapReduce Join》
《YARN Capacity Scheduler(容量调度器)》
《hadoop上搭建hive》
《基于Hadoop的数据仓库Hive基础知识》
《Hive使用必知必会系列》
《一个小知识点-Hive行转列实现Pivot》
《面试必备技能-HiveSQL优化》
《HBase和Hive的区别和各自适用的场景》
《一篇文章入门Hbase》
《敲黑板:HBase的RowKey设计》
《HBase读写优化》
《HBase在滴滴出行的应用场景和最佳实践》
《Phoenix=HBase+SQL,让HBase插上了翅膀》
《一个知识点将你拒之门外之Hbase的二级索引》(https://dwz.cn/umfBOZ5l)
《Phoenix重磅 | Phoenix核心功能原理及应用场景介绍》
《DB、DW、DM、ODS、OLAP、OLTP和BI的概念理解》
《Hive/HiveSQL常用优化方法全面总结》
实时计算系列(spark、kafka等)
《Spark Streaming消费Kafka数据的两种方案》
《Apache Kafka简单入门》
《你不得不知道的知识-零拷贝》
《Kafka在字节跳动的实践和灾备方案》
《万字长文干货 | Kafka 事务性之幂等性实现》
《Kafka最佳实践》
《Kafka Exactly-Once 之事务性实现》
《Kafka连接器深度解读之错误处理和死信队列》
《Spark之数据倾斜调优》
《Structured Streaming 实现思路与实现概述》
《Spark内存调优》
《广告点击数实时统计:Spark StructuredStreaming + Redis Streams》
《Spark Shuffle在网易的优化》
《SparkSQL极简入门》
《下一代分布式消息队列Apache Pulsar》
《Pulsar与Kafka消费模型对比》
《Spark SQL重点知识总结》
《Structured Streaming 之状态存储解析》
《周期性清除Spark Streaming流状态的方法》
《Spark Structured Streaming特性介绍》
《Spark Streaming 反压(Back Pressure)机制介绍》
《Spark 从 Kafka 读数设置子并发度问题》
规范和系统设计
《阿里云10 PB+/天的日志系统设计和实现》
《阿里云Redis开发规范》
《Java中多个ifelse语句的替代设计》
《面试系列:十个海量数据处理方法大总结》
杂谈
《作为面试官的一点点感悟,谈谈技术人的成长之路》
《成年人的世界没有容易二字》
《我最近在关注的事》
《真香》
《简单说说学习这件事》
《20多岁做什么,将来才不会后悔》
《2019-05-12最近的总结》
《我军新闻联播气势+9999》
《周末分享 | 高手的战略》
《周末分享 | 快速定位自己的缺点》
《周末分享 | 我见过最高级的聪明是靠谱》