1)决策树之ID3
决策树算法是分类算法的一种,基础是ID3算法,C4.5、C5.0都是对ID3的改进。ID3算法的基本思想是,选择信息增益最大的属性作为当前的分类属性。
看Tom M. Mitchell老师的《Machine Learing》第三章中的例子: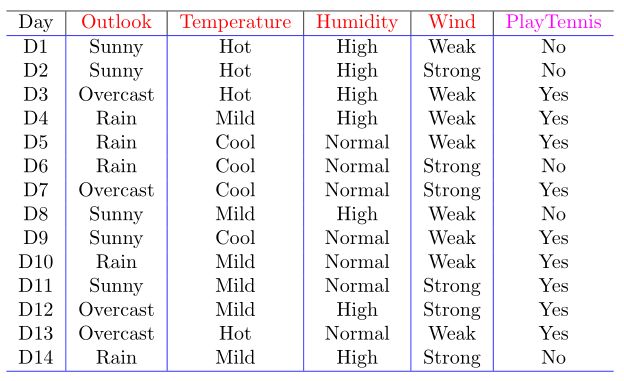
我们先解释一下这张表,表中有14条实例数据,就是我们的训练数据,其中 Outlook,Temperature,Humidity ,Wind 称作条件属性,PlayTennis 称作是决策属性(标签)。
每一个属性都有各自的值记做:Value(Outlook)={Sunny,OverCast,Rain},Value(Temperature)={Hot,Mild,Cool},Value(Humidity)={High,Normal},Value(Wind)={Strong,Weak},Value(PlayTennis)={NO,Yes}。
第一个重要的概念:Entropy。
我们数一下 决策属性PlayTennis,一共有两个类别:Yes,No。Yes的实例数是 9,No的实例数是 5。计算决策属性的Entropy(熵): ,计算结果为:0.940286。
,计算结果为:0.940286。
这里的决策属性S的值只有两个值(Yes,No),当然可以有多个值(s1,s2,s3,...,sk),这些决策属性的值的概率分别为:p1,p2,p3,...,pk所以决策属性的Entroy的计算公式:
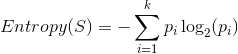
第二个重要的概念:information gain(信息增益)
我们只拿Outlook条件属性举例,其他的属性一样:
Value(Outlook)={Sunny,OverCast,Rain}:Outlook是sunny的实例数为5(其中Yes的个数为2,No的个数为3),占总的实例数为5/14,那么针对sunny的Entropy:
Entropy(Sunny)= ,计算结果为:0.97095。
,计算结果为:0.97095。
Outlook是OverCast的实例数为4(其中Yes的个数为4,No的个数为0),占总的实例数为4/14,那么针对Overcast的Entropy:
 ,计算结果为:0。
,计算结果为:0。
Outlook是Rain的实例数为5(其中Yes的个数为3,No的个数为2),占总的实例数为5/14,那么针对Rain的Entropy,
 ,计算结果为:0.97095。
,计算结果为:0.97095。
那么最后针对Outlook条件属性的information gain为:
 ,计算结果为:0.24675。
,计算结果为:0.24675。
所以针对某一条件属性的information gain为:

那么其他三个条件属性Temperature、Humidity、Wind的信息增益为:


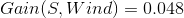
我们看到Outlook的信息增益是最大的,所以作为决策树的一个根节点。即:

然后,从Outlook下面出来三个树枝,最左边的Sunny,我们从Outlook是Sunny的实例数据中,找到信息增益最大的那一个,依次类推。
(注释:http://blog.csdn.net/mmc2015/article/details/42525655;而下面程序本人写的)
clc; clear all; close all; %% 导入数据 %data = [1,1,1;1,1,1;1,0,0;0,1,0;0,1,0]; data = [0,2,0,0,0; 0,2,0,1,0; 1,2,0,0,1; 2,1,0,0,1; 2,0,1,0,1; 2,0,1,1,0; 1,0,1,1,1; 0,1,0,0,0; 0,0,1,0,1; 2,1,1,0,1; 0,1,1,1,1; 1,1,0,1,1; 1,2,1,0,1; 2,1,0,1,0]; % data = {'sunny','hot','high','week','no'; % 'sunny','hot','high','strong','no'; % 'overcast','hot','high','week','yes'; % 'rain','midd','high','week','yes'; % 'rain','cool','nomal','week','yes'; % 'rain','cool','nomal','strong','no'; % 'overcast','cool','nomal','strong','yes'; % 'sunny','midd','high','week','no'; % 'sunny','cool','nomal','week','yes'; % 'rain','midd','nomal','week','yes'; % 'sunny','midd','nomal','strong','yes'; % 'overcast','midd','high','strong','yes'; % 'overcast','hot','nomal','week','yes'; % 'rain','midd','high','strong','no'}; %sunuy-0,overcast-1,rain-2;--hot-2,midd-1,cool-2---high-0,nomal-1--week-0,strong-1,no-0,yes-1 %% 生成决策树 make_tree(data); function make_tree(train_data) %input train_data 训练数据 %output [m,n] = size(train_data); disp('original data'); disp(train_data); class_list = train_data(:,n); class_first = 1; for i = 2:m if train_data(i,n) == class_list(1,:) % if strcmp(train_data(i,n),class_list(1,:)) class_first = class_first + 1; end end %% 退出程序条件 if class_first == m || n == 1 disp('final data'); disp(train_data); return; end %% 建立决策树 bestfeat = choose_bestfeat(train_data); disp(['bestfeature:',num2str(bestfeat)]); featvalue = unique(train_data(:,bestfeat)); featvalue_num = length(featvalue); for i = 1:featvalue_num make_tree(splitData(train_data,bestfeat,featvalue(i,:))); disp('--------------------------------------------'); end end function [best_feature] = choose_bestfeat(data) %input data 输入数据 %output bestfeature 选择特征值 [m,n] = size(data); feature_num = n - 1; baseentropy = calc_entropy(data); best_gain = 0; best_feature = 0; %% 挑选最佳特征位 for j =1:feature_num feature_temp = unique(data(:,j)); num_f = length(feature_temp); new_entropy = 0; for i = 1:num_f subSet = splitData(data, j, feature_temp(i,:)); [m_s,n_s] = size(subSet); prob = m_s./m; new_entropy = new_entropy + prob * calc_entropy(subSet); end inf_gain = baseentropy - new_entropy; if inf_gain > best_gain best_gain = inf_gain; best_feature = j; end end end function [entropy] = calc_entropy(train_data) %input train_data 训练数据 %output entropy 熵值 [m,n] = size(train_data); %% 得到类的项并统计每个类的个数 label_value = train_data(:,n); label = unique(label_value); label_number = zeros(length(label),2); label_number(:,1) = label'; for i = 1:length(label) label_number(i,2) = sum(label_value == label(i)); end %% 计算熵值 label_number (:,2) = label_number(:,2) ./ m; entropy = 0; entropy = sum(-label_number(:,2).*log2 (label_number(:,2))); end function [subSet] = splitData(data, j, value) %input data 训练数据 %input j 对应第j个属性 %input value 第j个属性对应的特征值 %output sunset 熵值 subSet = data; subSet(:,j) = []; k = 0; for i = 1:size(data,1) if data(i,j) ~= value subSet(i-k,:) =[]; k = k + 1; end end end function [subSet] = splitData(data, j, value) %input data 训练数据 %input j 对应第j个属性 %input value 第j个属性对应的特征值 %output sunset 熵值 subSet = data; subSet(:,j) = []; k = 0; for i = 1:size(data,1) if data(i,j) ~= value subSet(i-k,:) =[]; k = k + 1; end end end