简介
经过上次轻松搭建了一个Redis的环境并用Java代码调通后,这次我们要来看看Redis的一些坑以及Redis2.8以后带来的一个新的特性即支持高可用特性功能的Sentinel(哨兵)。
Redis的一些坑
Redis是一个很优秀的NoSql,它支持键值对,查询方便,被大量应用在Internet的应用中,它即可以用作Http Session的分离如上一次举例中的和Spring Session的结合,还可以直接配置在Tomcat中和Tomcat容器结合并可以自动使用Redis作Session盛载器,同时它也可以作为一个分布式缓存。
Redis是单线程工作的
这边的单线程不是指它就是顺序式工作的,这边的单线程主要关注的是Redis的一个很重要的功能即“持久化”工作机制。Redis一般会使用两种持久化工作机制,这种工作机制如果在单个Redis Node下工作是没有意义的,因此你必须要有两个Redis Nodes,如:
| IP |
端口 |
身份 |
| 192.168.56.101 |
7001 |
主节点 |
| 192.168.56.101 |
7002 |
备节点 |
Redis所谓的持久化就是在N个Redis节点间进行数据同步用的,因为在复杂的网络环境下Redis服务有时会崩溃,此时主备结构就成了高可用方案中最常用的一种手段,那么在主机宕机时,备机顶上此时会存在一个主机和备机间数据同步的问题,最好的情况是备机可以保有主机中所有的数据以便在主机宕掉时无差异的为客户进行着持续化的服务。因此Redis会使用RDB和AOF模式来保持多个Redis节点间的数据同步。
RDB
RDB 的优点:
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF
AOF 的优点:
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
RDB 和 AOF间的选择
一般来说,如果想达到足以媲美 PostgreSQL 的数据安全性, 你应该同时使用两种持久化功能。如果你非常关心你的数据,但仍然可以承受数分钟以内的数据丢失, 那么你可以只使用 RDB 持久化。有很多用户都只使用 AOF 持久化, 但我们并不推荐这种方式: 因为定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快, 除此之外, 使用 RDB 还可以避免之前提到的 AOF 程序的 bug 。
如我在上篇中所述,RDB与AOF可以同时启用,那么就做到了“数据高同步不丢失”的效果,可是你会应此付出高昂的网络IO开销,因为在使用AOF进行数据同步时造成的网络读写也是开销很大的。
因此这就要看你的设计了,一般来说一个设计不能够因为缓冲服务宕了或者不可用了而影响到整个应用不能使用,如果设计成这样那么这样的架构是比较糟糕的。
举一例来说:
用户登录后正在操作,他正在查询着订单,其中有一部分数据来自于缓存,这时缓存死了,用户的查询行为此时应该被导向至DB而等缓存被恢复后才应该重新去查缓存,当然如果在缓存中找不到相关的信息自然还是应该去找数据库,对不对?
因此你的伪代码应该是:
object=queryFromCache();
if(object==null||queryFromCache throw any exception)
{
object=queryFromDB();
}
如果因为缓存服务不存在而在queryFromCache时抛错一个exception以致于页面直接回一个HTTP 500 error给用户那是相当的不合理的。
因此,在缓存服务停止时你的DB在缓存被恢复前是需要顶出去的,如果说你的DB连这点时间都不能顶,那就需要好好的来优化你的DB内的操作了。
再举一例来说:
在一主一备的缓存环境下,用户正在访问,此时主缓存服务器宕机了,备用机顶上去了,而此时当中有7-10分钟左右数据丢失,这样的数据丢失不应该影响用户的连续性操作即用户不应该感觉到有服务切换的这种感觉比如说:要求 用户重新做一个什么操作,这种设计是不对的,因此你的设计上要有冗余,比如说用户正在操作时此时一切都在master nodes中,而此时master nodes突然崩溃了你的slave nodes顶上时在设计上你要允许用户可以丢失缓存中的数据这样的形为,比如说可以用DB顶上,或者是用二级缓存,或者是用内存数据库。。。bla...bla...bla...这里具体就要看业务了。
上面说了这些,并不是说我们就可以因此不追求数据同步完整性了,而是要回到Redis这个坑,即数据同步时的一个坑。
Redis它是单线程的,当master和slave在正常工作时everything ok,它会保持着两个节点中数据基本的同步,如果你开了AOF那你的同步率会很高。
但是,一旦当master宕机时,slave会变成master,这时它会使用它本身所在目录内的RDB文件来作为持久化的入口,此时还是everything ok,接着那台原先宕机的旧master重新被恢复后。。。此时这台旧的master上的RDB文件和从slave位置被提升成master(new master)间的RDB文件的出入,是不是就会比较高啊。。。因此此时old master会试图和新的master进行RDB间的数据同步,而这个同步。。。是非常要命的,如果你的用户并发量很大,在一瞬时内你的rdb增长的会非常高,因此当两个redis nodes在同步RDB文件时就会直接把你的现在的new master(原来的slave)搞死进而搞死你的old master(原来的master),因为它是单线程的,大数据量在同步时它会ban掉任何的访问请求。
因此,在设有master & slave模式环境内的redis,请一定记得把配置文件中的这一行:
slave-serve-stale-data 设置为
yes。
来看看slave-server-stale-data为什么要设成yes的原因吧:
1) 如果 slave-serve-stale-data 设置成 'yes' (the default) slave会仍然响应客户端请求,此时可能会有问题。
2) 如果 slave-serve-stale data设置成 'no' slave会返回"SYNC with master in progress"这样的错误信息。 但 INFO 和SLAVEOF命令除外。
想一下,当master-slave节点在因为master节点有问题做切换时,此时不管是因为slave在被提升(promopted)到master时需要同步数据还是因为原有的master在宕机后再恢复而被decreased成了slave而同步new master数据时造成的“阻塞”,如果此时slave-server-stale-data设成了no。。。那么你将会没有一个可用的redis节点进而把整个环境搞死。
因此这也是为什么我上面要说设计上不能过多依赖于Redis的原因,它只因该是你一个锦上添花的东西,是一个辅助手段。
THP(Transparent Huge Pages)
这也是Redis的一个坑,来看看什么是THP吧,Transparent Huge Pages。
Redis是安装在Linux上的一个服务
Linux本身的页大小是固定的4KB,在2.6.38内核新增了THP,透明地支持huge page(2MB)的使用,并且默认开启。
- 减少page fault。一次page fault可以加载更大的内存块.。
- 更小的页表。相同的内存大小,需要更少的页。
- 由于页表更小,虚拟地址到物理地址的翻译也更快。
- 降低分配内存效率。需要大块、连续内存块,内核线程会比较激进的进行compaction,解决内存碎片,加剧锁争用。
- 降低IO吞吐。由于swapable huge page,在swap时需要切分成原有的4K的页。Oracle的测试数据显示会降低30%的IO吞吐。
- 对于redis而言,开启THP的优势:fork子进程的时间大幅减少。fork进程的主要开销是拷贝页表、fd列表等进程数据结构。由于页表大幅较小(2MB / 4KB = 512倍),fork的耗时也会大幅减少。
- 劣势在于: fork之后,父子进程间以copy-on-write方式共享地址空间。如果父进程有大量写操作,并且不具有locality,会有大量的页被写,并需要拷贝。同时,由于开启THP,每个页2MB,会大幅增加内存拷贝。
针对这个特性,我做了一个测试,分别在开启和关闭THP的情况下,测试redis的fork、响应时间。
测试条件:redis数据集大小20G, rdb文件大小4.2G 我用jmeter做了100个并发乘1万的压力测试,测试过程中写要比读频繁。
- fork时间对比 开启THP后,fork大幅减少。
- 超时次数对比 开启THP后,超时次数明显增多,但是每次超时时间较短。而关闭THP后,只有4次超时,原因是与fork在同一事件循环的请求受到fork的影响。 关闭THP影响的只是零星几个请求,而开启后,虽然超时时间短了,但是影响面扩大了进而导致了整个Linux系统的不稳定。
因此,针对上述情况,建议大家在Linux系统中发一条这个命令:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
Redis的maxmemory 0的问题
Redis配置文件中的这一行代表Redis会使用系统内存,你不该去限制Redis的内存开销如:JVM中的-xmx这个参数,而是要让Redis自动去使用系统的内存以获得最高的性能,因此我们会把这个值设成0即代表无限使用系统内存,系统内存有多少我们用多少。默认它启动后会消耗掉1个G的系统自有内存。
因此linux系统中有一个系统参数叫overcommit_memory,它代表的是内存分配策略,可选值为:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
所以我们结合我们的Redis使用以下的linux命令:
echo 1 > /proc/sys/vm/overcommit_memory
上述两条命令发完后不要完了刷新系统内存策略,因此我们接着发出一条命令
sysctl -p
Redis在Linux系统中Too many open files的问题
有时位于系统访问高峰时间段突发的大量请求导致redis连接数过大,你会收到这样的错误信息:
Too many open files.
这是因为频繁访问Redis时造成了TCP连接数打开过大的主要原因, 这是因为Redis源码中在accept tcp socket时的实现里面遇到句柄数不够的处理方法为:留在下次处理,而不是断开TCP连接。
但这一行为就会导致监听套接字不断有可读消息,但却accept无法接受,从而listen的backlog被塞满;从而导致后面的连接被RST了。
这里我多啰嗦一下也就是Redis和Memcached的比较,memcached对于这种情况的处理有点特殊,或者说周到!
如果memcache accept 的时候返回EMFILE,那么它会立即调用listen(sfd, 0) , 也就是将监听套接字的等待accept队列的backlog设置为0,从而拒绝掉这部分请求,减轻系统负载,保全自我。
因此为了对付这个too many open files问题我们需要在Linux下做点小动作来改变ulimit的配置。
- 修改/etc/security/limits.conf
通过 vi /etc/security/limits.conf修改其内容,在文件最后加入(数值也可以自己定义):
* soft nofile = 65535
* hard nofile = 65535
通过vi /etc/profile修改,在最后加入以下内容
ulimit -n 65535
修改完后重启Linux系统。
通过上述一些设置,我们基本完成了Redis在做集群前的准备工作了,下面就来使用Redis的Sentinel来做我们的高可用方案吧。
使用Redis Sentinel来做HA
sentinel是一个管理redis实例的工具,它可以实现对redis的监控、通知、自动故障转移。sentinel不断的检测redis实例是否可以正常工作,通过API向其他程序报告redis的状态,如果redis master不能工作,则会自动启动故障转移进程,将其中的一个slave提升为master,其他的slave重新设置新的master服务器。
sentinel是一个分布式系统,在源码包的src目录下会有redis-sentinel命令,你甚至还可以在多台机器上部署sentinel进程,共同监控redis实例。
- 一个Master可以有多个Slave;
- Redis使用异步复制。从2.8开始,Slave会周期性(每秒一次)发起一个Ack确认复制流(replication stream)被处理进度;
- 不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个图状结构;
- 复制在Master端是非阻塞模式的,这意味着即便是多个Slave执行首次同步时,Master依然可以提供查询服务;
- 复制在Slave端也是非阻塞模式的:如果你在redis.conf做了设置,Slave在执行首次同步的时候仍可以使用旧数据集提供查询;你也可以配置为当Master与Slave失去联系时,让Slave返回客户端一个错误提示;
- 当Slave要删掉旧的数据集,并重新加载新版数据时,Slave会阻塞连接请求(一般发生在与Master断开重连后的恢复阶段);
- 复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability): 比如说, 繁重的 SORT 命令可以交给附属节点去运行。
- 可以通过修改Master端的redis.config来避免在Master端执行持久化操作(Save),由Slave端来执行持久化。
Redis Sentinel规划
考虑到大多数学习者环境有限,我们使用如下配置:
| IP |
端口 |
身份 |
| 192.168.56.101 |
7001 |
master |
| 192.168.56.101 |
7002 |
slave |
| 192.168.56.101 |
26379 |
sentinel |
所以我们在一台服务器上安装3个目录:
- redis1-对应master
- redis2-对应slave
- redis-sentinel对应sentinel,它使用26379这个端口来监控master和slave
因此我们使用redis-stable源码包来如此构建我们的实验环境
make PREFIX=/usr/local/redis1 install
make PREFIX=/usr/local/redis2 install
make PREFIX=/usr/local/redis-sentinel install
下面给出sentinel的配置
Sentinel中的配置
更改/usr/local/redis-sentinel/bin/sentinel.conf文件:
port 26379
daemonize yes
logfile "/var/log/redis/sentinel.log"
sentinel monitor master1 192.168.56.101 7001 1
sentinel down-after-milliseconds master1 1000
sentinel failover-timeout master1 5000
#sentinel can-failover master1 yes #remove from 2.8 and aboved version
- daemonize yes – 以后台进程模式运行
- port 26379 – 哨兵的端口号,该端口号默认为26379,不得与任何redis node的端口号重复
- logfile “/var/log/redis/sentinel.log“ – log文件所在地
- sentinel monitor master1 192.168.56.101 7001 1 – (第一次配置时)哨兵对哪个master进行监测,此处的master1为一“别名”可以任意如sentinel-26379,然后哨兵会通过这个别名后的IP知道整个该master内的slave关系。因此你不用在此配置slave是什么而由哨兵自己去维护这个“链表”。
- sentinel monitor master1 192.168.56.101 7001 1 – 这边有一个“1”,这个“1”代表当新master产生时,同时进行“slaveof”到新master并进行同步复制的slave个数。在salve执行salveof与同步时,将会终止客户端请求。此值较大,意味着“集群”终止客户端请求的时间总和和较大。此值较小,意味着“集群”在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。我们这边只想让一个slave来做此时的响应以取得较好的客户端体验。
- sentinel down-after-milliseconds master1 1000 – 如果master在多少秒内无反应哨兵会开始进行master-slave间的切换,使用“选举”机制
- sentinel failover-timeout master1 5000 – 如果在多少秒内没有把宕掉的那台master恢复,那哨兵认为这是一次真正的宕机,而排除该宕掉的master作为节点选取时可用的node然后等待一定的设定值的毫秒数后再来探测该节点是否恢复,如果恢复就把它作为一台slave加入哨兵监测节点群并在下一次切换时为他分配一个“选取号”。
- #sentinel can-failover master1 yes #remove from 2.8 and aboved version – 该功能已经从2.6版以后去除,因此注释掉,网上的教程不适合于redis-stable版
在配置Redis Sentinel做Redis的HA场景时,一定要注意下面几个点:
- 除非有多机房HA场景的存在,坚持使用单向链接式的master->slave的配置如:node3->node2->node1,把node1设为master
- 如果sentinel(哨兵)或者是HA群重启,一定要使用如此顺序:先启master,再启slave,再启哨兵
- 第一次配置完成“哨兵”HA群时每次启动不需要手动再去每个redis node中去更改master slave这些参数了,哨兵会在第一次启动后记录和动态修改每个节点间的关系,第一次配置好启动“哨兵”后由哨兵以后自行维护一般情况下不需要人为干涉,如果切换过一次master/slave后也因该记得永远先起master再起slave再起哨兵这个顺序,具体当前哪个是master可以直接看哨兵的sentinel.conf文件中最末尾哨兵自行的记录
Redis Master和Redis Slave的配置
这部分配置除了端口号,所在目录,pid文件与log文件不同其它配置相同,因此下面只给出一份配置:
daemonize yes
pidfile "/var/run/redis/redis1.pid"
port 7001
tcp-backlog 511
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/var/log/redis/redis1.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error no
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
dir "/usr/local/redis1/data"
slave-serve-stale-data yes
slave-read-only yes #slave只读,当你的应用程序试图向一个slave写数据时你会得到一个错误
repl-diskless-sync no
repl-disable-tcp-nodelay no
slave-priority 100
maxmemory 0
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# appendfsync always
#appendfsync everysec
appendfsync no #关闭AOF
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events "gxE"
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
其中:
- slave-read-only yes 我们把slave设成只读,当你的应用程序试图向一个slave写数据时你会得到一个错误
- appendfsync no 我们关闭了AOF功能
这是192.168.56.101:7001master上的配置,你要把192.168.56.101:7002作为slave,那很简单,你只需要在redis2的配置文件的最未尾加入一句:
slaveof 192.168.56.101 7001
配完了master, slave和sentinel后,我们按照这个顺序来启动redis HA:
master->slave->sentinel
启动后我们通过windows客户端使用命令:
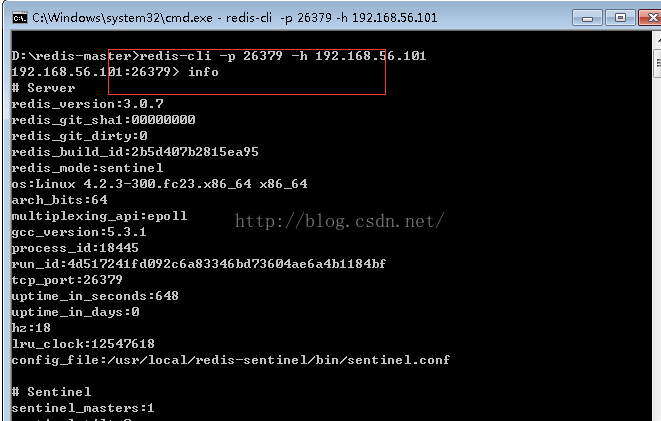
redis-cli -p 26379 -h 192.168.56.101
进入我们配置好的sentinel后并使用: info命令来查看我们的redis sentinel HA配置。
可以看到目前它的master为7001,它有一个slave。
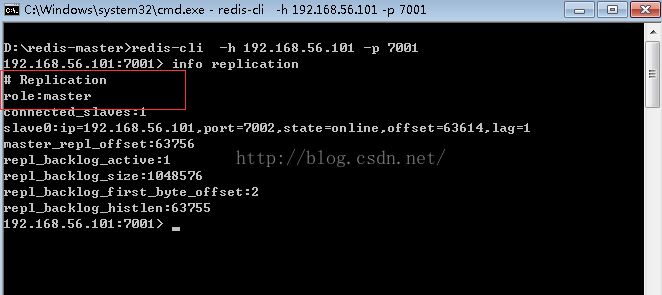
为了确认,我们另外开一个command窗口,通过:
redis-cli -p 7001 -h 192.168.56.101
进入到7001后再使用redis内部命令info replication来查看相关信息
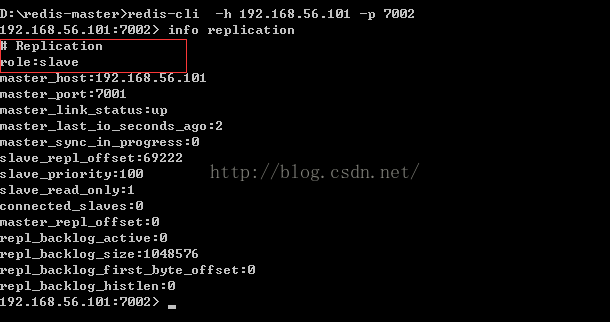
我们还可以通过命令:
redis-cli -h 192.168.56.101 -p 7002
进入到7002中并通过info replication来查看7002内的情况:
好了,环境有了,我们接下来要使用:
来测一下我们这个redis sentinel了的自动故障转移功能了。
使用 Spring Data + Jedis来访问我们的Redis Sentinel
pom.xml
4.0.0
webpoc
webpoc
0.0.1-SNAPSHOT
war
UTF-8
1.8
9.3.3.v20150827
1.7.7
4.2.1.RELEASE
1.0.2.RELEASE
2.5
5.8.0
3.8
org.apache.poi
poi
${poi_version}
org.apache.poi
poi-ooxml-schemas
${poi_version}
org.apache.poi
poi-scratchpad
${poi_version}
org.apache.poi
poi-ooxml
${poi_version}
org.apache.activemq
activemq-all
5.8.0
org.apache.activemq
activemq-pool
${activemq_version}
org.apache.xbean
xbean-spring
3.16
javax.servlet
servlet-api
${javax.servlet-api.version}
provided
javax.servlet.jsp
jsp-api
2.1
provided
javax.servlet
jstl
1.2
redis.clients
jedis
2.7.2
org.redisson
redisson
1.0.2
org.slf4j
jcl-over-slf4j
${slf4j.version}
org.slf4j
slf4j-log4j12
${slf4j.version}
org.springframework.data
spring-data-redis
1.6.2.RELEASE
org.springframework
spring-webmvc
${spring.version}
commons-logging
commons-logging
org.springframework
spring-tx
${spring.version}
org.springframework
spring-aop
${spring.version}
org.springframework
spring-context-support
${spring.version}
org.springframework
spring-orm
${spring.version}
org.springframework
spring-jms
${spring.version}
org.springframework.session
spring-session
${spring.session.version}
org.springframework
spring-core
${spring.version}
src
maven-compiler-plugin
3.1
1.7
1.7
maven-war-plugin
2.4
WebContent
false
applicationContext.xml文件
此处的master1需要与sentinel中的名字一致:
sentinel down-after-milliseconds
master1 1000
redis.properties文件
# Redis settings
redis.host.ip=192.168.56.101
redis.host.port=7001
redis.maxTotal=1000
redis.maxIdle=100
redis.maxWait=2000
redis.testOnBorrow=false
redis.testOnReturn=true
redis.sentinel.addr=192.168.56.101:26379
SentinelController.java文件
package sample;
import java.util.HashMap;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.BoundHashOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RequestMapping;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import util.CountCreater;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* Created by xin on 15/1/7.
*/
@Controller
public class SentinelController {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private StringRedisTemplate redisTemplate;
@RequestMapping("/sentinelTest")
public String sentinelTest(final Model model,
final HttpServletRequest request, final String action) {
return "sentinelTest";
}
@ExceptionHandler(value = { java.lang.Exception.class })
@RequestMapping("/setValueToRedis")
public String setValueToRedis(final Model model,
final HttpServletRequest request, final String action)
throws Exception {
CountCreater.setCount();
String key = String.valueOf(CountCreater.getCount());
Map mapValue = new HashMap();
for (int i = 0; i < 1000; i++) {
mapValue.put(String.valueOf(i), String.valueOf(i));
}
try {
BoundHashOperations boundHashOperations = redisTemplate
.boundHashOps(key);
boundHashOperations.putAll(mapValue);
logger.info("put key into redis");
} catch (Exception e) {
logger.error(e.getMessage(), e);
throw new Exception(e);
}
return "sentinelTest";
}
}
这个controller如果返回success会跳转到一个叫/page/sentinelTest.jsp文件中,它的内容如下:
sentinelTest.jsp文件
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
test sentinel r/w
这个jsp文件的
内含有 test sentinel r/w字样,我们在后面的jmeter压力测试中就会用一个assertion(断言)来判断此字样以示SentinelController成功跳转,如果在jmeter的assertion中没有读到controller跳转后的response中有此字样,那么这个请求即为failed。
<br>
<br>
</div>
<div>
<br>
</div>
<h1>测试代码运行</h1>
<div>
<br>
</div>
<div>
<br>
</div>把工程编译后启动起来,启动前不要忘了按照master->slave->sentinel的顺序来启动redis的sentinel HA群。
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/77e547387ca34d9ba92e2a6ded4d4e4c.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/77e547387ca34d9ba92e2a6ded4d4e4c.jpg" alt="" width="650" height="98"></a>
</div>
<div>
<br>
</div>
<div>
启动后我们访问
<br>
<br>
</div>
<div>
http://localhost:8080/webpoc/setValueToRedis
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/e38d497eb83449e99762e060c41bf536.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/e38d497eb83449e99762e060c41bf536.jpg" alt="" width="650" height="85"></a>
</div>
<div>
看到我们的eclipse控制台有这一行输出,代表我们的sentinel群和代码已经完美合起来了。
</div>
<div>
<br>
</div>
<div>
于是我们分别登录master和slave来查看我们刚才插的值
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/0a8978793c12420b958ae65d23d2cda4.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/0a8978793c12420b958ae65d23d2cda4.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第5张图片" width="630" height="223" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
可以看到,在master被插入值后,slave从master处同步了相应的值过来。
</div>
<div>
<br>
</div>
<h1>测试master不可访问时sentinel的自动切换</h1>
<div>
<br>
</div>
<div>
我们现在的情况为:
</div>
<div>
<br>
</div>
<div>
<ul>
<li>master-7001</li>
<li>slave-7002</li>
</ul>
<div>
于是,我们在Linux中发出一条命令
</div>
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/bab14a939ae64b51b23111a1fa18427a.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/bab14a939ae64b51b23111a1fa18427a.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第6张图片" width="663" height="130" style="border:1px solid black;"></a>
<br>
<br>
</div>
<div>
这条命令代表封闭192.168.56.101上的7001端口到达任何地方的路由,即人为造成了一次master服务的“宕机”。
</div>
<div>
<br>
</div>
<div>
先来看eclipse中控制台的情况:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/d51db441e96044a5ad363c6a6c5cedc0.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/d51db441e96044a5ad363c6a6c5cedc0.png" alt="" width="601" height="67"></a>
<br>
<br>
</div>
<div>
看到没有。。。jedispool to master at 192.168.56.101:7002,7002已经变成master了。
</div>
<div>
<br>
</div>
<div>
再来看我们的redis,看。。。7001上的服务不可用已经被我们位于26379端口的哨兵探测到了,它已经把7002变成master了。
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/13da687bcc41444e902b5c62c8e91c04.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/13da687bcc41444e902b5c62c8e91c04.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第7张图片" width="636" height="197" style="border:1px solid black;"></a>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/27a8d2a78c474768a008be054c93a570.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/27a8d2a78c474768a008be054c93a570.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第8张图片" width="645" height="115" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
不信,我们再登录7002来看一下我们的服务
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/5805863f276f4977a6e83e1191ddad93.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/5805863f276f4977a6e83e1191ddad93.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第9张图片" width="675" height="270" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
那么我们可以确认,从7001宕机后7002已经从slave变成了master。
</div>
<div>
<br>
</div>
<div>
于是,我们在linux端打开sentinel.conf文件看一下,它已经发生了变化,这个变化是sentinel自己自动往配置文件里加入的内容:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/a06ea35cf01e4f59aeeef21c797065d5.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/a06ea35cf01e4f59aeeef21c797065d5.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第10张图片" width="484" height="200" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<br>现在,我们把7001重新“恢复”起来,因此我们发出如下的命令:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/384de18cd8c74fa287e2393c1f2c9615.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/384de18cd8c74fa287e2393c1f2c9615.png" alt="" width="627" height="85"></a>
<br>
</div>
<div>
<br>
</div>
<div>
此刻我们再来登录7001来看看它变成什么状态了:
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/c710ca8b95d84f6fb049d652fae03a3e.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/c710ca8b95d84f6fb049d652fae03a3e.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第11张图片" width="665" height="373" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
看。。。7001恢复后从原来的old master成了new slave了。
</div>
<div>
<br>
</div>
<div>
那么sentinel到底做了什么,我们来看看sentinel的log日志一探究竟吧:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/c5a1bceaab8c4349808441aaa4956c78.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/c5a1bceaab8c4349808441aaa4956c78.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第12张图片" width="1051" height="238" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
我们再来看看redis1中的redis.conf文件中的内容:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/31bb7488396544d983ca552803585b39.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/31bb7488396544d983ca552803585b39.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第13张图片" width="685" height="255" style="border:1px solid black;"></a>
</div>
<div>
<br>
</div>
<div>
再来看看redis2中的redis.conf文件
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/da2bd2a193b64636ac337e820c99a39f.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/da2bd2a193b64636ac337e820c99a39f.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第14张图片" width="1149" height="173" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
以上实验成功,我们下面就用jmeter来进行大并发用户操作下的sentinel切换吧。
</div>
<div>
<br>
</div>
<h1>使用jmter模拟大并发用户操作下的故障自动转移</h1>
<div>
<br>
</div>
<h2>压力测试计划</h2>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/ad86b4e8d8bb4e89afa3dd2ecf7d28b0.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/ad86b4e8d8bb4e89afa3dd2ecf7d28b0.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第15张图片" width="703" height="329" style="border:1px solid black;"></a>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/9f2b03085967490aac1c49b98efb2b6d.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/9f2b03085967490aac1c49b98efb2b6d.jpg" alt="亲密接触Redis-第二天(Redis Sentinel)_第16张图片" width="650" height="157" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<br>
</div>
<div>
<br>
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/f4177864616a4beebd51446b0e9983c0.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/f4177864616a4beebd51446b0e9983c0.jpg" alt="亲密接触Redis-第二天(Redis Sentinel)_第17张图片" width="650" height="178" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<br>
</div>
<div>
在我的jmeter测试计划中我增加了4个监听器,它们分别为:
</div>
<div>
<ul>
<li>TPS值</li>
<li>summary report</li>
<li>表格查看结果</li>
<li>树形查看结果</li>
</ul>
<div>
<br>
</div>我们现在就来去选这个以 ”
<strong><span style="color:#ff0000;">100个并发以每秒一次的请求来点击这个SentinelController并永远点击下去</span></strong>“ 的压力测试吧,在测试时我们会有意将master搞宕。
</div>
<div>
<br>
</div>
<div>
<div>
点击菜单中的”运行->启动“, 不一会我们可以看到jmeter中的TPS与Summary Report中的数字开始飞速转动了起来。
</div>
<div>
<br>
</div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/2779b02993f54e8182d409b00e7441f0.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/2779b02993f54e8182d409b00e7441f0.jpg" alt="亲密接触Redis-第二天(Redis Sentinel)_第18张图片" width="650" height="247" style="border:1px solid black;"></a>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/1c05ce7eb0de4decb216025ffe826131.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/1c05ce7eb0de4decb216025ffe826131.jpg" alt="亲密接触Redis-第二天(Redis Sentinel)_第19张图片" width="650" height="132" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<h2>人为故意造成一次宕机</h2>
<div>
<br>
</div>
<div>
<span style="font-size:18px;color:#ff0000;"><strong>我们现在的master为7002, 7001为slave</strong></span>,因此,我们就把7002搞“崩”吧。
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/f8bc9518868641ce8520b324f82154b0.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/f8bc9518868641ce8520b324f82154b0.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第20张图片" width="701" height="107" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
再看来jmeter中的TPS显示:
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/6b6bbdc1bdd344bda7402740a0bc6d66.jpg" target="_blank"><img src="http://img.e-com-net.com/image/info8/6b6bbdc1bdd344bda7402740a0bc6d66.jpg" alt="亲密接触Redis-第二天(Redis Sentinel)_第21张图片" width="650" height="286" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/557f13463a8641d8a246ea2e04d3b86b.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/557f13463a8641d8a246ea2e04d3b86b.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第22张图片" width="893" height="157" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<ul>
<li>通过TPS我们可以发觉有<span style="font-size:18px;color:#3366ff;"><strong>蓝色</strong></span>的线,这代表“出错率”,这个出错率应该是7002在“崩”掉后,7001从slave升级成master时redis对客户端无法及时响应时抛出的HTTP 500即service unavailable的错。</li>
</ul>
</div>
<div>
<br>
</div>
<div>
<ul>
<li>通过Summary Report我们可以看到在主从切换的那一刻我们的fail rate为千分之0.5,这个fail rate是完全可以在接受范围内的,一般错误率在千分之一就已经很好了。</li>
</ul>
<div>
<br>
</div>
</div>
<div>
可以看到我们在搞“死”7002时,7001自动顶到了master的位置并及时响应了用户的请求,要知道我们这个测试只是在一台4GB的虚拟出来的Linux Fedora22上进行的redis 一主一备的sentinel测试,能够达到这个测试结果已经是相当的perfect了。
</div>
<div>
<br>
</div>
<div>
于是我们登录一下7001来看看
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/edfeada933484616b509834bf3fe3cda.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/edfeada933484616b509834bf3fe3cda.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第23张图片" width="671" height="298" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
我们可以看到,7001成了master了。
</div>
<div>
<br>
</div>
<div>
于是我们”恢复“7002。
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/a88be2ced8ab426c812d5d612b17cacc.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/a88be2ced8ab426c812d5d612b17cacc.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第24张图片" width="687" height="276" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
<a href="http://img.e-com-net.com/image/info8/569342637dba4895841c092674c8dd38.png" target="_blank"><img src="http://img.e-com-net.com/image/info8/569342637dba4895841c092674c8dd38.png" alt="亲密接触Redis-第二天(Redis Sentinel)_第25张图片" width="599" height="373" style="border:1px solid black;"></a>
<br>
</div>
<div>
<br>
</div>
<div>
它便自己成了slave了,而此时7001作为new master正在承担着客户端的访问。
</div>
<div>
<br>
</div>
<div>
结束今天的教程。
</div>
<div>
<br>
</div>
</div>
<p>转载于:https://www.cnblogs.com/aiwz/p/6154606.html</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1276868126864064512"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(亲密接触Redis-第二天(Redis Sentinel))</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1835510656011431936.htm"
title="爬山后遗症" target="_blank">爬山后遗症</a>
<span class="text-muted">璃绛</span>
<div>爬山,攀登,一步一步走向制高点,是一种挑战。成功抵达是一种无法言语的快乐,在山顶吹吹风,看看风景,这是从未有过的体验。然而,爬山一时爽,下山腿打颤,颠簸的路,一路向下走,腿部力量不够,走起来抖到不行,停不下来了!第二天必定腿疼,浑身酸痛,坐立难安!</div>
</li>
<li><a href="/article/1835501948011376640.htm"
title="使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)" target="_blank">使用 FinalShell 进行远程连接(ssh 远程连接 Linux 服务器)</a>
<span class="text-muted">编程经验分享</span>
<a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E5%B7%A5%E5%85%B7/1.htm">开发工具</a><a class="tag" taget="_blank" href="/search/%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">服务器</a><a class="tag" taget="_blank" href="/search/ssh/1.htm">ssh</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>目录前言基本使用教程新建远程连接连接主机自定义命令路由追踪前言后端开发,必然需要和服务器打交道,部署应用,排查问题,查看运行日志等等。一般服务器都是集中部署在机房中,也有一些直接是云服务器,总而言之,程序员不可能直接和服务器直接操作,一般都是通过ssh连接来登录服务器。刚接触远程连接时,使用的是XSHELL来远程连接服务器,连接上就能够操作远程服务器了,但是仅用XSHELL并没有上传下载文件的功能</div>
</li>
<li><a href="/article/1835497077891756032.htm"
title="想明白这个问题,你才能写下去" target="_blank">想明白这个问题,你才能写下去</a>
<span class="text-muted">文自拾</span>
<div>春节放假的时候,又有一天梦见她,第二天她冒着漫天大雪,傻傻地跑来见我。她说,见见傻傻的我,天很冷,心很暖。她回去后,我写了一篇文章,题目叫——从此梦中只有你。我们没在一起的很长一段时间里,她都在我的心底,一次次出现在我的梦里。我对她说,在一起之前,是胆小且闷骚,在一起之后,我变得不要脸了。不要脸的——去爱你。那文章没写完,火车上,给她看了。我有点小失望,花了好几个小时写,她分分钟就看完,很希望她逐</div>
</li>
<li><a href="/article/1835491349571399680.htm"
title="被带偏的家人,可气又感动" target="_blank">被带偏的家人,可气又感动</a>
<span class="text-muted">艾孤璟</span>
<div>当我还是个严肃且内敛的孩子时,爷爷也是个严谨且和蔼的人,虽然不苟言笑,但没有距离感。当我接触的人越来越多,知道怎么调动气氛,家人们就被我带偏了。家里人本来没有外号的,后来都被我给取了各种各样的名字,“骂人”时就相对应的有了暗号。村里的小孩,本来不知道怎么使用假动作“打人”,怎么给人取合适的外号,后来也被我带偏了。老人常说我,古灵精怪,好的不学非得学坏的,带着不良风气。而我对他的话总是想生气又觉得搞</div>
</li>
<li><a href="/article/1835490092068728832.htm"
title="Redis系列:Geo 类型赋能亿级地图位置计算" target="_blank">Redis系列:Geo 类型赋能亿级地图位置计算</a>
<span class="text-muted">Ly768768</span>
<a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/bootstrap/1.htm">bootstrap</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>1前言我们在篇深刻理解高性能Redis的本质的时候就介绍过Redis的几种基本数据结构,它是基于不同业务场景而设计的:动态字符串(REDIS_STRING):整数(REDIS_ENCODING_INT)、字符串(REDIS_ENCODING_RAW)双端列表(REDIS_ENCODING_LINKEDLIST)压缩列表(REDIS_ENCODING_ZIPLIST)跳跃表(REDIS_ENCODI</div>
</li>
<li><a href="/article/1835467944805625856.htm"
title="九月班级管理工作反思" target="_blank">九月班级管理工作反思</a>
<span class="text-muted">追梦蜂</span>
<div>这个月应该算是最难的一个月,我已N年没当班主任,然后我又开始当了。职称是一方面,想到我如果退休了,不能再接触学生了,那该是多么遗憾的事!我的学生梁*铭是我的榜样,她那么努力,那么拼,那么上进,为什么我不行?虽然我面临的工作很难,但是高考数学也不容易。她拿下来了!满分150分她考了146分!我目睹她的艰辛,她的拼搏!还有,我要为我的孩子做榜样,如何竭尽全力,实现梦想。还有,服务,为社会做事,也是会有</div>
</li>
<li><a href="/article/1835466664725016576.htm"
title="读书笔记|《遇见孩子,遇见更好的自己》5" target="_blank">读书笔记|《遇见孩子,遇见更好的自己》5</a>
<span class="text-muted">抹茶社长</span>
<div>为人父母意味着放弃自己的过去,不要对以往没有实现的心愿耿耿于怀,只有这样,孩子们才能做回自己。985909803.jpg孩子在与父母保持亲密的同时更需要独立,唯有这样,孩子才会成为孩子,父母才会成其为父母。有耐心的人生往往更幸福,给孩子留点余地。认识到养儿育女是对耐心的考验。为失败做好心理准备,教会孩子控制情绪。了解自己的底线,说到底线,有一点很重要,父母之所以发脾气,真正的原因往往在于他们自己,</div>
</li>
<li><a href="/article/1835455835682205696.htm"
title="《前夫如龙》王昊江琼(独家小说)精彩TXT阅读" target="_blank">《前夫如龙》王昊江琼(独家小说)精彩TXT阅读</a>
<span class="text-muted">海边书楼</span>
<div>《前夫如龙》王昊江琼(独家小说)精彩TXT阅读主角:王昊江琼简介:离婚那天,她视他如泥土。谁曾想,消息一出,天下震动!可关注微信公众号【风车文楼】去回个书号【203】,即可免费阅读【前夫如龙】全文!江芸并未听出华少龙声音里的冷漠,依旧一脸笑容道:“是啊,那个废物哪儿配得上我姐?这些年,我姐对他仁至义尽了。以后,华少爷可以多跟我姐接触接触,只有华少爷这样的人,才配得上我姐啊!”江琼低着头,微微有些娇</div>
</li>
<li><a href="/article/1835449364223455232.htm"
title="SpringCloudAlibaba—Sentinel(限流)" target="_blank">SpringCloudAlibaba—Sentinel(限流)</a>
<span class="text-muted">菜鸟爪哇</span>
<div>前言:自己在学习过程的记录,借鉴别人文章,记录自己实现的步骤。借鉴文章:https://blog.csdn.net/u014494148/article/details/105484410Sentinel介绍Sentinel诞生于阿里巴巴,其主要目标是流量控制和服务熔断。Sentinel是通过限制并发线程的数量(即信号隔离)来减少不稳定资源的影响,而不是使用线程池,省去了线程切换的性能开销。当资源</div>
</li>
<li><a href="/article/1835447700980592640.htm"
title="摄影小白,怎么才能拍出高大上产品图片?" target="_blank">摄影小白,怎么才能拍出高大上产品图片?</a>
<span class="text-muted">是波妞唉</span>
<div>很多人以为文案只要会码字,会排版就OK了!说实话,没接触到这一行的时候,我的想法更简单,以为只要会写字就行!可是真做了文案才发现,码字只是入门级的基本功。一篇文章离不开排版、配图,说起来很简单!从头做到尾你就会发现,写文章用两个小时,找合适的配图居然要花掉半天的时间,甚至更久!图片能找到合适的就不怕,还有找不到的,比如产品图,只能亲自拍。拿着摆弄了半天,就是拍不出想要的效果,光线不好、搭出来丑破天</div>
</li>
<li><a href="/article/1835420501065953280.htm"
title="华为云分布式缓存服务DCS 8月新特性发布" target="_blank">华为云分布式缓存服务DCS 8月新特性发布</a>
<span class="text-muted">华为云PaaS服务小智</span>
<a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BA%E4%BA%91/1.htm">华为云</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a>
<div>分布式缓存服务(DistributedCacheService,简称DCS)是华为云提供的一款兼容Redis的高速内存数据处理引擎,为您提供即开即用、安全可靠、弹性扩容、便捷管理的在线分布式缓存能力,满足用户高并发及数据快速访问的业务诉求。此次为大家带来DCS8月的特性更新内容,一起来看看吧!</div>
</li>
<li><a href="/article/1835411498286018560.htm"
title="冯玙哲诗歌。一日不见兮。" target="_blank">冯玙哲诗歌。一日不见兮。</a>
<span class="text-muted">冯玙哲</span>
<div>图片发自App古书里有鱼,它们没有眼睛,有脚它们不恋爱,却亲密,像极了爱人鸢尾花,铺满月光的海,爱人的笑像春天开满矮墙的牵牛花我承认爱如此美好以至于我梦里有你远方的浪花似乎在激荡,一朵朵朝向你说的春暖花开,那大海摇曳的梦幻沙滩的脚印,印着属于我们彼此的恩爱浮光不会轻易的散去,反而会甜蜜爱人的心,像大海,翻滚着浪花涌向我,日日夜夜太阳花开满了村庄,田野有嫩绿的荷叶蜻蜓带来了信笺,写满情诗蝴蝶编织舞蹈</div>
</li>
<li><a href="/article/1835406291489615872.htm"
title="隔离在防晒霜前还是后防晒 隔离霜和防晒霜的区别是什么" target="_blank">隔离在防晒霜前还是后防晒 隔离霜和防晒霜的区别是什么</a>
<span class="text-muted">氧惠导师</span>
<div>防晒霜是每天护肤的时候都需要使用的,主要针对的是紫外线,而隔离霜主要是用来隔离彩妆和空气中的脏东西,所以它用在化妆的前一步,即粉底液之前。二者缺一不可,也许很多人会说隔离霜有防晒成分,还要不要涂抹它,事实上,如果长期接触紫外线,只用隔离霜是不够的。➤推荐网购薅羊毛app“氧惠”,一个领隐藏优惠券+现金返利的平台。氧惠只提供领券返利链接,下单全程都在淘宝、京东、拼多多等原平台,更支持抖音、快手电商、</div>
</li>
<li><a href="/article/1835399830004920320.htm"
title="Redis Key的过期策略" target="_blank">Redis Key的过期策略</a>
<span class="text-muted">ArchManual</span>
<a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F%E6%9E%B6%E6%9E%84/1.htm">分布式架构</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%B8%83%E5%BC%8F/1.htm">分布式</a><a class="tag" taget="_blank" href="/search/Java/1.htm">Java</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a><a class="tag" taget="_blank" href="/search/%E5%BE%AE%E6%9C%8D%E5%8A%A1/1.htm">微服务</a><a class="tag" taget="_blank" href="/search/%E6%9E%B6%E6%9E%84/1.htm">架构</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a>
<div>Redis的过期策略主要是指管理和删除那些设定了过期时间的键,以确保内存的有效使用和数据的及时清理。具体来说,Redis有三种主要的过期策略:定期删除(ScheduledDeletion)、惰性删除(LazyDeletion)和内存淘汰策略(EvictionPolicies)。1.定期删除Redis的定期删除策略(ScheduledDeletion)的步骤如下:设置定期任务:Redis会在后台线程</div>
</li>
<li><a href="/article/1835397685104963584.htm"
title="Redis:缓存击穿" target="_blank">Redis:缓存击穿</a>
<span class="text-muted">我的程序快快跑啊</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>缓存击穿(热点key):部分key(被高并发访问且缓存重建业务复杂的)失效,无数请求会直接到数据库,造成巨大压力1.互斥锁:可以保证强一致性线程一:未命中之后,获取互斥锁,再查询数据库重建缓存,写入缓存,释放锁线程二:查询未命中,未获得锁(已由线程一获得),等待一会,缓存命中互斥锁实现方式:redis中setnxkeyvalue:改变对应key的value,仅当value不存在时执行,以此来实现互</div>
</li>
<li><a href="/article/1835397275208216576.htm"
title="乱说话 要承担后果" target="_blank">乱说话 要承担后果</a>
<span class="text-muted">余生要幸福888</span>
<div>平日里,我们说话一定要特别注意,有些话是万万不能说的,会很灵验的!当说了不该说的话后,可能引发的后果,将是你始料不及的!01乱说话遭遇“鬼打墙”几年前,我认识的一个客户给我讲了一段他的亲身经历:他们公司在北京十三陵附近的一个度假村召开公司年会,会期三天。会议的第二天下午,他和另外两个朋友临时回市区办点事。等到办完事往回赶,快到度假村时,天已经接近傍晚了。车里三个人一路走一路闲聊,其中一个人就突然感</div>
</li>
<li><a href="/article/1835396891043524608.htm"
title="交错时光的爱恋【第五章】" target="_blank">交错时光的爱恋【第五章】</a>
<span class="text-muted">苏羽花</span>
<div>第二天上马车,幻儿教无瑕认识几个简单的字,一早上就在写字中度过。下午幻儿就与无忌共乘一匹马。因为在她的缠功之下,使得石无忌只好点头答应。列出一长串三年以来北方上门求亲的名单。幻儿发现,举凡世家公子多为纨挎子弟不成材者!商人子弟尤为流气。她可要小心注意了,石家财大业大,生下的后代可别也成了那般!教育绝对不可缺,她背靠在丈夫怀中念着:“高大平,擅长调戏下女、上妓院。方天恩,好赌成性、挥霍无度。就只有这</div>
</li>
<li><a href="/article/1835390120858054656.htm"
title="Redis 有哪些危险命令?如何防范?" target="_blank">Redis 有哪些危险命令?如何防范?</a>
<span class="text-muted">花小疯</span>
<a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%8D%B1%E9%99%A9%E5%91%BD%E4%BB%A4/1.htm">危险命令</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>Redis有哪些危险命令?Redis的危险命令主要有以下几个:1.keys客户端可查询出所有存在的键。2.flushdb删除Redis中当前所在数据库中的所有记录,并且此命令从不会执行失败。3.flushall删除Redis中所有数据库中的所有记录,不止是当前所在数据库,并且此命令从不会执行失败。4.config客户端可修改Redis配置。怎么禁用和重命名危险命令?看下redis.conf默认配置</div>
</li>
<li><a href="/article/1835383403806027776.htm"
title="JVM源码分析之堆外内存完全解读" target="_blank">JVM源码分析之堆外内存完全解读</a>
<span class="text-muted">HeapDump性能社区</span>
<div>概述广义的堆外内存说到堆外内存,那大家肯定想到堆内内存,这也是我们大家接触最多的,我们在jvm参数里通常设置-Xmx来指定我们的堆的最大值,不过这还不是我们理解的Java堆,-Xmx的值是新生代和老生代的和的最大值,我们在jvm参数里通常还会加一个参数-XX:MaxPermSize来指定持久代的最大值,那么我们认识的Java堆的最大值其实是-Xmx和-XX:MaxPermSize的总和,在分代算法</div>
</li>
<li><a href="/article/1835381498153365504.htm"
title="动画电影《心灵奇旅》教你怎么做人,皮克斯为全人类上了一课" target="_blank">动画电影《心灵奇旅》教你怎么做人,皮克斯为全人类上了一课</a>
<span class="text-muted">韩漫小说</span>
<div>皮克斯出品,必属精品。不知从什么时候,这句话成了中国影迷和动画迷对皮克斯的认可和肯定。作为八十年代的人,虽然现在已经迈入中年,但是从小就对动画片十分痴迷。从《奥特曼》到《高达》,从《黑猫警长》到《海贼王》。动画伴我成长,给了我很多快乐。接触皮克斯的动画,是《玩具总动员》,看了真的令人感动。这不仅是儿童的欢乐片,也是给八零九零后奉献的精美大作。然而这一次的《心灵奇旅》,更是让我对皮克斯刮目相看。这次</div>
</li>
<li><a href="/article/1835376415000850432.htm"
title="【写作日更挑战双18】早上起来得比较早" target="_blank">【写作日更挑战双18】早上起来得比较早</a>
<span class="text-muted">林兮云</span>
<div>说着昨晚应该早点睡,是比平时早了,不过也到了12点才睡觉,第二天也就是今天早上6点20多起的床,时间过得很快。当你发现自己有很多事情想要去做的时候,就会发现时间根本不够用。乌云就像一块移动的海绵,里面装满了水,并且还在不停地吸水,一旦吸得太多了,装不下了,就要释放出来,这应该就是“下雨”了,乌云可能一边吸一边放,如果一直不停地吸,就会一直不停地放,如果停止吸水,等承受不了的水放完了,自然雨就不下了</div>
</li>
<li><a href="/article/1835367119223615488.htm"
title="这样共读一本书" target="_blank">这样共读一本书</a>
<span class="text-muted">eggplant</span>
<div>2021年10月6日星期三本期学校阳光管理轮训共读刘铁芳教授的《以教学打开生命——个体成人的教学哲学阐释》,这是继共读刘教授《什么是好的教育》之后的第二本书籍,这两本书籍都是有关教育的哲学书籍,应该说,《以教学打开生命——个体成人的教学哲学阐释》是《什么是好的教育》的延伸、丰富与升华,理论性更强,哲学意味更浓,对于一线教师来说,接触哲学类的书籍较少,在阅读上有些内容的理解有难度,但是,有难度才更值</div>
</li>
<li><a href="/article/1835360874869649409.htm"
title="每日一书|《亲密关系》(Day5)" target="_blank">每日一书|《亲密关系》(Day5)</a>
<span class="text-muted">采臣在等我</span>
<div>采臣在等我-广州【书籍名称】《亲密关系》图片发自App【阅读目标】1.了解“亲密关系”的几个阶段及特点2.认识和理解有效沟通的技巧和原则3.思考自己在亲密关系建立中的角色和心理,以及面临的挑战【阅读感受】这本书是克里斯多福研究亲密关系的智慧结晶,阅读的整体感受是:书中文字亲切,有种娓娓道来的感觉。书中的逻辑感较强,也有详细的小结和应用建议,适合应用和反思。1.亲密关系的4个阶段和特点阶段一:月晕A</div>
</li>
<li><a href="/article/1835352325032603648.htm"
title="第三十一节:Vue路由:前端路由vs后端路由的了解" target="_blank">第三十一节:Vue路由:前端路由vs后端路由的了解</a>
<span class="text-muted">曹老师</span>
<div>1.认识前端路由和后端路由前端路由相对于后端路由而言的,在理解前端路由之前先对于路由有一个基本的了解路由:简而言之,就是把信息从原地址传输到目的地的活动对于我们来说路由就是:根据不同的url地址展示不同的页面内容1.1后端路由以前咱们接触比较多的后端路由,当改变url地址时,浏览器会向服务器发送请求,服务器根据这个url,返回不同的资源内容后端路由的特点就是前端每次跳转到不同url地址,都会重新访</div>
</li>
<li><a href="/article/1835351054791831552.htm"
title="第一周" target="_blank">第一周</a>
<span class="text-muted">艾希米</span>
<div>好久没工作过了,第一天带着紧张和激动的心情去的办公室,害怕自己出什么差错,和大家也都是第一次见面,彼此之间都不熟悉。第一天在领导的培训️结束了。第二天去世纪星城小区做详细的楼层,单元,户数的记录,记得那天特别凉快,和越越一直到下午四点才完成了工作,越越还买了苹果分享给大家吃。第三天去万达广场考察了三个瑜伽馆,特别喜欢爱瑜伽的环境和销售,喜欢昕孕瑜伽教练的专业度和亲和力,对于空冥瑜伽真的不想说什么了</div>
</li>
<li><a href="/article/1835325072823382016.htm"
title="第三周第二天2019-11-12" target="_blank">第三周第二天2019-11-12</a>
<span class="text-muted">曲超king</span>
<div>今天学习字符串1、chars[5]={'A','S'},数组里面是单个的字符,由‘’chars[5]={"aasd"},数组里面是字符串,由“”chars[5]={"a"}也是一个字符串。其中的5代表字符串的长度每个字符串在结束位置都有\0,\0占一个元素。{\0}表示空的字符串。在输出时,%c代表字符输出,%s代表字符串输出。2、字符的长度一定要比总长度少一位,因为隐藏一个\0,系统自己默认规定</div>
</li>
<li><a href="/article/1835317832104112128.htm"
title="年少时,长大后" target="_blank">年少时,长大后</a>
<span class="text-muted">旧路上</span>
<div>图片发自App年少时的恋爱:确定关系的下一秒,你就赶紧发了一条“余生,请多多指教”的朋友圈。单身多年的你,巴不得向全天下公布恋情你觉得他是那个会和你走完一辈子的人,你的全世界都是他你每天醒来第一件事,就是看他有没有给你发消息你每天都想见到他,巴不得二十四小时都黏在他身边。你甚至都开始畅想你们老了,要修一个大大的院子,一起种草养花。长大后的谈恋爱:确定关系的那晚,你很平静地睡了一觉,然后第二天和他一</div>
</li>
<li><a href="/article/1835316814838591488.htm"
title="班主任修炼之放下身段" target="_blank">班主任修炼之放下身段</a>
<span class="text-muted">任米荣</span>
<div>二班好像得了瘟疫,扩散很快!上周有一位学生没有写作业,我批评了,让他补完,谁知第二天检查时,他居然没有补,而且还传染了两个。在教育缺少戒尺的尴尬地位中,我只好是苦口婆心,好言相劝,谁知根本不顶用,每天好话说一箩筐,可是效果非但没有,反倒像像感染了瘟疫一样,今天不写作业的学生由先前的一个到今天的八个。当课代表将没写完作业的学生名单给我时,我很无奈,准备好好说说。图片发自App当我走上讲台,发现讲桌上</div>
</li>
<li><a href="/article/1835316048295981056.htm"
title="最新小说《美女老婆种回家》吴敏霍小燕&全文阅读无删减" target="_blank">最新小说《美女老婆种回家》吴敏霍小燕&全文阅读无删减</a>
<span class="text-muted">小说推书</span>
<div>最新小说《美女老婆种回家》吴敏霍小燕&全文阅读无删减主角:吴敏霍小燕简介:在我的老家农村倒是经常听到老人们说起这种事情,或是某人没生育能力,然后找个族亲的同辈来传宗接代。可以关注微信公众号【小北文楼】去回个书号【53】,即可免费阅读【美女老婆种回家】小说全文!晚上,我熬了半个通宵,做出了一个自我感觉很是完美的企划案,第二天我兴冲冲的来到公司打算交给经理请功,没想到刚到经理办公室门口,就听到了秘书小</div>
</li>
<li><a href="/article/1835310046884491264.htm"
title="今日头条极速版邀请码是多少(亲测5个可用邀请码及填写方法)" target="_blank">今日头条极速版邀请码是多少(亲测5个可用邀请码及填写方法)</a>
<span class="text-muted">桃朵十三</span>
<div>第一次接触今日头条极速版app我记得是2018年7月份左右吧,当时手机上弹出一个小广告说看新闻还能赚零花钱,抱着好奇的心理下载了试一试,刚开始每天刷几条新闻或视频第二天早上金币兑换成一元多钱,可以提现到支付宝或者微信,弄得不亦乐乎。心想不给钱没事我也会看看新闻呢,何乐而不为呢。今日头条极速版邀请码是1712201738或1451455648或1805884301,秒懂你的阅读喜好,秒杀碎片化时间。</div>
</li>
<li><a href="/article/18.htm"
title="jQuery 跨域访问的三种方式 No 'Access-Control-Allow-Origin' header is present on the reque" target="_blank">jQuery 跨域访问的三种方式 No 'Access-Control-Allow-Origin' header is present on the reque</a>
<span class="text-muted">qiaolevip</span>
<a class="tag" taget="_blank" href="/search/%E6%AF%8F%E5%A4%A9%E8%BF%9B%E6%AD%A5%E4%B8%80%E7%82%B9%E7%82%B9/1.htm">每天进步一点点</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0%E6%B0%B8%E6%97%A0%E6%AD%A2%E5%A2%83/1.htm">学习永无止境</a><a class="tag" taget="_blank" href="/search/%E8%B7%A8%E5%9F%9F/1.htm">跨域</a><a class="tag" taget="_blank" href="/search/%E4%BC%97%E8%A7%82%E5%8D%83%E8%B1%A1/1.htm">众观千象</a>
<div>XMLHttpRequest cannot load http://v.xxx.com. No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://localhost:63342' is therefore not allowed access. test.html:1
</div>
</li>
<li><a href="/article/145.htm"
title="mysql 分区查询优化" target="_blank">mysql 分区查询优化</a>
<span class="text-muted">annan211</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%88%86%E5%8C%BA/1.htm">分区</a><a class="tag" taget="_blank" href="/search/%E4%BC%98%E5%8C%96/1.htm">优化</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>
分区查询优化
引入分区可以给查询带来一定的优势,但同时也会引入一些bug.
分区最大的优点就是优化器可以根据分区函数来过滤掉一些分区,通过分区过滤可以让查询扫描更少的数据。
所以,对于访问分区表来说,很重要的一点是要在where 条件中带入分区,让优化器过滤掉无需访问的分区。
可以通过查看explain执行计划,是否携带 partitions</div>
</li>
<li><a href="/article/272.htm"
title="MYSQL存储过程中使用游标" target="_blank">MYSQL存储过程中使用游标</a>
<span class="text-muted">chicony</span>
<a class="tag" taget="_blank" href="/search/Mysql%E5%AD%98%E5%82%A8%E8%BF%87%E7%A8%8B/1.htm">Mysql存储过程</a>
<div>DELIMITER $$
DROP PROCEDURE IF EXISTS getUserInfo $$
CREATE PROCEDURE getUserInfo(in date_day datetime)-- -- 实例-- 存储过程名为:getUserInfo-- 参数为:date_day日期格式:2008-03-08-- BEGINdecla</div>
</li>
<li><a href="/article/399.htm"
title="mysql 和 sqlite 区别" target="_blank">mysql 和 sqlite 区别</a>
<span class="text-muted">Array_06</span>
<a class="tag" taget="_blank" href="/search/sqlite/1.htm">sqlite</a>
<div>转载:
http://www.cnblogs.com/ygm900/p/3460663.html
mysql 和 sqlite 区别
SQLITE是单机数据库。功能简约,小型化,追求最大磁盘效率
MYSQL是完善的服务器数据库。功能全面,综合化,追求最大并发效率
MYSQL、Sybase、Oracle等这些都是试用于服务器数据量大功能多需要安装,例如网站访问量比较大的。而sq</div>
</li>
<li><a href="/article/526.htm"
title="pinyin4j使用" target="_blank">pinyin4j使用</a>
<span class="text-muted">oloz</span>
<a class="tag" taget="_blank" href="/search/pinyin4j/1.htm">pinyin4j</a>
<div>首先需要pinyin4j的jar包支持;jar包已上传至附件内
方法一:把汉字转换为拼音;例如:编程转换后则为biancheng
/**
* 将汉字转换为全拼
* @param src 你的需要转换的汉字
* @param isUPPERCASE 是否转换为大写的拼音; true:转换为大写;fal</div>
</li>
<li><a href="/article/653.htm"
title="微博发送私信" target="_blank">微博发送私信</a>
<span class="text-muted">随意而生</span>
<a class="tag" taget="_blank" href="/search/%E5%BE%AE%E5%8D%9A/1.htm">微博</a>
<div>在前面文章中说了如和获取登陆时候所需要的cookie,现在只要拿到最后登陆所需要的cookie,然后抓包分析一下微博私信发送界面
http://weibo.com/message/history?uid=****&name=****
可以发现其发送提交的Post请求和其中的数据,
让后用程序模拟发送POST请求中的数据,带着cookie发送到私信的接入口,就可以实现发私信的功能了。 </div>
</li>
<li><a href="/article/780.htm"
title="jsp" target="_blank">jsp</a>
<span class="text-muted">香水浓</span>
<a class="tag" taget="_blank" href="/search/jsp/1.htm">jsp</a>
<div>JSP初始化
容器载入JSP文件后,它会在为请求提供任何服务前调用jspInit()方法。如果您需要执行自定义的JSP初始化任务,复写jspInit()方法就行了
JSP执行
这一阶段描述了JSP生命周期中一切与请求相关的交互行为,直到被销毁。
当JSP网页完成初始化后</div>
</li>
<li><a href="/article/907.htm"
title="在 Windows 上安装 SVN Subversion 服务端" target="_blank">在 Windows 上安装 SVN Subversion 服务端</a>
<span class="text-muted">AdyZhang</span>
<a class="tag" taget="_blank" href="/search/SVN/1.htm">SVN</a>
<div>在 Windows 上安装 SVN Subversion 服务端2009-09-16高宏伟哈尔滨市道里区通达街291号
最佳阅读效果请访问原地址:http://blog.donews.com/dukejoe/archive/2009/09/16/1560917.aspx
现在的Subversion已经足够稳定,而且已经进入了它的黄金时段。我们看到大量的项目都在使</div>
</li>
<li><a href="/article/1034.htm"
title="android开发中如何使用 alertDialog从listView中删除数据?" target="_blank">android开发中如何使用 alertDialog从listView中删除数据?</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a>
<div>我现在使用listView展示了很多的配置信息,我现在想在点击其中一条的时候填出 alertDialog,点击确认后就删除该条数据,( ArrayAdapter ,ArrayList,listView 全部删除),我知道在 下面的onItemLongClick 方法中 参数 arg2 是选中的序号,但是我不知道如何继续处理下去 1 2 3 </div>
</li>
<li><a href="/article/1161.htm"
title="jdk-6u26-linux-x64.bin 安装" target="_blank">jdk-6u26-linux-x64.bin 安装</a>
<span class="text-muted">baalwolf</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>1.上传安装文件(jdk-6u26-linux-x64.bin)
2.修改权限
[root@localhost ~]# ls -l /usr/local/jdk-6u26-linux-x64.bin
3.执行安装文件
[root@localhost ~]# cd /usr/local
[root@localhost local]# ./jdk-6u26-linux-x64.bin&nbs</div>
</li>
<li><a href="/article/1288.htm"
title="MongoDB经典面试题集锦" target="_blank">MongoDB经典面试题集锦</a>
<span class="text-muted">BigBird2012</span>
<a class="tag" taget="_blank" href="/search/mongodb/1.htm">mongodb</a>
<div>1.什么是NoSQL数据库?NoSQL和RDBMS有什么区别?在哪些情况下使用和不使用NoSQL数据库?
NoSQL是非关系型数据库,NoSQL = Not Only SQL。
关系型数据库采用的结构化的数据,NoSQL采用的是键值对的方式存储数据。
在处理非结构化/半结构化的大数据时;在水平方向上进行扩展时;随时应对动态增加的数据项时可以优先考虑使用NoSQL数据库。
在考虑数据库的成熟</div>
</li>
<li><a href="/article/1415.htm"
title="JavaScript异步编程Promise模式的6个特性" target="_blank">JavaScript异步编程Promise模式的6个特性</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/Promise/1.htm">Promise</a>
<div> Promise是一个非常有价值的构造器,能够帮助你避免使用镶套匿名方法,而使用更具有可读性的方式组装异步代码。这里我们将介绍6个最简单的特性。
在我们开始正式介绍之前,我们想看看Javascript Promise的样子:
var p = new Promise(function(r</div>
</li>
<li><a href="/article/1542.htm"
title="[Zookeeper学习笔记之八]Zookeeper源代码分析之Zookeeper.ZKWatchManager" target="_blank">[Zookeeper学习笔记之八]Zookeeper源代码分析之Zookeeper.ZKWatchManager</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/zookeeper/1.htm">zookeeper</a>
<div>ClientWatchManager接口
//接口的唯一方法materialize用于确定那些Watcher需要被通知
//确定Watcher需要三方面的因素1.事件状态 2.事件类型 3.znode的path
public interface ClientWatchManager {
/**
* Return a set of watchers that should</div>
</li>
<li><a href="/article/1669.htm"
title="【Scala十五】Scala核心九:隐式转换之二" target="_blank">【Scala十五】Scala核心九:隐式转换之二</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/scala/1.htm">scala</a>
<div>隐式转换存在的必要性,
在Java Swing中,按钮点击事件的处理,转换为Scala的的写法如下:
val button = new JButton
button.addActionListener(
new ActionListener {
def actionPerformed(event: ActionEvent) {
</div>
</li>
<li><a href="/article/1796.htm"
title="Android JSON数据的解析与封装小Demo" target="_blank">Android JSON数据的解析与封装小Demo</a>
<span class="text-muted">ronin47</span>
<div>转自:http://www.open-open.com/lib/view/open1420529336406.html
package com.example.jsondemo;
import org.json.JSONArray;
import org.json.JSONException;
import org.json.JSONObject;
impor</div>
</li>
<li><a href="/article/1923.htm"
title="[设计]字体创意设计方法谈" target="_blank">[设计]字体创意设计方法谈</a>
<span class="text-muted">brotherlamp</span>
<a class="tag" taget="_blank" href="/search/UI/1.htm">UI</a><a class="tag" taget="_blank" href="/search/ui%E8%87%AA%E5%AD%A6/1.htm">ui自学</a><a class="tag" taget="_blank" href="/search/ui%E8%A7%86%E9%A2%91/1.htm">ui视频</a><a class="tag" taget="_blank" href="/search/ui%E6%95%99%E7%A8%8B/1.htm">ui教程</a><a class="tag" taget="_blank" href="/search/ui%E8%B5%84%E6%96%99/1.htm">ui资料</a>
<div>
从古至今,文字在我们的生活中是必不可少的事物,我们不能想象没有文字的世界将会是怎样。在平面设计中,UI设计师在文字上所花的心思和功夫最多,因为文字能直观地表达UI设计师所的意念。在文字上的创造设计,直接反映出平面作品的主题。
如设计一幅戴尔笔记本电脑的广告海报,假设海报上没有出现“戴尔”两个文字,即使放上所有戴尔笔记本电脑的图片都不能让人们得知这些电脑是什么品牌。只要写上“戴尔笔</div>
</li>
<li><a href="/article/2050.htm"
title="单调队列-用一个长度为k的窗在整数数列上移动,求窗里面所包含的数的最大值" target="_blank">单调队列-用一个长度为k的窗在整数数列上移动,求窗里面所包含的数的最大值</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E9%9D%A2%E8%AF%95%E9%A2%98/1.htm">面试题</a>
<div>import java.util.LinkedList;
/*
单调队列 滑动窗口
单调队列是这样的一个队列:队列里面的元素是有序的,是递增或者递减
题目:给定一个长度为N的整数数列a(i),i=0,1,...,N-1和窗长度k.
要求:f(i) = max{a(i-k+1),a(i-k+2),..., a(i)},i = 0,1,...,N-1
问题的另一种描述就</div>
</li>
<li><a href="/article/2177.htm"
title="struts2处理一个form多个submit" target="_blank">struts2处理一个form多个submit</a>
<span class="text-muted">chiangfai</span>
<a class="tag" taget="_blank" href="/search/struts2/1.htm">struts2</a>
<div>web应用中,为完成不同工作,一个jsp的form标签可能有多个submit。如下代码:
<s:form action="submit" method="post" namespace="/my">
<s:textfield name="msg" label="叙述:"></div>
</li>
<li><a href="/article/2304.htm"
title="shell查找上个月,陷阱及野路子" target="_blank">shell查找上个月,陷阱及野路子</a>
<span class="text-muted">chenchao051</span>
<a class="tag" taget="_blank" href="/search/shell/1.htm">shell</a>
<div>date -d "-1 month" +%F
以上这段代码,假如在2012/10/31执行,结果并不会出现你预计的9月份,而是会出现八月份,原因是10月份有31天,9月份30天,所以-1 month在10月份看来要减去31天,所以直接到了8月31日这天,这不靠谱。
野路子解决:假设当天日期大于15号</div>
</li>
<li><a href="/article/2431.htm"
title="mysql导出数据中文乱码问题" target="_blank">mysql导出数据中文乱码问题</a>
<span class="text-muted">daizj</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E4%B8%AD%E6%96%87%E4%B9%B1%E7%A0%81/1.htm">中文乱码</a><a class="tag" taget="_blank" href="/search/%E5%AF%BC%E6%95%B0%E6%8D%AE/1.htm">导数据</a>
<div>解决mysql导入导出数据乱码问题方法:
1、进入mysql,通过如下命令查看数据库编码方式:
mysql> show variables like 'character_set_%';
+--------------------------+----------------------------------------+
| Variable_name&nbs</div>
</li>
<li><a href="/article/2558.htm"
title="SAE部署Smarty出现:Uncaught exception 'SmartyException' with message 'unable to write" target="_blank">SAE部署Smarty出现:Uncaught exception 'SmartyException' with message 'unable to write</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/smarty/1.htm">smarty</a><a class="tag" taget="_blank" href="/search/sae/1.htm">sae</a>
<div>
对于SAE出现的问题:Uncaught exception 'SmartyException' with message 'unable to write file...。
官方给出了详细的FAQ:http://sae.sina.com.cn/?m=faqs&catId=11#show_213
解决方案为:
01
$path </div>
</li>
<li><a href="/article/2685.htm"
title="《教父》系列台词" target="_blank">《教父》系列台词</a>
<span class="text-muted">dcj3sjt126com</span>
<div>Your love is also your weak point.
你的所爱同时也是你的弱点。
If anything in this life is certain, if history has taught us anything, it is
that you can kill anyone.
不顾家的人永远不可能成为一个真正的男人。 &</div>
</li>
<li><a href="/article/2812.htm"
title="mongodb安装与使用" target="_blank">mongodb安装与使用</a>
<span class="text-muted">dyy_gusi</span>
<a class="tag" taget="_blank" href="/search/mongo/1.htm">mongo</a>
<div>一.MongoDB安装和启动,widndows和linux基本相同
1.下载数据库,
linux:mongodb-linux-x86_64-ubuntu1404-3.0.3.tgz
2.解压文件,并且放置到合适的位置
tar -vxf mongodb-linux-x86_64-ubun</div>
</li>
<li><a href="/article/2939.htm"
title="Git排除目录" target="_blank">Git排除目录</a>
<span class="text-muted">geeksun</span>
<a class="tag" taget="_blank" href="/search/git/1.htm">git</a>
<div>在Git的版本控制中,可能有些文件是不需要加入控制的,那我们在提交代码时就需要忽略这些文件,下面讲讲应该怎么给Git配置一些忽略规则。
有三种方法可以忽略掉这些文件,这三种方法都能达到目的,只不过适用情景不一样。
1. 针对单一工程排除文件
这种方式会让这个工程的所有修改者在克隆代码的同时,也能克隆到过滤规则,而不用自己再写一份,这就能保证所有修改者应用的都是同一</div>
</li>
<li><a href="/article/3066.htm"
title="Ubuntu 创建开机自启动脚本的方法" target="_blank">Ubuntu 创建开机自启动脚本的方法</a>
<span class="text-muted">hongtoushizi</span>
<a class="tag" taget="_blank" href="/search/ubuntu/1.htm">ubuntu</a>
<div>转载自: http://rongjih.blog.163.com/blog/static/33574461201111504843245/
Ubuntu 创建开机自启动脚本的步骤如下:
1) 将你的启动脚本复制到 /etc/init.d目录下 以下假设你的脚本文件名为 test。
2) 设置脚本文件的权限 $ sudo chmod 755</div>
</li>
<li><a href="/article/3193.htm"
title="第八章 流量复制/AB测试/协程" target="_blank">第八章 流量复制/AB测试/协程</a>
<span class="text-muted">jinnianshilongnian</span>
<a class="tag" taget="_blank" href="/search/nginx/1.htm">nginx</a><a class="tag" taget="_blank" href="/search/lua/1.htm">lua</a><a class="tag" taget="_blank" href="/search/coroutine/1.htm">coroutine</a>
<div>流量复制
在实际开发中经常涉及到项目的升级,而该升级不能简单的上线就完事了,需要验证该升级是否兼容老的上线,因此可能需要并行运行两个项目一段时间进行数据比对和校验,待没问题后再进行上线。这其实就需要进行流量复制,把流量复制到其他服务器上,一种方式是使用如tcpcopy引流;另外我们还可以使用nginx的HttpLuaModule模块中的ngx.location.capture_multi进行并发</div>
</li>
<li><a href="/article/3320.htm"
title="电商系统商品表设计" target="_blank">电商系统商品表设计</a>
<span class="text-muted">lkl</span>
<div>DROP TABLE IF EXISTS `category`; -- 类目表
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `category` (
`id` int(11) NOT NUL</div>
</li>
<li><a href="/article/3447.htm"
title="修改phpMyAdmin导入SQL文件的大小限制" target="_blank">修改phpMyAdmin导入SQL文件的大小限制</a>
<span class="text-muted">pda158</span>
<a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div> 用phpMyAdmin导入mysql数据库时,我的10M的
数据库不能导入,提示mysql数据库最大只能导入2M。
phpMyAdmin数据库导入出错: You probably tried to upload too large file. Please refer to documentation for ways to workaround this limit. </div>
</li>
<li><a href="/article/3574.htm"
title="Tomcat性能调优方案" target="_blank">Tomcat性能调优方案</a>
<span class="text-muted">Sobfist</span>
<a class="tag" taget="_blank" href="/search/apache/1.htm">apache</a><a class="tag" taget="_blank" href="/search/jvm/1.htm">jvm</a><a class="tag" taget="_blank" href="/search/tomcat/1.htm">tomcat</a><a class="tag" taget="_blank" href="/search/%E5%BA%94%E7%94%A8%E6%9C%8D%E5%8A%A1%E5%99%A8/1.htm">应用服务器</a>
<div>一、操作系统调优
对于操作系统优化来说,是尽可能的增大可使用的内存容量、提高CPU的频率,保证文件系统的读写速率等。经过压力测试验证,在并发连接很多的情况下,CPU的处理能力越强,系统运行速度越快。。
【适用场景】 任何项目。
二、Java虚拟机调优
应该选择SUN的JVM,在满足项目需要的前提下,尽量选用版本较高的JVM,一般来说高版本产品在速度和效率上比低版本会有改进。
J</div>
</li>
<li><a href="/article/3701.htm"
title="SQLServer学习笔记" target="_blank">SQLServer学习笔记</a>
<span class="text-muted">vipbooks</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a><a class="tag" taget="_blank" href="/search/xml/1.htm">xml</a>
<div>1、create database school 创建数据库school
2、drop database school 删除数据库school
3、use school 连接到school数据库,使其成为当前数据库
4、create table class(classID int primary key identity not null)
创建一个名为class的表,其有一</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>