WebCollector 简介与 快速入门
目录
WebCollerctor 简介
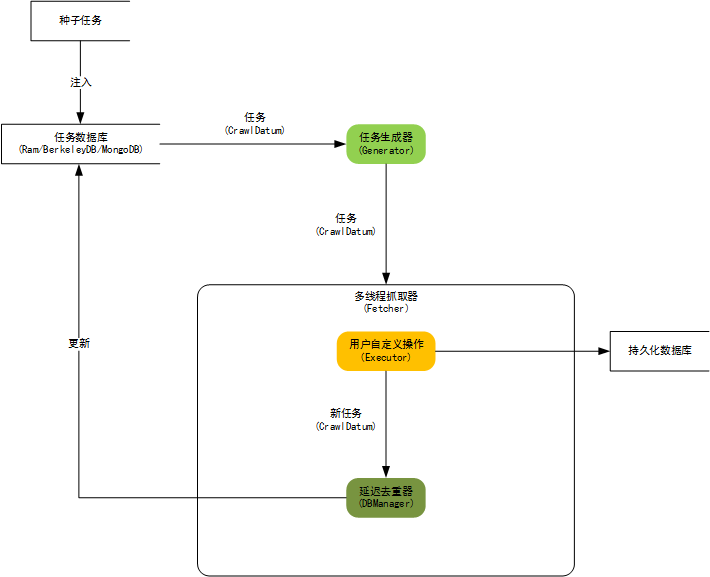
内核构架图
WebCollector 2.x 版本特性
WebCollector 快速入门
WebCollerctor 简介
1、WebCollector 是一个无须配置、便于二次开发的 JAVA 爬虫框架(内核),提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。
2、源码中集成了 Jsoup,可进行精准的网页解析,2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
3、WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
4、Github 上项目托管地址:https://github.com/CrawlScript/WebCollector
5、GitEE 上开源地址:http://git.oschina.net/webcollector/WebCollector
6、开源中国教程地址:http://www.oschina.net/p/webcollector
7、网络爬虫与数据挖掘教程地址:http://datahref.com/
内核构架图
WebCollector 2.x 版本特性
1、自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
2、可以为每个 URL 设置附加信息(MetaData),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
3、使用插件机制,用户可定制自己的 Http 请求、过滤器、执行器等插件。
4、内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
5、内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
6、集成 selenium,可以对 JavaScript 生成信息进行抽取
7、可轻松自定义 http 请求,并内置多代理随机切换功能。 可通过定义 http 请求实现模拟登录。
8、使用 slf4j 作为日志门面,可对接多种日志
9、使用类似Hadoop的Configuration机制,可为每个爬虫定制配置信息。
WebCollector 快速入门
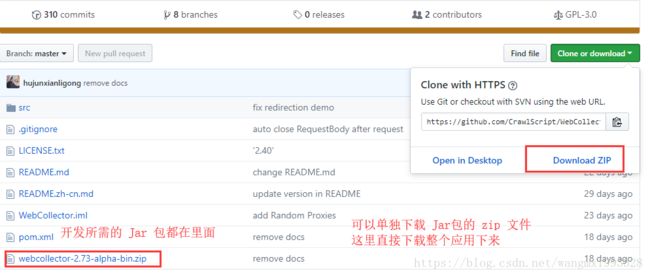
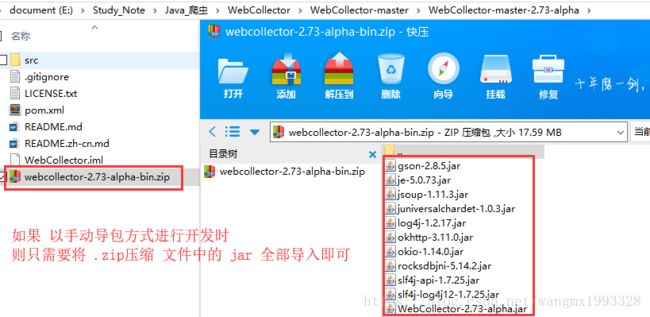
1、使用 WebCollector 步骤非常简单,可以直接从 GitHub 上下载打包好的 Jar 然后导入项目中,之后即可使用
2、当然 GitHub 上也提供了 webCollector 的 Maven 依赖,可以使用 Maven 项目进行开发
开发包获取
1、都可以从 GitHub 获取:https://github.com/CrawlScript/WebCollector
Maven 依赖
1、GitHub :https://github.com/CrawlScript/WebCollector 上同样提供了 Maven 依赖
2、上面下载的源码中的 README.md 文件中也可以找到
cn.edu.hfut.dmic.webcollector
WebCollector
2.73-alpha
DemoAutoNewsCrawler
1、GitHub 的 webCollector 主页 提供了官方示例,可以直接进行复制运行
2、这里就以第一个 DemoAutoNewsCrawler (自动探测新闻爬取)为例
import cn.edu.hfut.dmic.webcollector.model.CrawlDatums;
import cn.edu.hfut.dmic.webcollector.model.Page;
import cn.edu.hfut.dmic.webcollector.plugin.rocks.BreadthCrawler;
/**
* Crawling news from github news
* 自动爬取新闻网站,继承 BreadthCrawler(广度爬虫)
* BreadthCrawler 是 WebCollector 最常用的爬取器之一
*
* @author hu
*/
public class DemoAutoNewsCrawler extends BreadthCrawler {
/**
* @param crawlPath crawlPath is the path of the directory which maintains
* information of this crawler
* @param autoParse if autoParse is true,BreadthCrawler will auto extract
* links which match regex rules from pag
*/
public DemoAutoNewsCrawler(String crawlPath, boolean autoParse) {
super(crawlPath, autoParse);
/**设置爬取的网站地址
* addSeed 表示添加种子
* 种子链接会在爬虫启动之前加入到抓取信息中并标记为未抓取状态.这个过程称为注入*/
this.addSeed("https://blog.github.com/");
/**
* 循环添加了4个种子,其实就是分页,结果类似:
* https://blog.github.com/page/2/
* https://blog.github.com/page/3/
* https://blog.github.com/page/4/
* https://blog.github.com/page/5/
*/
for (int pageIndex = 2; pageIndex <= 5; pageIndex++) {
String seedUrl = String.format("https://blog.github.com/page/%d/", pageIndex);
this.addSeed(seedUrl);
}
/** addRegex 参数为一个 url 正则表达式, 可以用于过滤不必抓取的链接,如 .js .jpg .css ... 等
* 也可以指定抓取某些规则的链接,如下 addRegex 中会抓取 此类地址:
* https://blog.github.com/2018-07-13-graphql-for-octokit/
* */
this.addRegex("https://blog.github.com/[0-9]{4}-[0-9]{2}-[0-9]{2}-[^/]+/");
/**
* 过滤 jpg|png|gif 等图片地址 时:
* this.addRegex("-.*\\.(jpg|png|gif).*");
* 过滤 链接值为 "#" 的地址时:
* this.addRegex("-.*#.*");
*/
/**设置线程数*/
setThreads(50);
getConf().setTopN(100);
/**
* 是否进行断电爬取,默认为 false
* setResumable(true);
*/
}
/**
* 必须重写 visit 方法,作用是:
* 在整个抓取过程中,只要抓到符合要求的页面,webCollector 就会回调该方法,并传入一个包含了页面所有信息的 page 对象
*
* @param page
* @param next
*/
@Override
public void visit(Page page, CrawlDatums next) {
String url = page.url();
/**如果此页面地址 确实是要求爬取网址,则进行取值
*/
if (page.matchUrl("https://blog.github.com/[0-9]{4}-[0-9]{2}-[0-9]{2}[^/]+/")) {
/**
* 通过 选择器 获取页面 标题以及 正文内容
* */
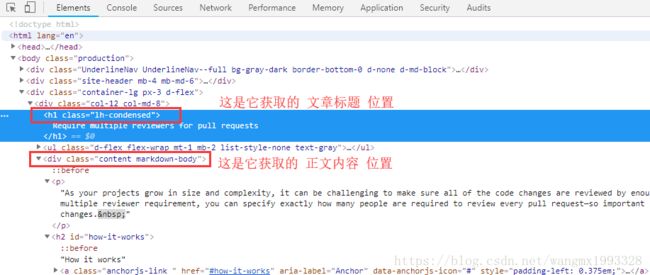
String title = page.select("h1[class=lh-condensed]").first().text();
String content = page.selectText("div.content.markdown-body");
System.out.println("URL:\n" + url);
System.out.println("title:\n" + title);
System.out.println("content:\n" + content);
}
}
public static void main(String[] args) throws Exception {
/**
* DemoAutoNewsCrawler 构造器中会进行 数据初始化,这两个参数接着会传给父类
* super(crawlPath, autoParse);
* crawlPath:表示设置保存爬取记录的文件夹,本例运行之后会在应用根目录下生成一个 "crawl" 目录存放爬取信息
* */
DemoAutoNewsCrawler crawler = new DemoAutoNewsCrawler("crawl", true);
/**
* 启动爬虫,爬取的深度为4层
* 添加的第一层种子链接,为第1层
*/
crawler.start(4);
}
}
运行结果
1、如下所示爬取是成功的,爬取结果有点多,截取其中少部分
2018-08-14 14:03:32 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 1
2018-08-14 14:03:32 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - start merge
2018-08-14 14:03:33 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge fetch database
2018-08-14 14:03:33 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge link database
2018-08-14 14:03:34 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - end merge
2018-08-14 14:03:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - init segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager
2018-08-14 14:03:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - create generator:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksGenerator
2018-08-14 14:03:35 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - use generatorFilter:cn.edu.hfut.dmic.webcollector.crawldb.StatusGeneratorFilter
2018-08-14 14:03:36 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=5, spinWaiting=0, fetchQueue.size=0
2018-08-14 14:03:37 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=5, spinWaiting=0, fetchQueue.size=0
2018-08-14 14:03:37 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/page/2/ (URL: https://blog.github.com/page/2/)
2018-08-14 14:03:37 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/ (URL: https://blog.github.com/)
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/page/5/ (URL: https://blog.github.com/page/5/)
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/page/3/ (URL: https://blog.github.com/page/3/)
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/page/4/ (URL: https://blog.github.com/page/4/)
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=0, spinWaiting=0, fetchQueue.size=0
.....
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - depth 1 finish:
total urls: 5
total time: 5 seconds
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 2
2018-08-14 14:03:38 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - start merge
2018-08-14 14:03:39 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge fetch database
2018-08-14 14:03:39 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge link database
.....
URL:
https://blog.github.com/2018-03-23-require-multiple-reviewers/
title:
Require multiple reviewers for pull requests
content:
As your projects grow in size and complexity, it can be challenging to make sure all of the code changes are reviewed by enough people on your team. Now, with the a multiple reviewer requirement, you can specify exactly how many people are required to review every pull request—so important projects are protected from unwanted changes. How it works To require multiple reviewers for pull requests, go to your repository’s settings and select “Branches”. Under “Protected branches”, select the branch you’d like to protect with a multiple reviewers requirement. There you can select the number of reviewers required for each pull request to that branch. After you’ve selected the number of reviewers, you’ll see that number and the status of their reviews in the sidebar and merge section of pull requests to protected branches. Learn more about required reviews for pull requests
2018-08-14 14:03:42 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/2018-03-23-require-multiple-reviewers/ (URL: https://blog.github.com/2018-03-23-require-multiple-reviewers/)
URL:
https://blog.github.com/2018-05-02-issue-template-improvements/
title:
Issue template improvements
content:
As more people contribute to your project, the issue tracker can start to feel hectic. We recently helped project maintainers set up multiple issue templates as a way to manage contributions, and now we’re following up with a better contributor experience and improved setup process. When someone opens a new issue in your project, you can now prompt them to choose from multiple issue types. To add this experience to your repository, go to the “Settings” tab and click Set up templates—or add a template from your community profile. You’ll be able to use a builder to preview and edit existing templates or create a custom template. Once these changes are merged into master, the new issue templates will be live for contributors. Head over to your project settings to get started. Learn more about creating issue templates
2018-08-14 14:03:42 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - done: [200] Key: https://blog.github.com/2018-05-02-issue-template-improvements/ (URL: https://blog.github.com/2018-05-02-issue-template-improvements/)
......
2018-08-14 14:03:55 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - start depth 4
2018-08-14 14:03:55 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - start merge
2018-08-14 14:03:55 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge fetch database
2018-08-14 14:03:56 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - merge link database
2018-08-14 14:03:56 INFO cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager - end merge
2018-08-14 14:03:57 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - init segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager
2018-08-14 14:03:58 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - create generator:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksGenerator
2018-08-14 14:03:58 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - use generatorFilter:cn.edu.hfut.dmic.webcollector.crawldb.StatusGeneratorFilter
2018-08-14 14:03:58 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - -activeThreads=0, spinWaiting=0, fetchQueue.size=0
2018-08-14 14:03:58 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - clear all activeThread
2018-08-14 14:03:58 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - close generator:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksGenerator
2018-08-14 14:03:59 INFO cn.edu.hfut.dmic.webcollector.fetcher.Fetcher - close segmentWriter:cn.edu.hfut.dmic.webcollector.plugin.rocks.RocksDBManager
2018-08-14 14:03:59 INFO cn.edu.hfut.dmic.webcollector.crawler.Crawler - depth 4 finish:
total urls: 0
total time: 3 seconds
Process finished with exit code 0