ElasticSearch概述及Linux下的单机ElasticSearch安装
这两天在项目中要涉及到ElasticSearch的使用,就上网去搜索了一些这方面的资料,发现elasticSearch的安装分为单机和集群两种方式。在本例中,我们重点介绍单机下的ElasticSearch的安装,亲测可用,记录下来与各位同仁分享。
一、ElasticSearch概述
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,令我们受打击的是:搜索工作是很难的。我们希望我们的搜索解决方案要快,我们希望有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP的索引数据,我们希望我们的搜索服务器始终可用,我们希望能够一台开始并扩展到数百,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。Elasticsearch旨在解决所有这些问题和更多的问题。【百度百科】
几个重要的核心概念
1、接近实时
ElasticSearch是一个接近实时的搜索平台,这就是说,从索引这个文档到这个文档能够被搜索到有一个轻微的延迟。
2、集群和节点
一个集群就是由一个或者多个节点组织在一起,它们共同的持有你整个的数据,通俗的来说就是一个或者多个服务器,即组成集群,而每个独立的服务器即是一个节点,一般在集群中会有一个主节点,剩下的即为从节点,主节点和从节点共同负责参与数据的存储和管理。
3、索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。举个例子,相信各位肯定有过在图书馆找书的经历,每本书上都会贴着一个索引,而我们可以将每本书中的每一页看作是文档,这样的话看,索引就是一系列文档的集合。一个索引由一个名字来标识,并且当我们要对对应于这个索引中的文档进行索引,进行搜索、更新和删除的时候,都会用到这个名字。当然了,在集群中,你可以根据自己的想法定义任意多的索引。
4、类型(type)
在一个索引中,你可以定义一种或者多种类型。一个类型是一个索引的一个逻辑上的分类/分区,其语义完全由你来定。通常来说,会为具有一组共同字段的文档定义一个类型。再拿上述的例子,我们可以将书中的文字定义为一个数据类型,而为书中的数据定义为另外一个数据类型。
5、文档(document)
一个文档是一个可被索引的基础信息单元。文档是以JSON格式来表示,而JSON是一个到处存在的互联网数据交互格式。
6、分片和复制
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片的重要性的原因:
允许你水平分割/扩展你的内容容量
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制的重要性的原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
二、Linux下的单机ElasticSearch安装
准备工作:
操作系统:Centos 7 IP:192.168..18.228

1、安装JDK,并且设置环境变量和使之生效(略,这一步可以去参照我之前的博文“hadoop+hive的安装配置”里写的很详细),如图所示,jdk安装成功:

2、添加新的用户,在本例中添加的用户名为es:
[root@slave2 ~] useradd es
[root@slave2 ~] passwd es
切换到es用户下:
3、建立新的文件夹,并将之后的所有的文件放到这个文件夹,如图:
![]()
4、将下载好的elasticsearch-1.7.3.tar.gz复制到3中新建的文件夹下,并解压:
如何上传呢?请参照我之前的博文“hadoop+hive的安装配置”,用scp命令将elasticsearch-1.7.3.tar.gz从本地上传到3中新建的文件夹下。
解压:
tar -zxvf elasticsearch-1.7.3.tar.gz
解压后,并赋予普通用户es,如下图:

5、进入elasticsearch的bin目录下,启动elassticsearch脚本,如下图:

启动成功后如下图所示:
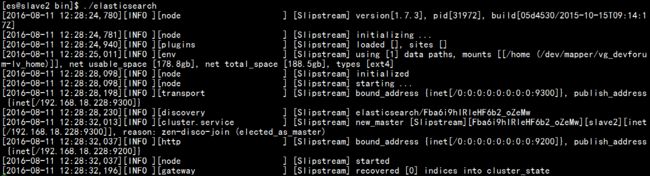
也可以用如下命令进行后台启动:
![]()
6、测试
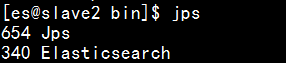
(1)可以通过jps查看,如图:
(2)用如下方法查看:下图中192.168.18.228有时可以换做是localhost,(另外是否要将elascticsearch下的config下的elasticsearch.yml中的network处替换成192.168.18.228,我未验证,若未出现下图所示,请将yml的network处替换成192.168.18.228,囧)
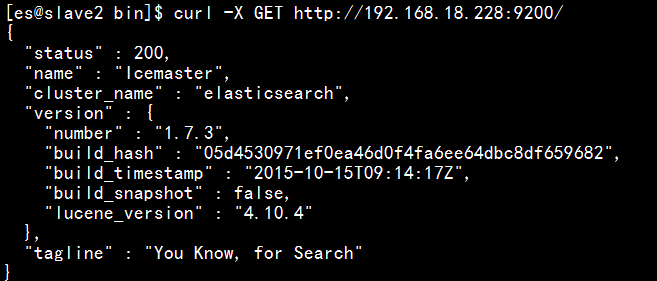
若出现上图,即为elasticsearch安装成功。
7、安装插件elasticsearch-servicewrapper方便管理elasticsearch服务:
从https://github.com/elastic/elasticsearch-servicewrapper下载service文件夹,放到es的bin目录下即可。如何上传文件夹呢?参照之前的博文,嘿嘿,用scp命令。
附:
./elasticsearch console ——-前台运行
./elasticsearch start ——-后台运行
./elasticsearch install——-添加到系统自动启动
./elasticsearch remove——-取消随系统自动启动
8、后面的两种插件head和bigdesk是针对集群管理的,我在本例中只是单机安装,所以就没必要安装这两款插件了,有需要的可以参考以下的链接:
http://blog.csdn.net/a806267365/article/details/51020633
或者更多的链接可以参考学习交流:
http://blog.csdn.net/sinat_28224453/article/details/51134978
本文同时参考了以下的链接:
http://blog.csdn.net/cnweike/article/details/33736429