【AI视野·今日CV 计算机视觉论文速览 第152期】Fri, 9 Aug 2019
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 9 Aug 2019
Totally 31 papers
?上期速览✈更多精彩请移步主页

Interesting:
?***VOMonodepth/VOPyD-Net利用视觉里程计提升的单目深度估计, 基于单目深度估计的方法需要大量昂贵的标记数据,这篇文章中研究人员将已有的几何先验方法集成到自监督网络中,提出了一种稀疏不变性的自编码器架构,可以有效处理传统传统视觉里程计算法的输出,并将这些输出用于增强网络估计出深度的结果。(from Univrses AB)
利用双目相机,首先利用视觉里程计得到稀疏的深度SD,随后将他们馈入到稀疏自编码中得到较为稠密的结果DD,再将它们和RGB信息传入主网络中。自监督的信号来自于网络后蓝色和绿色的框框,其中蓝色框框中计算出立体重投影连续性,绿色框里得到图像的光度连续性,以及橙色和紫色线条表示的稠密深度图上原始稀疏点的深度信息。
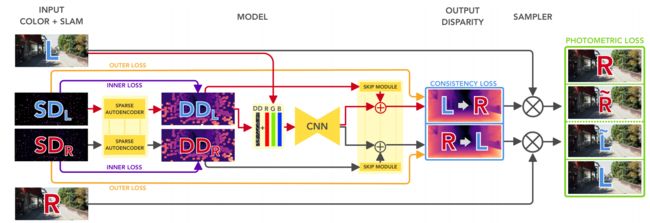
下图为模型中提出的具有稀疏不变性的卷积模型:

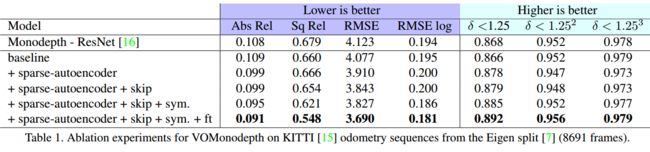
在KITTI数据集上的比较结果,可以看到稀疏自编码器,跳接层、对称训练和调优带来的性能增长(part4.3):
最终得到的结果,从RGB图像到稀疏图,较半稠密图再到最终的深度图输出。:

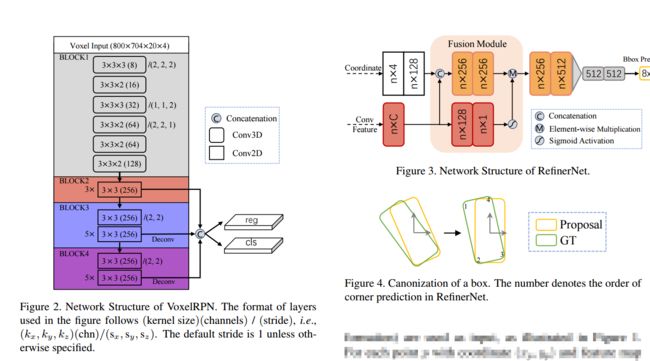
?Fast Point R-CNN三维点云快速目标检测方法, 研究人员提出了一种统一、高效、有效的点云目标检测网络。这个网络包含两个阶段,充分使用体素表示和原始点云数据来结合各自的优势,第一阶段的模型主要用于体素表示的输出,利用轻量级的卷积操作,产生少量高质量的初始预测结果。初始预测结果中的坐标和带序号的点的卷积特征将有效的利用注意力机制融合,保存精确的位置信息和内容信息。第二阶段则在内部点上进行特征融合,进一步优化预测结果。并且能实现15fps的检测速度。(from 香港中文)
模型中包含了两个阶段,首先将体素化的点云馈入VoxelRPN结构,得到初始化预测结果。随后将坐标值特征与卷积特征融合得到每个box的特征,最终将box特征送入优化网络进行最终的结果优化。
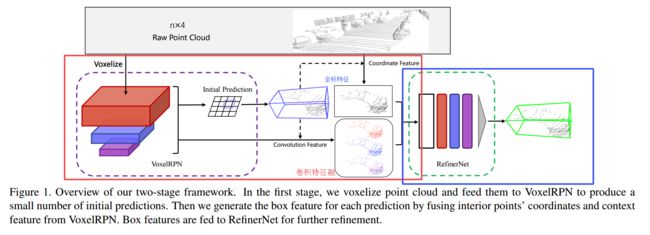
下图显示了触及VoxelRPN的结构以及次级哟花网络的结构,还包括框坐标的计算方式:
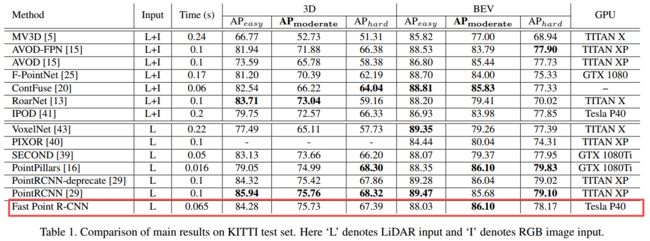
下图显示了与其他方法的比较结果:
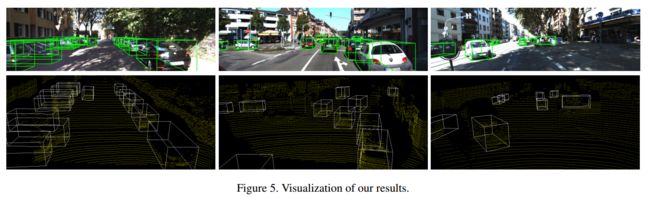
得到的结果如下所示:
?LVIS大规模词汇实例分割数据集, 随着目标检测的发展,从检测到分割的细化,研究人员提出了一个更为细粒度的词汇级分割数据集LVIS,包含了164k张图像,超过一千类约两百万个高质量的实例分割mask的数据集,Zipfian分布自然包含了长尾的分类。(from facebook FAIR)

图像中的标注实例,每张图像中的每一类物体分别标注,图中只显示了一类物体:
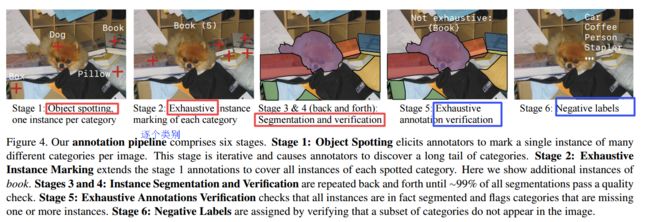
图像标注的流程方法:
project:http://www.lvisdataset.org/
ref:COCO [18] ,ADE20K [28] ,iNaturalist [26] ,Open Images v4 [14]
Daily Computer Vision Papers
| +基于Unet的器官三维分割模型Multi Scale Supervised 3D U-Net for Kidney and Tumor Segmentation Authors Wenshuai Zhao, Zengfeng Zeng U Net在各种医学图像分割挑战中取得了巨大成功。当使用最优超参数时,具有花哨的新结构可能在某些数据集中成功,但是它们的泛化总是得不到保证。在这里,我们专注于基本的U Net架构,并为KiTS19挑战中的分段任务提出了一个多尺度监督3D U Net。为了提高性能,我们的工作首先可以概括为三个部分,我们在解码器路径中使用多尺度监控,这可以鼓励网络从深层次预先判断正确的结果,目的是减轻不良影响。在肾脏和肿瘤的样本不平衡中,我们采用指数对数损失三,设计了基于连通成分的后处理方法去除明显错误的体素。在已发表的KiTS19训练数据集中,共有210名患者,我们将42名患者分为测试数据集,最终获得了肾脏和肿瘤的DICE评分分别为0.969和0.805。在挑战中,我们最终在106支队伍中排名第7位,复合骰子为0.8961,即肾脏为0.9741,肿瘤为0.8181。 |
| ++大规模词汇实例数据集LVIS: A Dataset for Large Vocabulary Instance Segmentation Authors Agrim Gupta, Piotr Doll r, Ross Girshick 数据集实现了对象检测的进展,这些数据集将研究团队的注意力集中在开放式挑战上。这个过程使我们从简单的图像到复杂的场景,从边界框到分割蒙版。在这项工作中,我们介绍了LVIS发音,用于大词汇量实例分割的新数据集。我们计划为164k图像中的1000多个入门级对象类别收集200万个高质量实例分割掩码。由于Zipfian在自然图像中分类,LVIS自然具有很长的类别,只有很少的训练样本。鉴于最先进的物体检测深度学习方法在低样本制度下表现不佳,我们认为我们的数据集构成了一个重要且令人兴奋的新科学挑战。 LVIS可在http://www.lvisdataset.org/ |
| Dynamic Scale Inference by Entropy Minimization Authors Dequan Wang, Evan Shelhamer, Bruno Olshausen, Trevor Darrell 鉴于视觉世界的多样性,没有一个真正的识别对象尺度可能在整个视野中出现截然不同的尺寸。动态模型不是枚举滤波器通道或金字塔等级的变化,而是在本地预测比例并相应地调整感受野。输入的变化程度和多样性使这成为一项艰巨的任务。现有方法要么学习前馈预测器,它本身并不完全不受它所要反对的尺度变化的影响,要么通过固定算法选择尺度,这不能从给定的任务和数据中学习。我们将动态尺度推断从前馈预测扩展到迭代优化,以进一步提高适应性。我们提出了一种新颖的熵最小化目标,用于推理和优化任务和结构参数,以将模型调整到每个输入。推理期间的优化提高了语义分割的准确性,并且更好地推广到极端尺度变化,这导致前馈动态推断变得不稳定。 |
| ++电影多模态数据集Moviescope: Large-scale Analysis of Movies using Multiple Modalities Authors Paola Cascante Bonilla, Kalpathy Sitaraman, Mengjia Luo, Vicente Ordonez 电影媒体是一种丰富的艺术表现形式。与摄影和短片不同,电影中包含故意复杂而错综复杂的故事情节,以吸引观众。在本文中,我们提出了一项大型研究,比较了视觉,音频,文本和基于元数据的功能的有效性,以预测电影的高级信息,如其类型或估计预算。我们证明了基于内容的方法在这个领域的有用性,与深度学习时代的基于人类和基于元数据的预测相反。此外,我们提供了用于表示视频和文本的时态特征聚合方法的全面研究,并发现简单的池化操作在该领域中是有效的。我们还展示了不同形式在多大程度上相互补充。为此,我们还介绍了Moviescope,这是一部包含5,000部电影的新型大型数据集,其中包含相应的电影预告片视频音频,电影海报图片,电影情节文本和元数据。 |
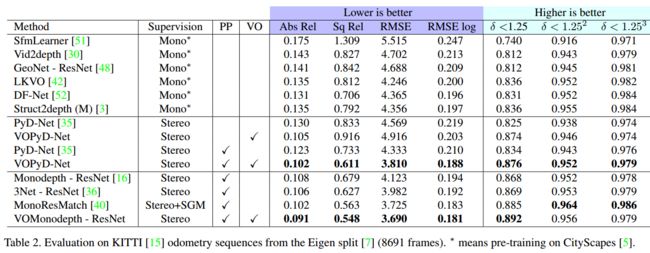
| +++基于视觉里程计提升单目深度估计效果Enhancing self-supervised monocular depth estimationwith traditional visual odometry Authors Lorenzo Andraghetti, Panteleimon Myriokefalitakis, Pier Luigi Dovesi, Belen Luque, Matteo Poggi, Alessandro Pieropan, Stefano Mattoccia 从单个图像估计深度代表了利用多个相机的更传统方法的有吸引力的替代方案。在这一领域,深度学习产生了出色的成果,代价是需要大量的数据标记精确的深度测量进行训练。利用单眼序列或立体对代替昂贵的地面实况深度注释的自我监督方法软化了一个问题。本文通过将现有的自监测网络集成到几何先验中,可以进一步改善单眼深度估计。具体来说,我们提出了一种稀疏性不变自动编码器,能够处理传统视觉测距算法的输出,与单声道网络的深度协同工作。 KITTI数据集的实验结果表明,通过利用几何先验,我们的建议优于文献中的现有方法,并且与单一体系结构的紧凑和复杂深度良好耦合,允许其在高端GPU和嵌入式上的部署设备,例如NVIDIA Jetson TX2。 |
| +++轻量级的肖像分割网络ExtremeC3Net: Extreme Lightweight Portrait Segmentation Networks using Advanced C3-modules Authors Hyojin Park, Lars Lowe Sj sund, YoungJoon Yoo, Nojun Kwak 设计轻量且健壮的纵向分割算法是广泛的面部应用的重要任务。但是,该问题已被视为对象分割问题的子集。显然,肖像分割有其独特的要求。首先,因为纵向分割是在许多真实世界应用程序的整个过程的中间执行的,所以它需要非常轻量级的模型。其次,该域中没有任何公共数据集包含足够数量的具有无偏统计的图像。为了解决这些问题,我们引入了一种新的极其轻量级的肖像分割模型,该模型由基于集中的综合卷积块的两个分支架构组成。我们的方法将参数数量从2.08M减少到37.9K,减少了98.2,同时将精度保持在最先进的肖像分割方法的1个范围内。在我们对EG1800数据集的定性和定量分析中,我们表明我们的方法优于各种现有的轻量级分割模型。其次,我们提出了一种简单的方法来创建额外的肖像分割数据,这可以提高EG1800数据集的准确性。此外,我们通过另外注释我们自己的种族,性别和年龄来分析公共数据集中的偏差。增强的数据集和附加注释将在发布后发布。 |
| Sim-to-Real Learning for Casualty Detection from Ground Projected Point Cloud Data Authors Roni Permana Saputra, Nemanja Rakicevic, Petar Kormushev 本文利用点云数据解决了人体检测特别是躺在地上的人体问题。这种检测伤员的能力是移动救援机器人最重要的特征之一,以便他们能够自主操作。我们提出了一种使用深度卷积神经网络CNN的基于深度学习的伤亡检测方法。该网络经过训练,能够使用点云数据输入来检测伤员。在我们提出的方法中,预先处理点云输入以生成像地面投影高度图的深度图像。基于点云数据内每个点到检测到的地平面上的投影距离生成该高度图。然后将生成的图像形式的高度图用作CNN的输入,以检测躺在地上的人体。为了训练神经网络,我们提出了一种新的实际方法,其中使用在仿真中获得的合成数据训练网络模型,然后在真实的传感器数据上进行测试。为了使模型可以转换为实际数据实现,在培训期间,我们采用特定的数据增强策略和综合训练数据。实验结果表明,在训练过程中引入的数据增加对于提高训练模型在实际数据上的性能至关重要。更具体地说,结果表明,原始点云数据的数据增强有助于显着提高训练模型的性能。 |
| What goes around comes around: Cycle-Consistency-based Short-Term Motion Prediction for Anomaly Detection using Generative Adversarial Networks Authors Thomas Golda, Nils Murzyn, Chengchao Qu, Kristian Kroschel 异常检测在许多研究领域中起着重要作用,与异常检测的强烈相关任务起着非常重要的作用。特别是在监视摄像机记录的视频资料的自动分析的背景下,异常情况可能具有非常不同的性质。为此目的,这项工作研究了基于生成性对抗网络的方法GAN,用于与监视应用相关的异常检测。重点是静态相机设置的使用,因为这种相机是最常用的相机之一,属于较低价格段。为了解决该任务,评估了多个子任务,包括现有光流方法对于结合短期时间信息,不同形式的网络设置和GAN损失的影响,以及使用形态学操作来进一步提高性能。通过这些扩展,我们实现了2.4个更好的结果。此外,最终方法将基于GAN的方法的异常检测误差减少了大约42.8。 |
| +++x编辑场景文字Editing Text in the Wild Authors Liang Wu, Chengquan Zhang, Jiaming Liu, Junyu Han, Jingtuo Liu, Errui Ding, Xiang Bai 在本文中,我们感兴趣的是编辑自然图像中的文本,其目的是在保持其逼真外观的同时用另一个图像替换或修改源图像中的单词。此任务具有挑战性,因为需要保留背景和文本的样式,以便编辑的图像在视觉上与源图像无法区分。具体来说,我们提出了一个端到端的可训练式保留网络SRNet,它由三个模块组成文本转换模块,后台修复模块和融合模块。文本转换模块将源图像的文本内容更改为目标文本,同时保持原始文本样式。背景修复模块擦除原始文本,并用适当的纹理填充文本区域。融合模块组合来自两个前模块的信息,并生成编辑的文本图像。据我们所知,这项工作是第一次尝试在单词级别编辑自然图像中的文本。合成和现实世界数据集ICDAR 2013的视觉效果和定量结果都充分证实了模块化分解的重要性和必要性。我们还进行了大量实验,以验证我们的方法在各种实际应用中的有用性,如文本图像合成,增强现实AR翻译,信息隐藏等。 |
| Semantic Estimation of 3D Body Shape and Pose using Minimal Cameras Authors Andrew Gilbert, Matthew Trumble, Adrian Hilton, John Collomosse 我们提出了一种方法,使用一小组摄像机视图sim 2精确估计高保真无标记3D姿势和人体表现的体积重建。我们的方法利用生成对抗网络中的双重损失,其可以在重建和姿势估计误差中产生改进的性能。我们使用由网络隐式学习的深度先验,该网络是在广泛的主题和动作的视图消融的多视图视频镜头的数据集上训练的。独特地,我们使用具有双重损失的多通道对称3D卷积编码器解码器来强制执行潜在嵌入的学习,其实施骨架关节位置和表演者的深度体积重建。在三个数据集Human 3.6M,TotalCapture和TotalCaptureOutdoor上报告了最新性能的广泛评估。该方法开启了在集合和专业消费者场景中高端体积和姿势性能捕获的可能性,其中时间或成本禁止高见证摄像机计数。 |
| Feature selection of neural networks is skewed towards the less abstract cue Authors Marcell Wolnitza, Babette Dellen 人工神经网络人工神经网络已经成为图像分类的重要工具,在研究和工业中有许多应用。但是,如何选择相关的图像功能以及数据属性如何影响此过程仍然很大程度上未知。特别是,我们感兴趣的是与类成员关系相关的图像提示的抽象级别是否会影响特征选择。我们使用包含组合提示的二进制图像进行实验,表示两个不同级别的抽象,一个是从随机分布中绘制的模式,其中类成员关系与模式的统计相关联,另一个是符号类似实体的组合,其中符号代码与类成员关联。当用两个提示同等重要的数据训练网络时,我们观察到学习了较低抽象级别的提示,即模式,而符号信息在很大程度上被忽略,即使在具有许多层的网络中也是如此。只有当低级别线索的重要性与高级别线索的重要性相比时,才会学习类似实体的符号。这些发现提出了关于深度人工神经网络学习的特征的相关性以及如何将学习转向符号特征的重要问题。 |
| Constrained domain adaptation for segmentation Authors Mathilde Bateson, Jose Dolz, Hoel Kervadec, Herv Lombaert, Ismail Ben Ayed 我们建议使用约束公式来调整分段网络,该公式嵌入关于分割区域的域不变先验知识。这种知识可以采取简单的解剖学信息的形式,例如,从源样本估计的结构大小或形状,或者已知的先验。我们的方法对未标记的目标样本的网络输出施加了域不变的不等式约束。它隐含地匹配目标域和源域之间的预测统计与允许的先验知识的不确定性。我们用可微分的惩罚来解决我们的约束问题,完全适用于标准随机梯度下降方法,消除了对具有双投影的计算上昂贵的拉格朗日优化的需要。与目前的两步对抗训练不同,我们的表述基于单一网络中的单一损失,通过避免额外的对抗步骤简化了适应性,同时提高了训练的收敛性和质量。 |
| +++基于流型的观点解释Deep Image Prior Manifold Modeling in Embedded Space: A Perspective for Interpreting "Deep Image Prior" Authors Tatsuya Yokota, Hidekata Hontani, Qibin Zhao, Andrzej Cichocki 深度图像之前的DIP,利用深度卷积网络ConvNet结构本身作为图像先验,在计算机视觉社区中具有吸引力的关注。它凭经验证明了ConvNet结构在各种图像恢复应用中的有效性。然而,为什么DIP工作得如此之好仍然是黑盒子,为什么ConvNet对图像必不可少也不是很清楚。 |
| +++点云目标检测方法Fast Point R-CNN Authors Yilun Chen, Shu Liu, Xiaoyong Shen, Jiaya Jia 我们为基于点云的三维物体检测提供了统一,高效和有效的框架。我们的两阶段方法利用体素表示和原始点云数据来利用各自的优势。以体素表示为输入的第一级网络仅由轻卷积运算组成,产生少量高质量初始预测。初始预测中每个点的坐标和索引卷积特征与注意机制有效融合,保留了准确的定位和上下文信息。第二阶段利用其融合特征在内部点上工作,以进一步细化预测。我们的方法在KITTI数据集上进行了评估,包括3D和Bird s Eye View BEV检测,并以15FPS检测率实现了现有技术水平。 |
| Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning Authors Eric Arazo, Diego Ortego, Paul Albert, Noel E. O Connor, Kevin McGuinness 半监督学习,即从标记的未标记样本中共同学习,由于其在放松人类注释约束方面的关键作用,因此是一个活跃的研究课题。在图像分类的背景下,从未标记样本中学习的最新进展主要集中在一致性正则化方法上,该方法鼓励对未标记样本的不同扰动进行不变预测。相反,我们建议通过使用网络预测生成软伪标签来学习未标记的数据。我们表明,由于所谓的确认偏差,一个天真的伪标签会过度拟合不正确的伪标签,并证明标签噪声和混合增强是减少它的有效正则化技术。所提出的方法在CIFAR 10 100和Mini Imaget中实现了最先进的结果,尽管比其他现有技术简单得多。这些结果表明伪标记可以胜过一致性正则化方法,而在之前的工作中则相反。源代码可在网址获得 |
| From Two Graphs to N Questions: A VQA Dataset for Compositional Reasoning on Vision and Commonsense Authors Difei Gao, Ruiping Wang, Shiguang Shan, Xilin Chen 视觉问题回答VQA是一项具有挑战性的任务,用于评估全面了解世界的能力。现有的基准测试通常只关注视觉上的推理能力,或者主要关注具有相对简单视觉能力的知识。然而,回答需要交替推断图像内容和常识知识的问题的能力对于高级VQA系统是至关重要的。在本文中,我们介绍了一个VQA数据集,它提供了有关vIsion和Commonsense的组合推理的更具挑战性和一般性的问题,它被命名为CRIC。为了创建这个数据集,我们开发了一种强大的方法,可以从给定图像的场景图和一些外部知识图中自动生成组合问题和丰富的注释。此外,本文提出了一种新的组合模型,能够在图像内容和知识图上实现各种类型的推理功能。此外,我们分析了CRIC数据集的几个基线,最新技术和我们的模型。实验结果表明,所提出的任务具有挑战性,其中现有技术获得52.26准确度,我们的模型获得58.38。 |
| Semi Supervised Phrase Localization in a Bidirectional Caption-Image Retrieval Framework Authors Deepan Das, Noor Mohammed Ghouse, Shashank Verma, Yin Li 我们介绍了一种新颖的深度神经网络架构,将视觉区域与相应的文本片段(包括短语和单词)相关联为了完成这项任务,我们的架构利用了多模态数据的联合嵌入空间中可用的丰富语义信息。从这个联合嵌入空间,我们提取自然发展的关联本地化地图,而无需在培训期间明确地提供对本地化任务的监督。使用双向排序目标来学习关节空间,该目标使用N对损失公式进行优化。该培训机制演示了在优化双向检索目标的同时本地学习本地化信息的想法。在MSCOCO和Flickr30K实体数据集上评估模型的检索和定位性能。该架构优于半监督短语本地化设置中的现有技术结果。 |
| Progressive Relation Learning for Group Activity Recognition Authors Guyue Hu, Bo Cui, Yuan He, Shan Yu 小组活动通常涉及许多互动个体之间的时空动态,而几个关键帧中只有少数参与者基本上定义了活动。因此,有效地对相关群体进行建模并抑制不相关的行为和相互作用对群体活动识别至关重要。在本文中,我们提出了一种基于深度强化学习的新方法,逐步完善群体活动的低层次特征和高层次关系。首先,我们构造一个语义关系图SRG来明确地模拟人与人之间的关系。然后,应用根据两个马尔可夫决策过程采用策略的两个代理来逐步细化SRG。具体地,在离散动作空间中提取FD代理的一个特征通过提取最具信息性的帧来细化低级空间时间特征。在连续动作空间中连接RG代理的另一个关系是调整高级语义图以更加关注组相关关系。 SRG,FD代理和RG代理交替优化,以相互提升彼此的性能。对两个广泛使用的基准测试的广泛实验证明了所提出方法的有效性和优越性。 |
| Towards Generating Stylized Image Captions via Adversarial Training Authors Omid Mohamad Nezami, Mark Dras, Stephen Wan, Cecile Paris, Len Hamey 虽然大多数图像字幕旨在产生对图像的客观描述,但是最近几年已经看到产生具有特定风格的视觉上接地的图像标题的工作,例如,结合正面或负面情绪。然而,因为风格组件通常是训练的最后部分,所以当前模型通常以牺牲准确的内容描述为代价而更加注重风格。此外,在风格方面缺乏可变性。为了解决这些问题,我们提出了一个名为ATTEND GAN的图像字幕模型,它首先有两个核心组件,一个基于注意力的字幕生成器,用于将图像的不同部分与字幕的不同部分强烈关联,其次是对抗训练机制,以协助标题生成器,用于为生成的标题添加不同的样式组件。由于这些组件,ATTEND GAN可以生成相关的字幕以及更像人类的风格模式的可变性。我们的系统优于最先进的技术以及我们的基线模型集合。对生成的字幕的语言分析表明,使用ATTEND GAN生成的字幕具有更广泛的风格形容词和形容词名词对。 |
| Bayesian Feature Pyramid Networks for Automatic Multi-Label Segmentation of Chest X-rays and Assessment of Cardio-Thoratic Ratio Authors Roman Solovyev, Iaroslav Melekhov, Timo Lesonen, Elias Vaattovaara, Osmo Tervonen, Aleksei Tiulpin 从胸部X光片估计的心脏电位比CTR是指示心脏扩大的标志物,其存在是心力衰竭诊断的标准。用于自动评估CTR的现有方法由基于深度学习的分段驱动。然而,这些技术仅产生CTR的点估计,但临床决策通常假设不确定性。在本文中,我们提出了一种自动方式的胸部X射线分割和CTR评估的新方法。与现有技术相比,我们首次提出用不确定性边界估计CTR。我们的方法基于具有特征金字塔网络FPN解码器的深度卷积神经网络。我们提出FPN的两个修改用实例归一化替换批量归一化并注入丢失,这允许在测试时获得分割图的蒙特卡洛估计。最后,使用预测的分割掩模样本,我们估计具有不确定性的CTR。在我们的实验中,我们证明了所提出的方法很好地推广到三个不同的测试集。最后,我们制作了两位放射科医师为我们所有数据集公开提供的注释。 |
| ++基于人脸表情和注意力的图像标注方法Image Captioning using Facial Expression and Attention Authors Omid Mohamad Nezami, Mark Dras, Stephen Wan, Cecile Paris 受益于机器视觉和自然语言处理技术的进步,当前的图像字幕系统能够生成详细的视觉描述。在大多数情况下,这些描述代表了图像的客观表征,尽管某些模型确实包含了与观察者的图像视图相关的主观方面,例如情感当前模型,但是,通常不考虑图像的情感内容。标题生成过程。本文通过提出使用面部表情特征生成图像标题的新颖图像字幕模型来解决这个问题。该模型使用长短期记忆网络生成图像标题,除了在不同时间步骤的其他视觉特征之外,还应用面部特征。我们使用所有标准评估指标比较具有和不具有面部特征的全面图像字幕模型集合。评估指标表明,应用具有注意机制的面部特征在从标准Flickr 30K数据集提取的图像标题数据集上实现最佳性能,显示更具表现力和更相关的图像标题,该数据集由包含面部的大约11K图像组成。对生成的字幕的分析发现,或许意外地,字幕质量的改善似乎不是来自与图像的情感方面相关的形容词的添加,而是来自字幕中描述的动作的更多变化。 code:https://github.com/omidmnezami/Face-Attend |
| +细粒度植物疾病监测iCassava 2019Fine-Grained Visual Categorization Challenge Authors Ernest Mwebaze, Timnit Gebru, Andrea Frome, Solomon Nsumba, Jeremy Tusubira 病毒性疾病是木薯产量低的主要原因,木薯是中国第二大碳水化合物供应国 |
| +++基于RGB-D的三维语义场景分割方法EdgeNet: Semantic Scene Completion from RGB-D images Authors Aloisio Dourado, Teofilo Emidio de Campos, Hansung Kim, Adrian Hilton 语义场景完成是从单个视点预测用于场景的对应语义标签的体积占用的完整3D表示的任务。之前关于语义场景的工作完成RGB D数据通过将2D图像投影到3D体积中而仅使用颜色的深度或深度,从而产生稀疏数据表示。在这项工作中,我们提出了一种新的策略,使用边缘检测和翻转截断的符号距离来编码3D空间中的颜色信息。我们还介绍了EdgeNet,这是一种新的端到端神经网络架构,能够处理深度和边缘信息融合产生的特征。实验结果表明,对于端到端方法,对于实际数据的现有技术结果的改进为6.9。 |
| Unsupervised Feature Learning in Remote Sensing Authors Aaron Reite, Scott Kangas, Zackery Steck, Steven Goley, Jonathan Von Stroh, Steven Forsyth 标记数据的需求是部署深度学习算法以解决现实世界问题的最常见和众所周知的实际障碍。当前一代学习算法需要根据静态和预定义模式标记的大量数据。相反,人类可以基于大量未标记数据快速学习概括,并使用自发标签将这些概括转化为分类,通常包括之前未见过的标签。我们将一种先进的无监督学习算法应用于噪声和极不平衡的xView数据集,以训练一个特征提取器,该特征提取器适应几个任务视觉相似性搜索,这些搜索在标识数据集和学习中识别异常值的常见和罕见类别上表现良好。自动的自然类层次结构。 |
| +++位置场描述子用于单图像三维模型检索Location Field Descriptors: Single Image 3D Model Retrieval in the Wild Authors Alexander Grabner, Peter M. Roth, Vincent Lepetit 我们提出了位置字段描述符,这是一种用于野外单图像3D模型检索的新方法。与以前直接将3D模型和RGB图像映射到嵌入空间的方法相比,我们以位置字段的形式建立了一个共同的低级表示,我们从中计算姿势不变的3D形状描述符。位置字段编码2D像素和3D表面坐标之间的对应关系,因此,明确地捕获3D形状和3D姿势信息,而没有与任务无关的外观变化。 3D模型和RGB图像的早期融合产生三个主要优点首先,瓶颈位置场预测在训练期间充当正则化器。其次,系统的主要部分受益于对几乎无限量的合成数据的培训。最后,预测的位置字段在视觉上是可解释的,并且是黑白的系统。我们在具有不同对象类别的三个具有挑战性的现实世界数据集Pix3D,Comp和Stanford上评估我们提出的方法,并且在多个3D检索度量中最多20个绝对值,显着优于现有技术水平。 |
| GP2C: Geometric Projection Parameter Consensus for Joint 3D Pose and Focal Length Estimation in the Wild Authors Alexander Grabner, Peter M. Roth, Vincent Lepetit 我们提出了一种用于野外物体类别的联合3D姿态和焦距估计方法。与先前预测独立于焦距的3D姿势或假设恒定焦距的方法相比,我们明确地估计焦点长度并将其整合到3D姿势估计中。为此,我们在两阶段方法中结合深度学习技术和几何算法首先,我们估计初始焦距并使用深度网络从单个RGB图像建立2D 3D对应。其次,我们通过最小化预测的对应关系的重投影误差来恢复3D姿势并改善焦距。通过这种方式,我们利用焦距给出的几何先验进行3D姿态估计。这带来两个优点首先,与现有方法相比,我们实现了显着改善的3D平移和3D姿势精度。其次,我们的方法在各个投影参数之间找到几何共识,这是精确2D 3D对齐所需的。我们在具有不同对象类别的三个具有挑战性的现实世界数据集Pix3D,Comp和Stanford上评估我们提出的方法,并且在多个不同指标中显着优于最先进的20个绝对数据集。 |
| ++基于自适应容量的多尺度卷积人群密度估计Attend To Count: Crowd Counting with Adaptive Capacity Multi-scale CNNs Authors Zhikang Zou, Yu Cheng, Xiaoye Qu, Shouling Ji, Xiaoxiao Guo, Pan Zhou 由于人群分布的巨大差异,人群计数是一项具有挑战性的任务。以前的方法倾向于用单个固定结构来处理整个图像,这不能处理具有不同人群密度的各种复杂场景。因此,我们提出了自适应容量多尺度卷积神经网络ACM CNN,一种新颖的人群计数方法,可以为输入的不同部分分配不同的容量。直觉是模型应该关注输入图像的重要区域,并在人群密集程度上优化其容量分配条件。 ACM CNN由粗网络,精细网络和平滑网络三种模块组成。粗网络用于通过计数注意机制探索需要聚焦的区域,并生成粗略的特征图。然后,精细网络将感兴趣的区域处理成精细的特征图。为了减轻由融合引起的分裂感,平滑网络被设计为有机地组合两个特征图以产生高质量的密度图。对五个主流数据集进行了广泛的实验。结果证明了所提出的模型对密度估计和人群计数任务的有效性。 |
| Hierarchy-of-Visual-Words: a Learning-based Approach for Trademark Image Retrieval Authors V tor N. Louren o, Gabriela G. Silva, Leandro A. F. Fernandes 在本文中,我们提出了视觉词的层次结构HoVW,一种新颖的商标图像检索TIR方法,它将图像分解为更简单的几何形状,并通过编码组件形状的分层排列来定义二进制商标图像表示的描述符。所提出的视觉数据的分层组织将每个组件形状存储为视觉词。它能够表示单个元素的几何形状和商标图像的拓扑结构,使得描述符对线性以及某种程度的非线性变换具有鲁棒性。实验表明,在MPEG 7 CE 1和MPEG 7 CE 2图像数据库中,HoVW优于以前的TIR方法。 |
| Learning Vision-based Flight in Drone Swarms by Imitation Authors Fabian Schilling, Julien Lecoeur, Fabrizio Schiano, Dario Floreano 今天部署的分散无人机群体要么依靠在代理之间共享位置,要么借助视觉标记来检测群体成员。这项工作提出了一种完全可视化的方法来协调基于模仿学习的无标记无人机群。每个代理由一个小而有效的卷积神经网络控制,该网络将原始全方位图像作为输入并预测与通过植绒算法计算的3D速度命令相匹配的3D速度命令。我们开始进行模拟训练,并提出一种简单而有效的无监督域自适应方法,将学习到的控制器转移到现实世界。我们进一步训练控制器,使用我们的动作捕捉大厅收集的数据。我们表明,在无人机的视觉输入上训练的卷积神经网络不仅可以学习有效的代理间碰撞避免,而且可以以样本有效的方式学习群体的内聚力。神经控制器有效地学习在视觉输入中定位其他代理,我们通过可视化对代理运动影响最大的区域来显示。我们通过仅考虑本地视觉信息来消除对群体成员之间共享位置的依赖性。因此,我们的工作可视为迈向完全分散的,基于视觉的群体的第一步,而无需通信或视觉标记。 |
| AxoNet: an AI-based tool to count retinal ganglion cell axons Authors Matthew D. Ritch, Bailey G. Hannon, A. Thomas Read, Andrew J. Feola, Grant A. Cull, Juan Reynaud, John C. Morrison, Claude F. Burgoyne, Machelle T. Pardue, C. Ross Ethier 目标在这项工作中,我们开发了一种强大的,可扩展的工具,可以自动准确地计算来自各种青光眼动物模型的视神经组织图像中的视网膜神经节细胞轴突。方法U Net卷积神经网络结构适用于学习像素轴突计数密度估计,然后将其整合到图像区域以确定轴突计数。该工具称为AxoNet,使用包含从完整大鼠视神经的完整横截面随机选择的视神经区域的图像的数据集进行训练和评估,并手动注释轴突计数和位置。使用对照和受损的视神经。然后将该经过大鼠训练的网络应用于非人灵长类动物NHP视神经图像的单独数据集。然后使用两个数据集将AxoNet与两个现有的自动轴突计数工具AxonMaster和AxonJ进行比较。结果AxoNet在大鼠和NHP视神经数据集上的表现均优于平均绝对误差,回归自动计数与手动计数时的R2值以及Bland Altman分析。结论所提出的工具允许准确量化轴突数量,作为青光眼损伤的量度。 AxoNet对视神经组织损伤程度,图像质量和哺乳动物种类的变化具有很强的适应性。意义深度学习方法不依赖于手工制作的图像特征来进行轴突识别。因此,这种方法不是物种特异性的,可以扩展到量化额外的视神经特征。它将有助于评估青光眼和潜在的其他神经退行性疾病的视神经变化。 |
| +太阳图像去噪网络Solar image denoising with convolutional neural networks Authors C. J. D az Baso, J. de la Cruz Rodr guez, S. Danilovic 太阳色球的拓扑和动力学受磁场的影响很大。可以通过分析光谱线的极化观察来推断磁场。然而,由色球磁场引起的极化信号特别弱,并且在大多数情况下非常接近当前仪器的检测极限。因此,只有少数观测研究成功地重建了色球层中磁场矢量的三个分量。传统上,通过执行时间平均或空间平均来改善观测的信噪比,但在这两种情况下,一些信息都会丢失。还采用了更先进的技术,如主成分分析,以利用光谱方向上观测的稀疏性。在本研究中,我们建议使用观测的空间相干性来使用深度学习技术来降低噪声。我们设计了一种神经网络,能够在复杂的噪声损坏下恢复微弱信号,包括仪器伪像和非线性后处理。网络的训练是在没有清洁信号的先验知识的情况下进行的,或者是对噪声或其他腐败的明确统计表征。我们只使用与生成模型相同的观察结果。该方法的性能在合成实验和实际数据上都得到了证明。我们展示了目前望远镜中获得的典型信号改进的例子,例如瑞典1米太阳望远镜。无论使用什么谱线或光谱采样,所提出的方法都可以同样良好地恢复弱信号。它特别适用于波长采样不足的情况。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com