Mask RCNN源码解读及如何使用自己的数据集进行训练
一、概述
作者使用了Tensorflow,Keras,python3实现了Mask R-CNN。由于作者使用了Keras搭建网络,使用data generator导入数据,所以对于以python实现的网络来说,其性能并不是最优的。之后我会改一版使用tf.estimator 和 tf.data API搭建的网络。
Mask R-CNN的源码:https://github.com/matterport/Mask_RCNN
Mask R-CNN的论文:https://arxiv.org/abs/1703.06870
Mask R-CNN的博客:https://blog.csdn.net/wangdongwei0/article/details/83110305
在github上,作者提供了:
- Source code of Mask R-CNN built on FPN and ResNet101.
- Training code for MS COCO
- Pre-trained weights for MS COCO
- Jupyter notebooks to visualize the detection pipeline at every step
- ParallelModel class for multi-GPU training
- ParallelModel class for multi-GPU training
- Example of training on your own dataset
二、文件功能描述
- demo.ipynb 是最简单的例子,适合入门时使用。下载pretrained model后,你可以使用demo.py对自己的任意一张图像进行实例分割。
- train_shapes.ipynb 通过以shapes dataset为例,告诉你该如何使用自己的数据集训练网络
- model.py,utils.py,config.py 包含了Mask R-CNN的实现代码
- inspect_data.ipynb 监控程序是如何一步步进行数据的预处理的
- inspect_model.ipynb 监控程序是如何进行定位和分割的
- Inspect_weights.ipynb 监控模型权重变化的
本文主要讲述前三点,后三点并不是我们所关心的。
三、demo.ipynb
建议首先运行demo.py,与Faster RCNN源码中的demo.py相同,拿到代码后先运行一下,就只检测一张图片看看效果。
1、导入库,设置基本路径
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
# Root directory of the project
ROOT_DIR = os.path.abspath("../")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
%matplotlib inline
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")2、设置配置信息
配置信息主要存在./mrcnn/config.py下,在./samples/coco.py中也有小部分配置信息。class InferenceConfig类是一层层继承的,如果需要修改 ./mrcnn/config.py 或 ./samples/coco.py 中的某些参数,直接重写就好。
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()打印配置信息如下:
Configurations:
BACKBONE_SHAPES [[256 256]
[128 128]
[ 64 64]
[ 32 32]
[ 16 16]]
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 1
BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.5
DETECTION_NMS_THRESHOLD 0.3
GPU_COUNT 1
IMAGES_PER_GPU 1
IMAGE_MAX_DIM 1024
IMAGE_MIN_DIM 800
IMAGE_PADDING True
IMAGE_SHAPE [1024 1024 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.002
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [ 123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME coco
NUM_CLASSES 81
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (32, 64, 128, 256, 512)
RPN_ANCHOR_STRIDE 2
RPN_BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 1000
TRAIN_ROIS_PER_IMAGE 128
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STEPS 50
WEIGHT_DECAY 0.00013、建立模型,加载权重
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)4、设定类别
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']5、开始预测
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2]
image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
# Run detection
results = model.detect([image], verbose=1)
# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])到此为止,我们已经可以使用该网络完成任意一张图的实例分割任务,对程序的基本模块有了初步认识,接下来就开始进一步的提升,使用自己的数据集训练。
四、train_shapes.ipynb
shapes dataset是一个包含了规则的三角形,圆形,矩形的训练集,用来训练网络分割不同形状的实例。我们将以这个数据集为例,详细介绍如何使用自己的数据集训练网络。
1、与 demo.ipynb 相同,首先导入库,设置基本路径。
import os
import sys
import random
import math
import re
import time
import numpy as np
import cv2
import matplotlib
import matplotlib.pyplot as plt
# Root directory of the project
ROOT_DIR = os.path.abspath("../../")
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn.config import Config
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
from mrcnn.model import log
%matplotlib inline
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)2、配置、与上面 demo.ipynb的不同,根据 shapes dataset 进行合适的配置
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 8
# Number of classes (including background)
NUM_CLASSES = 1 + 3 # background + 3 shapes
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 128
IMAGE_MAX_DIM = 128
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8, 16, 32, 64, 128) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small
VALIDATION_STEPS = 5
config = ShapesConfig()
config.display()打印配置信息如下:
Configurations:
BACKBONE_SHAPES [[32 32]
[16 16]
[ 8 8]
[ 4 4]
[ 2 2]]
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 8
BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.5
DETECTION_NMS_THRESHOLD 0.3
GPU_COUNT 1
IMAGES_PER_GPU 8
IMAGE_MAX_DIM 128
IMAGE_MIN_DIM 128
IMAGE_PADDING True
IMAGE_SHAPE [128 128 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.002
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [ 123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME SHAPES
NUM_CLASSES 4
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (8, 16, 32, 64, 128)
RPN_ANCHOR_STRIDE 2
RPN_BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 100
TRAIN_ROIS_PER_IMAGE 32
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STEPS 50
WEIGHT_DECAY 0.00013、使用matplotlib显示
def get_ax(rows=1, cols=1, size=8):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Change the default size attribute to control the size
of rendered images
"""
_, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))
return ax4、数据预处理
在 Mask RCNN源码中,自定义的数据集都需要被定义为一个类,比如COCODatasets和ShapesDataset,我们需要进一步
- 创建类别: squrare、circle、triangle。(不理解没关系,继续往下看)
- 针对所用数据集,重写以下函数:load_image() 、load_mask()、image_reference()
我们如何预处理数据呢?如下:
# Training dataset
#定义一个train对象,ShapeDataset是Dataset的子类,重写了一些函数
dataset_train = ShapesDataset()
#生成500张用来训练的图片,指定长宽
dataset_train.load_shapes(500, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
#预处理
dataset_train.prepare()
# Validation dataset
dataset_val = ShapesDataset()
dataset_val.load_shapes(50, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
dataset_val.prepare()接着我们看一下 ShapeDataset 的定义,它是继承自 utils.Dataset,发现并没有初始化函数,所以首先找到其父类 utils.Dataset的 __init__()函数,我们看看都定义了哪些属性。我们可以看到,Dataset类主要有 image_ids、image_info, class_info,source_class_ids 这四个属性。 class_info保存了训练各个类别都是什么,序号为0的类别永远都是背景。
1、dataset_train = ShapesDataset()
class Dataset(object):
"""The base class for dataset classes.
To use it, create a new class that adds functions specific to the dataset
you want to use. For example:
class CatsAndDogsDataset(Dataset):
def load_cats_and_dogs(self):
...
def load_mask(self, image_id):
...
def image_reference(self, image_id):
...
See COCODataset and ShapesDataset as examples.
"""
def __init__(self, class_map=None):
self._image_ids = []
self.image_info = []
# Background is always the first class
self.class_info = [{"source": "", "id": 0, "name": "BG"}]
self.source_class_ids = {}
继承类需要重写以下三个函数:load_image() 、load_mask()、image_reference()。我们按照代码运行的先后顺序分别说明各个函数的作用。
2、dataset_train.load_shapes(500, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
class ShapesDataset(utils.Dataset):
"""Generates the shapes synthetic dataset. The dataset consists of simple
shapes (triangles, squares, circles) placed randomly on a blank surface.
The images are generated on the fly. No file access required.
"""
def load_shapes(self, count, height, width):
"""Generate the requested number of synthetic images.
count: number of images to generate.
height, width: the size of the generated images.
"""
# Add classes
# 就是往 self.class_info字典列表中添加类别,很简单
self.add_class("shapes", 1, "square")
self.add_class("shapes", 2, "circle")
self.add_class("shapes", 3, "triangle")
# Add images
# Generate random specifications of images (i.e. color and
# list of shapes sizes and locations). This is more compact than
# actual images. Images are generated on the fly in load_image().
for i in range(count):
#返回值是每张图的背景颜色和形状的属性(大小,形状,颜色,位置)
bg_color, shapes = self.random_image(height, width)
#把上面的返回值添加到 self.image_info 字典列表中去
self.add_image("shapes", image_id=i, path=None,
width=width, height=height,
bg_color=bg_color, shapes=shapes)
这部分代码还是比较乱的,画成图理解更加直观,所以我就不小心画成下面这个丑陋的样子。。。
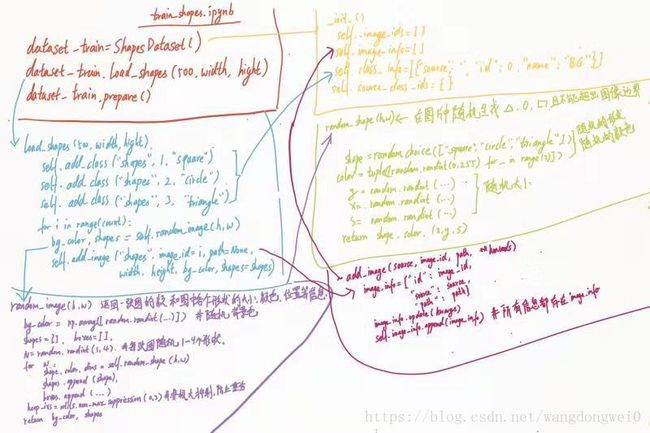
3、dataset_train.prepare()
def prepare(self, class_map=None):
"""Prepares the Dataset class for use.
TODO: class map is not supported yet. When done, it should handle mapping
classes from different datasets to the same class ID.
"""
def clean_name(name):
"""Returns a shorter version of object names for cleaner display."""
return ",".join(name.split(",")[:1])
# Build (or rebuild) everything else from the info dicts.
self.num_classes = len(self.class_info)
self.class_ids = np.arange(self.num_classes)
self.class_names = [clean_name(c["name"]) for c in self.class_info]
self.num_images = len(self.image_info)
self._image_ids = np.arange(self.num_images)
# Mapping from source class and image IDs to internal IDs
self.class_from_source_map = {"{}.{}".format(info['source'], info['id']): id
for info, id in zip(self.class_info, self.class_ids)}
self.image_from_source_map = {"{}.{}".format(info['source'], info['id']): id
for info, id in zip(self.image_info, self.image_ids)}
# Map sources to class_ids they support
self.sources = list(set([i['source'] for i in self.class_info]))
self.source_class_ids = {}
# Loop over datasets
for source in self.sources:
self.source_class_ids[source] = []
# Find classes that belong to this dataset
for i, info in enumerate(self.class_info):
# Include BG class in all datasets
if i == 0 or source == info['source']:
self.source_class_ids[source].append(i)至此,数据已经准备完毕!
5、建立模型:
# Create model in training mode
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# Which weights to start with?
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# Load weights trained on MS COCO, but skip layers that
# are different due to the different number of classes
# See README for instructions to download the COCO weights
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
# Load the last model you trained and continue training
model.load_weights(model.find_last(), by_name=True)class MaskRCNN():
"""Encapsulates the Mask RCNN model functionality.
The actual Keras model is in the keras_model property.
"""
def __init__(self, mode, config, model_dir):
"""
mode: Either "training" or "inference"
config: A Sub-class of the Config class
model_dir: Directory to save training logs and trained weights
"""
assert mode in ['training', 'inference']
self.mode = mode
self.config = config
self.model_dir = model_dir
self.set_log_dir()
self.keras_model = self.build(mode=mode, config=config)
def build(self, mode, config):
"""Build Mask R-CNN architecture.
input_shape: The shape of the input image.
mode: Either "training" or "inference". The inputs and
outputs of the model differ accordingly.
"""
assert mode in ['training', 'inference']
# Image size must be dividable by 2 multiple times
h, w = config.IMAGE_SHAPE[:2]
if h / 2**6 != int(h / 2**6) or w / 2**6 != int(w / 2**6):
raise Exception("Image size must be dividable by 2 at least 6 times "
"to avoid fractions when downscaling and upscaling."
"For example, use 256, 320, 384, 448, 512, ... etc. ")
# Inputs
# 使用Keras建立模型
input_image = KL.Input(
shape=[None, None, config.IMAGE_SHAPE[2]], name="input_image")
input_image_meta = KL.Input(shape=[config.IMAGE_META_SIZE],
name="input_image_meta")
if mode == "training":
# RPN GT
# 建立RPN网络,RPN的两个GT输入分别是:bbox、是否是前景
input_rpn_match = KL.Input(
shape=[None, 1], name="input_rpn_match", dtype=tf.int32)
input_rpn_bbox = KL.Input(
shape=[None, 4], name="input_rpn_bbox", dtype=tf.float32)
# Detection GT (class IDs, bounding boxes, and masks)
# 1. GT Class IDs (zero padded)
# 分类网络的gt输入
input_gt_class_ids = KL.Input(
shape=[None], name="input_gt_class_ids", dtype=tf.int32)
# 2. GT Boxes in pixels (zero padded)
# [batch, MAX_GT_INSTANCES, (y1, x1, y2, x2)] in image coordinates
# 定位网络的gt输入
input_gt_boxes = KL.Input(
shape=[None, 4], name="input_gt_boxes", dtype=tf.float32)
# Normalize coordinates
gt_boxes = KL.Lambda(lambda x: norm_boxes_graph(
x, K.shape(input_image)[1:3]))(input_gt_boxes)
# 3. GT Masks (zero padded)
# Mask Branch的gt输入
# [batch, height, width, MAX_GT_INSTANCES]
if config.USE_MINI_MASK: # true MINI_MASK:56x56
input_gt_masks = KL.Input(
shape=[config.MINI_MASK_SHAPE[0],
config.MINI_MASK_SHAPE[1], None],
name="input_gt_masks", dtype=bool)
else:
input_gt_masks = KL.Input(
shape=[config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1], None],
name="input_gt_masks", dtype=bool)
elif mode == "inference":
# Anchors in normalized coordinates
input_anchors = KL.Input(shape=[None, 4], name="input_anchors")
# Build the shared convolutional layers.
# Bottom-up Layers
# Returns a list of the last layers of each stage, 5 in total.
# Don't create the thead (stage 5), so we pick the 4th item in the list.
# 建立resnet模型,同时导出[C2,C3,C4,C5]层
if callable(config.BACKBONE):
_, C2, C3, C4, C5 = config.BACKBONE(input_image, stage5=True,
train_bn=config.TRAIN_BN)
else:
_, C2, C3, C4, C5 = resnet_graph(input_image, config.BACKBONE,
stage5=True, train_bn=config.TRAIN_BN)
# Top-down Layers
# TODO: add assert to varify feature map sizes match what's in config
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c5p5')(C5)
P4 = KL.Add(name="fpn_p4add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p5upsampled")(P5),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c4p4')(C4)])
P3 = KL.Add(name="fpn_p3add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p4upsampled")(P4),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c3p3')(C3)])
P2 = KL.Add(name="fpn_p2add")([
KL.UpSampling2D(size=(2, 2), name="fpn_p3upsampled")(P3),
KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (1, 1), name='fpn_c2p2')(C2)])
# Attach 3x3 conv to all P layers to get the final feature maps.
P2 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p2")(P2)
P3 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p3")(P3)
P4 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p4")(P4)
P5 = KL.Conv2D(config.TOP_DOWN_PYRAMID_SIZE, (3, 3), padding="SAME", name="fpn_p5")(P5)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
P6 = KL.MaxPooling2D(pool_size=(1, 1), strides=2, name="fpn_p6")(P5)
# Note that P6 is used in RPN, but not in the classifier heads.
rpn_feature_maps = [P2, P3, P4, P5, P6]
mrcnn_feature_maps = [P2, P3, P4, P5]
# Anchors
if mode == "training":
anchors = self.get_anchors(config.IMAGE_SHAPE)
# Duplicate across the batch dimension because Keras requires it
# TODO: can this be optimized to avoid duplicating the anchors?
anchors = np.broadcast_to(anchors, (config.BATCH_SIZE,) + anchors.shape)
# A hack to get around Keras's bad support for constants
anchors = KL.Lambda(lambda x: tf.Variable(anchors), name="anchors")(input_image)
else:
anchors = input_anchors
# RPN Model
rpn = build_rpn_model(config.RPN_ANCHOR_STRIDE,
len(config.RPN_ANCHOR_RATIOS), config.TOP_DOWN_PYRAMID_SIZE)
# Loop through pyramid layers
layer_outputs = [] # list of lists,装入的结果[[rpn_class_logits, rpn_probs, rpn_bbox]],列表的列表
# 对于[P2, P3, P4, P5, P6]中的每个元素分别使用rpn网络
for p in rpn_feature_maps:
layer_outputs.append(rpn([p]))
# Concatenate layer outputs
# Convert from list of lists of level outputs to list of lists
# of outputs across levels.
# e.g. [[a1, b1, c1], [a2, b2, c2]] => [[a1, a2], [b1, b2], [c1, c2]]
output_names = ["rpn_class_logits", "rpn_class", "rpn_bbox"]
outputs = list(zip(*layer_outputs))
outputs = [KL.Concatenate(axis=1, name=n)(list(o))
for o, n in zip(outputs, output_names)]
#各个尺度的rpn结果进行融合的结果
rpn_class_logits, rpn_class, rpn_bbox = outputs
# Generate proposals
# Proposals are [batch, N, (y1, x1, y2, x2)] in normalized coordinates
# and zero padded.
proposal_count = config.POST_NMS_ROIS_TRAINING if mode == "training"\
else config.POST_NMS_ROIS_INFERENCE
rpn_rois = ProposalLayer(
proposal_count=proposal_count,
nms_threshold=config.RPN_NMS_THRESHOLD,
name="ROI",
config=config)([rpn_class, rpn_bbox, anchors])
if mode == "training":
# Class ID mask to mark class IDs supported by the dataset the image
# came from.
active_class_ids = KL.Lambda(
lambda x: parse_image_meta_graph(x)["active_class_ids"]
)(input_image_meta)
if not config.USE_RPN_ROIS:
# Ignore predicted ROIs and use ROIs provided as an input.
input_rois = KL.Input(shape=[config.POST_NMS_ROIS_TRAINING, 4],
name="input_roi", dtype=np.int32)
# Normalize coordinates
target_rois = KL.Lambda(lambda x: norm_boxes_graph(
x, K.shape(input_image)[1:3]))(input_rois)
else:
target_rois = rpn_rois
# Generate detection targets
# Subsamples proposals and generates target outputs for training
# Note that proposal class IDs, gt_boxes, and gt_masks are zero
# padded. Equally, returned rois and targets are zero padded.
rois, target_class_ids, target_bbox, target_mask =\
DetectionTargetLayer(config, name="proposal_targets")([
target_rois, input_gt_class_ids, gt_boxes, input_gt_masks])
# Network Heads
# TODO: verify that this handles zero padded ROIs
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
fpn_classifier_graph(rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
mrcnn_mask = build_fpn_mask_graph(rois, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
# TODO: clean up (use tf.identify if necessary)
output_rois = KL.Lambda(lambda x: x * 1, name="output_rois")(rois)
# Losses
rpn_class_loss = KL.Lambda(lambda x: rpn_class_loss_graph(*x), name="rpn_class_loss")(
[input_rpn_match, rpn_class_logits])
rpn_bbox_loss = KL.Lambda(lambda x: rpn_bbox_loss_graph(config, *x), name="rpn_bbox_loss")(
[input_rpn_bbox, input_rpn_match, rpn_bbox])
class_loss = KL.Lambda(lambda x: mrcnn_class_loss_graph(*x), name="mrcnn_class_loss")(
[target_class_ids, mrcnn_class_logits, active_class_ids])
bbox_loss = KL.Lambda(lambda x: mrcnn_bbox_loss_graph(*x), name="mrcnn_bbox_loss")(
[target_bbox, target_class_ids, mrcnn_bbox])
mask_loss = KL.Lambda(lambda x: mrcnn_mask_loss_graph(*x), name="mrcnn_mask_loss")(
[target_mask, target_class_ids, mrcnn_mask])
# Model
inputs = [input_image, input_image_meta,
input_rpn_match, input_rpn_bbox, input_gt_class_ids, input_gt_boxes, input_gt_masks]
if not config.USE_RPN_ROIS:
inputs.append(input_rois)
outputs = [rpn_class_logits, rpn_class, rpn_bbox,
mrcnn_class_logits, mrcnn_class, mrcnn_bbox, mrcnn_mask,
rpn_rois, output_rois,
rpn_class_loss, rpn_bbox_loss, class_loss, bbox_loss, mask_loss]
model = KM.Model(inputs, outputs, name='mask_rcnn')
else:
# Network Heads
# Proposal classifier and BBox regressor heads
mrcnn_class_logits, mrcnn_class, mrcnn_bbox =\
fpn_classifier_graph(rpn_rois, mrcnn_feature_maps, input_image_meta,
config.POOL_SIZE, config.NUM_CLASSES,
train_bn=config.TRAIN_BN,
fc_layers_size=config.FPN_CLASSIF_FC_LAYERS_SIZE)
# Detections
# output is [batch, num_detections, (y1, x1, y2, x2, class_id, score)] in
# normalized coordinates
detections = DetectionLayer(config, name="mrcnn_detection")(
[rpn_rois, mrcnn_class, mrcnn_bbox, input_image_meta])
# Create masks for detections
detection_boxes = KL.Lambda(lambda x: x[..., :4])(detections)
mrcnn_mask = build_fpn_mask_graph(detection_boxes, mrcnn_feature_maps,
input_image_meta,
config.MASK_POOL_SIZE,
config.NUM_CLASSES,
train_bn=config.TRAIN_BN)
model = KM.Model([input_image, input_image_meta, input_anchors],
[detections, mrcnn_class, mrcnn_bbox,
mrcnn_mask, rpn_rois, rpn_class, rpn_bbox],
name='mask_rcnn')
# Add multi-GPU support.
if config.GPU_COUNT > 1:
from mrcnn.parallel_model import ParallelModel
model = ParallelModel(model, config.GPU_COUNT)
return model6、训练:
如果只训练 head branches
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=1,
layers='heads')如果要训练所有的层
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 10,
epochs=2,
layers="all")7、定位
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
inference_config = InferenceConfig()
# Recreate the model in inference mode
model = modellib.MaskRCNN(mode="inference",
config=inference_config,
model_dir=MODEL_DIR)
# Get path to saved weights
# Either set a specific path or find last trained weights
# model_path = os.path.join(ROOT_DIR, ".h5 file name here")
model_path = model.find_last()
# Load trained weights
print("Loading weights from ", model_path)
model.load_weights(model_path, by_name=True)# Test on a random image
image_id = random.choice(dataset_val.image_ids)
original_image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
log("original_image", original_image)
log("image_meta", image_meta)
log("gt_class_id", gt_class_id)
log("gt_bbox", gt_bbox)
log("gt_mask", gt_mask)
visualize.display_instances(original_image, gt_bbox, gt_mask, gt_class_id,
dataset_train.class_names, figsize=(8, 8))
results = model.detect([original_image], verbose=1)
r = results[0]
visualize.display_instances(original_image, r['rois'], r['masks'], r['class_ids'],
dataset_val.class_names, r['scores'], ax=get_ax())

8、验证
# Compute VOC-Style mAP @ IoU=0.5
# Running on 10 images. Increase for better accuracy.
image_ids = np.random.choice(dataset_val.image_ids, 10)
APs = []
for image_id in image_ids:
# Load image and ground truth data
image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
molded_images = np.expand_dims(modellib.mold_image(image, inference_config), 0)
# Run object detection
results = model.detect([image], verbose=0)
r = results[0]
# Compute AP
AP, precisions, recalls, overlaps =\
utils.compute_ap(gt_bbox, gt_class_id, gt_mask,
r["rois"], r["class_ids"], r["scores"], r['masks'])
APs.append(AP)
print("mAP: ", np.mean(APs))输出: mAP: 0.95